Guava的布隆过滤器
点击上方"张狗蛋的技术之路",选择“置顶或者星标”
你的关注意义重大!
程序世界的算法都要在时间,资源占用甚至正确率等多种因素间进行平衡。同样的问题,所属的量级或场景不同,所用算法也会不同,其中也会涉及很多的trade-off。
If there’s one rule in programming, it’s this: there will always be trade-offs.
你是否真的存在
今天我们就来探讨如何判断一个值是否存在于已有的集合问题。这类问题在很多场景下都会遇到,比如说防止缓存击穿,爬虫重复URL检测,字典纠缠和CDN代理缓存等。

我们以网络爬虫为例。网络间的链接错综复杂,爬虫程序在网络间“爬行”很可能会形成“环”。为了避免形成“环”,程序需要知道已经访问过网站的URL。当程序又遇到一个网站,根据它的URL,怎么判断是否已经访问过呢?
第一个想法就是将已有URL放置在 HashSet中,然后利用 HashSet的特性进行判断。它只花费O(1)的时间。但是,该方法消耗的内存空间很大,就算只有1亿个URL,每个URL只算50个字符,就需要大约5GB内存。
如何减少内存占用呢?URL可能太长,我们使用MD5等单向哈希处理后再存到HashSet中吧,处理后的字段只有128Bit,这样可以节省大量的空间。我们的网络爬虫程序又可以继续执行了。
但是好景不长,网络世界浩瀚如海,URL的数量急速增加,以128bit的大小进行存储也要占据大量的内存。
这种情况下,我们还可以使用 BitSet,使用哈希函数将URL处理为1bit,存储在BitSet中。但是,哈希函数发生冲突的概率比较高,若要降低冲突概率到1%,就要将 BitSet的长度设置为URL个数的100倍。
但是冲突无法避免,这就带来了误判。理想中的算法总是又准确又快捷,但是现实中往往是“一地鸡毛”。我们真的需要100%的正确率吗?如果需要,时间和空间的开销无法避免;如果能够忍受低概率的错误,就有极大地降低时间和空间的开销的方法。

所以,一切都要trade-off。布隆过滤器(Bloom Filter)就是一种具有较低错误率,但是极大节约空间消耗的算法。
布隆过滤器
Bloom Filter是一种空间效率很高的随机数据结构,它利用位数组很简洁地表示一个集合,并能判断一个元素是否属于这个集合。Bloom Filter的这种高效是有一定代价的:在判断一个元素是否属于某个集合时,有可能会把不属于这个集合的元素误认为属于这个集合(false positive)。因此,Bloom Filter不适合那些“零错误”的应用场合。而在能容忍低错误率的应用场合下,Bloom Filter通过极少的错误换取了存储空间的极大节省。
A Bloom filter is a space-efficient probabilistic data structure, conceived by Burton Howard Bloom in 1970, that is used to test whether an element is a member of a set. False positive matches are possible, but false negatives are not, thus a Bloom filter has a 100% recall rate. In other words, a query returns either “possibly in set” or “definitely not in set”.
上述描述引自维基百科,特点总结为如下:
空间效率高的概率型数据结构,用来检查一个元素是否在一个集合中。
对于一个元素检测是否存在的调用,BloomFilter会告诉调用者两个结果之一:可能存在或者一定不存在。
布隆过滤器的使用场景很多,除了上文说的网络爬虫,还有处理缓存击穿和避免磁盘读取等。Goole Bigtable,Apache HBase和Postgresql等都使用了布隆过滤器。
我们就以下面这个例子具体描述使用BloomFilter的场景,以及在此场景下,BloomFilter的优势和劣势。
一组元素存在于磁盘中,数据量特别大,应用程序希望在元素不存在的时候尽量不读磁盘,此时,可以在内存中构建这些磁盘数据的BloomFilter,对于一次读数据的情况,分为以下几种情况:
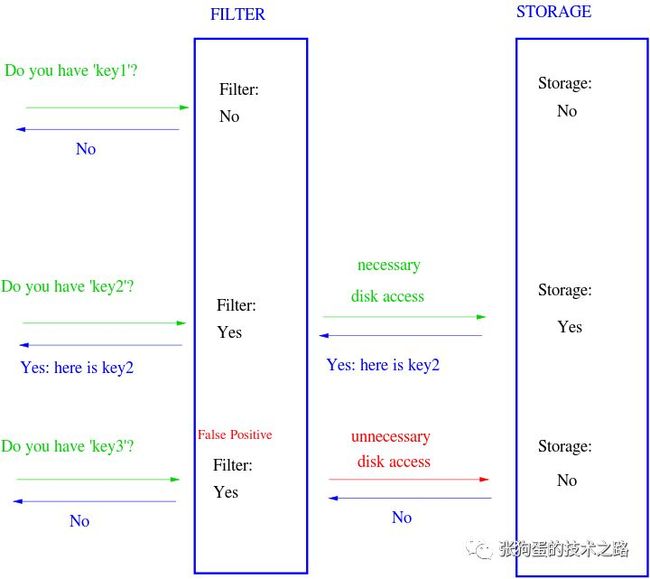
我们知道HashMap或者Set等数据结构也可以支持上述场景,这里我们就具体比较一下二者的优劣,并给出具体的数据。
精确度量十分重要,对于算法的性能,我们不能只是简单的感官上比较,要进行具体的计算和性能测试。找到不同算法之间的平衡点,根据平衡点和现实情况来决定使用哪种算法。就像Redis一样,它对象在不同情况下使用不同的数据结构,比如说列表对象的内置结构可以为 ziplist或者 linkedlist,在不同的场景下使用不同的数据结构。
请求的元素不在磁盘中,如果BloomFilter返回不存在,那么应用不需要走读盘逻辑,假设此概率为P1。如果BloomFilter返回可能存在,那么属于误判情况,假设此概率为P2。请求的元素在磁盘中,BloomFilter返回存在,假设此概率为P3。
如果使用 HashMap等数据结构,情况如下:
请求的数据不在磁盘中,应用不走读盘逻辑,此概率为P1+P2
请求的元素在磁盘中,应用走读盘逻辑,此概率为P3
假设应用不读盘逻辑的开销为C1,走读盘逻辑的开销为C2,那么,BloomFilter和hashmap的开销分别为
Cost(BloomFilter) = P1 * C1 + (P2 + P3) * C2
Cost(HashMap) = (P1 + P2) * C1 + P3 * C2;
Delta = Cost(BloomFilter) - Cost(HashMap) = P2 * (C2 - C1)
因此,BloomFilter相当于以增加P2 * (C2 - C1)的时间开销,来获得相对于 HashMap而言更少的空间开销。
既然P2是影响BloomFilter性能开销的主要因素,那么BloomFilter设计时如何降低概率P2(即误判率false positive probability)呢?,接下来的BloomFilter的原理将回答这个问题。
原理解析
初始状态下,布隆过滤器是一个包含m位的位数组,每一位都置为0。
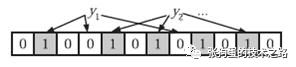
为了表达S={x1, x2,…,xn}这样一个n个元素的集合,Bloom Filter使用k个相互独立的哈希函数,它们分别将集合中的每个元素映射到{1,…,m}的范围中。对任意一个元素x,第i个哈希函数映射的位置hi(x)就会被置为1(1≤i≤k)。注意,如果一个位置多次被置为1,那么只有第一次会起作用,后面几次将没有任何效果。在下图中,k=3,且有两个哈希函数选中同一个位置(从左边数第五位)。

在判断y是否属于这个集合时,我们对y应用k次哈希函数,如果所有hi(y)的位置都是1(1≤i≤k),那么我们就认为y是集合中的元素,否则就认为y不是集合中的元素。下图中y1就不是集合中的元素。y2则可能属于这个集合,或者刚好是一个误判。
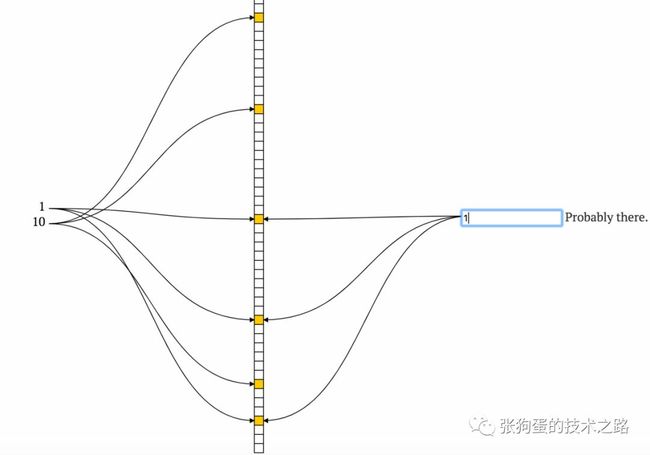
下面我们来看一下具体的例子,哈希函数的数量为3,首先加入1,10两个元素。通过下面两个图,我们可以清晰看到1,10两个元素被三个不同的韩系函数映射到不同的bit上,然后判断3是否在集合中,3映射的3个bit都没有值,所以判断绝对不在集合中。

关于误判率,实际的使用中,期望能给定一个误判率期望和将要插入的元素数量,能计算出分配多少的存储空间较合适。这涉及很多最优数值计算问题,比如说错误率估计,最优的哈希函数个数和位数组的大小等,相关公式计算感兴趣的同学可以自行百度,重温一下大学的计算微积分时光。
Guava的布隆过滤器
这就又要提起我们的Guava了,它是Google开源的Java包,提供了很多常用的功能,比如说我们之前总结的超详细的Guava RateLimiter限流原理解析 。
Guava中,布隆过滤器的实现主要涉及到2个类, BloomFilter和 BloomFilterStrategies,首先来看一下 BloomFilter的成员变量。需要注意的是不同Guava版本的 BloomFilter实现不同。
/** guava实现的以CAS方式设置每个bit位的bit数组 */
private final LockFreeBitArray bits;
/** hash函数的个数 */
private final int numHashFunctions;
/** guava中将对象转换为byte的通道 */
private final Funnel funnel;
/**
* 将byte转换为n个bit的策略,也是bloomfilter hash映射的具体实现
*/
private final Strategy strategy;这是它的4个成员变量:
LockFreeBitArray是定义在BloomFilterStrategies中的内部类,封装了布隆过滤器底层bit数组的操作。numHashFunctions表示哈希函数的个数。Funnel,它和PrimitiveSink配套使用,能将任意类型的对象转化成Java基本数据类型,默认用java.nio.ByteBuffer实现,最终均转化为byte数组。Strategy是定义在BloomFilter类内部的接口,代码如下,主要有2个方法,put和mightContain。
interface Strategy extends java.io.Serializable {
/** 设置元素 */
boolean put(T object, Funnel funnel, int numHashFunctions, BitArray bits);
/** 判断元素是否存在*/
boolean mightContain(
T object, Funnel funnel, int numHashFunctions, BitArray bits);
.....
} 创建布隆过滤器, BloomFilter并没有公有的构造函数,只有一个私有构造函数,而对外它提供了5个重载的 create方法,在缺省情况下误判率设定为3%,采用 BloomFilterStrategies.MURMUR128_MITZ_64的实现。
BloomFilterStrategies.MURMUR128_MITZ_64是 Strategy的两个实现之一,Guava以枚举的方式提供这两个实现,这也是《Effective Java》书中推荐的提供对象的方法之一。
enum BloomFilterStrategies implements BloomFilter.Strategy {
MURMUR128_MITZ_32() {//....}
MURMUR128_MITZ_64() {//....}
} 二者对应了32位哈希映射函数,和64位哈希映射函数,后者使用了murmur3 hash生成的所有128位,具有更大的空间,不过原理是相通的,我们选择相对简单的 MURMUR128_MITZ_32来分析。
先来看一下它的 put方法,它用两个hash函数来模拟多个hash函数的情况,这是布隆过滤器的一种优化。
public boolean put(
T object, Funnel funnel, int numHashFunctions, BitArray bits) {
long bitSize = bits.bitSize();
// 先利用murmur3 hash对输入的funnel计算得到128位的哈希值,funnel现将object转换为byte数组,
// 然后在使用哈希函数转换为long
long hash64 = Hashing.murmur3_128().hashObject(object, funnel).asLong();
// 根据hash值的高低位算出hash1和hash2
int hash1 = (int) hash64;
int hash2 = (int) (hash64 >>> 32);
boolean bitsChanged = false;
// 循环体内采用了2个函数模拟其他函数的思想,相当于每次累加hash2
for (int i = 1; i <= numHashFunctions; i++) {
int combinedHash = hash1 + (i * hash2);
// 如果是负数就变为正数
if (combinedHash < 0) {
combinedHash = ~combinedHash;
}
// 通过基于bitSize取模的方式获取bit数组中的索引,然后调用set函数设置。
bitsChanged |= bits.set(combinedHash % bitSize);
}
return bitsChanged;
} 在 put方法中,先是将索引位置上的二进制置为1,然后用 bitsChanged记录插入结果,如果返回true表明没有重复插入成功,而 mightContain方法则是将索引位置上的数值取出,并判断是否为0,只要其中出现一个0,那么立即判断为不存在。
public boolean mightContain(
T object, Funnel funnel, int numHashFunctions, BitArray bits) {
long bitSize = bits.bitSize();
long hash64 = Hashing.murmur3_128().hashObject(object, funnel).asLong();
int hash1 = (int) hash64;
int hash2 = (int) (hash64 >>> 32);
for (int i = 1; i <= numHashFunctions; i++) {
int combinedHash = hash1 + (i * hash2);
// Flip all the bits if it's negative (guaranteed positive number)
if (combinedHash < 0) {
combinedHash = ~combinedHash;
}
// 和put的区别就在这里,从set转换为get,来判断是否存在
if (!bits.get(combinedHash % bitSize)) {
return false;
}
}
return true;
} Guava为了提供效率,自己实现了 LockFreeBitArray来提供bit数组的无锁设置和读取。我们只来看一下它的 put函数。
boolean set(long bitIndex) {
if (get(bitIndex)) {
return false;
}
int longIndex = (int) (bitIndex >>> LONG_ADDRESSABLE_BITS);
long mask = 1L << bitIndex; // only cares about low 6 bits of bitIndex
long oldValue;
long newValue;
// 经典的CAS自旋重试机制
do {
oldValue = data.get(longIndex);
newValue = oldValue | mask;
if (oldValue == newValue) {
return false;
}
} while (!data.compareAndSet(longIndex, oldValue, newValue));
bitCount.increment();
return true;
}-推荐阅读
TCP/IP的底层队列
基于Redis和Lua的分布式限流
AbstractQueuedSynchronizer超详细原理解析
-关注我

参考
http://pages.cs.wisc.edu/~cao/papers/summary-cache/node8.html
http://oserror.com/backend/bloomfilter/
https://en.wikipedia.org/wiki/Bloom_filter
https://blog.medium.com/what-are-bloom-filters-1ec2a50c68ff
https://juejin.im/post/5c9442ae5188252d77392241
演示网站 https://www.jasondavies.com/bloomfilter/?spm=a2c4e.11153940.blogcont683602.11.21181fe6hVAGjH
感谢搓一下”在看“ 