细粒度情感分析任务(ABSA)的最新进展

作者丨邴立东、李昕、李正、彭海韵、许璐
单位丨阿里巴巴达摩院等
任务简介
我们略过关于 sentiment analysis 重要性的铺陈,直接进入本文涉及的任务。先上例子,对于一句餐馆评论:“Waiters are very friendly and the pasta is simply average.”,提到了两个评论目标:“waiter”和“pasta”;用来评价他们的词分别是:“friendly”和“average”;这句话评论的分别是餐馆的“service”和“food”方面。
以上便是 Aspect-Based Sentiment Analysis (ABSA) 任务中处理的三类对象:aspect、opinion、aspect category。也就是下图中的最上层。
从目标识别角度,针对 aspect term 和 opinion term,存在抽取问题;针对 aspect category,存在分类问题(假设预定义 aspect categories)。从情感分析角度,对 aspect term 和 aspect category 存在情感分类问题。这些原子任务如下图中间层所示。注意,一句评论里可能没有显示提及 aspect term,但同样可以存在 aspect category,比如“I was treated rudely.”讲的是“service”。
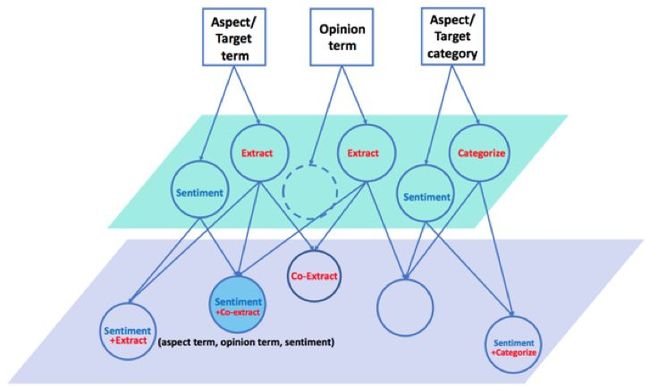
在已有的工作中,研究者也探索了结合两个或以上原子任务,如上图底层所示。基于任务之间的耦合关系,期望联合任务能取得更优的效果。比如我们提出的在做 aspect extraction 的同时预测 sentiment 极性(下文介绍的第一个工作),这个任务被称作 End-to-End ABSA (E2E-ABSA),对应于上图底层最左侧圆圈。
我们也尝试了利用迁移学习,来解决在低资源、少资源 domain 上的 E2E-ABSA 任务(下文介绍的第二个工作)。Aspect 及其 sentiment 极性(即 E2E-ABSA 任务),同表明这个极性的 opinion term,这三者之间是紧密相关的,为此我们提出 Aspect Sentiment Triplet Extraction (ASTE) 任务(下文介绍的第三个工作),对应于上图底层蓝色填充圆圈。
End-to-End ABSA任务
本小节工作来自论文:
1. A Unified Model for Opinion Target Extraction and Target Sentiment Prediction. In AAAI 2019.


源码链接:https://github.com/lixin4ever/E2E-TBSA
2. Exploiting BERT for End-to-End Aspect-based Sentiment Analysis. In EMNLP W-NUT Workshop 2019.


源码链接:https://github.com/lixin4ever/BERT-E2E-ABSA
问题定义
基于评论目标的端到端情感分析(End-to-End Aspect/Target-Based Sentiment Analysis, E2E-ABSA)的目的在于同时检测用户评论的目标/方面(Target/Aspect)以及相应的情感倾向(Target/Aspect Sentiment)。
我们将 E2E-ABSA 任务定义为一阶段的序列标注问题并引入了一种统一的标注模式(unified tagging schema)来将 Aspect 的位置信息和情感信息同时集成到单个标签当中。
如下图中的“Unified”行所示,除了 O 之外的每个标签的组成元素都包含位置(B/I/E/S)和情感标签(POS/NEG/NEU)。在这种标注模式下,输入为单词序列,输出为每个单词对应的 unified tag。

相关方法的局限
本任务中,aspect 抽取加情感判断,是一个很自然的两阶段建模问题。因此,E2E-ABSA 可以通过流水线(pipeline)或者联合建模(joint)的方式解决。
基于pipeline 的解决方案会先检测文本中的 aspect(序列标注问题),然后再判断相应的情感倾向(分类问题)。这种方案简单直接,但是存在 error propagation 的局限。
基于 joint 的解决方案将 E2E-ABSA 转化为两个串联的序列标注问题,即 target 标注和 sentiment 标注问题,如上图中的“Joint”行所示。该方案能够很大程度上减轻 error propagation 问题,但是工作 [1] [2] [3] 指出,把序列标注问题拆分为多个子问题逐步解决,并不会比解决单个问题性能更好。
基于以上的考虑,我们设计了一种统一的标注模式并基于这种模式提出了解决统一 E2E-ABSA 序列标注问题的神经网络模型(unified 方案)。需要注意的是,工作 [4] [5] 也尝试了用 unified 方案去解决 E2E-ABSA 问题,但是效果均差于 pipeline 方案和 joint 方案。所以,提出了一个更有效的 unified 方案也是我们的贡献之一。
我们的模型
根据以上统一的标注模式(unified tagging schema)的设计,我们将 E2E-ABSA 建模为一个序列标注问题。同时,我们还从下游模型的建模能力和词义表示的质量这两个角度来探索如何提升 unified 方案的性能:
1. 更强大的下游模型:我们提出了一个新的堆叠式循环神经网络(RNN)来解决 E2E-ABSA 问题。这个模型包含了两层堆叠的循环神经网络(RNN),上层的 RNN 用于解决 E2E-ABSA 问题(即预测 unified 方案中的标签序列),下层的 RNN 负责检测评论目标的边界。
为了充分利用评论目标的边界信息,我们提出了一个 Boundary Guidance (BG) 组件显式地把下层 RNN 提取的边界信息加入到 E2E-ABSA 的序列决策中。在序列预测过程中,我们还通过 Sentiment Consistency (SC) 组件,来加强当前词和过去一个时刻的词的关系,从而缓解同一个评论目标短语内情感标签不一致的问题。

2. 更好的词级别语义表示:我们利用预训练的 BERT [6] 来产生上下文相关的词向量,然后将 BERT 与标准的神经序列模型,例如:LSTM, Self-Attention Networks [7], CRF [8] 等结合起来解决 E2E-ABSA 这个序列标注问题。
主要结果
我们在 SemEval Laptop、SemEval Restaurant 和 Twitter 数据集上进行了实验。方案 1 的实验结果如下。我们提出的第一种 unified 方案(方案 1),在所有数据集上均胜过现有的 pipeline 方案(HAST-TNet)和 joint 方案(NN-CRF-joint)。我们的方案同样也优于三种基于 LSTM-CRF(NER 任务中最常用的模型)的 unified 方案。
以上结果不仅验证了我们所设计的统一标注模式(unified tagging schema)在 E2E-ABSA 任务上的适用性,也说明了更强大的下游神经网络框架能够更精确地识别评论目标以及对应的用户情感倾向。

方案 2 的实验结果如下。从表格中我们可以看到,在引入 BERT 的情况下,使用最简单的下游任务模型(i.e, BERT-Linear)都可以胜过之前最好的模型(Luo et al., 2019);继续增加下游网络的复杂度(i.e., BERT-GRU, BERT-TFS, BERT-CRF),模型的效果能够得到进一步提升。

这些结果表明 BERT 所提供的的上下文相关的语义表示对于提升 E2E-ABSA 系统性能的重要性。一个很自然的问题就是结合我们的方案 1 和方案 2 结果会怎么样,目前正在实验中。
本小节参考文献
[1] Jing, Hongyan, et al. "HowtogetaChineseName (Entity): Segmentation and combination issues." Proceedings of the 2003conference on Conference on Empirical Methods in Natural Language Processing (EMNLP). 2003.
[2] Ng, Hwee Tou, and Jin Kiat Low. "Chinese part-of-speech tagging: One-at-a-time or all-at-once? word-based or character-based?." Proceedings of the 2004 Conference on EmpiricalMethods in Natural Language Processing (EMNLP). 2004.
[3] Miwa, Makoto, and Yutaka Sasaki. "Modeling joint entity and relation extraction with table representation." Proceedings of the2014 Conference on Empirical Methods in Natural Language Processing (EMNLP).2014.
[4] Mitchell, Margaret, et al. "Open domain targeted sentiment." Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing(EMNLP). 2013.
[5] Zhang, Meishan, Yue Zhang, and Duy Tin Vo. "Neural networks for open domain targeted sentiment." Proceedings of the 2015Conference on Empirical Methods in Natural Language Processing (EMNLP).2015.
[6] Devlin, Jacob, et al. "BERT: Pre-training of DeepBidirectional Transformers for Language Understanding." Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 2019.
[7] Vaswani, Ashish, et al. "Attention is all you need." Advances in neural information processing systems.2017.
[8] Lafferty, John D., Andrew McCallum, and Fernando CN Pereira."Conditional Random Fields: Probabilistic Models for Segmenting and Labeling Sequence Data." Proceedings of the EighteenthInternational Conference on Machine Learning. 2001.
Transfer Learning for E2E-ABSA
本小节工作来自论文:
Transferable End-to-End Aspect-based Sentiment Analysis with Selective Adversarial Learning, In EMNLP 2019.


源码链接:https://github.com/hsqmlzno1/Transferable-E2E-ABSA
问题定义
可迁移的基于评价目标的端到端情感分析(Transferable End-to-End Aspect-Based Sentiment Analysis, Trans-E2E-ABSA)是建立在 E2E-ABSA 统一的标注模式(序列标注)下无监督领域自适应的问题设置,目的在于利用有大量标签数据的源领域学习到的知识帮助无任何标签数据的目标领域进行序列学习(统一标注的预测)。
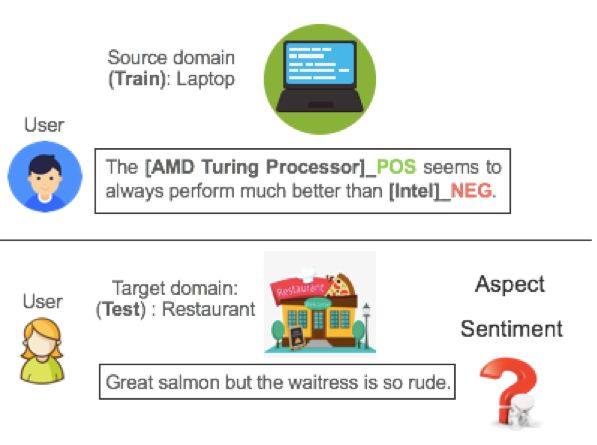
如下图所示,在笔记本电脑源领域(source domain),我们有大量的标签数据,即用户评论中标注了所有出现的评价目标以及其情感倾向([AMD]B_POS [Turing]I_POS [Processor]E_POS, [Intel]S_NEG),对于餐馆目标领域(target domain),只有无标签数据,即不标记任何出现的评价目标以及对应的情感。Trans-E2E-ABSA 需要迁移笔记本电脑领域的学习知识来帮助餐馆领域进行的评价对象以及情感的预测。
相关方法的局限
在真实场景下,总存在只有少量或者没有标签数据的新领域,而手工标注用户评论中每个词的统一标签是耗时且昂贵的。这构成了迁移学习在 E2E-ABSA 任务上必要性。
现有的基于评价对象的端到端情感分析的研究只考虑到单个领域的性能表现,而忽略了跨领域的迁移与泛化能力。因此,我们提出了在 E2E-ABSA 下的无监督领域自适应的问题设置来帮助缓解模型依赖于领域的监督。
与之前无监督领域自适应在情感分析任务相比,E2E-ABSA 问题的迁移学习更加具有挑战性:
1. 由于不同领域评价对象的不同,领域间特征分布差异很大。例如,用户通常在餐馆领域提及“pizza”,而在笔记本电脑领域常常讨论“camera”;
2. 不像在普通情感分类问题下的领域自适应目的是为了学习领域间共享的句子或者文档级的特征表达 [1],我们需要学习更加细粒度的(词级别)领域共享的特征表达来进行序列的预测。
我们的模型

我们使用了 [2] 中提出的堆叠式双向 LSTM 来作为我们的 base 模型,即上层 LSTM 用于预测统一标签(评价对象+情感极性),下层的 LSTM 负责检测评论对象的边界。为了使得该 base 模型可以在领域之间迁移,我们设计了两个不同的模块来分别解决迁移学习对于 E2E-ABSA 任务的两个核心问题:1)迁移什么?2)如何迁移?
1. 迁移什么?
尽管在不同的领域评价对象不同,但评价对象与观点词(情感词)关联的模式在领域间是共享的。例如,在餐馆领域中的“The pizza is great“和在笔记本电脑领域中的“The camera is excellent”,他们共享相同的句法模式(评价对象→nsubj→观点词)。
受此启发,现有的相关工作使用通用语法关系来作为枢纽来减少领域间的差异,用于跨领域的评价对象的抽取 [3] [4],或者跨领域评价与观点对象抽取 [5] [6]。然而,这些方法高度依赖先验知识(手工设计的规则)或外部语言资源(依存关系语法分析),这使得模型不够灵活以及容易引入外部的知识错误。
与此相反,我们提出了一种双内存交互(DMI)机制来自动捕捉评价对象与观点词之间的隐藏关系。DMI 通过多次交互 local memory(LSTM 隐状态)与 global 的评价对象 memory,观点词 memory 的方式,推理出每个词的关系表达,从而可用于序列标注任务下迁移的知识。
2. 如何迁移?
对于序列预测任务下的迁移,其中一种最直接的办法就是应用领域自适应的方法来对齐句子中所有的词,使得在源领域训练好的序列标注器(tagger)可以同时很好的在目标领域进行预测。然而这种方式并不会带来显著的性能提升。
我们一个重要的发现是:在序列预测任务下的迁移,由于每个词对于领域共享的特征空间的贡献不同,我们需要对不同的词使用不同的领域自适应的权重。在 E2E-ABSA 任务中,我们着重的对齐句子中更加具有信息量的评价对象。这是因为统一的标注模式(unified tagging schema)将评价对象的位置信息和情感信息同时集成到单个标签中,并且赋予了评价对象,其对共享的特征空间的贡献比句子中剩余的被标记成 O 的词远远比要大。
因此,我们提出了选择性对抗学习(SAL)来对齐句子中的重要的评价对象词。具体的,我们对于句子中的每个词采用的一个领域判断器来判别该词所在的句子来自哪一个领域(源领域或者目标领域),并利用一个梯度反转层 [7] 来对每一个词的关系向量进行领域的对抗学习,从而迷惑领域判断器来达到学习细粒度(词级别)的领域共享特征表达。
同时,我们利用 DMI 模块中评价对象的注意力权重分布来作为每个词的领域自适应的权重,从而实现选择性对抗学习。我们将两个用于迁移学习的模块放置于两层 LSTM 的中间,这是因为底层的用于预测评价对象边界的任务相比于高层用于预测评价对象边界+情感极性复杂任务更容易进行迁移 [8] [9]。
主要结果
我们在 4 个基准数据集 Laptop (L) [10], Restaurant (R) [10], Device (D) [10] 和 Service (S) [11] 上进行了实验。其中 Laptop,Restaurant 来自于 SemEvalABSA challenge。我们在此上面构建 10 个类似于 D_s->D_t 迁移的任务,其中由于 D 与 L 领域非常的相似,我们不使用 L->D 和 D->L。
由于我们是第一个在 E2E-ABSA 问题下进行迁移学习的探索,因为我们不得不将之前用于跨领域评价对象的抽取的 SOTA 方法(TCRF,Hier-Joint),以及跨领域评价对象与观点词抽取的 SOTA 方法(RAP, RNSCN)应用到我们任务上来。
这些方法高度依赖先验知识(手工设计的规则)或外部语言资源(依存关系语法分析)来挖掘共享的评价对象与观点词的句法模式进行迁移。与此不同,我们的方法通过自动的挖掘它们间隐藏的关系,并且利用选择性对抗学习得到更好的领域间共享的关系特征表达,从而取得非常大的性能提升。
为了更加具有说服力,我们将两种深度学习的方法 Hier-Joint 与 RNSCN 扩展成了相同的堆叠式 base 模型 Hier-Joint+,RNSCN+。可以发现,我们的模型仍然显著的超越了扩展模型。

为了验证各个模块的作用,我们进行了大量的消融实验,主要分为以下:
1. 有 DMI v.s. 无 DM:结果可见 Base Model (SO) 与 Base Model+DMI 的差别;
2. 有 SAL v.s. 无 SAL:结果可见 Base Model+DMI 与 AD-SAL 的差别;
3. 有选择性 v.s. 无选择性:结果可见 AD-AL 与 AD-SAL 的差别;
4. 底层任务迁移 v.s. 高层任务迁移:结果可见 ADS-SAL 与 AD-SAL 的差别。

我们可以得出以下结论:
1. DMI 自动的捕获评价对象与观点词来作为领域间可以迁移的知识,有效的充当了领域间的桥梁;
2. SAL 通过选择性对抗学习,使得领域自适应的方法(对抗学习)能够在序列预测任务上有了非常显著的提升,这给其它序列预测任务上进行迁移带来很好的启发性;
3. 底层简单任务(特征)比高层复杂任务(特征)更容易迁移。
本小节参考文献
[1] John Blitzer, Mark Dredze, and Fernando Pereira. 2007.Biographies, bollywood, boom-boxes and blenders: Domain adaptation for sentiment classification. In ACL, pages 440–447.
[2] Xin Li, Lidong Bing, Piji Li, and Wai Lam. 2019a. A unified model for opinion target extraction and target sentiment prediction. In AAAI,pages 6714–6721.
[3] Niklas Jakob and Iryna Gurevych. 2010. Extracting opinion targets in a single-and cross-domain setting with conditional random fields. In EMNLP, pages 1035–1045.
[4] Ying Ding, Jianfei Yu, and Jing Jiang. 2017. Recurrent neural networks with auxiliary labels for cross domain opinion target extraction. In AAAI, pages 3436–3442.
[5] Fangtao Li, Sinno Jialin Pan, Ou Jin, Qiang Yang, and XiaoyanZhu. 2012. Cross-domain co-extraction of sentiment and topic lexicons. In ACL, pages 410– 419.
[6] Wenya Wang and Sinno Jialin Pan. 2018. Recursive neural structural correspondence network for cross domain aspect and opinion co-extraction. In ACL, pages 2171–2181.
[7] Yaroslav Ganin, Evgeniya Ustinova, Hana Ajakan, Pascal Germain, Hugo Larochelle, Franc ̧ois Laviolette, Mario Marchand, and Victor Lempitsky.2016. Domain-adversarial training of neural networks. JMLR, pages 2096–2030.
[8] Jason Yosinski, Jeff Clune, Yoshua Bengio, and HodLipson. 2014. How transferable are features in deep neural networks? In NIPS, pages 3320–3328.
[9] Lili Mou, Zhao Meng, Rui Yan, Ge Li, Yan Xu, LuZhang, and Zhi Jin. 2016. How transferable are neural networks in NLP applications? In EMNLP, pages 479–489.
[10] Minqing Hu and Bing Liu. 2004. Mining and summarizing customer reviews. In KDD, pages 168–177.
[11] Cigdem Toprak, Niklas Jakob, and IrynaGurevych. 2010. Sentence and expression level annotation of opinions in user-generated discourse. In ACL, pages 575–584.
Aspect Sentiment Triplet Extraction (ASTE) 任务
本小节工作来自论文:
Knowing What, How and Why: A Near Complete Solution for Aspect-based Sentiment Analysis, In AAAI 2020.


数据链接:https://github.com/xuuuluuu/SemEval-Triplet-data
问题定义
如前述,opinion term 和其描述的 aspect 以及 sentiment 高度相关。如果在抽取出 aspect 及预测出sentiment 同时,能给出表明该 sentiment 的 opinion term,将会使结果更加完整:aspect 给出了带有情感的评论目标,sentiment 给出了对目标的情感极性,opinion term 给出了情感的原因,这三者依次回答了What(对于什么),How(情感怎么样)以及 Why(为什么是这个情感)三个问题,对于评论目标构成更全面的分析。
正如开篇所讲述的那个例子,“Waiters are very friendly and the pasta is simply average.”,提到了两个评论目标:“waiter”和“pasta”。在理解目标的情感极性之上,知道导致情感的原因,既“friendly”和“average”,在现实场景中更具有实用性和指导性。
本工作中第一次定义了 Aspect Sentiment Triplet Extraction (ASTE) 任务。这个Triplet Extraction(三元组抽取)任务旨在抽取评论中出现的所有 aspect,对应的 sentiment 以及对应的 opinion term,并完成三者的匹配工作,形成(aspect, sentiment, opinion term)的三元组,如上例中的(waiter, Positive, friendly)和(pasta, Negative, average)。
相关方法的局限
正如开篇关于评论目标情感分析任务的总览图所示,本工作之前尚未有研究 Aspect Sentiment Triplet Extraction (ASTE) 任务的的工作。
之前的工作最多研究了两个原子任务的结合:例如 aspect term extraction 和 sentiment classification 的结合 [1] [2],aspect term 和 opinion term 的联合抽取 [3] [4],aspect category 和 sentiment classification 的结合 [5]。[6] 尝试针对已知 aspect 进行 opinion term 抽取,[7] 的模块化系统也仅进行 aspect term extraction 和 sentiment classification,未提取 opinion term。
我们的模型
我们的设计采用了二阶段模型,如下模型图所示。 第一阶段模型(stage one)主要分为两个部分:1)预测所有评论目标词以及目标词的情感极性;2)预测所有可能描述目标词的情感词。
目标词以及带有其情感极性的标签主要由第一阶段模型的左侧结构标注得出。句子向量通过第一层 Bi-LSTM 会进行一次序列预测来确定评论目标的范围,然后加以模型右侧图卷积网络(GCN)返回的情感词信息辅助输入第二层 Bi-LSTM 进行二次序列预测,由此获得带有情感极性的标签。
描述目标词的情感词由模型第一阶段的右侧结构预测。具体地,句子向量首先通过两层图卷积网络加以模型左侧结构输出的主题词范围来确定相关的情感词。然后将图卷积网络的隐状态输入 Bi-LSTM 层来进行情感词标签的预测。
第一阶段模型是基于前述 E2E-ABSA 工作的改进。第二阶段模型(stage two)对第一阶段模型左侧输出的带情感的目标词和右侧输出的情感词进行配对。首先我们枚举可能出现的配对,加之文本信息以及目标词和情感词之间的距离信息通过分类器来确定哪些是有效的组合。

主要结果
我们在现有 SemEval 14 Laptop 和 14,15,16 Restaurant 数据集上进行了补充标注。我们将同一个句子具有不同 aspects 和 opinons 标注的情形合并在一起,每个合成的数据包含原始句子,aspect 标注和 opinion 标注,并将它们配对,例如:
The best thing about this laptop is the price along with some of the newer features.
The=O best=O thing=O about=O this=Olaptop=O is=O the=O price=T-POS along=O with=O some=O of=O the=O newer=Ofeatures=TT-POS .=O
The=O best=S thing=O about=O this=Olaptop=O is=O the=O price=O along=O with=O some=O of=O the=O newer=SSfeatures=O .=O
上例中包含两个 aspect-opinion 对:‘price’—‘best’和‘feature’ —‘newer’。我们同时也清除了少量的 aspect 标注和 opinion 标注有重合的数据。最终数据集统计如下:
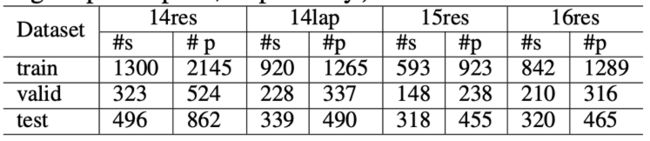
实验上,我们对模型的两阶段分别进行了验证。我们首先针对一阶段 unified aspect extraction 和 sentiment classification 进行了验证,结果如下表。

我们的模型及变种全部优于现有方法,仅在 14lap 上稍逊于我们改进的 Li-unified [1] 方法。另外我们发现 RINANTE 和 CMLA 的实验结果较原文均大幅下滑,为公平起见,我们增设了最后两行的对比实验,参考以原文同样的实验设置。结果显示效果显著上升,一方面证明了我们复现的可靠性,另一方面佐证了三元组抽取任务的高难度。
接下来,我们针对一阶段 opinion term extraction 进行了验证,结果如下表。我们的模型稳定地优于现有方法及其改进。证明了我们利用 aspect extraction 和 sentiment classification 来辅助 opinion term extraction 的设计的有效性。

最后我们进行了二阶段的验证实验,结果如下图。其中 pair 代表 aspect-opinion 的配对结果,triplet 代表 aspect-opinion-sentiment 的三元组结果。在 triplet 结果上,我们的模型一致性的优于其他现有方法。在 pair 的结果上,整体上对现有方法具有明显优势。

以上方法的缺点在于第一和第二阶段是割裂开的,会导致 error propagation 的问题,一个很自然的改进思路便是如何将两阶段模型改进为 End-to-End 的方式。这是很值得尝试的一个研究点。
本小节参考文献
[1] Xin Li, Lidong Bing, Piji Li, and Wai Lam. 2019a. A unified model for opinion target extraction and target sentiment prediction. In AAAI, pages 6714–6721.
[2] He, R.; Lee, W. S.; Ng, H. T.; and Dahlmeier, D. 2019. An interactive multi-task learning network for end-to-end aspect-based sentiment analysis. In ACL.
[3] Wang, W.; Pan, S. J.; Dahlmeier, D.; and Xiao, X. 2017. Coupled multi-layer attentions for co-extraction of aspect and opinion terms. In AAAI,3316–3322.
[4] Dai, H., and Song, Y. 2019. Neural aspect and opinion term extraction with mined rules as weak supervision. In ACL, 5268–5277.
[5] Hu, M.; Zhao, S.; Zhang, L.; Cai, K.; Su, Z.; Cheng, R.; and Shen, X. 2018. Can: Constrained attention networks for multi-aspect sentiment analysis. arXiv preprint arXiv:1812.10735.
[6] Fan, Z.; Wu, Z.; Dai, X.; Huang, S.; and Chen, J. 2019.Target-oriented opinion words extraction with target-fused neural sequence labeling. In NAACL-HLT, 2509–2518.
[7] Zhang, X., and Goldwasser, D. 2019. Sentiment tagging with partial labels using modular architectures. arXiv preprint arXiv:1906.00534.
总结
情感分析作为自然语言理解里最重要也是最有挑战的主要任务之一,有很大的研究空间和广阔的应用价值。细粒度的情感分析(i.e. ABSA)的相关研究已历经多年,有大量的相关论文发表。
目前,这个方向的研究有两个明显的局限。一是已有数据小、标注不完备,导致更实用的任务无法进行。例如 ASTE 任务,其可行性依赖于对已有数据进行额外打标。二是跨语言、跨领域迁移能力的研究不足,导致研究工作的实际可用性差。
虽然目前基于 BERT 等大规模深度语言模型的尝试,显示出了不错的潜力,但深度语言模型本身的部署还没有很好解决。另外,情感分析离不开常识和场景,目前主流 NN 方法所欠缺在这些方面的建模能力。
本文由阿里巴巴达摩院的邴立东及其实习生李昕、合作者李正、同事彭海韵、联培博士生许璐等共同整理而成。由 PaperWeekly 编辑进行了校对和格式调整。

点击以下标题查看更多期内容:
AAAI 2020 | 语义感知BERT(SemBERT)
从Word2Vec到BERT
任务导向型对话系统:对话管理模型研究最新进展
后BERT时代的那些NLP预训练模型
BERT的成功是否依赖于虚假相关的统计线索?
从三大顶会论文看百变Self-Attention
 #投 稿 通 道#
#投 稿 通 道#
让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
???? 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
???? 投稿邮箱:
• 投稿邮箱:[email protected]
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
????
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。
▽ 点击 | 阅读原文 | 获取最新论文推荐