1 spark内核架构

过程如下:
首先:
①、用户通过spark-submit提交自己编写的程序(jar、py)。
②、一般认为上述的提交方式为Standlone,其会通过反射的方式,创建和构造一个DriverActor进程出来。
③、Driver执行我们的Application应用程序(我们编写的代码),此时代码里是先构建sparkConf,再构建SparkCpntext。
④、⑤ SparkContext在初始化的时候,做的最重要的两件事就是构建DAGScheduler和TaskScheduler。
⑥、构建完TaskScheduler之后,它(TaskScheduler)会通过本身对应的一个后台进程去spark集群上链接Master,向Master注册Application。Master接收到application的注册请求后,会使用自己的资源调度算法,在spark集群的worker中,为这个application启动多个executor。
⑦、master通知worker启动executor后,worker会为application启动executor。
⑧、executor启动之后,会自己反向注册到taskScheduler上。
然后:
每执行到一个action(自己编写的代码里面的比如count、show、join等操作),就会创建一个job。
这个job会提交给DAGscheduler,DAGscheduler会将这个job通过算法规则划分为多个stage,然后每个stage创建一个taskSet。
taskScheduler通过task分配算法会将taskSet中的每一个task提交到executor上执行。
executor每接收到一个task,都会用taskRunner(taskRunner将我们编写的代码,也就是执行的算子及函数,进行拷贝、反序列化)来封装task,然后从线程池中取出一个线程来执行这个task。
task分为两种,shufleMapTask和resultTask。只有最后一个stage是resultTask,之前的stage中的都是shuffleMapTask。
最后:
整个spark应用程序的执行,就是stage分批次作为taskSet,提交到executor上执行,每个task针对RDD的一个partition,执行我们定义的算子和函数。以此类推,直到所有操作执行完为止。
2.宽依赖和窄依赖

如图,以word count为例。
窄依赖:Narrow dependency,一个RDD,对应它的父RDD,只有一个简单的一对一依赖关系。也就是说,RDD的每个partition仅仅依赖父RDD的一个partition,父RDD和子RDD的partition是一一对应关系。如上图中的①和②操作。
宽依赖:shuffle dependency,本质如其名,就是shuffle。每一个父RDD的partition和子RDD的partition有交错复杂的关系,它们(父和子)之间发生的操作就是shuffle。
3. 基于yarn的两种提交模式

cluster模式
①、用户向Yarn集群的resourcesManger(RM)通过spark-submit提交应用程序,请求启动ApplicationMaster。
②、RM在nodeManager中找到一个container,启动applicationMaster(AM)。---相当于driver,driver在集群上
③、AM找RM,请求contain来启动executor。
④、RM返回一批container给AM,用于启动executor。
⑤、AM连接其他的nodeManager,来启动executor。这里的nodeManager相当于worker
⑥、executor启动后,反向向AM注册。最后再如本文章中1.1章节提到的进行计算。

client模式
①、用户向Yarn集群的resourcesManger(RM)通过spark-submit提交应用程序,请求启动ApplicationMaster。
②、RM在nodeManager中找到一个container,启动applicationMaster(AM)。---相当于executorLancher,只负责向RM申请container
③、AM找RM,请求contain来启动executor。
④、RM返回一批container给AM,用于启动executor。
⑤、AM连接其他的nodeManager,来启动executor。这里的nodeManager相当于worker
⑥、executor启动后,反向向driver注册。最后再如本文章中1.1章节提到的进行计算。 ---driver在本机上
client vs cluster
1.client用于测试,因为driver在本地客户端,负责调度application(DAGScheduler、taskScheduler),会与yarn集群产生超大量的网络通信,导致网卡流量激增,可能会被公司SA(运维)警告。但好处在于本地可以看到所有的log,便于调试。
2.cluster用于生产环境,因为driver运行在NodeManager上没有流量激增问题。但只能通过yarn application这种命令来查看log,不便于调试。
4. spark context原理
spark context包含了taskScheduler、DAGScheduler、spark UI三部分。

TaskScheduler的初始化机制
①、首先sparkContext调用createTaskScheduler()方法。
②、createTaskScheduler()里面包含了三个方法:
taskSchedulerImpl就是我们所说的TaskScheduler 。
sparkDeploySchedulerBackend()方法在底层接收 taskSchedulerImpl的控制,实际上负责与master的注册、executor的反向注册、task发送到executor等操作。
SchedulerPool有不同的优先策略,比如FIFO。
③、通过上述流程启动executor。
④、executor反向注册到sparkDeploySchedulerBackend上。
DAGScheduler初始化机制

DAGScheduler底层是基于该组件进行通信的(是一个进程)。
spark UI初始化机制

5. master原理

worker、driver、 application 注册机制
如上图所示,worker(蓝色)、driver(红色)、application(绿色)在向master进行注册的流程:
①、worker:worker在启动后,就会主动向master进行注册
②、driver:用spark-submit提交sparkapplication的时候,首先会注册driver。
③、application:driver启动好后,执行用户编写的application程序,执行sparkContext初始化,底层的sparkDeploySchedulerBackend会通过appClient内部的线程启动clientActor发送registerApplication到master上,进行application的注册。

master主备切换机制
spark master主备切换,可以基于文件系统和Zookeeper。基于文件系统的主备切换机制,需要在active master挂掉之后手动去切换到standby master上;而基于zookeeper的主备切换是自动的。
主备切换,实际上指的是:active master挂掉之后,切换到standby master时,master会做哪些操作(如上图所示)。

driver调度机制
只有当时spark-submit为cluster模式时,才会通过上述图描述的过程进行driver的调度,因为client和standalone都会在本地初始化一个worker。
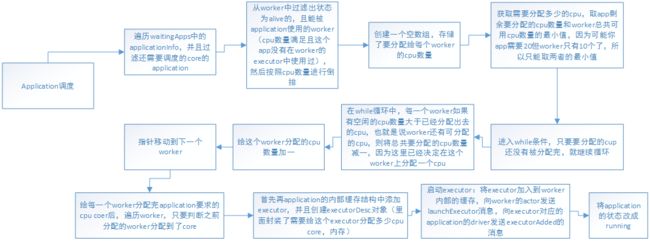
application调度机制
分为两种调度机制:
①、spreadOutApps:如上流程图所示:当在spark conf里设置了时,就会使用第一种方法进行调度,该方法其实会将每个application及要启动的executor,平均分配到各个worker中。
比如有20个cpu core要分配,那么实际上就会遍历两次worker,每次循环会给每个worker分配一个core,最后每个worker分配到2个core。
在这种机制中,实际上最后的executor个数和每个executor的cpu个数,可能的和配置(spark conf)指定的不一样,因为这里是基于总的cpu来分配的。比如要
求3个executor、每个executor3个cpu,但实际上有9个worker,每个worker有1个cpu,那么其实总共知道要分配9个core,根据这种机制,会给每一个worker分配一个core,
然后每个worker启动一个executor,最后变成启动了9个executor,每个executor一个cpu core。
②、非spreadOutApps:将每一个application,近可能少的分配到worker上。首先遍历worker,并且状态为alive且有空闲的cpu的--》在循环内部,遍历application,并且是还需要分配core的application--》
判断,如果当前这个worker可以被application使用---》取worker剩余cpu数量与app要分配的cup数量的最小值--》给app添加一个executor--》在worker上启动executor--》将app的状态改成running。
这种算法和spreadOutApps正好相反,每个app都尽可能分配到尽可能少的worker上去。比如总共有10个worker,每个有10个core,app总共要分配20个core,那么该机制只会分配
到两个worker上,每个worker都占满10个core,剩余的app就只能分配到下一个worker上。
6. worker原理

master启动driver和executor,都是通过发送launchDriver和launchExecutor:
①、Driver:worker启动driver的基本原理,就是worker内部会启动一个线程(driverRunner),然后driverRunner会去负责启动driver进程,并在之后对driver进程进行管理。
②、Executor:跟driver启动差不多,executorRunner进程去启动和关联executor。executor启动之后,会向driver进行注册。
7. job原理
用户提交的application会包含多个job,一个job就是一个action。比如如下例子,会有一个什么样的流程:
val lines=sc.textFile()
val words=lines.flatMap(line=>line.split(" "))
val paris=words.map(word=>(word,1))
val counts=paris.reduceByKey(_+_)
counts.foreach(count=>println(count._1+":"count._2))
前面四个都是在进行transformation的操作,最后的foreach的print才会触发action操作。
①、首先,对于sc.textFile()这个操作,hadoopFile()方法会创建一个hadoopRDD,其中的元素其实就是(key,value)的pair,key为hdfs文件或者文本文件的每一行offset(可以认为是索引、行号),value就是文本行。
然后,对hadoopRDD调用map()方法,剔除key,只保留value,从而获取到一个mapPartitionsRDD,这个RDD的内部其实就是一行一行的文本行。
②、对mapPartitionsRDD调用flatMap()方法,按照一定规则(比如按照“ ”对每一行文本进行split展开,原一行文本形成多行文本)生成一个新的mapPartitionsRDD。
③、调用map()方法,为每一个mapPartitionsRDD附上value,形成key-value对。
④、其实RDD里面是没有reduceByKey的,因此对RDD调用reduceByKey()方法时,会触发scala的隐式转换,此时在作用域内寻找隐式转换,会在RDD中找到rddToPairRDDFunctions(),然后将RDD转变成PairRDDFunctions,
接着调用PairRDDFunctions中的reduceByKey()方法。
⑤、foreach是一个action,它会去调用spark context中的runJob()方法。runJob()方法中,会去调用spark context初始化时创建的DAGScheduler的runJob()方法,RDD作为入参。
8. DAG scheduler原理
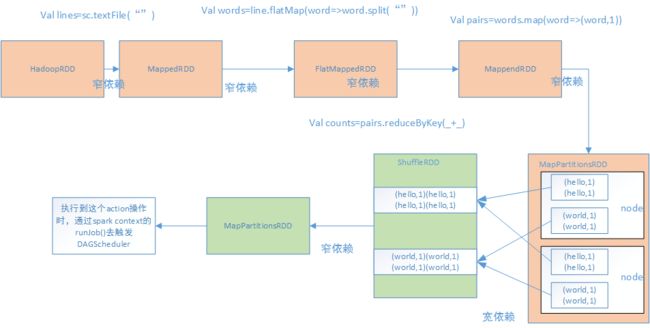
如图所示,还是以worldCount为例子,上面整个步骤,就是一个job,每个job之间以action为界限,需要注意如下:
①、在执行reduceByKey前,对mappendRDD使用hashPartitioner,将每个key写入到对应的partition的本地磁盘文件中(设置了多少个partition就会有多少个文件,partition会分布在不同的node上)。
②、mapPartitionsRDD其实代表了本地文件的RDD,按照key存放在不同的partition中。
③、shuffleRDD相当于一个中间性质的RDD。
DAGScheduler划分stage:
从会触发action操作的那个RDD开始往前倒推,为最后一个RDD创建一个stage,然后往前发现前面一个RDD是窄依赖则把这个RDD纳入到这个stage中;当发现某个RDD是宽依赖时,
为这个RDD创建一个新的stage,这个RDD就是这个新stage的最后一个RDD,依次往前,根据宽、窄依赖进行划分stage。
如上图,stage0:橙色,stage1:绿色。
9. task schedule原理
taskManager
①、针对stage的task,创建taskSet对象,调用taskScheduler的submitTasks()方法,提交taskSet。----默认情况下使用standalone是使用的taskSchedulerImpl,taskScheduler只是一个trait。
②、submitTasks()会给每一个taskSet创建一个taskManager,taskManager会负责它对应taskSet的任务执行状况的监视和管理。
③、在taskSchedulerImpl中,对每一个单独的taskSet的任务进行调度,这个类负责追踪每一个task,如果task失败则会负责重试,直到超过重试的次数,并且会通过延迟调度,为这
个taskSet处理本地化调度机制。它的主要接口是resourceOffer。在resourceOffer中,taskSet会希望在一个节点上运行一个任务,并且接收任务的状态改变消息,来知道它负责的task的状态改变了。
sparkDeploySchedulerBackend
(在上述章节中提到过,在创建taskScheduler的时候,就是为taskSchedulerImpl创建一个sparkDeploySchedulerBackend。其主要功能是负责创建appClient,向master创建application):
①、sparkDeploySchedulerBackend继承了coarseGrainedSchedulerBackend这个父类。在这个父类中,主要有一个类较makeOffers()。
②、makeOffers():
第一步就是调用taskSchedulerImpl的resources的resourceOffers()方法,执行任务分配算法,将各个task分配到executor上。
第二步,分配好task到executor后,执行自己的launchTask()方法,将分配的task发送launchTask消息到对应的executor上,有executor启动执行task。
③、task分配算法有resourceOffer()方法实现:
该方法传入的是application所有可用的executor,并且将其封装成workerOffer,每个workerOffer代表了传入的是这个executor可用的cpu资源数量。
首先,将可用的executor进行shuffle(打散),从而尽量做到负载均衡。
然后针对workerOffer创建一堆需要用的东西,比如tasks(一个二维数组arrayBuffer,元素又是另外一个arrayBuffer,并且每个子arrarBuffer的数量都是固定的,也就是这个executor可用的cpu数量)。
再从rootPool中取出了排序的taskSet。这里的rootPool是在创建完taskSchedulerImpl和sparkDeploySchedulerBackend之后,执行一个initialize()方法,在这个方法中创建了一个调度池。 然后在执行task分配算法的时候,从这个调度池rootPool中,取出排好队的taskSet。
任务分配算法核心:
双重for循环,遍历所有的taskSet和每一种本地化级别:
本地化级别分为:PROCESS_LOCAL--进程本地化,相当于RDD的partition和task进入同一个executor内,速度最快;
NODE_LOCAL--rdd的partition和task不在一个executor上,不在一个进程中,但在一个worker节点上;
NO_PREF---,无,没有本地化级别;
RACK_LOCAL----,机架本地化,rdd的partition和task,在一个机架上。
ANY---任意的本地化级别。
以上本地化,从上到下,从好到怀。
a、首先,对每一个taskSet,从最好的本地化级别开始进行遍历;
b、然后,对当前的taskSet尝试使用最小的本地化级别,将taskSet的task,在executor上进行启动。
c、如果启动不了,则跳出循环,进入下一种本地化级别,以此类推,逐渐放大本地化级别,直到将taskSet在某本地化级别下,让task在executor上全部启动。
这里的task启动流程如下:
首先,遍历所有的executor,如果当前的executor的cpu数量至少大于每个task要使用的cpu数量(默认为1),则调用taskManager的resourceOffer方法,去找到在这个executor上,就用这种本地化级别(上述已经确定)来确定哪些task可以启动。
10. executor原理
executor的启动主要在coarseGrainedExecutorBackend(粗粒度的ExecutorBackend)中实现,包括以下流程:
①、初始化actor:获取diver的actor,向driver发送registerExecutor的消息。
②、注册成功后,dirver返回给coarseGrainedExecutorBackend一个registeredExecutor消息。
③、接收到消息后,coarseGrainedExecutorBackend会创建一个executor对象,这个对象中包含了launchTask和killTask等方法,它的大部分功能都是通过executor实现的。
启动task流程:把task给反序列化(发送过来的是序列化之后的),然后用内部的执行句柄--executor的launchTask()方法,启动一个task。
launchTask流程:对于每一个task,都会创建一个taskRunner,这个taskRunner继承的是java的多线程中runable接口。然后将taskRunner放入内存缓存runningTasks。这里基本是java多线程的运行原理了。
11.task运行原理

12.shuffle原理(重点)
什么情况下会发生shuffle
reduceByKey、groupByKey、sortByKey、countByKey、join、cogroup等操作。
默认的shuffle
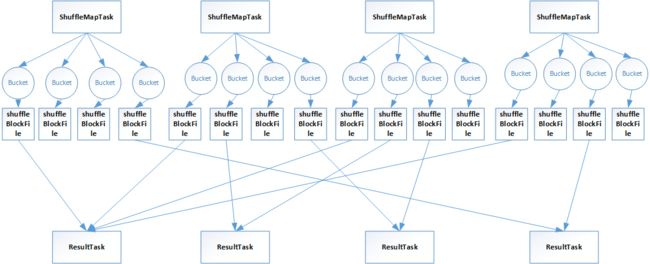
举例,比如有一个节点,上面运行4个shuffleMapTask,然后这个节点上只有两个cpu core。另外假设另外一个节点,上面运行了4个resultTask,等着shuffleMapTask的输出结果,来完成一些操作(比如reduceByKey等)。
其过程如下:
首先,每个shuffleMapTask,都会为每个resultTask创建一份bucket内存缓存,以及对应的shuffleBlockFile磁盘文件。---这是因为在resultTask中,需要按照相同的key进行处理,比如shuffleMapTask中有hello、world、you等key,
需要把它们按照相同的key放在一起。
其次,shuffleMapTask的输出,会作为mapStatus,发送给driver的DAGScheduler中的mapOutputTrackerMaster中。这个mapStatus包含了resultTask要拉取的数据的大小等信息。
最后,resultTask通过mapOutputTrackerMaster,获取需要拉取的数据及相应的位置信息等,然后通过blockManager去将对应的shuffleBlockFile磁盘文件中去拉取数据。比如某个resultTask都去对应的shuffleBlockFile
拉取hello这个key。每个resultTask拉取过来的数据,其实在内部会组成一个shuffleRDD,这个RDD优先写入内存,如果内存不足再写入磁盘。然后再对shuffleRDD进行聚合,最后生成mapPartitionsRDD,也就是我们执行
reduceByKey等操作最终希望得到的结果:
map端的RDD,也就是mapPartitionsRDD------》拉取过来后生成shuffledRDD-------》聚合后生成mapPartitionsRDD。
由上可知:假设有100个mapTask、100个result task,那么就会产生100*100个磁盘文件,磁盘io过多影响性能。
spark shuffle的两个特点
a.在早期的spark版本中,bucket缓存非常重要,因为需要将一个shuffleMapTask所有的数据写入到缓存之后,才会刷新到磁盘。但如果map size数据过多,就容易造成内存溢出。所以在新版本中进行了优化,默认内存
缓存是100kb,当写入一部分数据达到刷新磁盘的阈值之后,就会将数据一点点地刷新到磁盘。优点:不容易发生内存溢出。缺点:发生过多的磁盘io(每超过100kb就写刷新写一次磁盘)。所以这里的内存缓存大小,是可以根据实际业务进行优化。
b.与mapReduce不同,MR必须将所有的数据写入到本地磁盘后才能启动reduce操作,来拉取数据(这是因为MapReduce要实现默认的根据key的排序,排序需要在写完数据之后才能进行)。而spark默认情况下不需要对数据进行排序,因此
shuffleMapTask每写入一点数据,resultTask就可以拉取一点数据,然后在本地执行用户定义的函数或者算子进行计算。优点:速度比MR快很多。缺点:因为是实时拉取,所以容易因为某些原因(网络抖动等)断开重新执行,不如MR稳定;且提供不了
直接对key对应的value的算子操作,只能通过groupByKey的方式,先shuffle,在用map算子对key的value进行操作,没有MR的计算模型方便。
优化后的shuffle
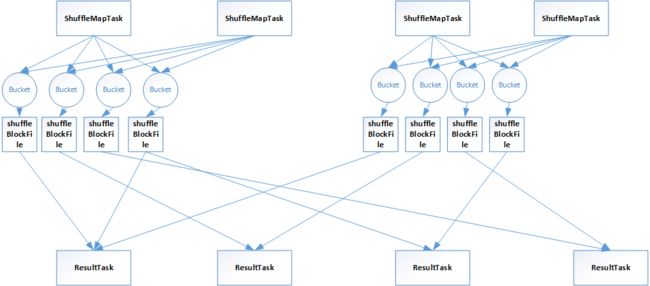
在spark新版本中,引入了consolidation机制,提出了shuffleGroup的概念:一个shuffleMapTask将数据写入resultTask数量的本地文件不会变,但是,当下一个shuffleMapTask运行时,可以直接将数据写到之前的shuffleMapTask的本地文件
中,相当于对多个shuffleMapTask的输出进行了合并,从而大大减少了本地磁盘文件的数量。
比如,在上述例子中,一个节点上有2个cpu,四个shffleMapTask,那么就可以有2个shuffleMapTask是可以进行并行执行的。并行执行的shuffleMapTask写入的文件是不同的,当它们执行完成后,新一批并行执行的shuffleMapTask执行启动,
通过consolidation机制进行优化。
上述中,写入到同一个文件的可以成为一组shuffleGroup。每个文件中都存储了多个shuffleMapTask的数据,每个shuffleMapTask的数据叫做一个segment。此外,还会通过一些索引来标记每个shuffleMapTask的输出在shuffleBlockFile中的索引,
来对不同的shuffleMapTask数据进行区分。
consolidation机制,是同spark conf中设置参数的方式来打开。
shuffle读写原理
从taskRunner开始, 从shuffleManager中,找到shuffleWriter:
a.首先调用rdd的iterator()方法,并且传入当前task需要处理的那个partition,在这里,就实现了针对RDD的某个partition执行用户自定义的算子或者函数。
b.执行完算子之后,对RDD的partition进行了处理,返回的数据都是通过shuffleWriter,经过hashPartitioner进行分区后,写入自己对于的bucket。
c.最后返回mapStatus,里面封装了shuffleTask计算后的数据存储在哪,其实就是blockManager相关的信息(blockManager是spark底层的内存、数据、磁盘数据管理的组件)。
shuffleWriter其实默认的是hashShuffleWriter(作用是:将shuffleMapTask计算出来的新的RDD的partition数据写入到本地磁盘中):
a.首先判断是否需要在map端进行聚合(比如是reduceByKey,它的dep.aggregator.isDegined就是true且dep.mapSideCombine也是true,就会在map端进行聚合),然后进行是否本地聚合。比如本地有(hello,1),(hello,1),就会聚合成(hello,2)
b.如果要本地聚合,那么先进行本地聚合,然后遍历数据,对每个数据调用partitioner(默认是hashPartitioner),生成bucketId,也就是决定了每一份数据,要写入到哪个bucket中。
c.获取到bucketId后,会调用shuffleBlockManager.forMapTask()方法,来生成bucketID对应的writer,然后用writer将数据写入bucket。
对于read,首先调用shuffledRDD类中的compute方法,在compute方法中,会通过shuffleManager的getRead()方法,获取一个hashShuffleReader,然后调用它的read()方法,拉取该resultTask / shuffleMapTask需要聚合的数据。
在hashShuffleReader的read()方法中:
a.resultTask在拉取数据时,是先通过blockStoreShuffleFetcher来从DAGScheduler的mapOutputTrackerMaster中获取到自己的数据信息;
b.然后进入底层,通过blockManager从对应的位置,拉取需要的数据。
13. blockManager
blockManager是spark底层的内存、数据、磁盘数据管理的组件。

①、在driver上,有blockManagerMaster,它的功能就是负责对各个节点上的blcokManager内部管理的数据的元数据,进行维护,比如block的增删改查等操作,都会在这里维护元数据的变更。
②、在每个节点上都有blockManager,它有四个关键组件:
diskStore:负责对磁盘上的数据进行读写;
memoryStore:负责对内存中的数据进行读写;
connectionManager:负责建立blockManager到远程其他节点上的blockManager的网络连接;
blockManagerWorker:负责对远程其他节点的blockManager的数据进行读写。
③、每个blockManager创建后,做的第一件事就是向blockManagerMaster进行注册,此时blockManagerMaster会为其创建对应的blockManagerInfo。
④、使用blockManager进行读写操作时,比如一个RDD运行过程中的一些中间数据,或者手动指定persist(),那么数据优先写入到内存中,如果内存不够,会根据自己的算法把一部分数据写到磁盘中。
此外,如果persist()指定了replicate(备份),那么会使用blockManagerWorker将数据replicate一份到其他节点的blockManager上去。
⑤、在进行shuffleRead时,如果要拉取数据,在本地没有是,就会去远程的节点blockManager拉取数据。这里需要通过connectionManager建立blockManager连接,然后blockManagerWorker从远程的blockManager读取数据。
⑥、只用使用blockManager执行了数据的增删查改操作,那么必须将block的blockStatus上报到blockManagerMaster上去,在blockManagerMaster中,会对指定的blockManager的blockManagerInfo内部的blockStatus进行增删查改操作,
从而达到元数据的维护功能。
---------------------------------------------------------------------------------------
参考:北风网spark从入门到精通,讲师:中华石杉。