Hadoop-2.7.3完全分布式集群搭建(Centos7系统)
实验环境Centos7
使用Hadoop2.7.3和jdk1.8搭建4个结点的完全分布式,一个namenode,3个datanode
192.168.159.101 master
192.168.159.102 node1
192.168.159.103 node2
192.168.159.104 node3
1.首先做好准备工作
下载好对应的hadoop和jdk版本

2.创建虚拟机和用户
创建一个虚拟机master和hadoop用户,hadoop组。创建这些是为了便于管理且安全,如果是为了学习方便使用的话可以直接使用root用户。
如果没有则创建使用以下命令创建
groupadd hadoop
useradd hadoop -d /home/hadoop -g hadoop
3.永久关闭防火墙
先查看防火墙状态systemctl status firewalld.service
如果还在运行则关闭防火墙systemctl stop firewalld.service
禁用防火墙systemctl disable firewalld.service
4.将hadoop和jdk传至虚拟机中
如果安装过Vmware Tools则可以直接从本机将文件拖如虚拟机中。如果没有,可以使用传输工具进行传输,例如xshell或其他工具,记下文件的位置。
传输完成后创建目录,将hadoop和jdk分别放在hadoop和Java目录中(如果创建了用户则需要注意创建的文件和目录的权限问题,即使用集群的用户一定要有权限)
mkdir /home/hadoop/hadoop2.7
mkdir /home/java/jdk1.8
mv /.... /home/hadoop/hadoop2.7
mv /.... /home/java/jdk1.8
将hadoop和jdk分别解压
tar -zxvf /home/hadoop/hadoop2.7/hadoop.2.7.tar.gz(路径可以自己修改,对应即可)
tar -zxvf /home/java/jdk1.8/jdk1.8.tar.gz
5.配置环境变量
vi /etc/profile 编辑环境变量配置文件,添加或修改环境变量(有些系统可能有jdk工具,不要使用系统安装的openjdk,使用自己的jdk)。
添加jdk和hadoop的环境变量(路径设置为自己存放的目录)
export JAVA_HOME=/home/java/jdk1.8
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export HADOOP_HOME=/home/hadoop/hadoop2.7
export HADOOP_LOG_DIR=/home/hadoop/hadoop2.7/logs
export YARN_LOG_DIR=$HADOOP_LOG_DIR
export PATH=.:$HADOOP_HOME/sbin:$HADOOP_HOME/bin:$JAVA_HOME/bin:$PATH
6.验证环境变量
输入 source /etc/profile 更新环境变量
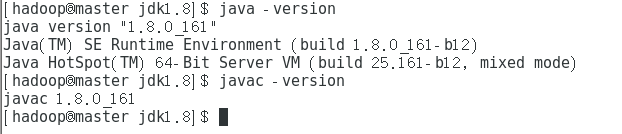
输入 java -version 和 javac -version,看有无版本信息输出
输入hadoop,同样看是否出现提示信息
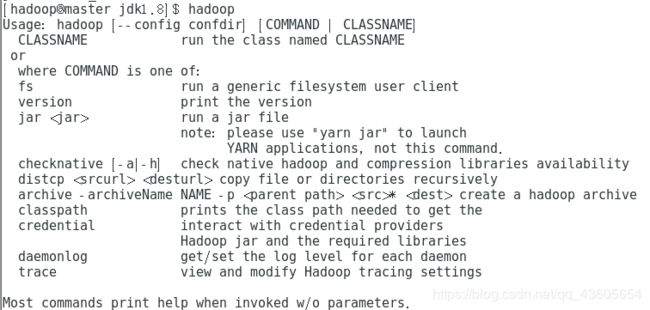
如果有提示信息输出,则说明配置正确,如果没有仔细检查环境变量
7.创建目录
mkdir /home/hadoop/hadoop2.7/tmp 用来存放临时文件
mkdir /home/hadoop/hadoop2.7/logs 用来存放日志文件
mkdir /home/hadoop/hadoop2.7/hdfs 用来存储集群数据
mkdir /home/hadoop/hadoop2.7/hdfs/name 用来存储文件系统元数据
mkdir /home/hadoop/hadoop2.7/hdfs/data 用来存储真正的数据
8.进入hadoop解压后的目录下,找到两个.sh文件,修改JAVA_HOME的值
cd etc/hadoop
vi hadoop-env.sh
修改JAVA_HOME的值,指向存放Jdk的路径
export JAVA_HOME=/home/java/jdk1.8/
vi yarn-env.sh
修改JAVA_HOME的路径
export JAVA_HOME=/home/java/jdk1.8/
9.修改核心配置文件
vi core-site.xml
在配置标签中添加
fs.default.name
hdfs://master:9000
指定HDFS的默认名称
fs.defaultFS
hdfs://master:9000
HDFS的URI
hadoop.tmp.dir
/home/hadoop/hadoop2.7/tmp
节点上本地的hadoop临时文件夹

vi hdfs-site.xml
在配置标签中添加
dfs.namenode.name.dir
file:/home/hadoop/hadoop2.7/hdfs/name
namenode上存储hdfs名字空间元数据
dfs.datanode.data.dir
file:/home/hadoop/hadoop2.7/hdfs/data
datanode上数据块的物理存储位置
dfs.replication
1
副本个数,默认是3,应小于datanode机器数量

输入 cp mapred-site.xml.template mapred-site.xml 将mapred-site.xml.template文件复制到当前目录,并重命名为mapred-site.xml
vi mapred-site.xml
在配置标签中添加
mapreduce.framework.name
yarn
指定mapreduce使用yarn框架

vi yarn-site.xml
在配置标签中添加
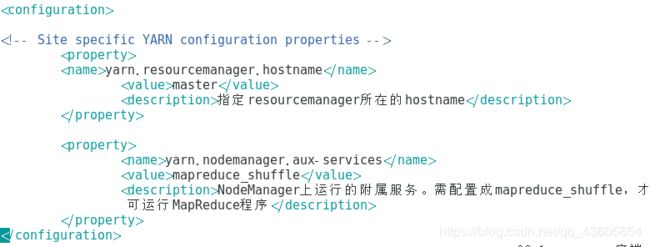
yarn.resourcemanager.hostname
master
指定resourcemanager所在的hostname
yarn.nodemanager.aux-services
mapreduce_shuffle
NodeManager上运行的附属服务。需配置成mapreduce_shuffle,才可运行 MapReduce程序
vi slaves
删除localhost,改为datanode的主机名
node1
node2
node310.克隆虚拟机
使用Vmware的克隆功能,完整克隆master

11.修改主机名
vi /etc/hostname
配置每一台主机,把localhost删除,修改为节点对应的名称,master,node1,node2,node3,如master修改为master
![]()
12.配置网络
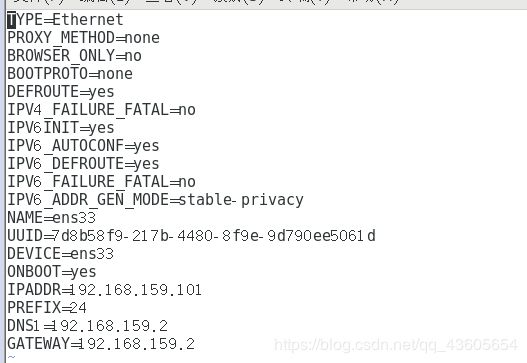
vi /etc/sysconfig/network-script/ifcfg-ens33 这里不同的系统可能网络接口名不同
将每一台主机配置为对应的ip地址,如master修改为192.168.159.101
重启网络服务 service network restart ,查看修改是否成功
13.修改每一台主机的/etc/hosts文件
vi /etc/hosts
添加
192.168.159.101 master
192.168.159.102 node1
192.168.159.103 node2
192.168.159.104 node3注意要与实际Ip和主机名对应
14.配置ssh免密登录
原理:通过创建无密码公钥的方式,将公钥传给对方。使用ssh协议连接时,会寻找authorized_keys文件中存放的公钥,如果有目标主机的公钥则将公钥传给目标主机,目标主机用自己的私钥和公钥进行匹配,正确匹配之后则认为两者可信,即不需要密码就可以登录
实现节点之间免密服务原理:
通过把所有节点的公钥写入authorized_keys文件中,再把这个文件传输给每一台节点,此时所有节点都有了其他节点的公钥,则登录时就不需要输入密码
在每台主机上输入 ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa 创建一个无密码的公钥,-t是类型的意思,dsa是生成的密钥类型,-P是密码,’’表示无密码,-f后是秘钥生成后保存的位置
创建完成后,会出现两个文件
id_dsa 存放私钥
id_dsa.pub 存放公钥
输入 cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys 将公钥id_dsa.pub添加进authorized_keys
执行后会创建authorized_keys文件,这个文件用来放其他节点的公钥。
在非master节点上输入 ssh-copy-id -i ~/.ssh/id_dsa.pub master 将自己的公钥传输给master节点。
这时,master节点拥有所有节点的公钥。
在master中输入
scp -r /用户家目录/.ssh/authorized_keys 用户@主机名:/对应用户的家目录/.ssh/
scp -r /home/hadoop/.ssh/authorized_keys root@node1:/home/hadoop/.ssh/
scp -r /home/hadoop/.ssh/authorized_keys root@node2:/home/hadoop/.ssh/
scp -r /home/hadoop/.ssh/authorized_keys root@node3:/home/hadoop/.ssh/
在每一台主机上输入 chmod 600 authorized_keys 修改文件权限
重启服务 service sshd restart
此时每个节点都保存了所有的公钥,节点之间也就可以ssh免密登录了(第一次仍然需要密码)
15.格式化hdfs
在master机器上输入 hdfs namenode -format 格式化namenode,第一次使用需格式化一次,之后就不用再格式化,如果修改了一些配置文件,则需要重新格式化。(由于配置了环境变量任意位置执行都可以)
hdfs namenode -format
16.启动hadoop
如果没有配置环境变量则进入hadoop下的sbin目录
输入 start-all.sh,输入yes即可启动
17.使用jps查看每个节点的进程
master节点有4个进程
NameNode
SecondaryNameNode
ResourceManager
Jps
其他节点(slave)有3个进程
DataNode
NodeManager
Jps
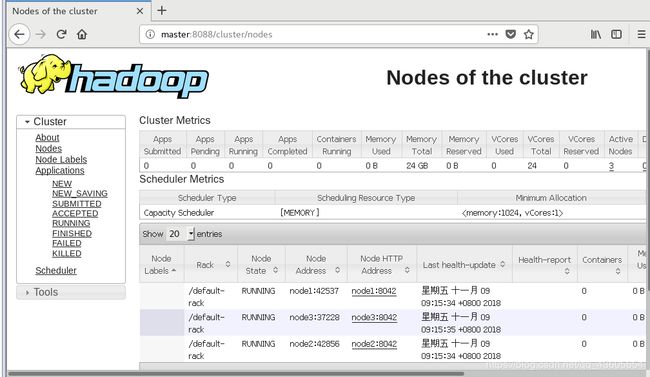
18.用web端查看节点信息
在浏览器打开master:8088或master:50070
打开后显示节点的信息并都正常运行,即搭建成功
19.关闭集群
在sbin目录下输入stop-all.sh即可关闭
如果文章对你有用的话就点个赞鼓励一下吧!