你知道吗?还有比自回归方式更快更好的序列生成!
点击上方,选择星标或置顶,每天给你送干货 !
!
阅读大概需要26分钟
跟随小博主,每天进步一丢丢


作者: 龚俊民(昵称: 除夕)
学校: 新南威尔士大学
单位:Vivo AI LAB 算法实习生
方向: 自然语言处理和可解释学习
知乎: https://www.zhihu.com/people/gong-jun-min-74
前言:今天要说的内容是关于非自回归方法的序列生成。在作业1中,我们做了语音识别。它可以看作是一种条件序列生成。输入是一段语音,输出的一段文本序列要求对应到这段输入的语音。除了语音识别外,条件序列生成还可以拓展到更多的任务。比如看图说话,给定一副图片,要求生成的文本序列能够描述图片中的内容。类似的,机器翻译也是,给定一个源语言的文本序列,要求生成的文本序列是还原源语言语义且语言是另一种指定语言。

一般自回归模型用的是 RNN,序列的 token 是一个个输入给模型。在解码时,每次生成出的 tokens 都会用来作为限制下一个 token 生成的条件。这样的方法有一个缺点在,当我们要解码生成的句子很长时,要花的时间就和解码的长度成正比。但我们有了 transformer 之后,我们编码时就不需要像 RNN 一样,需要吃前一个时间点的 token 后,才能编码下一个时间点的东西。所以它的速度是可以并行加速的。但在解码时,还是会遇到和 RNN 一样的问题。
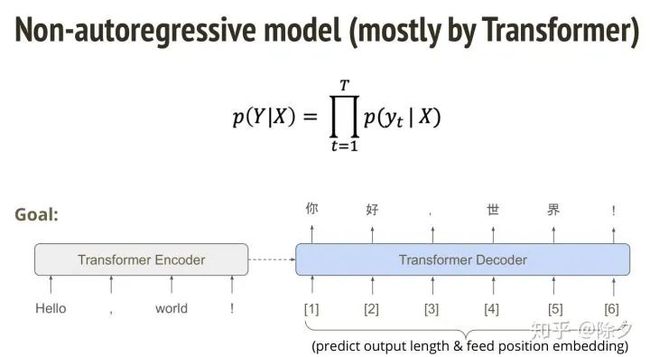
既然 transformer 都能够并行运算了,为何不让它在解码的时候也一口气把整句话直接生成呢?这样的话,时间就能减少很多。但有一个问题是,我们要如何确定一口气生成的句子到底有多长?我们可以先让解码器预测出一个长度,再利用这个长度去得到位置嵌入。但这样去做又会遇到一个很大的问题。

在理解这个问题之前,可以先看一下在图像处理中的例子。假如我们不用 GAN 的方法而是纯粹监督学习的方法去训练一个文本到图像的模型。这个模型的输入是一个文字比如说(火车),输出是一张图片。损失就用带有火车的图片和生成的图片算L2距离。这个方法的缺陷在,生成的图像都会很糊。因为它会是每一张图片的平均。假如我们有三张朝向不同的火车。那么生成的火车则倾向于是它们三个朝向的平均。
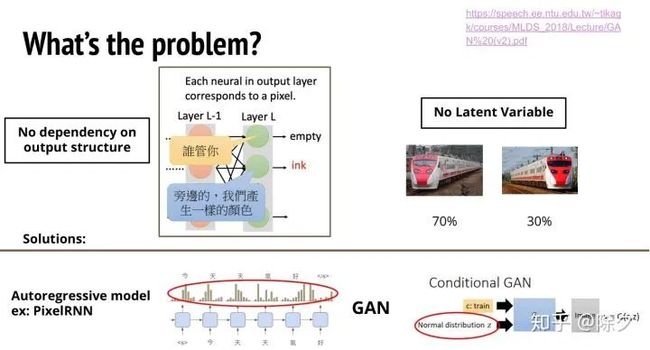
为什么我们会遇到这个问题?这是因为图像每个位置的像素都是独立输出的,没有考虑到彼此的依赖关系。如果我们用自回归模型去做,就可以避开这类问题。因为在输出第二个位置的像素时候,可以看到第一个位置的像素。另一种方法是用 GAN 来解这个问题。判别器能够给整张图片评分。然后把这个分数反馈给生成器去更新参数。这个分数得出是参照了整个图片所有的结构,考虑了不同位置的像素与像素之间的依赖关系。所以 GAN 是一种可以让生成器输出完整结构的方法。除了没有考虑不同输出的依赖问题外,这类依赖监督信息的模型也没有任何的随机机制,没有一个隐变量去决定输出的火车朝向左边还是右边。虽然这个模型在训练的过程中,已经知道有 70% 左右火车朝左。但由于它内部没有随机的机制,所以即使到了最后一层输出,它还是会输出两种朝向火车的叠加状态。为什么自回归模型不会有这类问题呢?这是因为它对每个时间点解码就会有个采样的过程。它会挑一个几率比较大的,把其它可能性都排除掉。对于 GAN 而言,不管有没有条件生成,输入给生成器的都会加一段随机的噪音。这段噪音实际上就是让模型实现决定好生成的方向。所以自回归模型 和 GAN 都会避开这两个问题。但是我们的非自回归序列生成模型,就会遇到这两个问题。
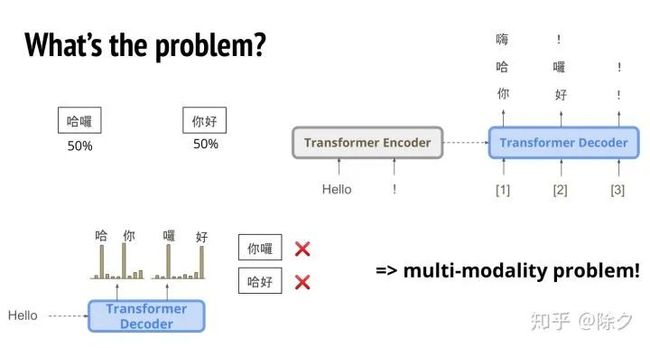
说完图像的例子,现在我们来回到文字的例子中。我们有一句英文,想要把它翻译成中文。可是中文可以有很多不同的翻译方法。比如,Hello 可以翻译成你好,或者是嗨。假如我们有一半的概率是你好,一半的概率是哈喽。那么 Transformer 解码时,第一个字 "哈" 和 "你" 的概率是差不多大的。第二个字是 "喽" 和 "好" 的概率是差不多大的。所以 Transformer 会生成出错误的翻译,比如 "你喽" 或者是 "哈好"。这便是 multi-modality 问题。同一个输出,可能对应到很多不同模式的输出。如果是非自回归,它会把各种可能的模式叠加在一起,作为输出。所以这个 multi-modality 是我们关键要解决的问题。
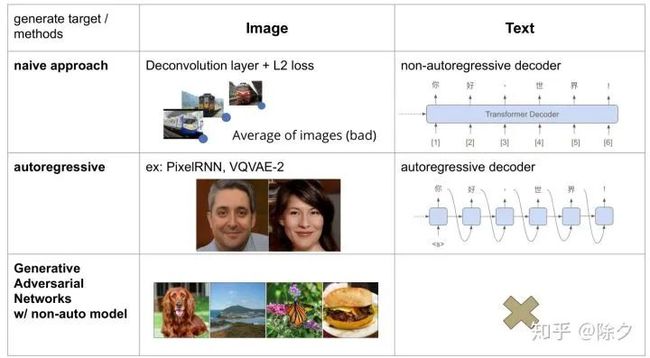
这里总结一下。加入我们要用传统算L2距离的方法去训练图像生成,它会输出很多张图片的平均。对应在文本就是,我们用非自回归模型去生成文本,它也是各种可能的输出叠加状态。如果我们用自回归方法在图谱上,就能生成出品质很好的图片。对应到文本上,就是用 RNN 自回归的方式去解码生成。GAN 可以生成很高品质的图片。我们在做 GAN 的时候,可以用传统的模型架构,从而可以避开自回归模型的架构。但 GAN 在文字上却显得很不可行。因为离散的文字用 GAN 来做,目前还不成熟。因此目前 GAN 在文本的研究上都还是偏自回归多一点。由此我们只有一条路走,如何针对非自回归模型改良?
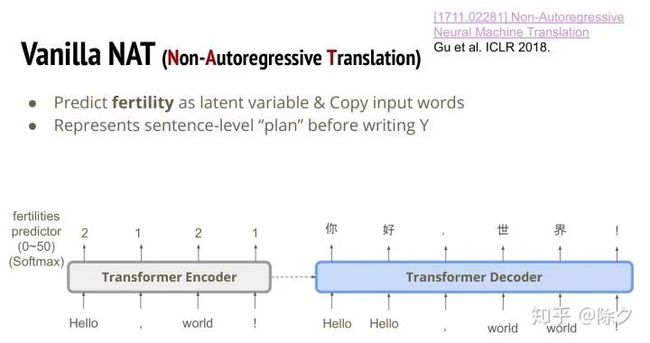
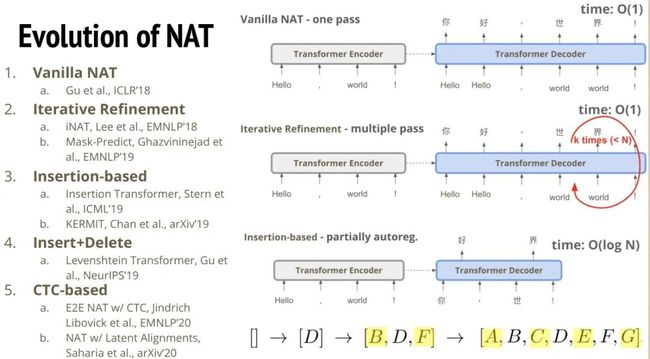
ICLR 18 出了第一篇用非自回归模型做翻译的模型。非自回归翻译简称叫 NAT。这篇文章的概念还挺简单的。它提出了几种改良方法。第一种方法是,我们在 transformer 的编码器这里,每个位置去预测一个数字。这个数字代表的意义是,这个输入的字,对应输出的几个字。我们预测完这个数字后。就把输入给解码器的token 嵌入来拷贝该位置输出的数字份。图中 Hello 的位置编码器输出2,解码器的输入就有两个 Hello。为什么我们要预测这个数值呢?其实它代表了解码器对这个输出的规划。
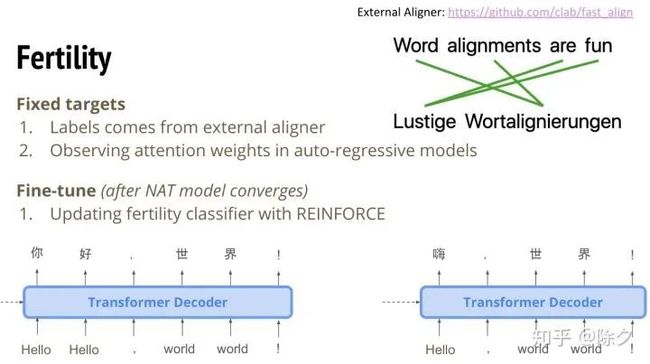
假如编码器输出的是 2121,Hello 复制两次,那它就可能输出一个 Hello 的 token 对应着 "你好" 两个中文 tokens。但如果编码器输出的是 1121,则 Hello 只有一次,它就只可能对应着中文的 "嗨" 一个token。除此以外,我们也可以直接去训练一个序列到序列的模型,然后去看它的注意力权重是怎样分布的。在语音处理中,对应的就是哪段语音信号对应的哪段文字。这里做的事情是一样的。但如果我们只是从外部得到答案,来端对端训练这个 Fertility 预测的话,它和最后模型要预测一句不错的句子目标是不一致的。所以我们在模型收敛以后,会做一个微调的步骤。就是用强化学习的损失加在 fertility 分类器上面,去优化。
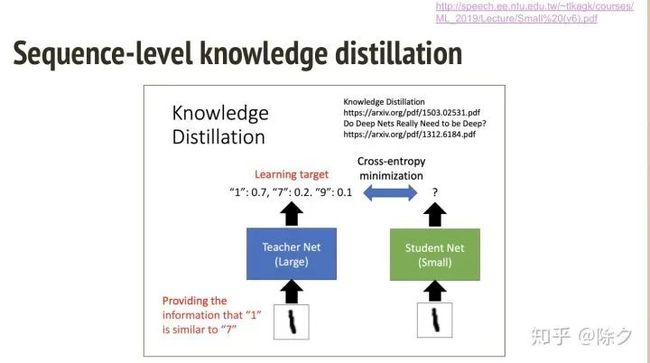
之前的 Fertility 是一种技巧。我们也可以基于知识蒸馏来做。假如我们要训练一个小模型,想让它和大模型一样好。那我们可以把小模型当作学生,向大模型学习。小模型在训练时,先把输入丢给大模型,让它预测出概率分布,作为小模型的监督信息计算损失。这样小模型就会学的比较好。
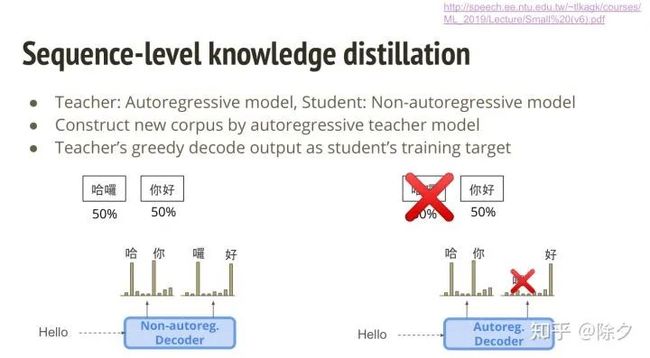
类似的,我们可以让自回归模型作为老师,非自回归模型作为学生。但后面的事情有一小点不一样,我们不用自回归模型的预测分布作为监督信息。而是让自回归模型的贪心解码输出作为新的训练语料。用它来作为学生的训练目标。为什么这种方式可以解决 multi-modality 问题呢?因为输出之间没有考虑依赖,所以错误的翻译概率会很大。但如果我们的数据集有先给自回归模型做解码,它在生成出第二个字的时候,其概率分布依赖于之前生成的字。比如第一个字预测的是 "你",那第二个字预测出是 "喽" 的概率就会变小。这样一来,正确答案里面就不会有"哈喽"这个可能,只会留下 "你好" 这个可能。这样做完后,数据集就会变干净,更容易让自回归模型去学习。
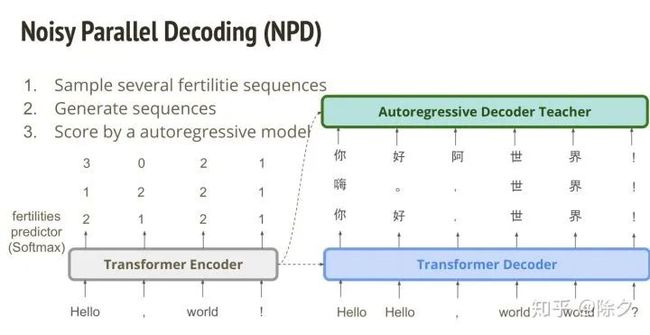
还有一招叫作 Noisy Parallel Decoding (NPD)。它的概念是,我们先训练好非自回归模型后,解码时,其实是可以采样不同的 fertilities。这样就能确保随机性,输出一大堆不同的句子。这些句子再交给自回归模型来评分,选择一个最好的句子当成答案。
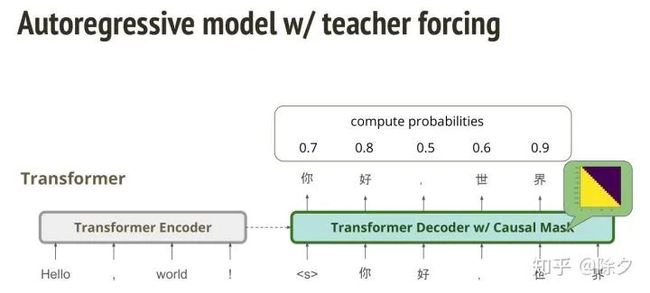
这样可能有点奇怪,我们不就使用了自回归模型了吗,不就变慢了吗?但其实我们让自回归模型去为一个已经生成出的句子打分,是只需要一步就能完成。比如我们用 Transformer,把当前 token 的后面用 MASK 遮住,它就不能看到后面的字。这样一个 MASK 矩阵与 Transformer 解码器乘起来,就是整个句子的概率。
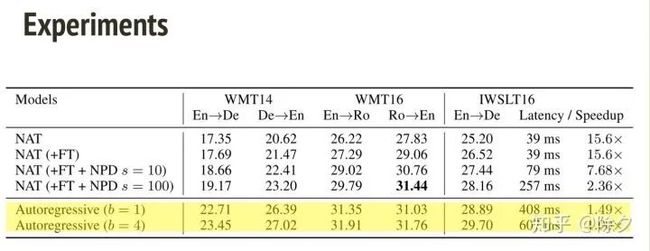
所以我们就有三种方法可以加强非自回归模型。从结果来看,b 代表的是 beam search size。在解码推断上,NAT 速度会显著快于自回归模型,但表现低于它。我们一步步把三个 trick 加上去,会发现表现越来越好,直到与自回归模型相当。即便如此,速度也是自回归模型的至少两倍。
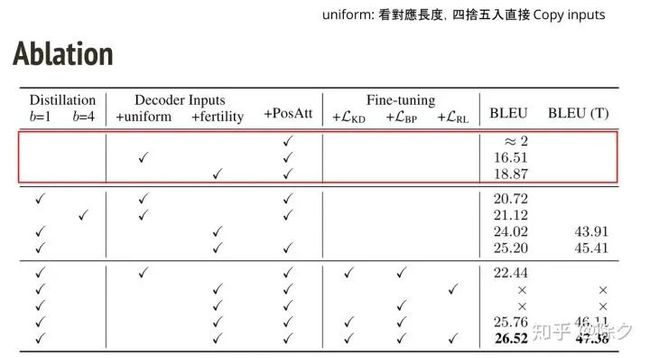
在消融实验中,可以看出,加上 fertility 之后,BLEU 分数可以进步到 18.87,加上蒸馏之后,分数一下子进步到25.20,。再加上微调之后,BLUE 略微提升了1个点左右。
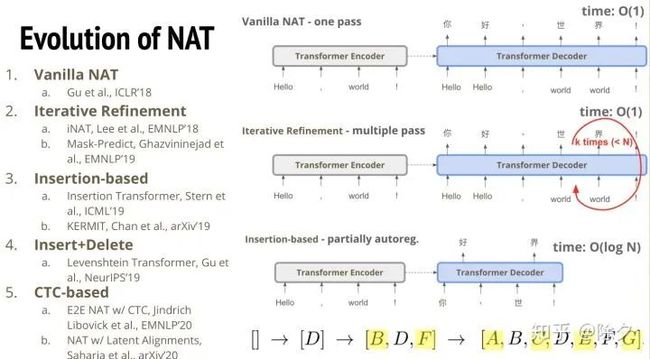
自从这篇 NAT 出来之后,之后几乎每个月都会不止一个新模型出现。第一个出来的变种是 Iterative Refinement 的思路是,如果我们让模型一口气输出整段话可能会太勉强,我们能不能把解码出的文本再重新丢回到解码器,重复多次让它来修正之前的错误。除此之外,还有一种方法是 Insertion-based,它类似于前面的变种,不过它迭代的方式是通过插入的方法。对于非自回归模型输出的比较差的句子,重新丢回解码器判断每两个字之间要不要插入新的词。因为原本的迭代优化的方法,句子长度是固定的。第一次解码出的句子多长,迭代优化后的句子也会是这个长度。但是用基于插入的方法,迭代优化的句子长度就可以改变。但这样还是会比较慢。比如我们想要生成 ABCDEFG,第一步可能会先生成中间的D,然后是 BDF,最后才是全部的tokens。最快是 O(logN) 的实践。所以基于插入的迭代优化法,比较像是介于自回归和非自回归模型中间的一个产物。有了插入之后,我们又会想到它插入了一个错字,它就不能再修改了。所以我们会自然地想到既可以插入又可以删除地迭代优化方法。最后一个就是 CTC-based 方法,这个和语音识别中的 CTC 是一致的。待会我们会详细介绍它要怎样应用。

这就是第一种迭代优化的变体。它一开始也是一个编码器,去预测目标token的长度。然后把每个 token 按照长度去复制,输入给解码器1生成出 Y0 做第一次迭代。接下来我们把 Y0 再输入给解码器1输出Y1,做第二次迭代。以此类推。我们要怎样训练这第二个解码器呢?我们除了可以直接拿Y1和正确答案算损失外,我们也可以随机加一些噪音丢给解码器2,让它去学去噪的过程。加噪音可以直接把某个 token 重复两次,或者直接把某个 token 换成随机的 token,再或者是把两个 token 交换。接着我们让模型去学习两种不同的损失,前面那项是第一个解码器的损失,负责计算把根据长度复制的X‘输入给解码器后得到Y0,与正确答案的交叉熵,后面那项是迭代优化去噪的交叉熵。
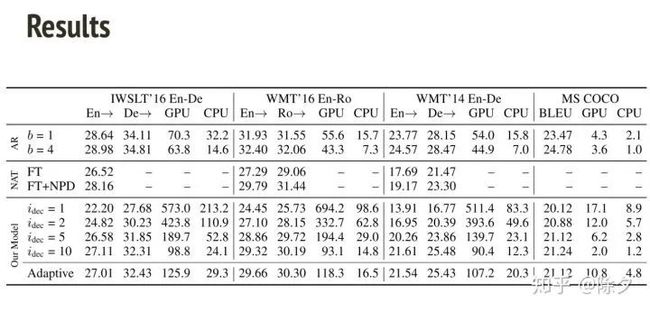
结果表明它的效果和最初的 NAT 那篇论文相当。
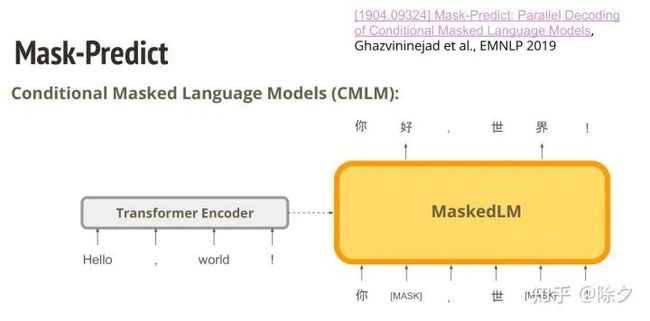
另一篇在 BERT 出来之后做的。它的思路是把 BERT 当作纠错的解码器。BERT 可以把一句话中被替换成 MASK 的 token,还原出来。我们把 BERT 加上一个编码器,再用 BERT 当解码器来用。它在做 MaskedLM 的时候,可以看到翻译之前的句子。这样基于条件的语言模型训练完后,要怎样使用呢?首先,英文 tokens 输入给编码器后会在 CLS 这个 token 的位置预测一个长度,比如是6。接着,它就会把 MASK 这个 token 复制六次,让 BERT 去预测出第一版的翻译。这个翻译可能会是比较乱的。于是我们会把这第一版中生成几率比较低的 token 重新 MASK 掉,再作为输入丢给 MaskedLM,让他生成出第二版。
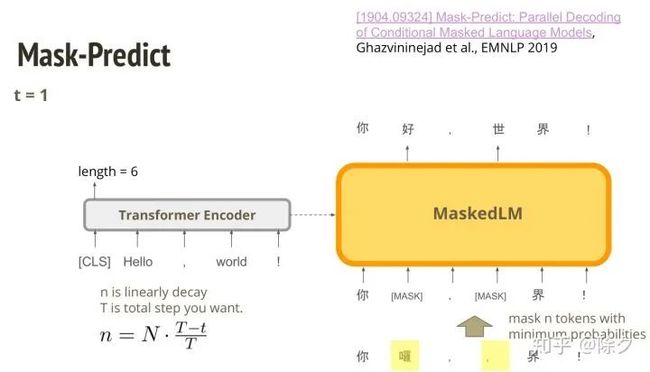
我们要怎样决定要 MASK 掉多少 tokens 呢?一开始我们希望MASK多一些,到后面随着迭代优化得越来越好,则 MASK 越少。

我们可以看一下个例。在t=0代表第一次的时候,模型一口气吐出了所有文字,发现有明显的语法错误。涂黄色的区域表示要 MASK 掉的 tokens。t=1,迭代一次后,错误明显减少。再迭代一次后,则翻译的很通顺,没有明显错误。
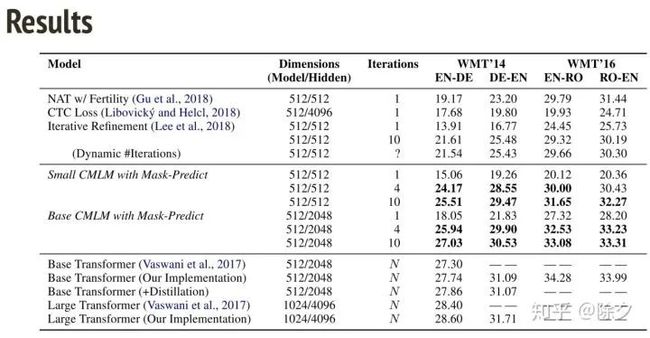
从结果上看,这种 MASK-predict 的方法显著好于过去非自回归的生成,甚至好到要接近自回归模型的生成。
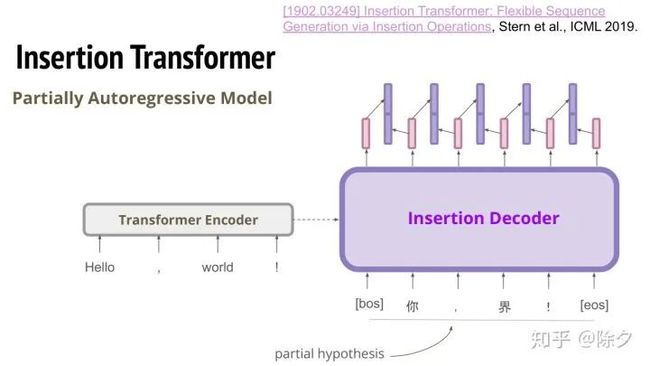
接下来要讲的是基于插入的方法。它也是一种部分自回归模型。insertion transformer 的概念是,将残缺的句子输入给模型,模型要预测每两个句子之间要不要插入一个字,如果要,则插入什么样的字。假如我们输入有6个 token,输出也会是6个向量。我们把相邻的两个向量都接起来,这样每两个字中间就会有一个表征。我们把这个表征接上 MLP 去预测它要插入的字。如果两个字之间不需要预测插入的字,就预测 end。

这样的模型我们要怎样训练呢?我们要怎样创造让模型去学的个例?假如我们数据集中有一段10个字的话,我们先把这10个字做顺序打乱,然后从0-10中随机挑k个数字,比如k为5,我们就只取前5个字。后五个字就是被 drop 掉的字。然后我们把这五个句子还原回来,被 drop 掉的字就会形成一个槽位,表示要插入字的位置。
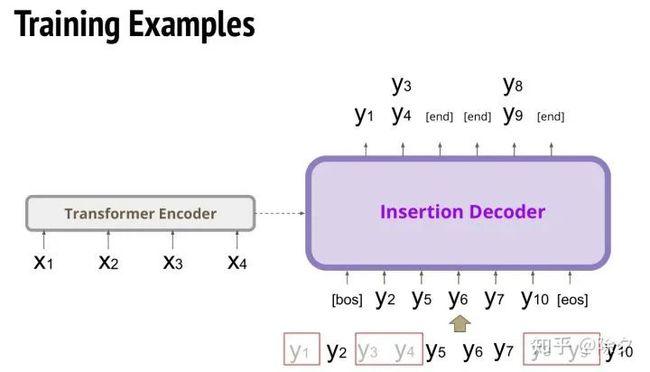
接着,我们用这样处理出的训练数据集取训练一个 insertion decoder。它是一个 transformer 架构。输入是前面方法处理后的个例,解码器目标是还原出 drop 掉的字。如果 drop 掉了连续两个字要怎么办呢?我们要两个y都去算损失。假如这两个字中间本来就没有字的话,就预测 end。

假如一个槽位有很多个字的话,我们就要把全部的损失都计算。原本我们这些字的所有的损失相加求平均。但我们可以让模型倾向于生成出槽位靠中间的字。为什么要这样做呢?因为在迭代的过程中,先生成出中间的字,可以方便下一次迭代生成补全。这样迭代的次数就会尽可能的少。所以我们可以针对中间的字算损失的时候,乘上一个比较大的权重,让模型更倾向于先把中间的字生成出来。

这边我们可以看一个例子。模型在解码的时候,会先生成出最中间的字,然后一步步像二叉树遍历一样,生成左右两边中间的字。迭代次数显著少于不对中间字生成损失加权重的方式。
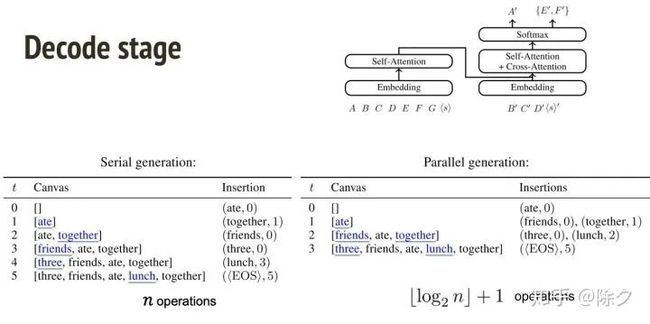
这种方式除了可以并行解码之外,我们也可以每次选一个几率最大的,一步步做解码。但相比用二叉树生成的方法解码会慢很多。一个要操作 n 次,另一个操作 log2n 次就行。
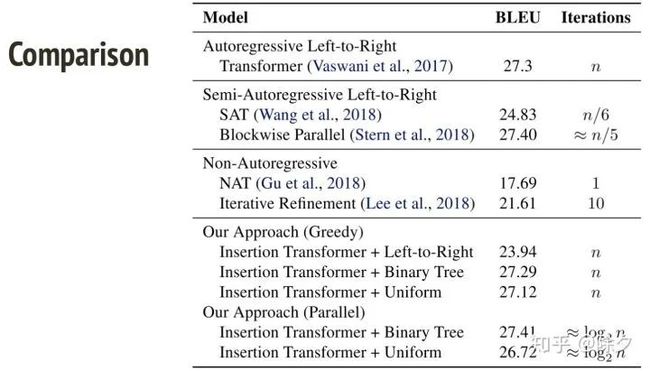
从表现结果上去看,一个个生成和二叉树生成 BLEU 得分是差不多的,都于从左到右生成的自回归模型相当。但从速度上看,二叉树生成的方法会显著快于过往的方法。尤其是在要生成的序列很长的时候。

Insertion transformer 出来以后,又出了一篇叫 KERMIT 的论文。这个也是芝麻街的人物。为了凑名字,原本是 C 开头的 contextual 变成了德文的 Kontextuell。这个 KERMIT 的概念和 insertion transformer 的概念是一模一样的。唯一不同在, insertion transformer 有编码器和解码器。而 KERMIT 把编码器和解码器混合在同一个模型中了,就像 BERT 一样。比如我们要中文翻译英文,我们把中文和英文的序列接在一起,然后在英文的那半边做插入的操作就好了。
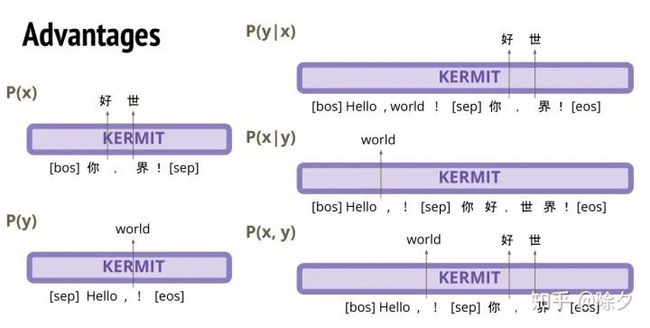
这样做是有个好处的。英文翻译中文的话,我们就可以把英文接中文。然后在中文的那边做插入的操作。它可以做到中英互译。我们还可以训练中文和英文的联合概率 P(x,y)。我们把中文和英文接在一起,中文 drop 掉部分字,英文也 drop 掉部分字。英文要预测插入的字的时候,它就可以看一下中文有什么信息。同理,中文要预测插入字的时候,也可以参照英文的信息来生成结果。当然,我们也可以只放中文或只放英文,去做插入的训练。这样一个模型就能学到 5 件事情。
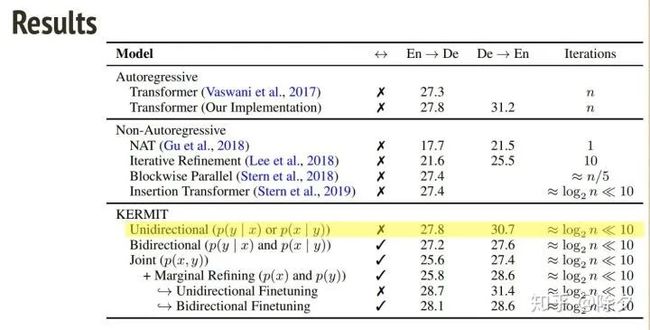
同时学 5 件事有什么好处呢?如果我们分别训练两个中译英,英译中的模型,作为表现基准。单纯地让模型同时学中译英,英译中 (KERMIT 的方式),结果表现是往下掉的。但如果我们为 5种任务在一个模型中去建模,最后再做一个微调,效果又会升回来,甚至超过单P(y|x)或P(x|y)的基准。
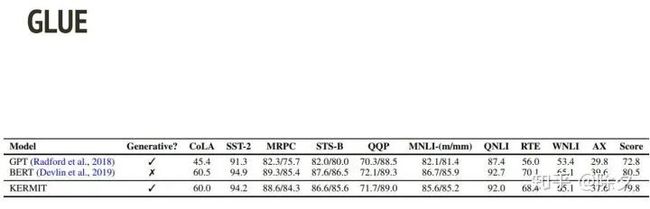
KERMIT 之所以用芝麻街中的人物命名是因为,它可以像GPT 和 BERT 一样作为预训练语言模型。KERMIT 的方法在 GLUE 上跑出来的效果,竟然和 BERT 不相上下。而比BERT厉害的是,KERMIT 又可以做生成,又可以和 BERT 一样做其它任务。
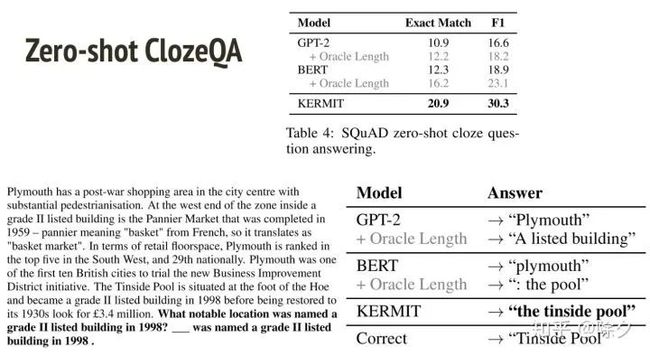
在 ClozeQA上做零样本学习,BERT 不能很好地判断空格要填入几个 tokens。但是 KERMIT 可以很自然地插入正确地字。同理在 SQuAD 上做零样本学习,KERMIT 也显著好过 BERT 和 GPT-2。

KERMIT 往后还有一个新版本叫作 Multi-KERMIT。它把各种语言的数据都训练在同一个模型上面,是一篇值得一看的 paper。

上面说到 KERMIT 在问答任务的零样本学习上表现要比 BERT 和 GPT2 好很多,因为它为五个任务建模。这一期我们来说一下非自回归序列生成未讲完的两个模型。一种是加入了删除操作的插入迭代法,另一种是借鉴了语音识别任务 CTC 的方法。
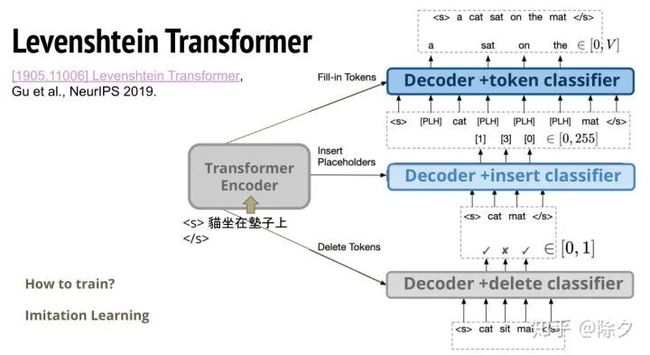
Levenshtein Transformer 相比于之前插入迭代的方法,它还增加了删除操作。解码器会生成三个部分。首先我们会有一个翻译到一半的未完整片段。我们把它丢进解码器后,再接一个分类器用来决定哪些生成的 token 不合适需要删掉。我们再把这个句子丢到解码器中,又接一个分类器用来决定哪些 token 之间需要插入新的token。最后我们把这个句子丢到解码器,再用一个分类器去决定要插入token的位置,应该插入什么新 token。我们要怎么去训练一个这样的模型呢?它用的是模仿学习的方法。

既然是模仿学习,我们就需要有一个模仿对象。这个模仿对象的算法就是 Levenshtein 的 python 算法包。它可以算两个序列的编辑距离。它也可以算出我们要怎样把第一个序列编辑成第二个序列的方案。我们把替换操作拆解成先删除后插入,这样会比较好操作。
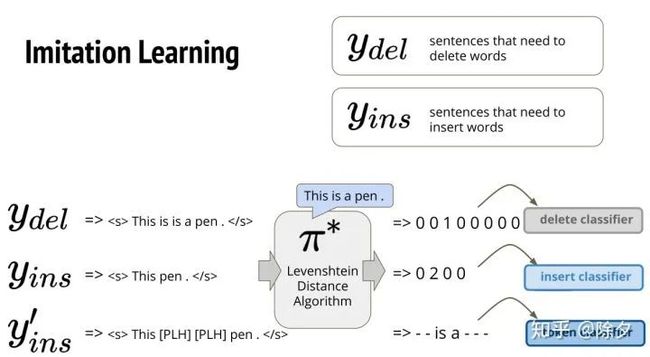
接下来要怎么训练呢?首先,我们要在数据集中制造需要被删除一些字的句子,然后我们插入一些错的字进去。同时,我们也会制造一些需要被插入一些字的句子,然后我们把一些字drop 掉。比如 "This is is a pen .",这句话中 "is" 是重复的,需要被删除。我们把这句话和原本的正确句子 "This is pen",丢到 Levenshtein 算法中,它就会得出,哪一个字需要被删除的01向量。这个向量会作为删除分类器的监督信息。再比如 "This pen .",这句话中 "is" 是缺失的,需要被插入。我们把这句话和原本正确的句子 "This is pen",也丢到Levenshtein 算法中,它就会得出,哪一个位置需要被插入字数的向量。这个向量会作为插入分类器的监督信息。最后,我们把原本这句话,插入 placeholder 之后,去看一下,原本这些 placeholders 会对应到怎样的字。它会作为监督信息给 token 分类器。

我们再来详细地看一个例子。它的句子序列是日文。第一次迭代时,模型能一口气生成出很多文字,但由于上一期讲到的 multi-modality 问题,某些位置上的 token 会生成的不好,比如存在重复冗余的tokens。于是在第二次迭代的时候,它会把其中一些 tokens 删掉,再插入一些让句子更顺畅的 tokens。于是在短短三步之内,它就能生成出一句完整的话。
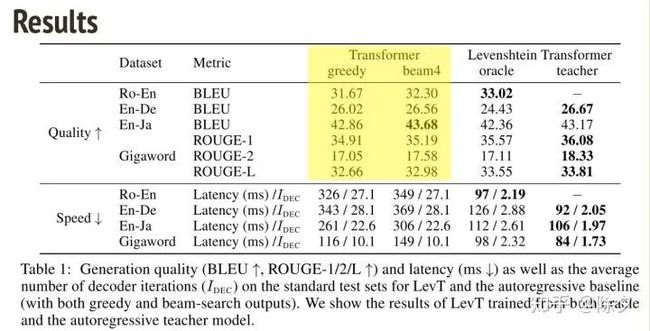
从结果上去看,Levenshtein Transformer 的非自回归方法,是要和自回归的 Transformer BLEU 分数相当,但速度显著变快。如果再加上知识蒸馏的方法,它还能获得更好的表现。
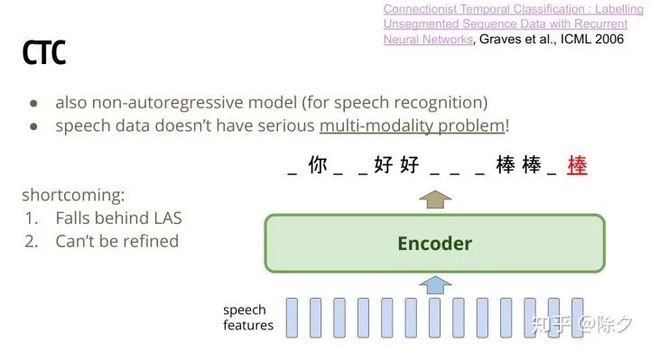
CTC 也是一个非自回归模型。对于语音数据,通常不存在很严重的 multi-modality 问题。这是因为语音中,前一个时段的发音对后一个时段的发音影响依赖很小。通常一段语音就是搭配一种可能的说法。之前语音识别的笔记中有讲到,编码器可以直接一口气生成一个序列。对于每个 frame 就输出一个 token。这个 token 可以包含空白的 blank token。所以最终模型输出了如图那句话后,可以把 blank tokens 拿掉,把重复的字缩成一个字。最后就会生成出 "你好棒" 这个序列。CTC 有几个小缺点。虽然它的表现一直还不错,但是它还是会输给 序列到序列的 LAS。另一方面,CTC 虽然是个非自回归序列生成模型。但它没办法做迭代优化的动作。因为输入是语音,而不是文字。文字不能再拿来重新当作输入喂给模型。假如我们输出了一个错字。这个错字是没有机会被修正的。
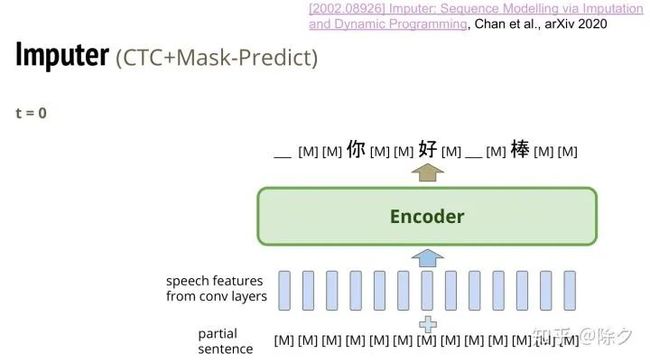
所以为了改良 CTC,就有了 Imputer。它的概念就是 CTC + Mask-Predict。这是一篇非常新的 paper。它的模型和 CTC 很像,不同在它输入的地方,会同时把文字的token序列也加进来。在 t=0 时刻,这个序列会全是 MASK tokens。就和在做 Mask-Predict 一样。输出需要模型把部分 MASK 换成真的字,也可以换成是 blank token。
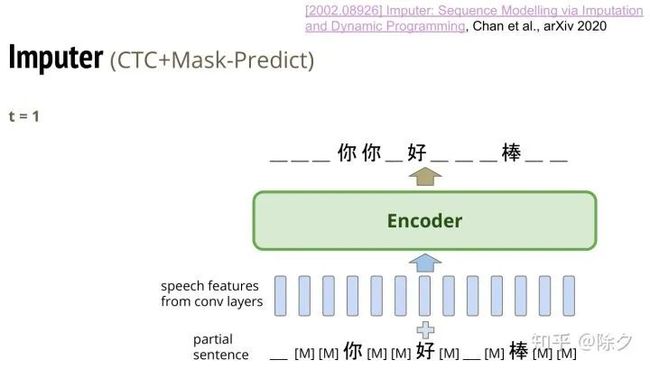
在 t=1 的时候,它会把刚刚生成的序列重新放回输入,再和语音信号同时丢给编码器,继续预测。
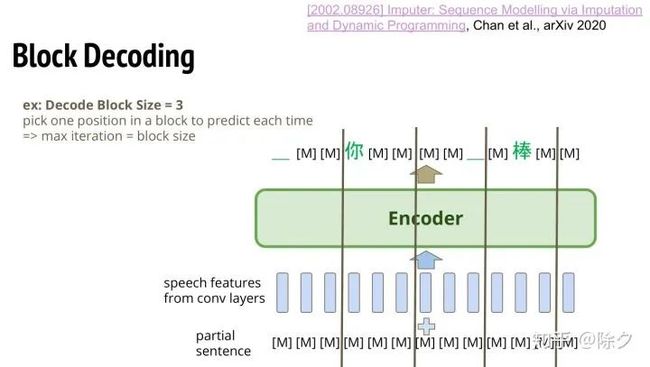
这边还会用一个叫 Block Decoding 的技巧。我们会让输入的特征有一个 Block。假如 Block 的大小是 3。那至少在一个 Block 里面,我们限制,至少一个 MASK 要被换成是真的字。这样做之后,模型在3步之内一定可以把全是 MASK 的序列变成最终生成的序列。
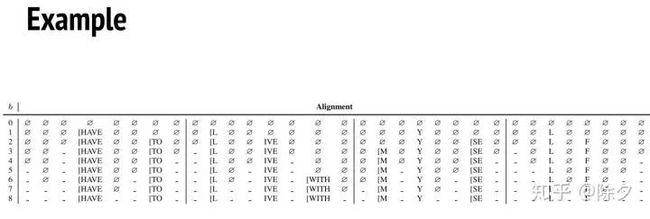
这个例子中,Block size 是8,所以它每一个 Block 中就有8个声学特征和 MASK。在第一步,会把一个 Block 中的其中一个 MASK 换成真 token。每一步都会如此,到第8步,刚好每个 Block 中的 MASK 都完成了解码转换。
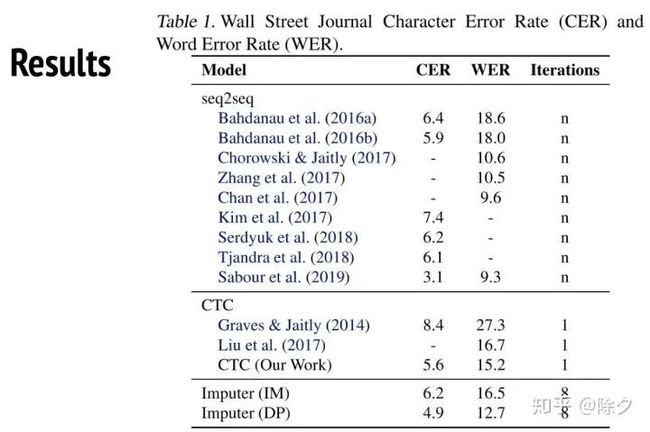
从结果上去看。前面的都是自回归的 Seq2Seq,其 word Error Rate 可以被压到非常低。但如果如果用 CTC 的话,没办法压到那么低。但用了 Imputer 之后,是可以赢过 CTC 的。
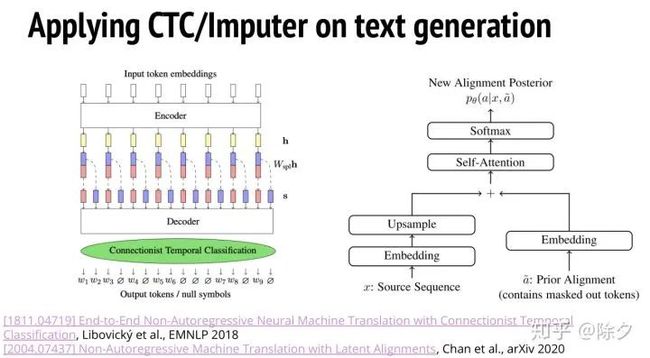
这种 CTC/Imputer 的方法有没有办法用在文字生成上呢?其实有两篇论文都是在做这件事情。我们想要做一个翻译的任务,可能是中译英。输入句子在经过编码后,会做一个上采样的操作,每个位置的嵌入会被分裂成两个小向量。这样我们的句子就变长了,有点像语音信号那样的序列。我们再对这个变长的序列,去训练一个 CTC。这样就可以用 CTC 来做翻译。Imputer 也是一样。它左边部分原本是要放语音信号的。但是我们现在换成源序列句子,对其嵌入上采样后,把变长的序列当作原版的 Imputer 中的语音信号来处理。
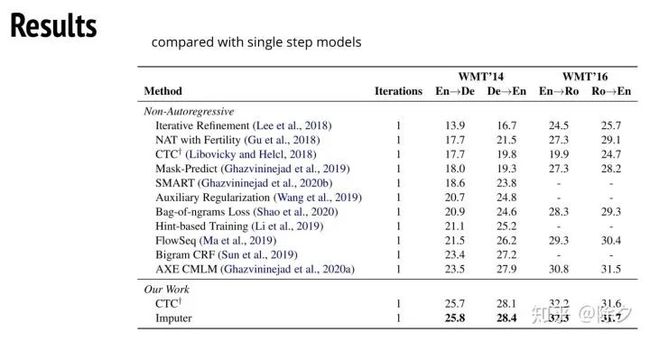
这个方法做纯文字的翻译,效果很好。我们可以看到它和其它所有非自回归生成的方法比较,CTC就可以胜过之前所有的模型。而 Imputer 又可以赢过 CTC,做到略胜一筹的表现。
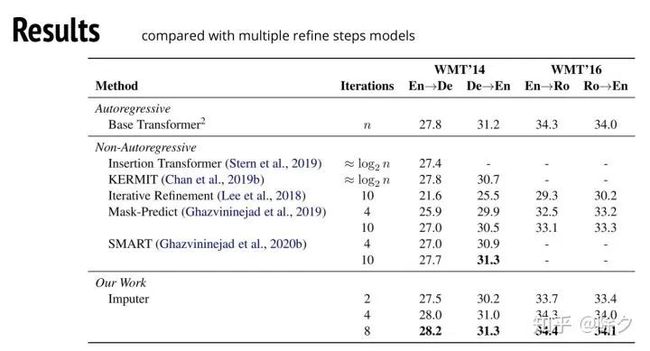
我们再拿它和自回归模型做比较。我们会发现,Imputer 在多迭代几次的情况下,已经可以赢过自回归模型了。这个方法其实还蛮强大的。概念也很简单。

最后再提一下知识蒸馏在NAT中为什么有用。这篇2020的论文做了一个实验。任务是把英文翻译成西班牙文、法文、或德文。数据对随机匹配,模型不知道它要把英文翻译成哪种语言。我们让自回归模型去学这个任务的话,模型每次都分不清要翻译成什么语言。只要一吐出德文,它句子中所有字都会是德文的词汇。图中的每一个点就是它输出的一句话中,德文、西班牙文和法语的比例。要么就整句话都是德文,要么就整句话都是西班牙文或法文。就很难出现同一句话有三种不同的文字的句子。这也非常符合真实的数据分布。但如果我们用 NAT 非自回归序列生成模型去学,就发现它会出现一句话中出现不同语言文字的情况。如果我们把数据集中,存在一句英文对应到三种翻译的句子,随机删除掉英文到另外两种语言的数据对。我们互发现,之前的问题就会减轻。可是我们发现更有效的是,我们直接让 NAT 模型去学自回归语言模型的输出,即做知识蒸馏。这个状况可以减轻得更多。所以说知识蒸馏在 NAT 中的作用很大。
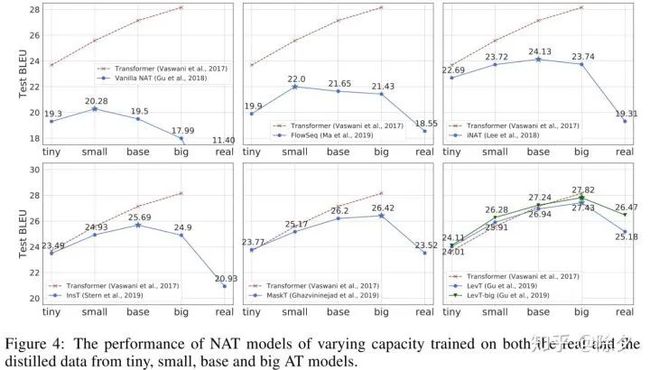
作者后面还做了一个分析。我们在不同参数大小的 teacher model 下去做蒸馏。不管和参数多大的自回归语言模型学,它都会比纯粹的 NAT 好。最开始的那篇 NAT 模型,和小模型学是最好的。但如果是迭代优化的 NAT 模型,则和中等大小的模型学比较好。如果是 Mask-Predict 或 Levenshtein ,和大模型学比较好。所以每种模型都有适合它的 teacher model 的参数大小。Levenshtein 的表现已经可以和自回归模型表现差不多了。

值得一提的是,非自回归序列生成模型,初版的 NAT,Levenshtein 和最后那篇知识蒸馏的效果,都是由 Facebook 的同一个人做的。

对于插入迭代优化法,KERMIT和其改进,Imputer 和 Imputer + NAT 都是由这一位谷歌大佬做的。他还是著名的 LAS 算法的一作。

最后是剩下的四篇论文来源。
视频见(需要梯子):
https://www.youtube.com/watch?v=jvyKmU4OM3c&feature=youtu.be
Reference
• 李宏毅 《人类语言处理 2020》Non-Autoregressive Generation
添加个人微信,备注:昵称-学校(公司)-方向,即可获得
1. 快速学习深度学习五件套资料
2. 进入高手如云DL&NLP交流群

记得备注呦
