可用于深度学习的源代码漏洞数据分析
可用于深度学习的源代码漏洞数据分析
- 介绍
海量的数据是应用人工智能的基石,深入了解数据有利于进一步开展相关研究。这批可用于深度学习的源代码漏洞数据来源于NDSS’18的VulDeePecker[1]提供的数据集,其数据均属于C/C++程序切片,通过从源代码中的某些可能与漏洞相关的API库函数为关注点根据数据流相关性前向后向提取语句组成程序切片,每个切片样本有对应的0或1标签,0表示无漏洞,1表示有漏洞。这些数据来源于NIST参考数据集SARD和美国国家漏洞数据库NVD,漏洞类型分为CWE-119和CWE-399。
- 程序切片
程序切片是指从程序P中提取和关注点N有关的指令而不包含无关的指令,切片S与源程序P在一定的切片准则下的语义是一致的,即保留了完整程序语义的同时减少了无关指令的干扰。1979年,美国Mark Weise首次提出了程序切片思想,在程序控制流图(CFG)上建立了数据流方程。1984年,K.J.Ottenstein 和 L.M.Ottenstein提出了程序依赖图(PDG),后续又提出了系统依赖图(SDG),从而使提取切片的基础方法分为数据流方程算法、基于PDG的图可达算法和基于SDG的图可达算法。
切片方向可以分为后向切片和前向切片,其中后向切片是为了寻找与程序P中对关注点N有影响的语句,出现在关注点的前面;前向切片是寻找程序P中会受到关注点N影响的语句,出现在关注点的后面。在该数据集中,单个切片是以可能存在风险的API库函数为关注点,依据程序的数据流相关性对程序P进行后向切片和前向切片的并集。
更多程序切片的相关知识参见[2]。
- 数据处理
具体的数据处理内容包括对文本文件进行拆分,分别读取每一个切片;对切片进行词法分析,删除程序中的注释,并将切片文本转换为每个元素为一个词的列表;将单个切片内的用户自定义变量名和自定义函数名进行映射,即使用“variable_m”、“function_n”对自定义变量名和函数名进行替换,以避免自定义函数名和变量名对切片的漏洞语义信息产生干扰;记录每个切片的语料、行号、标签等信息用于数据分析;最后对切片数据进行了去重处理,包括对语料相同且标签相同的样本只保留一个,对语料相同而标签不同的样本予以删除(本次试验中共发现前者37388组,后者1148组)。
以单个切片为例,原始的切片(上)和对应的处理后的语料(下)如下:
| data = NULL; if(staticFalse) printLine("Benign, fixed string"); else data = new char[10+1]; char source[10+1] = SRC_STRING; strncpy(data, source, strlen(source) + 1); |
| ['variable_0', '=', 'NULL', ';', 'if', '(', 'variable_1', ')', 'func_0', '(', 'string_len18', ')', ';', 'variable_0', '=', 'new', 'char', '[', '10', '+', '1', ']', ';', 'char', 'variable_2', '[', '10', '+', '1', ']', '=', 'variable_3', ';', 'strncpy', '(', 'variable_0', ',', 'variable_2', ',', 'strlen', '(', 'variable_2', ')', '+', '1', ')', ';'] |
- 分析结果
1. 切片来源
数据处理完后的切片总数为48005,总testcase(即单个软件项目)数为9919。SARD切片数量为45605,来源于9851个testcase;NVD切片数量为2400,来源于68个testcase。由此可见在NVD此类真实软件数据中单个testcase提取出的切片量更大,在SARD这类简单数据集中能够提出的切片量更少。

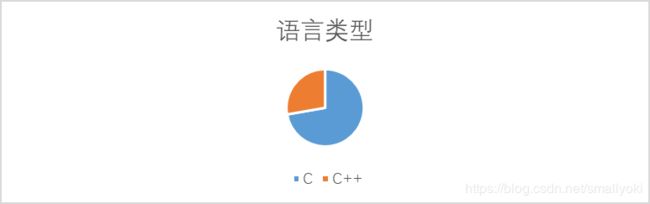
C语言切片和C++语言切片数分别为34681和13324,占比分别为72%和28%。
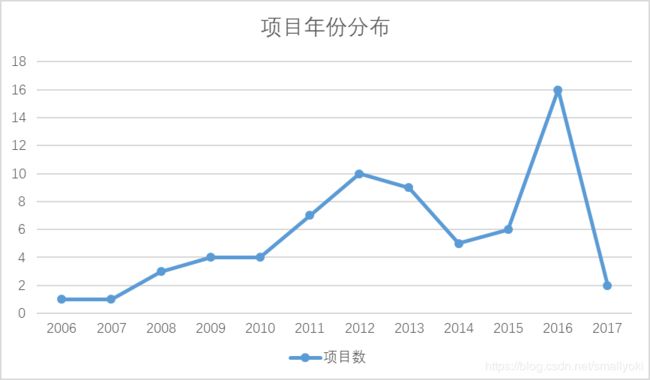
NVD的数据涵盖从2006年到2017年的数据,漏洞数据的年份分布如下:
NVD数据的软件来源分布如下:
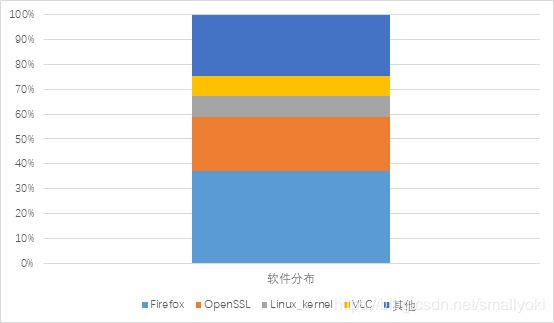
'Firefox': 888, 'OpenSSL': 528, 'linux': 196, 'vlc': 191, 'qemu': 184, 'Ffmpeg': 162, 'cups': 108, 'Wireshark': 102, 'xen': 21, 'Apachehttpserver': 20。
2. 数据性质
有无漏洞数据量分别为14775和33230,比例为1:2.25。其中SARD数据的有无漏洞数据量分别为13791和31814,比例为1:2.31;NVD数据的有无漏洞数据量分别为984和1416,比例为1:1.44。
整个数据集的语料库词汇表长度为909。
长度统计分为切片语料长度统计和切片行数统计。切片语料长度统计中,平均值为93,中位数为75,90%的切片语料长度在153以内,98%的切片语料长度在340以内。其中SARD数据的平均长度为89,中位数为74,98%的切片在295以内;NVD数据的平均长度为178,中位数为139,98%的切片在693以内。切片行数统计中平均每个程序切片长度为9.1行,中位数为7行,98%的切片在30行以内。SARD数据的平均行数为8.6行,中位数为7行,98%的切片在27行以内;NVD数据的平均行数为18.2,中位数为15,98%的切片在68行以内。由此可见对于真实数据通常程序切片较长,在后续输入深度学习模型如何解决真实软件切片过长的问题是需要克服的难题之一。
3. 漏洞类型
漏洞类型为CWE-119的切片数为32450,漏洞类型为CWE-399的切片数为15555。
对于SARD中的数据,其细分的CWE类型则有45个,按照细分的漏洞类型对testcase统计的结果如下:
'CWE-122': 2850, 'CWE-121': 2585, 'CWE-789': 910, 'CWE-124': 894, 'CWE-127': 508, 'CWE-761': 427, 'CWE-680': 306, 'CWE-134': 227, 'CWE-126': 129, 'CWE-400': 91, 'CWE-785': 76, 'CWE-416': 76, 'CWE-805': 76, 'CWE-120': 73, 'CWE-806': 72, 'CWE-775': 54, 'CWE-774': 51, 'CWE-771': 50, 'CWE-414': 48, 'CWE-412': 48, 'CWE-773': 47, 'CWE-824': 44, 'CWE-119': 39, 'CWE-415': 27, 'CWE-822': 19, 'CWE-123': 19, 'CWE-476': 19, 'CWE-190': 12, 'CWE-561': 7, 'CWE-401': 6, 'CWE-704': 4, 'CWE-468': 3, 'CWE-835': 3, 'CWE-197': 2, 'CWE-590': 2, 'CWE-194': 2, 'CWE-825': 2, 'CWE-765': 1, 'CWE-762': 1, 'CWE-668': 1, 'CWE-675': 1, 'CWE-399': 1, 'CWE-839': 1, 'CWE-843': 1, 'CWE-457': 1。
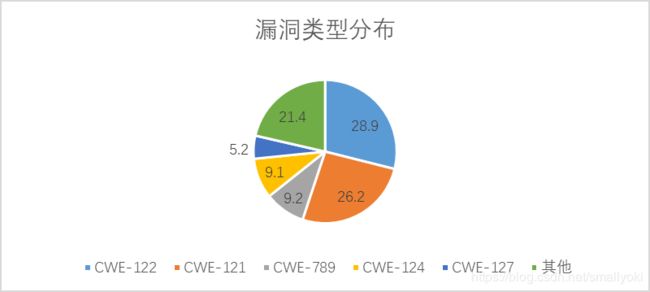
在漏洞数据中,CWE-119和CWE-399分别对应从内存分配的缓冲区域之外进行读写(Improper Restriction of Operations within the Bounds of a Memory Buffer)和不可靠的系统资源管理(Improper management of System Resources),而其在SARD数据中出现较多的子类包括CWE-122这类常使用malloc分配内存导致的堆积溢出漏洞类型(Heap-based Buffer Overflow)、CWE-121栈基溢出(Stack-based Buffer Overflow)、CWE-789不受信任的参数导致允许分配任意数量的内存(Uncontrolled Memory Allocation)等。
参考文献
[1] https://github.com/CGCL-codes/VulDeePecker
[2] Silva, Josep. A vocabulary of program slicing-based techniques[J]. ACM Computing Surveys, 2012, 44(3):1-41.