一、简述systemd的新特性及unit常见类型分析,能够实现编译安装的如nginx\apache实现通过systemd来管理
Systemd概述
1.systemd是一种新的linux系统服务管理器,用于替换init系统,能够管理系统启动过程和系统服务,一旦启动起来,就将监管整个系统。在centos7系统中,PID1被systemd所占用;
2.systemd可以并行地启动系统服务进程,并且最初仅启动确实被依赖的服务,极大减少了系统的引导时间,这也就是为什么centos7系统启动速度比centos6快许多的原因;
3.systemctl 是 systemd 的主命令,用于管理系统及服务
systemd的新特性:
- 在系统引导时实现服务并行启动;
- 能按需激活进程;
- 能做系统状态快照;
- 基于依赖关系定义服务控制逻辑;
关键特性:(了解systemd的工作)
- 基于socket的激活机制:socket与程序分离;
- 基于bus的激活机制;
- 基于设备device的激活机制:
能监控内核输出的硬件信息,当设备插入时一旦发现就创建设备文件,再自动挂载至某挂载点,如果挂载点不存在还能自动创建 - 基于path的激活机制:
系统可监控某目录或文件是否存在,如果文件在了立即就能激活一个服务或进程;例如某服务运行中突然崩溃,崩溃时能创建一个log或lock文件;一旦发现这个lock文件立即激活一个程序如发送报告 - 系统快照:
能保存各unit的当前状态信息于持久存储设备中; 因为systemd的所有管理都是通过unit实现的,回滚时使用 - 向后兼容sysv init脚本:
所以放在/etc/init.d/服务脚本也一样能靠systemd来启动
不兼容:
- systemctl的命令是固定不变的;
不能自定义命令,旧版能自定义如start、stop等命令,在脚本中可随意定义命令使用;而systemctl的命令是固定不变的 - 非由systemd启动的服务,systemctl无法与之通信,无法控制此服务;
例如启动web进程httpd,直接在命令行键入httpd也能启动,这种服务在CentOS 5和6上使用servcie httpd stop有时也能停掉服务,但是systemd就不行,但可自定义unit脚本来实现
systemd核心概念:unit
unit由其相关配置文件进行标识、识别和配置;文件中主要包含了系统服务、监听的socket、保存的快照以及其他与init相关的信息;这些配置文件主要保存在:
/usr/lib/systemd/system
/run/systemd/system
/etc/systemd/system
- unit的常见类型
| unit单元 | 文件扩展名 | 解释说明 |
|---|---|---|
| Service unit | .service | 定义系统服务 |
| Target unit | .Target | 用于模拟实现"运行级别" |
| Device unit | .device | 定义内核识别的设备 |
| Mount unit | .mount | 定义文件系统挂载点 |
| Socket unit | .socket | 标识进程间通信用到的socket文件 |
| Snapshot unit | .snapshot | 管理系统快照 |
| Swap unit | .swap | 标识swap设备 |
| Automount unit | .automount | 文件系统自动挂载点设备 |
| Path unit | .path | 定义文件系统中的一文件或目录 |
CentOS 7管理系统服务service unit:
Control the systemd system and service manager
systemctl [OPTIONS...] COMMAND [NAME...]
| 动作 | CentOS 6 | CentOS 7 |
|---|---|---|
| 启动 | service NAME start | systemctl start NAME.service |
| 停止 | service NAME stop | systemctl stop NAME.service |
| 重启 | service NAME restart | systemctl restart NAME.service |
| 状态 | service NAME status | systemctl status NAME.service |
| 条件式重启 | service NAME condrestart | systemctl try-restart NAME.service |
| 重载或重启 | systemctl reload-or-restart NAME.service | |
| 重载或条件式重启 | systemctl reload-or-try-restart NAME.service | |
| 查看某服务当前激活与否的状态 | systemctl is-active NAME.service | |
| 查看所有已激活的服务 | systemctl list-units --t service | |
| 查看所有服务(包含未激活) | chkconfig --list systemctl list-units -t NAME.service -a | |
| 设置服务开机自启 | chkconfig NAME on | systemctl enable NAME.service |
| 禁止服务开机自启 | chkconfig NAME off | systemctl disable NAME.service |
| 查看某服务是否能开机自启 | chkconfig --list NAME | systemctl is-enabled NAME.service |
| 禁止某服务设定为开机自启 | systemctl mask NAME.service | |
| 取消此禁止 | systemctl umask NAME.service | |
| 查看服务依赖关系 | systemctl list-dependencies NAME.service |
管理target units:
- 运行级别:
| 运行级别 | 对应别名 | 服务名 |
|---|---|---|
| 0 | runlevel0.target | poweroff.target |
| 1 | runlevel1.target | rescue.target |
| 2 | runlevel2.target | multi-user.target |
| 3 | runlevel3.target | multi-user.target |
| 4 | runlevel4.target | multi-user.target |
| 5 | runlevel5.target | graphical.target |
| 6 | runlevel6.target | reboot.target |
service unit文件组织格式:
文件通常由三段组成:
[Unit]:主要定义与Unit类型无关的通用选项;用于提供当前unit的描述信息、unit行为及依赖关系;
[Service]:与特定类型相关的专用选项;此处为service类型;
(UNIT-TYPE,类似是什么就为相对应的名称)
[Install]:定义由"systemctl enable"以及"systemctl disable"命令在实现服务启用或禁用时用到的一些选项;
各部分释义:
- [Unit] 段的常用选项:
Description:描述信息; 意义性描述;
After:定义unit的启动次序,表示当前unit应该晚于哪些unit启动;其功能与Before相反;
Requies:依赖到的其它units;强依赖,被依赖的units无法激活时,当前unit即无法激活;
Wants:依赖到的其它units;弱依赖;
Conflicts:定义units间的冲突关系 - [Service] 段的常用选项:
Type:用于定义影响ExecStart及相关参数的功能的unit进程启动类型,其类型有:
simple:默认值,执行ExecStart指定的命令,启动主进程
forking:以 fork 方式从父进程创建子进程,创建后父进程会立即退出
oneshot:一次性进程,Systemd 会等当前服务退出,再继续往下执行
dbus:当前服务通过D-Bus启动
notify:当前服务启动完毕,会通知systemd再继续往下执行
idle:若有其他任务执行完毕,当前服务才会运行
EnvironmentFile:环境配置文件;
ExecStart:指明启动unit要运行命令或脚本;
ExecStartPre:在ExecStart之前运行;
ExecStartPost:在ExecStart之后运行;
ExecStop:指明停止unit要运行的命令或脚本;
Restart:当设定Restart=1时,则当次daemon服务意外终止后,会再次自动启动。 - [Install] 段的常用选项:
Alias:别名,可使用systemctl command Alias.service;
RequiredBy:被哪些units所依赖;
WantedBy:被哪些units所依赖 注意:对于新创建的unit文件或修改了的unit文件,要通知systemd重载此配置文件,通过命令 systemctl daemon-reload
编译安装nginx\apache,并通过systemd来管理
第一步--安装nginx基础依赖包并创建用户
[root@wujunjie ~]# yum install pcre pcre-devel.x86_64 openssl-devel.x86_64 -y
[root@wujunjie ~]# useradd nginx
[root@wujunjie ~]# echo nginx|passwd --stdin nginx
第二步--下载nginx并编译安装
[root@wujunjie ~]#官网下载nginx包
[root@wujunjie tools]# tar -xf nginx-1.14.0.tar.gz
[root@wujunjie tools]# ls
nginx-1.14.0 nginx-1.14.0.tar.gz
[root@wujunjie tools]# cd nginx-1.14.0/
[root@wujunjie nginx-1.14.0]# ./configure --user=nginx --group=nginx --prefix=/usr/local/nginx1.4/ --with-http_stub_status_module --with-http_ssl_module
[root@wujunjie nginx-1.14.0]# make && make install
第三步--编辑配置文件
[root@wujunjie ~]# cd /usr/lib/systemd/system
[root@wujunjie system]# vim nginx.service
[unit]
Description=nginx
After=network.target
[Service]
Type=forking
ExecStart=/usr/local/nginx1.4/sbin/nginx
ExecReload=/usr/local/nginx1.4/sbin/nginx -s reload
ExecStop=/usr/local/nginx1.4/sbin/nginx -s stop
[Install]
WantedBy=multi-user.target
第四步--最后重启;关闭nginx
[root@wujunjie ~]# systemctl daemon-reload #重新载入
[root@wujunjie ~]# systemctl start nginx.service
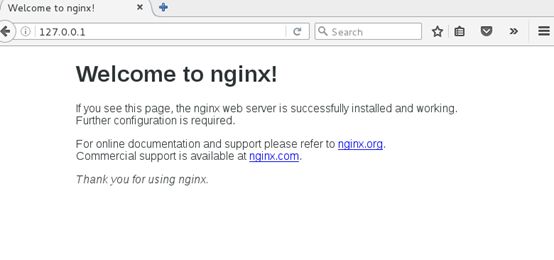
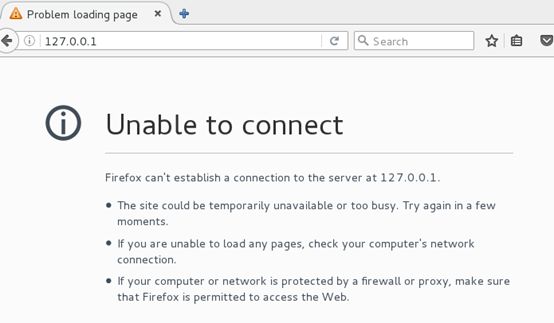
[root@wujunjie ~]# systemctl reload nginx.service
[root@wujunjie ~]# systemctl stop nginx.service
二、描述awk命令用法及示例(至少3例)
简介
awk是一个强大的文本分析工具,相当于grep的查找,sed的编辑,awk在其对数据分析并生成报告时,显得尤为强大。awk就是把文件逐行读入,以空格为默认分隔符将每行切片,切开的部分再进行各种分析处理。基本用法:
gawk [options] 'program' FILE ...
program: PATTERN{ACTION STATEMENTS}
PATTERN:模式有多种,有地址定界作用,不同于sed或grep里面的概念;
ACTION STATEMENTS:动作语句,可有多个语句,但语句之间用分号分隔;可认为是脚本里的调用命令,这不过用的是awk内建命令;如:print, printf(格式化输出)选项:
-F:指明输入时用到的字段分隔符;
-v VAR=VALUE: 自定义变量;-
awk的基本处理机制
一次从文件中读取一行文本,awk会对其自动进行切片,将每一行按字符串的分隔符进行切割。如这一行是this is a test,它会默认使用空白字符当分隔符,不管空了几个格,这样这一行就会成四片,一片中保存一个单词,而这四片在awk中可以使用一个变量来引用,这个变量相关于脚本中的位置参数$1,$2... ,$0表示这一整行。awk默认使用空白当分隔符,也可以指定分隔符。
1、printprint item1, item2, ... -
要点:
(1) 逗号分隔符;
(2) 输出的各item可以字符串,也可以是数值;当前记录的字段、变量(2,..)或awk的表达式;
(3) 如省略item,相当于print $0; 即$0代表一整行内容,默认显示就为$0即整行内容;
例:[root@wujunjie ~]# vim 12 this is a,test [root@wujunjie ~]# awk '{print $1,$2}' 12 this is [root@wujunjie ~]# awk -F, '{print $1}' 12 this is a [root@wujunjie ~]# awk '{print $0}' 12 this is a,test
2、变量
2.1内建变量
常用内置变量之记录变量
FS:input field seperator,输入分隔符,默认为空白字符;
OFS:output field seperator,输出分隔符,默认为空白字符;
RS:input record seperator,输入时的换行符;一行为一条record;默认为行分隔符;
ORS:output record seperator,输出时的换行符;一行为一条record;默认为行分隔符;-
awk内置变量之数据变量
NF:number of field,字段数量,即每行的字段数量;
注意:{print NF}, {print $NF}的区别;
NR:number of record, 行数;即对文件中的行进行编号;
FNR:各文件分别计数;行数;
FILENAME:当前文件名;即显示每行的文件名;
ARGC:命令行中参数的个数;
ARGV:数组,保存的是命令行中所给定的各参数;
例:[root@wujunjie ~]# awk '{print NF}' /etc/issue 1 5 0 显示issue文件中每一行有多少字段; [root@wujunjie ~]# awk '{print NR}' /etc/issue 1 2 3 统计行数,显示行号; [root@wujunjie ~]# awk '{print NR}' 12 /etc/issue 1 2 3 4 显示内容:两文件的总行数; [root@wujunjie ~]# awk '{print FNR}' 12 /etc/issue 1 1 2 3 显示内容:两文件分别显示行数;
2.2自定义变量
(1) -v VAR=VALUE变量名区分字符大小写;
(2) 在program中直接定义
注意:定义变量,同bash中一样,用时定义即可;
[root@wujunjie ~]# awk -v test='hello gawk' '{print test}' /etc/issue
hello gawk
hello gawk
hello gawk
文件此处没什么用,只有一个显示行数作用;即文件有12行显示了每行显示一次,显示了3行;
3、printf命令(格式化输出命令)
printf FORMAT, item1, item2, ...
FORMAT是格式符,为每个item按位占一个位留一个特殊符号,所以item最终会显示在format指定格式符号的位置上;
-
要点:
(1) FORMAT必须给出;
(2) 在显示多行文本时,不会自动换行,需要显式给出换行控制符,\n;
(3) FORMAT中需要分别为后面的每个item指定一个格式化符号;
格式符:
%c: 显示字符的ASCII码;
%d, %i: 显示十进制整数;decimal,integer;
%e, %E: 科学计数法数值显示;
%f:显示为浮点数;
%g, %G:以科学计数法或浮点形式显示数值;
%s:显示字符串;
%u:无符号整数;
%%: 显示%自身;
例:[root@wujunjie ~]# head -3 /etc/passwd|awk -F: '{printf "%s\n",$1}' root bin daemon 以字符串显示每行的第1字段;每字段一行; [root@wujunjie ~]# head -3 /etc/passwd|awk -F: '{printf "username:%s\n",$1}' username:root username:bin username:daemon 显示指定字符串即username:,同时以字符串显示每行的第1字段;每字段一行;
修饰符:
#[.#]:第一个数字控制显示的宽度;第二个#表示小数点后的精度;默认右对齐;
%3.1f:3表示显示3个字符的宽度;
-: 左对齐
+:显示数值的符号
4、操作符
算术操作符:
x+y, x-y, x*y, x/y, x^y(x的y次方), x%y(取模)
-x:把整数转为负数;
+x: 把字符串转换为数值;
字符串操作符:
没有符号的操作符,字符串连接(一般使用内建函数进行字符串切片)
赋值操作符:
=, +=, -=, *=, /=, %=, ^=(增强相赋值)
++, --(自增、自减运算)
比较操作符:
>, >=, <, <=, !=, ==(等值比较)
模式匹配符:
~:左侧字符串是否能被右侧模式匹配;
!~:左侧字符串是否不能被右侧模式匹配;
逻辑操作符:将多个操作连接起来;
&& 与运算
|| 或运算
! 非运算
函数调用:(这才是规范使用方式)
function_name(argu1, argu2, ...)
条件表达式:
selector?if-true-expression:if-false-expression
5、PATTERN(实现地址定界功能)
(1) empty:空模式,匹配每一行;
(2) /regular expression/:仅处理能够被此处的(正则表达式)模式匹配到的行;前面加!表示对模式过滤的条件取反;
(3) relational expression: 关系(比较)表达式;结果有“真”有“假”;结果为“真”才会被处理;
真:结果为非0值,非空字符串;
假:0,空字符串;
(4) line ranges:行范围,
/pat1/,/pat2/:startline,endline表示地址定界;
注意: 不支持直接给出数字的格式
~]# awk -F: '(NR>=2&&NR<=10){print $1}' /etc/passwd
(5) BEGIN/END模式
BEGIN{program}: 仅在开始处理文件中的文本之前执行一次程序;显示表头;
END{program}:仅在文本处理完成之后命令结束之前执行一次程序;
6、常用的action
(1) Expressions
(2) Control statements:if, while等;
(3) Compound statements:组合语句;
(4) input statements
(5) output statements
7、控制语句
if(condition) {statments}
if(condition) {statments} else {statements}
while(conditon) {statments}
do {statements} while(condition)
for(expr1;expr2;expr3) {statements}
break
continue
delete array[index]
delete array
exit
{ statements }
7.1 if-else语句,支持双分支if语句,完成条件判断;
语法格式:if(condition) statement [else statement]
语句如果有多个,需要用{}括起来;如果有else语句,各语句都要用{};
使用场景:对awk取得的整行或某个字段做条件判断时使用;
7.2 while循环
语法格式:while(condition) statement
条件“真”,进入循环;条件“假”,退出循环;语句如果有多个,需要用{}括起来;
要根据初始条件判断为真或假,如果为假,则一次都不会执行;
使用场景:对一行内的多个字段逐一进行类似处理时使用;或对数组中的各元素逐一处理时使用;
7.3 do-while循环
语法:do statement while(condition)
7.4 for循环
语法格式:for(expr1;expr2;expr3) statement
expr1:控制变量初始化;
expr2:条件判断;
expr3:控制变量的数值修正表达式;
for(variable assignment;condition;iteration process) {for-body}
即:for(变量赋值;条件判断表达式;变量修正表达式) {循环体语句} 意义:无论条件真假,先执行一次,即至少执行一次循环体
7.5 switch语句(在awk中用的不多)
语法格式:
switch(expression) {case VALUE1 or /REGEXP1/: statement1; case VALUE2 or /REGEXP2/: statement2; ...; default: statement}
7.6 break和continue(不做详细介绍,用到时再说)
break [n]:退出n层循环;
continue:提前结束本轮循环,直接进入下一轮循环(即下一个字段);
7.7 next
在awk中能实现2重循环,awk本身可对文件每行循环,使用循环语句是为了遍历一行中的每个字段,或数组中的每个元素;
next同continue一样,也是控制循环的,但是是控制awk的本身循环的;即提前结束对本行的处理而直接进入下一行;
8、array数组
关联数组:array[index-expression]
index-expression:索引表达式
(1) 可使用任意字符串;字符串要使用双引号;不能随便使用单引号;
(2) 如果某数组元素事先不存在,在引用时,awk会自动创建此元素,并将其值初始化为“空”;允许未经声明直接引用;
若要判断数组中是否存在某元素,要使用"index in array"格式进行;
三、描述awk函数示例(至少3例)
-
3.1内置函数
数值处理:
rand():返回0和1之间一个随机数;在大多数awk实现中,包括gawk,每次运行awk时,rand()都会从相同的起始数字或种子开始生成数字。因此,程序每次运行时都会产生相同的结果。在一个AWK运行中,这些数字是随机的,但从运行到运行是可以预测的。这便于调试,但如果希望程序每次使用时都执行不同的操作,则必须将种子更改为每次运行中不同的值。要做到这一点,使用srand()例如: [root@wujunjie ~]# awk 'BEGIN{print rand()}' 0.237788 [root@wujunjie ~]# awk 'BEGIN{print rand()}' 0.237788 [root@wujunjie ~]# awk 'BEGIN{srand();print rand()}' 0.343 [root@wujunjie ~]# awk 'BEGIN{srand();print rand()}' 0.0389058
字符串处理:
length([s]):返回指定字符串的长度;
sub(r,s,[t]):以r表示的模式来查找t所表示的字符中的匹配的内容,并将其第一次出现替换为s所表示的内容;
例如:
[root@wujunjie ~]# awk -F: '{sub(o,O,$1)}' /etc/passwd
把每行的第1字段中,第一次出现的小写o替换为大写O;注意:仅替换每行一次出现的;
gsub(r,s,[t]):以r表示的模式来查找t所表示的字符中的匹配的内容,并将其所有出现的内容均替换为s所表示的内容;
split(s,a[,r]):以r为分隔符切割字符s,并将切割后的结果保存至a所表示的数组中;数组元素从1开始编号;
例如:
[root@wujunjie ~]# netstat -tan | awk '/^tcp\>/{split($5,ip,":");count[ip[1]]++}END{for (i in count) {print i,count[i]}}'
192.168.32.1 1
0.0.0.0 6
显示来访的主机地址连接的次数;
- 3.2自定义函数
可参考《sed和awk》