Hadoop2、Mac系统上,Hadoop集群配置,基于Centos7与Hadoop2.7.3
一、安装了一台虚拟机,先安装单机版Hadoop,为克隆做准备
首先本地下载Hadoop2.7.3文件,然后打开Mac终端上传文件到服务器上指定位置:
上传文件命令 :scp hadoop2.7.tgz.gz [email protected]:/usr/bigdata/tools/
文件的目录结构:
开始安装:
1、 先解压: tar -xzvf hadoop2.7.tgz.gz -C /usr/bigdata/
2、 创建符合连接(可以不创建,是为了方便):ln -s hadoop-2.7.3 hadoop
3、配置环境变量:vim /etc/profile
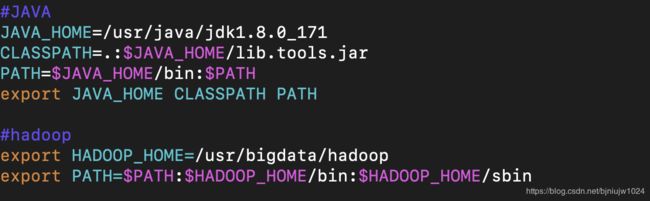
4、更新环境变量:source /etc/profile
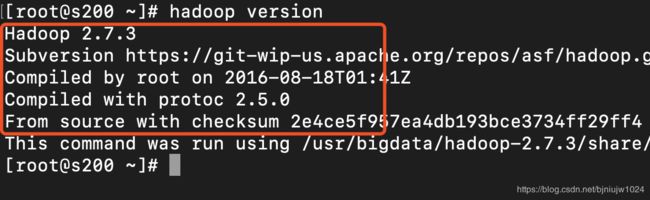
5、验证Hadoop是否安装成功: hadoop version
出现如下即显示安装成功
二、安装Hadoop的伪分布式
1、进入hadoop的/etc/hadoop目录:cd $HADOOP_HOME/etc/hadoop/

2、编辑core-site.xml
命令:vim core-site.xml
fs.defaultFS
hdfs://s200/
3、编辑hdfs-site.xml
命令:vim hdfs-site.xml
dfs.replication
3
4、编辑mapred-site.xml
命令:vim mapred-site.xml
mapreduce.framework.name
yarn
5、编辑yarn-site.xml
命令:vim yarn-site.xml
yarn.resourcemanager.hostname
s200
yarn.nodemanager.aux-services
mapreduce_shuffle
三、Hadoop完全分布式集群搭建(一台主机上)
1、配置hadoop,使用符号连接的方式,让三种配置形态共存。
命令: cd $HADOOP_HOME/etc/
创建三个目录,内容等同于hadoop:(类似与复制重命名)
full(完全) local(单机) pesudo(伪分布)
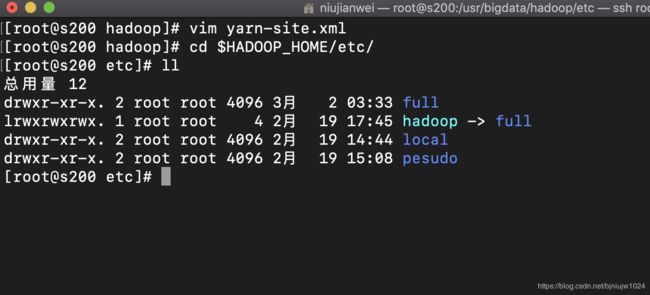
2、删除hadoop,然后创建符合连接
命令:ln -s full hadoop
3、对hdfs进行格式化
命令:hadoop namenode -format
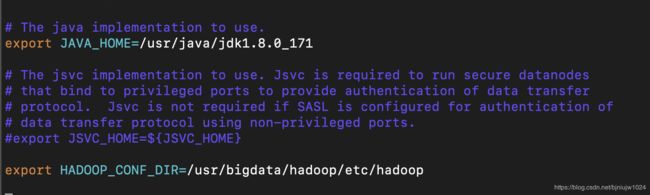
4、修改hadoop配置文件,手动指定JAVA_HOME环境变量
命令:cd $HADOOP_HOME/etc/full/
编辑: vim hadoop-env.sh
修改:JAVA_HOME环境变量
...
export JAVA_HOME=/soft/jdk
... 
5、保存,退出。然后启动hadoop,查看进程
命令:start-all.sh
进程:jps

6、查看hdfs文件系统
命令:hdfs dfs -ls /
7、通过webui查看hadoop的文件系统
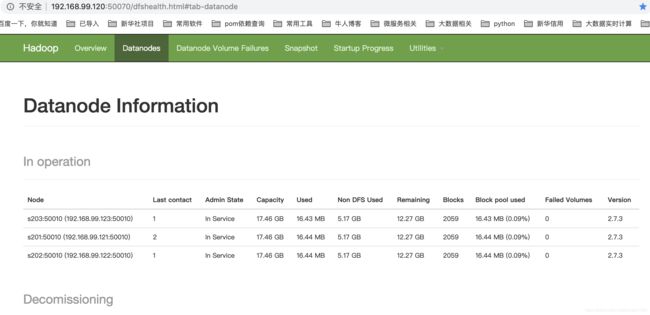
8、停止hadoop所有进程
命令:stop-all.sh
9、centos防火墙操作
[cnetos 6.5之前的版本]
$>sudo service firewalld stop //停止服务
$>sudo service firewalld start //启动服务
$>sudo service firewalld status //查看状态
[centos7]
$>sudo systemctl enable firewalld.service //"开机启动"启用
$>sudo systemctl disable firewalld.service //"开机自启"禁用
$>sudo systemctl start firewalld.service //启动防火墙
$>sudo systemctl stop firewalld.service //停止防火墙
$>sudo systemctl status firewalld.service //查看防火墙状态
[开机自启]
$>sudo chkconfig firewalld on //"开启自启"启用
$>sudo chkconfig firewalld off //"开启自启"禁用注意:拓展
Hadoop启动和停止命令:start-all.sh stop-all.sh
单独启动节点的命令:
start-dfs.sh
start-yarn.sh
[hdfs] start-dfs.sh stop-dfs.sh
NN
DN
2NN
[yarn] start-yarn.sh stop-yarn.sh
RM
NM10、修改主机名:
1./etc/hostname
s200
2./etc/hosts
127.0.0.1 localhost
192.168.99.200 s200
192.168.99.201 s201
192.168.99.202 s202
192.168.99.203 s203
四、Hadoop完全分布式集群搭建(多台主机)
1、克隆3台client(centos7)
右键centos-7-->管理->克隆-> ... -> 完整克隆
2、启动client
3、启用客户机共享文件夹。
4、修改hostname和ip地址文件
[/etc/hostname]
s200

命令:[/etc/sysconfig/network-scripts/ifcfg-ethxxxx]
5、重启网络服务
service network restart
6、修改/etc/resolv.conf文件
nameserver 192.168.99.2
7、重复以上3 ~ 6过程,每台克隆的新设备都需要进行操作
8、配置slaves

9、将配置分发到每一台主机 scp命令 分发一个文件到指定到文件夹下,不懂scp命令到可以查看如下:
感觉不错到一个朋友到博客:https://blog.csdn.net/yeyinglingfeng/article/details/83411129
命令: scp spark-env.sh root@s201:/usr/bigdata/spark/conf/
10、删除hadoop日志
cd /usr/bigdata/hadoop/logs
rm -rf *
ssh s201 rm -rf /usr/bigdata/hadoop/logs/*
ssh s202 rm -rf /usr/bigdata/hadoop/logs/*
ssh s203 rm -rf /usr/bigdata/hadoop/logs/*
11、格式化文件系统
hadoop namenode -format
12、启动hadoop进程
start-all.sh
13、验证方式:
类似与伪分布式,jps查看进程,webui查看界面
***如有疑问可以提出,我会帮朋友们解决,谢谢大家支持***
***请关注QQ群号:851989684 ***