专家视野 | 牟宇航:百度OLAP数据库——Palo
https://mp.weixin.qq.com/s/q8_kdDPdCPwIjI2BCETPZw
3月28日,在工业和信息化部的指导下,为期两天的“2017大数据产业峰会”在北京国际会议中心召开。本次会议由中国信息通信研究院和中国通信标准化协会共同主办,数据中心联盟大数据发展促进委员会承办。
百度研发经理牟宇航在29日上午大数据产品和应用创新论坛上发表了题为《百度OLAP数据库——Palo》的演讲。

以下是内容实录:
大家好,我叫牟宇航,来自百度大数据部。现在负责百度大数据部在线系统的研发管理,在线系统简单来说就是大家用的数据库。今天来这里给大家分享一个在云上售卖了一年,而且准备开源的数据库。

在讲数据库之前先给大家讲一下我们面向的场景,第一个是百度统计,是为其他第三方站长提供流量分析的工具。它的形式是提供一个脚本,其他的站长嵌入到自己的网站代码里面,最后百度会通过这个脚本获取第三方网站的用户行为,然后出第三方网站的分析报表。这个产品量非常大,首先有450W网站站长去使用它,它的查询频率非常大,基本上峰值OPS会到2000以上。数据量也非常大,我们初步统计了一下每天结构化的数据会到1-2T。
这种场景是在线报表场景,可以看到左侧栏是主题,右侧栏包括了指标列和过滤条件,比如说可以根据时间过滤,可以根据其他方式过滤,每个主题是不一样的。
第二个场景是我们经常在业务上会出现的一个场景,就是数据集市。数据集市一般面向业务为主题,这里举例是百度糯米的数据集市,它是集运营、业务分析、订单管理、会员管理、客户关系、管理等一体的综合数据平台。这种数据集市场景多样化,一方面刚刚提到的在线报表,比如说渠道人员想看一下几个渠道的运维情况,这有一个报表。再有产品经理想多维分析下产品传单的情况。比如说新上线一个活动,运维人员想看一下新上线活动的情况,它的查询非常灵活。
在这种数据集市里面除了场景比较复杂,另外使用它的角色很多,所以这个里面涉及到多租户的管理。
这里拿了另外一个多维分析系统,初步看它的样子跟在线报表比较像,如果仔细看会不一样。它的左侧栏是个维度,包括像操作系统、时间浏览器维度,这些维度可以下展很多级别。右边这些栏首先是查询指标,另外是过滤维度的条件。

这种场景是典型的在线多维分析场景,以上三种场景就是今天要讲的数据库Palo的主要场景,在线报表、多维分析、机器查询。这个名字很好记,当时想这个名字就是面向多维分析的数据库,用一句话形容Palo就是A:MPP-based Interactive Data Analysis SQL DB。面向数据量是百TB到PB级别。
讲了这么多的OLAP,OLAP概念分为两个维度,第一个是中间的A,A相当于Transactional Processing。第二个维度是Online相当于Offline,下面列了一张图但凡所有的大数据应用和面向C端B端的架构都是这样的架构,首先前端是客户端,后面是服务端。

App Client加上App Server再加上Transaction,在大数据时代产生了很多数据,我们希望把这些数据提取出来,挖掘其中的价值,这就是AP角色的事情,它可以做很多的事情,可以做转换,可以做数据挖掘,这都是广义的概念。在大数据时代,AP变得越来越重要,变得越来越庞大。TP核心价值在于业务逻辑,AP核心逻辑在数据本身,我们要从数据本身挖掘更多的价值。OLAP是面向AP的,这个里面也提了在线概念。拿购物举例,离线像仓库的概念,在线像小超市的概念。离线面向数据开发人员和数据建设者,在线面向数据消费者,比如说产品经理、管理者、营销人员、运维人员,可能他不太懂数据怎么玩,但是用了这个系统就会玩了。我们看到在大数据时代越来越多人使用数据,在线这一部分的重要性变得越来越重要。
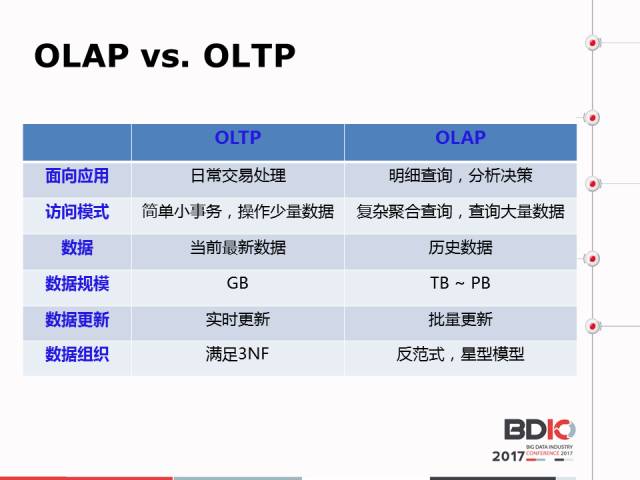
这个里面详细列举了一下OLAP和OLTP的区别,OLAP的场景比如说分析一个全量的历史数据,这个历史数据可能涉及一年可能涉及很多,它的数据量会非常大,数据量大也就导致很多不一样,比如说导入方式、侧重点,我们评估OLAP性能的方式不太一样。最后是数据组织,一般来讲OLTP是完全遵循三范式的,而OLAP就不一样,它是五范式的。
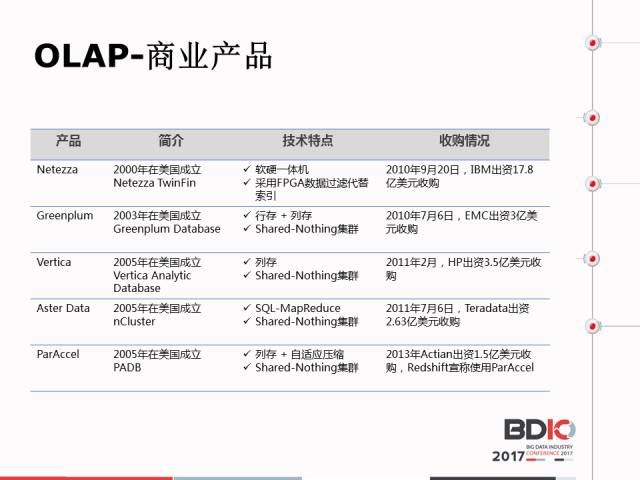
刚才提到AP在大数据时代变得越来越重要,在2000年之后整个业界在AP领域涌现出来了知名的数据厂商和数据产业。
在开源界大概在2010年左右发力,这里介绍了Palo的区别和定位。首先,最显著的区别是Palo的成本比较低,那些看到的开源产品基本是在百万美元的量级,一套产品就这么贵。而Palo用的是普通的X86服务器,百度统计的业务也不过用了60台,大家可以算一下这个成本很大的。
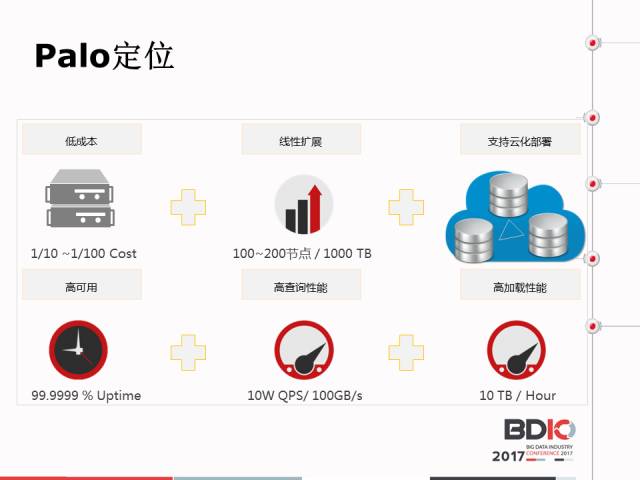
第二个是Palo的高可用和异用性,还有高性能,这是我们和其他竞品最核心的区别。


在讲Palo之前,我们先看Palo是怎么用的?长什么样子?首先我们在MySQL 的选择上语句不同,包括会增加一些在MySQL 比较有用的语句。这些增加的语句怎么用呢?我们通过直接输入XP就能看到语句包括参数怎么使用。上面是Palo,因为兼容MySQL协议。
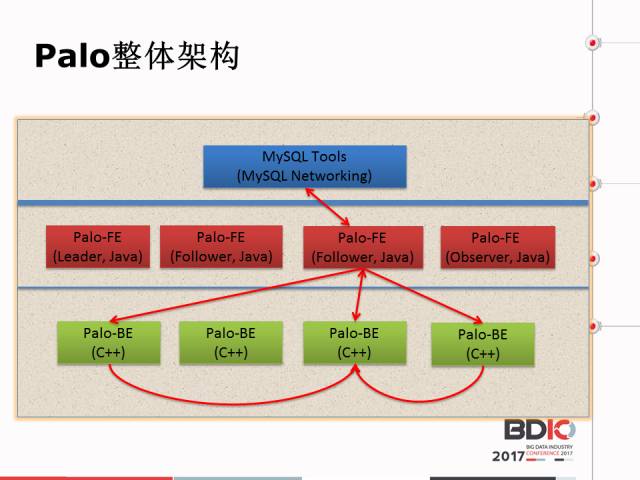
言归正传,看一下Palo的架构。首先说一下Palo的设计理念,Palo的设计理念强调要优雅、简洁,这个里面大家看我们的架构很简单,每个颜色代表一个进程,蓝色是客户端,不是Palo内部的东西。在这里面我们部署时前端和后端是分离的,在部署时一台机器上只需要部属一个进程就可以了,部署非常简单。前端首先负责源数据的管理,前端还可以负责接收产品请求,包括建表、建数据库,包括数据导入、管理,包括复本管理,数据请求。包括查询界定都是在前端完成的。比方说,前端是Palo的大脑,后端是Palo的躯干,可以干活。一般来讲前端节点稍微少一点,后端节点比较多。
为什么前端节点有3-10个呢?为什么不是10个呢?相当于元数据的架构,这个里面列了元数据的管理架构。
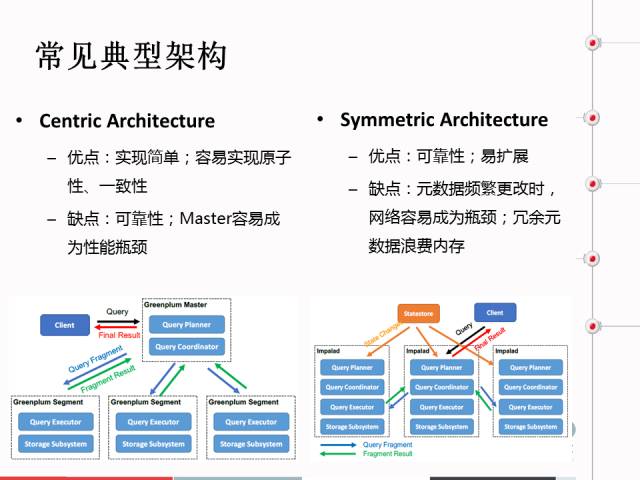
第一个是中心架构,最典型的代表最近开源很火的,它的优点:第一,实现很简单,这是中心架构。跟它对应的是对称架构,它的优点是可靠性比较好,缺点是当元数据更新频率高的话,如果Palo采用这种数据元数据更新比较高时,网络容易成为瓶颈。
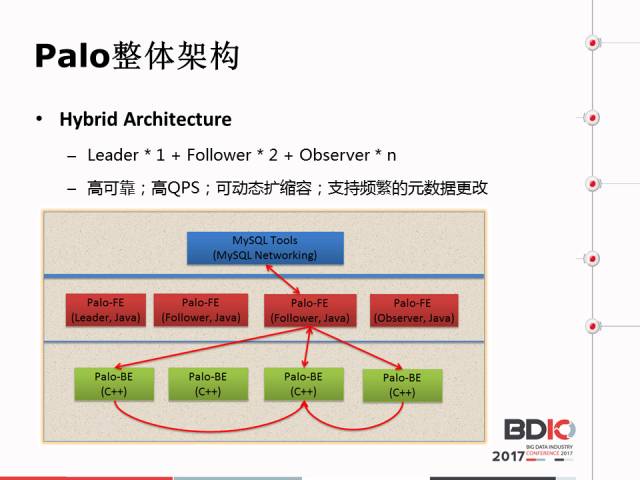
Palo的元数据管理分三类,一个是Leader,一个是Follower,一个是Observer,Leader和Follower会参与主节点的竞选。参与选举,让大家去选,这会带来一个问题,在元数据更新时要求大量的元数据同时更新,当你元数据很多时,性能会出现瓶颈,所以我们增加了Observer,它只负责接受元数据更新,这种方式可以最大程度节省元数据更新所带来的网络瓶颈。这种结合了高可靠,高QPS和可动态的扩缩容,支持频繁的元数据屏障。
业界有些数据库元数据直接存在类似于MySQL系统里面,为了对元数据的查询和保证。但是对于Palo来讲这种方案不太适合,在Palo第一版本时也是这种方案。但是在百度整个的数据量比较大前提下,整个的元数据访问比较复杂,而且我们对比了一些复杂工具之后,会有变态的情况出现。比如说一个查询语句、一个点击查询,会翻译成成千上万的语句。如果一下翻译出来成千上万语句时,你把它都执行完,可能访问性会存在瓶颈。
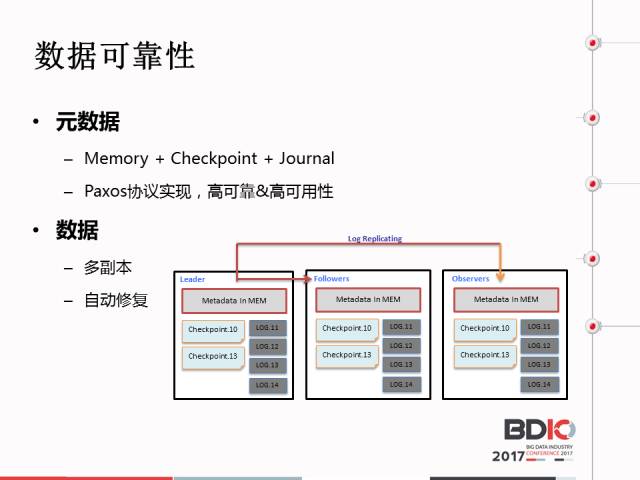
我们的内存如果BUG掉怎么办?Checkpoint保证说如果内存挂掉的话,还可以同步进其他的内存,这样保证了元数据的可靠性。数据可靠性和元数据可靠性大同小异,在这里Palo也支持做副本,也可以自动修复。之前发现了一个用户在导入数据时只测了一部分,他想导入更快一点,占用存储机更小一点,等他把数据都导进去时,他扩展成了三个副本,这都是利用Palo修复的功能,把单副本扩展成三个副本。

这个是MPP,它是把查询计划与查询执行物理分离。我要说一下Palo的MPP架构和OLTP MPP是不一样的,我们为了保证整个的查询执行不影响查询计划,所以把物理分离了。

很多同学会问我Palo底层用什么实现?Palo是一个高度集成系统,是查询与存储一体的数据库系统。在这里里面,它比较易于实现一致性保证。在一致性提到两个维度,一个是单调一致性,还有Consistent View,它是高性能的,最后是易部署,易调试。像Palo去部署的话一天就部署好了,像一些大的开源系统依赖的环境和条件比较多,一旦花了几个月做好,容易出问题,出了问题去定位比较复杂。
整体的架构是这样的,下面我讲一下后端节点存储结构是什么样的?
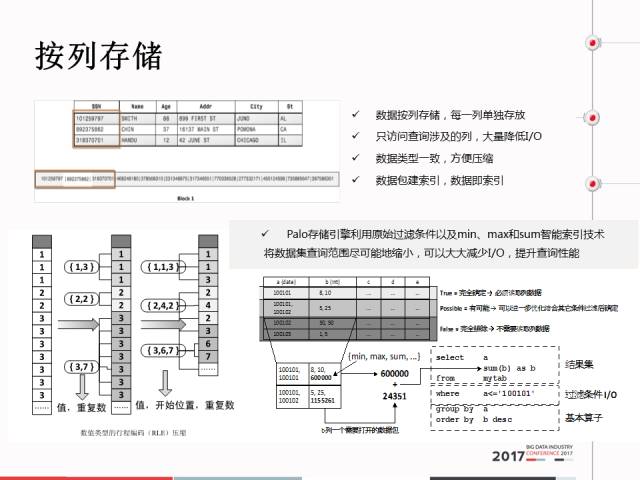
首先是列存,这个概念大家都很熟悉,我不会讲太多。只讲一点OLTP都是行存的,OLAP可能是对全量数据的某几列进行分析,所以把它一列存在一起更好一点。列存的优点很方便做压缩很方便做索引。

这里着重讲Palo很特色的地方,它可以支持很多的数据模型。数据模型建表时会考虑很多的列式,比如说多少列。在Palo建表时首先考虑一个问题,我的哪些列是指标列,哪些是维度列。维度列是Time、Id、Country,而指标列是Clids、Cost。我们的数据库首先存在序列,然后进行排序,Palo会做一个事情保证全局唯一。

首先已经有这样一份数据存在Palo里面,一共有三行,T是这样的。又新来一份数据,新来的数据第一行它的T列跟之前T列不一样,它是20140101,1、US。存到T列之后首先把T列不一样的单独存一条,T列相同的把Value列进行合并。
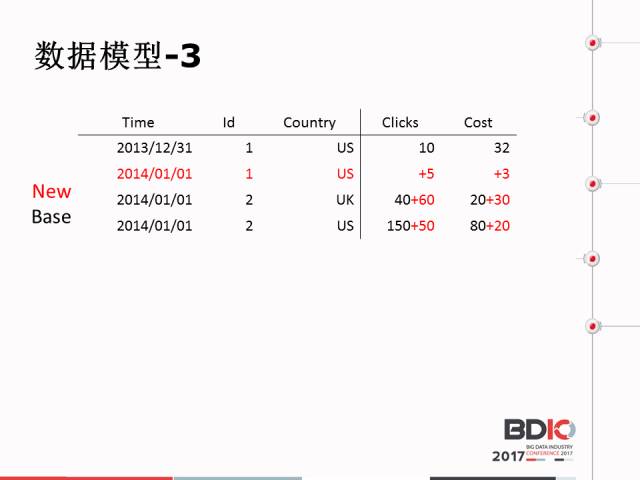
如果T列重复类很大,使用Palo之后其实存的数据量非常小。
查询时会进行很多的具体操作,这一部分操作在存储过程中已经做完了,也就是说这个数据模型可以极大提升做指标维度列的表查询。除了这个具体数据模型之外,我们也当然支持非具体模型。
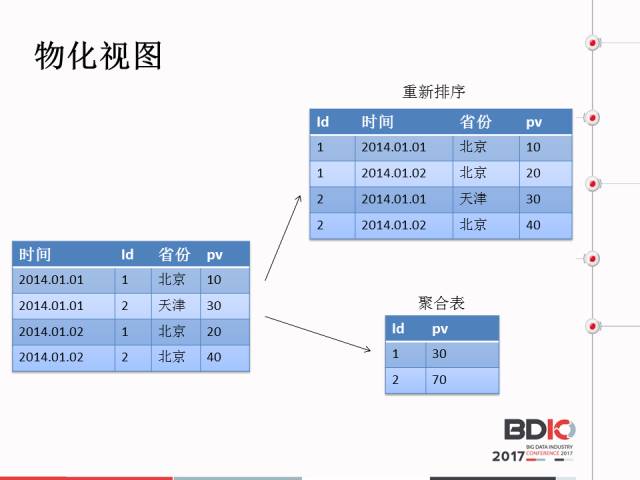
第二个是物化视图,它有两种优化方式和优化思路。第一个是物化视图把这些表按照某些T进行存储。一个原始表可以对应很多的物化视图,查询过程中具体应用哪个物化视图,这个是Palo进行选择的。物化视图本身概念是时间换空间的技术,然后讲一下查询的优化。

第一个是向量化执行,一个是LLVM。向量执行是行式执行引擎问题。但是LLVM有一个问题,它在编译时有一个固定的编译开销,这个大概在百毫秒左右。

下面讲一下存储的小技巧,所有的分布式系统都会分片存储,这样有可能会导致某些分片会很大,无论是用哪个方式进行分片,可能每个分片都很大。另外,做分片分列优化时又会很麻烦,Palo用两级分片解决的。通常出现用户第一级分区是用一个月分区,第二级分区是用SATA进行分区。在两级分区基础上,我们为了高效利用硬件性能,我们知道SSD数据非常好。

再讲一下数据导入,刚才提到的OLTP和OLAP的区别,OLTP有一个很关键的指标是每秒数据量。OLAP是讲数据吞吐量。鉴于此Palo有两种导入方式,一个是批量导入,一种是小批量导入。批量导入是利用Hadoop的系统,先把批量梳理好再进行导入。第二种是不批量导入,利用查询执行框架进行导入,它的好处做的频率好一点,多导入事务提交。具体的运行方式也和MySQL不一样,这两个命令都是异步的命令,因为批量导入不可能马上完成,异步命令有一个生效问题,因为Palo在业务过程中有很多没有对一致性要求,我们在一致性上做了很多改进。比如说每一批导入都附上版本号,MySQL是不用的。再比方说我们导入的一个批次数据,怎么往主版本里面去合?

这里面就给出了导入一个批次怎么往主版本合的?这里面列出了0-60,61、62都是导入的版本号。先假设主版本里面存的是0-60数据,如果往主版本合的时候,首先想一下把主版本的数据读出来,然后再写进去。通过版本合并可以极大减少数据量,但是版本合并的原则就是不能影响线路查询。

最后是资源隔离,刚才提到Palo在百度内部也应用了200多个业务,我们不可能建200多个集群。我们的大多数业务都是在一个共享集群里面,资源隔离有两层概念。第一层是用户之间建立的资源隔离,不同用户不能相互影响。第二,同用户之内设资源优先级隔离,可能我的分析类查询要优于Udhome查询。

这是Palo的发布,Palo2013年10月份发布了第一个版本。2014年发布百度云OLAP引擎。2015年进行了拍卖,实际上已经面向上市了。
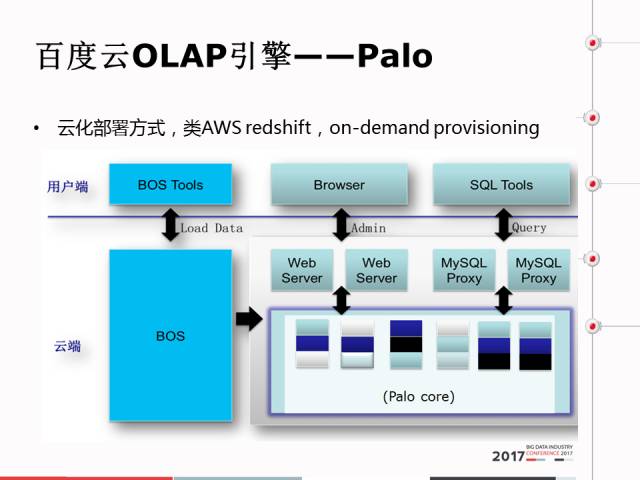
这是在云上的部署方式,类AWS redshift,
on-demand provisioning。这是在云上的一个界面,浏览器去进行集群管理,增添的界面,很简单,一共没有几步。

这里再说一下未来的Palo Road map,我们希望在这基础上开源,希望有更多对数据库感兴趣的同学能够跟我们一起开发,一起活跃这个产品。
