Spark Streaming官方编程指南【上】
定义
Spark Streaming是核心Spark API的扩展,可实现实时数据流的可伸缩,高吞吐量,容错流处理。数据可以从像 Kafka, Flume, Kinesis,或TCP socket等来源摄入,并且可以使用与像高级别功能表达复杂的算法来处理map,reduce,join和window。最后,可以将处理后的数据推送到文件系统,数据库和实时面板。并且,我们可以在数据流上应用Spark的 机器学习和图形处理算法。

在内部,它的工作方式如下。Spark Streaming接收实时输入数据流,并将数据分成批处理,然后由Spark引擎进行处理,以生成批处理的最终结果流。

Spark Streaming提供了称为离散流或DStream的高级抽象,它表示连续的数据流。可以根据来自Kafka,Flume和Kinesis等来源的输入数据流来创建DStream,也可以通过对其他DStream应用高级操作来创建DStream。在内部,DStream表示为RDD序列 。
一个简单的例子
在详细介绍如何编写自己的Spark Streaming程序之前,让我们快速看一下简单的Spark Streaming程序的外观。假设我们要计算从侦听TCP socket的数据服务器接收到的文本数据中的单词数。我们需要编写如下代码。
/*
* Licensed to the Apache Software Foundation (ASF) under one or more
* contributor license agreements. See the NOTICE file distributed with
* this work for additional information regarding copyright ownership.
* The ASF licenses this file to You under the Apache License, Version 2.0
* (the "License"); you may not use this file except in compliance with
* the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
// scalastyle:off println
package org.apache.spark.examples.streaming
import org.apache.spark.SparkConf
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* Counts words in UTF8 encoded, '\n' delimited text received from the network every second.
*
* Usage: NetworkWordCount
* and describe the TCP server that Spark Streaming would connect to receive data.
*
* To run this on your local machine, you need to first run a Netcat server
* `$ nc -lk 9999`
* and then run the example
* `$ bin/run-example org.apache.spark.examples.streaming.NetworkWordCount localhost 9999`
*/
object NetworkWordCount {
def main(args: Array[String]) {
if (args.length < 2) {
System.err.println("Usage: NetworkWordCount " )
System.exit(1)
}
StreamingExamples.setStreamingLogLevels()
// Create the context with a 1 second batch size
val sparkConf = new SparkConf().setAppName("NetworkWordCount")
val ssc = new StreamingContext(sparkConf, Seconds(1))
// Create a socket stream on target ip:port and count the
// words in input stream of \n delimited text (eg. generated by 'nc')
// Note that no duplication in storage level only for running locally.
// Replication necessary in distributed scenario for fault tolerance.
val lines = ssc.socketTextStream(args(0), args(1).toInt, StorageLevel.MEMORY_AND_DISK_SER)
val words = lines.flatMap(_.split(" "))
val wordCounts = words.map(x => (x, 1)).reduceByKey(_ + _)
wordCounts.print()
ssc.start()
ssc.awaitTermination()
}
}
// scalastyle:on println
通过使用以下命令将Netcat作为数据服务器运行。
$ nc -lk 9999
然后,在另一个终端中,您可以通过使用
$ ./bin/run-example streaming.NetworkWordCount localhost 9999
对运行netcat服务器的终端中键入的任何行进行计数并每秒打印一次。它将类似于以下内容。
# TERMINAL 1:
# Running Netcat
$ nc -lk 9999
hello world
-------------------------------------------
…
# TERMINAL 2: RUNNING NetworkWordCount
$ ./bin/run-example streaming.NetworkWordCount localhost 9999
...
-------------------------------------------
Time: 1357008430000 ms
-------------------------------------------
(hello,1)
(world,1)
...
一些基本概念
本节主要介绍Spark Streaming的基础知识
连接(Linking)
与Spark相似,可以通过Maven Central使用Spark Streaming。要编写自己的Spark Streaming程序,您必须将以下依赖项添加到SBT或Maven项目中。
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.12</artifactId>
<version>2.4.5</version>
<scope>provided</scope>
</dependency>
要从Spark Streaming核心API中不存在的,从诸如Kafka,Flume和Kinesis之类的源中获取数据,则必须将相应的jar包添加spark-streaming-xyz_2.12到依赖项中。例如,一些常见的如下。
| Source | Artifact |
|---|---|
| Kafka | spark-streaming-kafka-0-10_2.12 |
| Flume | spark-streaming-flume_2.12 |
| Kinesis | spark-streaming-kinesis-asl_2.12 [Amazon Software License] |
初始化 StreamingContext
要初始化Spark Streaming程序,必须创建StreamingContext对象,该对象是所有Spark Streaming功能的主要入口点。使用以下语句来创建一个StreamingContext。
import org.apache.spark._
import org.apache.spark.streaming._
val conf = new SparkConf().setAppName(appName).setMaster(master)
val ssc = new StreamingContext(conf, Seconds(1))
该appName参数是您的应用程序显示在集群UI上的名称。 master是Spark,Mesos,Kubernetes或YARN群集URL,或者是特殊的“ local ”字符串,以本地模式运行。实际上,当在集群上运行时,您将不希望master在程序中进行硬编码,而是在其中启动应用程序spark-submit并在其中接收。但是,对于本地测试和单元测试,您可以传递“ local ”以在内部运行Spark Streaming(检测本地系统中的内核数)。请注意,这会在内部创建一个SparkContext(所有Spark功能的起点),可以通过访问ssc.sparkContext。
必须根据应用程序的延迟要求和可用的群集资源来设置批处理间隔。有关更多详细信息,请参见性能调整部分。
我们也可以从目前已有的StreamingContext来创建一个新的StreamingContext。
import org.apache.spark.streaming._
val sc = ... // existing SparkContext
val ssc = new StreamingContext(sc, Seconds(1))
定义上下文后,必须执行以下操作。
-
通过创建输入DStream定义输入源。
-
通过将转换和输出操作应用于DStream来定义流计算。
-
开始接收数据并使用进行处理streamingContext.start()。
-
等待使用停止处理(手动或由于任何错误),ssc.awaitTermination(-1L)来hold住整个streaming程序(让其超时关闭,或者自然报错关闭)
-
可以使用手动停止处理streamingContext.stop()。
注意:
- JVM中只能同时激活一个StreamingContext。
- StreamingContext上的stop()也会停止SparkContext。要仅停止的StreamingContext,设置可选的参数stop()叫做stopSparkContext假。
- 只要在创建下一个StreamingContext之前停止(不停止SparkContext)上一个StreamingContext,即可将SparkContext重新用于创建多个StreamingContext。
离散流(DStreams)
离散流或DStream是Spark Streaming提供的基本抽象。它表示连续的数据流,可以是从源接收的输入数据流,也可以是通过转换输入流生成的已处理数据流。在内部,DStream由一系列连续的RDD表示,这是Spark对不可变的分布式数据集的抽象(有关更多详细信息,请参见Spark编程指南)。DStream中的每个RDD都包含来自特定间隔的数据,如下图所示。
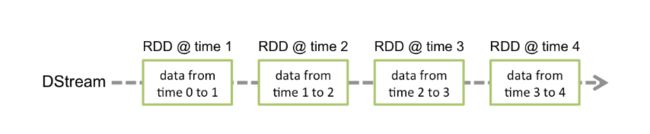
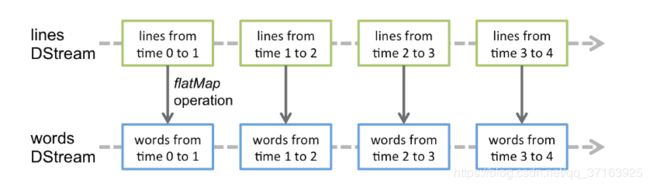
在DStream上执行的任何操作都转换为对基础RDD的操作。例如,在较早的将行流转换为单词的示例中,将flatMap操作应用于linesDStream中的每个RDD 以生成DStream的 wordsRDD。如下图所示。
Input DStreams 和 接收器
Input DStreams是表示从流源接收的输入数据流的DStream。在上面的例子中,lines输入DStream代表从netcat服务器接收的数据流。每个输入DStream(文件流除外,本节稍后将讨论)都与一个Receiver对象 (Scala doc, Java doc)关联,该对象从源接收数据并将其存储在Spark的内存中以进行处理。
Spark Streaming提供了两类内置的流媒体源。
- 基本来源:可直接在StreamingContext API中获得的来源。示例:文件系统和socket连接。
- 高级资源:可以通过额外的实用程序类获得诸如Kafka,Flume,Kinesis等资源。如连接部分所述,它们需要针对额外的依赖项进行连接。
如果要在流应用程序中并行接收多个数据流,则可以创建多个输入DStream(在“ 性能调整”部分中进一步讨论)。这将创建多个接收器,这些接收器将同时接收多个数据流。但是请注意,Spark worker/executor是一项长期运行的任务,因此它占用了分配给Spark Streaming应用程序的核心之一。因此,需要为Spark Streaming应用程序分配足够的内核(或线程,如果在本地运行),以处理接收到的数据以及运行接收器。
注意:
-
在本地运行Spark Streaming程序时,请勿使用“ local”或“ local [1]”作为主URL。这两种方式均意味着仅一个线程将用于本地运行任务。如果您使用的是基于接收器的输入DStream(例如套接字,Kafka,Flume等),则将使用单个线程来运行接收器,而不会留下任何线程来处理接收到的数据。因此,在本地运行时,请始终使用“ local [ n ]”作为主URL,其中n >要运行的接收者数(有关如何设置主服务器的信息,请参见Spark特性)。
-
为了将逻辑扩展到在集群上运行,分配给Spark Streaming应用程序的内核数必须大于接收器数。否则,系统将接收数据,但无法处理它。
基本数据源
我们已经ssc.socketTextStream(…)在快速示例中查看了,该示例根据通过TCP套接字连接接收的文本数据创建DStream。除套接字外,StreamingContext API还提供了从文件作为输入源创建DStream的方法。
文件流
要从与HDFS API兼容的任何文件系统(即HDFS,S3,NFS等)上的文件中读取数据,可以通过创建DStream StreamingContext.fileStream[KeyClass, ValueClass, InputFormatClass]。
文件流不需要运行接收器,因此无需分配任何内核来接收文件数据。
对于简单的文本文件,最简单的方法是StreamingContext.textFileStream(dataDirectory)。
监控目录:
Spark Streaming将监视目录dataDirectory并处理在该目录中创建的所有文件。
- 可以监视一个简单目录,例如"hdfs://namenode:8040/logs/"。发现后,将直接处理该路径下的所有文件。
提供了一个POSIX glob模式,例如 “hdfs://namenode:8040/logs/2017/*”。在此,DStream将包含与模式匹配的目录中的所有文件。也就是说:这是目录的模式,而不是目录中的文件。 - 所有文件必须使用相同的数据格式。
- 根据文件的修改时间而非创建时间,将其视为时间段的一部分。
- 处理后,在当前窗口中对文件的更改将不会导致重新读取该文件。即:忽略更新。
- 目录下的文件越多,扫描更改所需的时间就越长-即使未修改任何文件。
- 如果使用通配符来标识目录(例如)“hdfs://namenode:8040/logs/2016-*”,则重命名整个目录以匹配路径会将目录添加到受监视目录列表中。流中仅包含目录中修改时间在当前窗口内的文件。
- 调用FileSystem.setTimes() 修复时间戳是一种在以后的窗口中拾取文件的方法,即使其内容没有更改。
使用对象存储作为数据源
HDFS之类的“完整”文件系统往往会在创建输出流后立即对其文件设置修改时间。当打开文件时,甚至在完全写入数据之前,该文件也可能包含在DStream-之后,将忽略同一窗口中对该文件的更新。也就是说:更改可能会丢失,流中会省略数据。
为了确保在窗口中可以接收到更改,请将文件写入一个不受监视的目录,然后在关闭输出流后立即将其重命名为目标目录。如果重命名的文件在创建窗口期间显示在扫描的目标目录中,则将提取新数据。
相反,由于实际复制了数据,因此诸如Amazon S3和Azure存储之类的对象存储通常具有较慢的重命名操作。此外,重命名的对象可能具有rename()操作时间作为其修改时间,因此可能不被视为原始创建时间所暗示的窗口部分。
需要对目标对象存储进行仔细的测试,以验证存储的时间戳行为与Spark Streaming期望的一致。直接写入目标目录可能是通过所选对象存储流传输数据的适当策略。
基于自定义接收器的流
可以使用通过自定义接收器接收的数据流来创建DStream。有关更多详细信息,请参见《定制接收器指南》。
RDD队列流
为了使用测试数据测试Spark Streaming应用程序,还可以使用基于RDD队列创建DStream streamingContext.queueStream(queueOfRDDs)。推送到队列中的每个RDD将被视为DStream中的一批数据,并像流一样进行处理。
高级源
Python API从Spark 2.4.5开始,Python API中提供了上述来源中的Kafka,Kinesis和Flume。
这些高级资源如下。
Kafka: Spark Streaming 2.4.5与Kafka代理0.8.2.1或更高版本兼容。有关更多详细信息,请参见《Kafka集成指南》。
Flume: Spark Streaming 2.4.5与Flume 1.6.0兼容。有关更多详细信息,请参见《Flume集成指南》。
Kinesis: Spark Streaming 2.4.5与Kinesis Client Library 1.2.1兼容。有关更多详细信息,请参见《Kinesis集成指南》。
自定义源
Python API Python尚不支持此功能。
输入DStreams也可以从自定义数据源中创建。您所需要做的就是实现一个用户定义的接收器(请参阅下一节以了解其含义),该接收器可以从自定义源接收数据并将其推送到Spark中。有关详细信息,请参见《自定义接收器指南》。
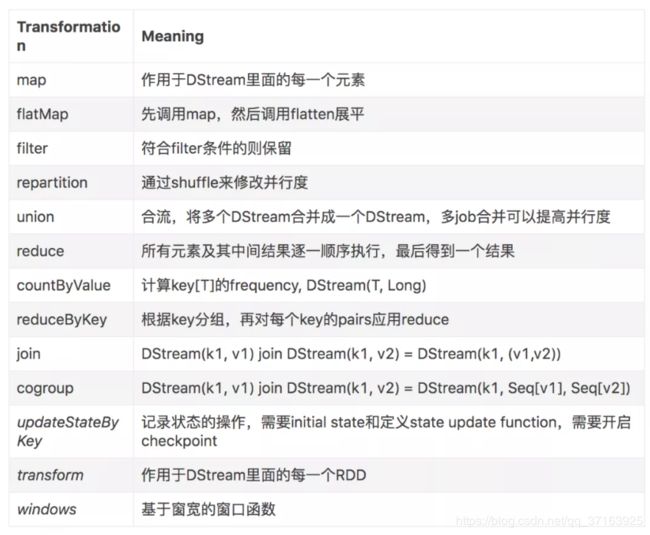
DStreams上的转换
与RDD相似,转换允许修改来自输入DStream的数据。DStream支持普通Spark RDD上可用的许多转换。一些常见的方法如下。
Transform 操作
transform操作(以及类似的变体transformWith)允许将任意RDD-to-RDD功能应用于DStream。它可用于应用DStream API中未公开的任何RDD操作。例如,将数据流中的每个批次与另一个数据集连接在一起的功能未直接在DStream API中公开。但是,您可以轻松地使用transform实现它。这实现了非常强大的可能性。例如,可以通过将输入数据流与预先计算的垃圾邮件信息(也可能由Spark生成)结合在一起,然后基于该信息进行过滤来进行实时数据清除。
val spamInfoRDD = ssc.sparkContext.newAPIHadoopRDD(...) // RDD containing spam information
val cleanedDStream = wordCounts.transform { rdd =>
rdd.join(spamInfoRDD).filter(...) // join data stream with spam information to do data cleaning
...
}
Window操作
Spark Streaming还提供了窗口计算,可让您在数据的滑动窗口上应用转换。下图说明了此滑动窗口。

如该图所示,每当窗口滑动在源DSTREAM,落入窗口内的源RDDS被组合及操作以产生RDDS的窗DSTREAM。在这种特定情况下,该操作将应用于数据的最后3个时间单位,并以2个时间单位滑动。这表明任何窗口操作都需要指定两个参数。
- 窗口长度 - 窗口的持续时间(图中3)。
- 滑动间隔 -进行窗口操作的间隔(图中为2)。
// Reduce last 30 seconds of data, every 10 seconds
val windowedWordCounts = pairs.reduceByKeyAndWindow((a:Int,b:Int) => (a + b), Seconds(30), Seconds(10))
一些常见的窗口操作如下。所有这些操作都采用上述两个参数-windowLength和slideInterval。

join 操作
在每个批处理间隔中,由生成的RDD stream1将与生成的RDD合并在一起stream2。你也可以做leftOuterJoin,rightOuterJoin,fullOuterJoin。此外,在流的窗口上进行连接通常非常有用。这也很容易。
val windowedStream1 = stream1.window(Seconds(20))
val windowedStream2 = stream2.window(Minutes(1))
val joinedStream = windowedStream1.join(windowedStream2)
DStreams上的输出操作
输出操作允许将DStream的数据推出到外部系统,例如数据库或文件系统。由于输出操作实际上允许外部系统使用转换后的数据,因此它们会触发所有DStream转换的实际执行(类似于RDD的操作)。当前,定义了以下输出操作:

使用foreachRDD的设计模式
通常,将数据写入外部系统需要创建一个连接对象(例如,到远程服务器的TCP连接),并使用该对象将数据发送到远程系统。为此,开发人员可能会无意间尝试在Spark驱动程序中创建连接对象,然后尝试在Spark worker中使用该对象以将记录保存在RDD中。例如(在Scala中),
dstream.foreachRDD { rdd =>
val connection = createNewConnection() // executed at the driver
rdd.foreach { record =>
connection.send(record) // executed at the worker
}
}
上面的是错误实例,因为connection产生在driver,但connection不能序列化到executor,所以connection.send(record)报错。
dstream.foreachRDD { rdd =>
rdd.foreach { record =>
val connection = createNewConnection()
connection.send(record)
connection.close()
}
}
上面是不推荐方式,因为需要为DStream里面的每一个元素都产生和销毁connection,而产生和销毁connection是昂贵的操作。
dstream.foreachRDD { rdd =>
rdd.foreachPartition { partitionOfRecords =>
val connection = createNewConnection()
partitionOfRecords.foreach(record => connection.send(record))
connection.close()
}
}
上面的方式,为每个rdd的partition产生一个connection,该connection产生于executor,可以用于send数据。
注意:
-
如果Streaming程序没有output operation,或者有output operation但是里面没有RDD的action算子,那么DSTream不会被执行。系统仅仅接收数据,然后丢弃之
-
默认情况下,output operation是串行执行
DataFrame和SQL操作
您可以轻松地对流数据使用DataFrames和SQL操作。您必须使用StreamingContext使用的SparkContext创建一个SparkSession。此外,必须这样做,以便可以在驱动程序故障时重新启动它。这是通过创建SparkSession的延迟实例化单例实例来完成的。在下面的示例中显示。它修改了前面的单词计数示例,以使用DataFrames和SQL生成单词计数。每个RDD都转换为一个DataFrame,注册为临时表,然后使用SQL查询。
/*
* Licensed to the Apache Software Foundation (ASF) under one or more
* contributor license agreements. See the NOTICE file distributed with
* this work for additional information regarding copyright ownership.
* The ASF licenses this file to You under the Apache License, Version 2.0
* (the "License"); you may not use this file except in compliance with
* the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
// scalastyle:off println
package org.apache.spark.examples.streaming
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.SparkSession
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.{Seconds, StreamingContext, Time}
/**
* Use DataFrames and SQL to count words in UTF8 encoded, '\n' delimited text received from the
* network every second.
*
* Usage: SqlNetworkWordCount
* and describe the TCP server that Spark Streaming would connect to receive data.
*
* To run this on your local machine, you need to first run a Netcat server
* `$ nc -lk 9999`
* and then run the example
* `$ bin/run-example org.apache.spark.examples.streaming.SqlNetworkWordCount localhost 9999`
*/
object SqlNetworkWordCount {
def main(args: Array[String]) {
if (args.length < 2) {
System.err.println("Usage: NetworkWordCount " )
System.exit(1)
}
StreamingExamples.setStreamingLogLevels()
// Create the context with a 2 second batch size
val sparkConf = new SparkConf().setAppName("SqlNetworkWordCount")
val ssc = new StreamingContext(sparkConf, Seconds(2))
// Create a socket stream on target ip:port and count the
// words in input stream of \n delimited text (eg. generated by 'nc')
// Note that no duplication in storage level only for running locally.
// Replication necessary in distributed scenario for fault tolerance.
val lines = ssc.socketTextStream(args(0), args(1).toInt, StorageLevel.MEMORY_AND_DISK_SER)
val words = lines.flatMap(_.split(" "))
// Convert RDDs of the words DStream to DataFrame and run SQL query
words.foreachRDD { (rdd: RDD[String], time: Time) =>
// Get the singleton instance of SparkSession
val spark = SparkSessionSingleton.getInstance(rdd.sparkContext.getConf)
import spark.implicits._
// Convert RDD[String] to RDD[case class] to DataFrame
val wordsDataFrame = rdd.map(w => Record(w)).toDF()
// Creates a temporary view using the DataFrame
wordsDataFrame.createOrReplaceTempView("words")
// Do word count on table using SQL and print it
val wordCountsDataFrame =
spark.sql("select word, count(*) as total from words group by word")
println(s"========= $time =========")
wordCountsDataFrame.show()
}
ssc.start()
ssc.awaitTermination()
}
}
/** Case class for converting RDD to DataFrame */
case class Record(word: String)
/** Lazily instantiated singleton instance of SparkSession */
object SparkSessionSingleton {
@transient private var instance: SparkSession = _
def getInstance(sparkConf: SparkConf): SparkSession = {
if (instance == null) {
instance = SparkSession
.builder
.config(sparkConf)
.getOrCreate()
}
instance
}
}
// scalastyle:on println
您还可以在来自不同线程的流数据定义的表上运行SQL查询(即与正在运行的StreamingContext异步)。只要确保将StreamingContext设置为记住足够的流数据即可运行查询。否则,不知道任何异步SQL查询的StreamingContext将在查询完成之前删除旧的流数据。例如,如果您要查询最后一批,但是查询可能需要5分钟才能运行,然后调用streamingContext.remember(Minutes(5))(使用Scala或其他语言的等效语言)。
请参阅DataFrames和SQL指南以了解有关DataFrames的更多信息。
MLlib操作
您还可以轻松使用MLlib提供的机器学习算法。首先,有流机器学习算法(例如,流线性回归,流KMeans等),可以同时从流数据中学习并将模型应用于流数据。除此之外,对于更多种类的机器学习算法,您可以离线学习学习模型(即使用历史数据),然后将模型在线应用于流数据。有关更多详细信息,请参见MLlib指南。
缓存/持久化
与RDD相似,DStreams还允许开发人员将流的数据持久存储在内存中。也就是说,persist()在DStream上使用该方法将自动将该DStream的每个RDD持久存储在内存中。如果DStream中的数据将被多次计算(例如,对同一数据进行多次操作),这将很有用。对于和的基于窗口的操作reduceByWindow和 reduceByKeyAndWindow和的基于状态的操作updateStateByKey,这都是隐含的。因此,由基于窗口的操作生成的DStream会自动保存在内存中,而无需开发人员调用persist()。
对于通过网络接收数据的输入流(例如,Kafka,Flume,套接字等),默认的持久性级别设置为将数据复制到两个节点以实现容错。
请注意,与RDD不同,DStream的默认持久性级别将数据序列化在内存中。性能调整部分将对此进行进一步讨论。有关不同持久性级别的更多信息,请参见《Spark编程指南》。
Checkpoint
流式应用程序必须24/7全天候运行,因此必须对与应用程序逻辑无关的故障(例如系统故障,JVM崩溃等)具有容忍性。为此,Spark Streaming需要将足够的信息检查点指向容错存储系统,以便可以从故障中恢复。检查点有两种类型的数据。
-
元数据检查点 -将定义流计算的信息保存到HDFS等容错存储中。这用于从运行流应用程序的驱动程序的节点的故障中恢复(稍后详细讨论)。元数据包括:
- 配置:用于创建流应用程序的配置。
- DStream操作 -定义流应用程序的DStream操作集。
- 不完整的批次 -作业排队但尚未完成的批次。
-
数据检查点 -将生成的RDD保存到可靠的存储中。在某些状态转换中,这是必须的,这些转换将跨多个批次的数据进行合并。在此类转换中,生成的RDD依赖于先前批次的RDD,这导致依赖项链的长度随时间不断增加。为了避免恢复时间的这种无限制的增加(与依存关系链成比例),有状态转换的中间RDD定期 检查点到可靠的存储(例如HDFS)以切断依存关系链。
何时启用Checkpoint
必须为具有以下任何要求的应用程序启用检查点:
- 有状态转换的用法 -如果在应用程序中使用updateStateByKey或reduceByKeyAndWindow(带有反函数),则必须提供检查点目录以允许定期进行RDD检查点。
- 从运行应用程序的驱动程序故障中恢复 -元数据检查点用于恢复进度信息。
如何配置Checkpoint
可以通过在容错,可靠的文件系统(例如,HDFS,S3等)中设置目录来启用检查点,将检查点信息保存到该目录中。这是通过使用streamingContext.checkpoint(checkpointDirectory)。这将允许您使用前面提到的有状态转换。此外,如果要使应用程序从驱动程序故障中恢复,则应重写流应用程序以具有以下行为。
- 程序首次启动时,它将创建一个新的StreamingContext,设置所有流,然后调用start()。
- 失败后重新启动程序时,它将根据检查点目录中的检查点数据重新创建StreamingContext。
创建Checkpoint代码示例
// Function to create and setup a new StreamingContext
def functionToCreateContext(): StreamingContext = {
val ssc = new StreamingContext(...) // new context
val lines = ssc.socketTextStream(...) // create DStreams
...
ssc.checkpoint(checkpointDirectory) // set checkpoint directory
ssc
}
// Get StreamingContext from checkpoint data or create a new one
val context = StreamingContext.getOrCreate(checkpointDirectory, functionToCreateContext _)
// Do additional setup on context that needs to be done,
// irrespective of whether it is being started or restarted
context. ...
// Start the context
context.start()
context.awaitTermination()
如果checkpointDirectory存在,则将根据检查点数据重新创建上下文。如果该目录不存在(即首次运行),则functionToCreateContext调用该函数以创建新上下文并设置DStreams。
注意: RDD的检查点会增加保存到可靠存储的成本。这可能会导致RDD被检查点的那些批次的处理时间增加。因此,需要仔细设置检查点的间隔。在小批量(例如1秒)时,每批检查点可能会大大降低操作吞吐量。相反,检查点太少会导致沿袭和任务规模增加,这可能会产生不利影响。对于需要RDD检查点的有状态转换,默认间隔为批处理间隔的倍数,至少应为10秒。可以使用设置 dstream.checkpoint(checkpointInterval)。通常,DStream的5-10个滑动间隔的检查点间隔是一个很好的尝试设置。
累加器,广播变量和检查点
无法从Spark Streaming中的检查点恢复累加器和广播变量。如果启用检查点并同时使用“ 累加器”或“ 广播”变量 ,则必须为“ 累加器”和“ 广播”变量创建延迟实例化的单例实例, 以便在驱动程序发生故障重新启动后可以重新实例化它们。在下面的示例中显示。
object WordBlacklist {
@volatile private var instance: Broadcast[Seq[String]] = null
def getInstance(sc: SparkContext): Broadcast[Seq[String]] = {
if (instance == null) {
synchronized {
if (instance == null) {
val wordBlacklist = Seq("a", "b", "c")
instance = sc.broadcast(wordBlacklist)
}
}
}
instance
}
}
object DroppedWordsCounter {
@volatile private var instance: LongAccumulator = null
def getInstance(sc: SparkContext): LongAccumulator = {
if (instance == null) {
synchronized {
if (instance == null) {
instance = sc.longAccumulator("WordsInBlacklistCounter")
}
}
}
instance
}
}
wordCounts.foreachRDD { (rdd: RDD[(String, Int)], time: Time) =>
// Get or register the blacklist Broadcast
val blacklist = WordBlacklist.getInstance(rdd.sparkContext)
// Get or register the droppedWordsCounter Accumulator
val droppedWordsCounter = DroppedWordsCounter.getInstance(rdd.sparkContext)
// Use blacklist to drop words and use droppedWordsCounter to count them
val counts = rdd.filter { case (word, count) =>
if (blacklist.value.contains(word)) {
droppedWordsCounter.add(count)
false
} else {
true
}
}.collect().mkString("[", ", ", "]")
val output = "Counts at time " + time + " " + counts
})