Hadoop之Hive简介与安装、测试(一)
一、Hive是什么?
-
Hive是一种建立在Hadoop文件系统上的数据仓库架构,并对存储在HDFS中的数据进行分析与管理。可以通俗的理解为:
-
对于存储在HDFS中的数据进行分析与管理时,我们不想使用手工,从而建立一个工具来进行相应的操作,这个工具就是hive。
-
数据仓库:数据仓库的本质就是收集尽可能多的信息,用作公司的决策支持。数据仓库一般是不可更新的,数据仓库主要是为决策分析提供数据,所涉及的操作主要是数据的查询;一旦某个数据进入数据仓库以后,一般情况下将被长期保留,也就是数据仓库中一般有大量的查询操作,但修改和删除操作很少,通常只需要定期的加载、刷新。
hive与hadoop的关系
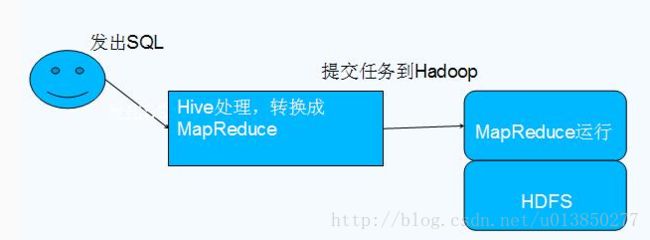
Hive产生的背景与历程
Hive典型应用场景
日志分析
统计网站一个时间段内的pv 、uv
多维度数据分析
大部分互联网公司使用Hive 进行日志分析,包括百度等 、淘宝等
其他场景
海量结构化数据离线分析
低成本进行数据分析(不直接编写MR)
Hive学习路线
二、hive的内嵌模式安装
1、设置环境变量
vi /etc/profile 添加环境变量值
export HIVE_HOME=/home/hadoopM/hive-2.1.0
export PATH = $HIVE_HOME/bin:$PATH
使之生效: source /etc/profile
2、修改配置文件:
cp hive-env.sh.template hive-env.sh
vi hive-env.sh 将hadoop的安装路径配置上去
# Set HADOOP_HOME to point to a specific hadoop install directory
HADOOP_HOME=/home/centosm/hadoopM
cp hive-default.xml.template hive-site.xml(修改hive运行时日志的输出路径,先创建本地文件:/home/centosm/hive/hivelog)
vi hive-site.xml
hive.querylog.location
/home/centosm/hive/hivelog
Location of Hive run time structured log file
hive.exec.local.scratchdir
/home/centosm/hive/hivelog
Local scratch space for Hive jobs
hive.downloaded.resources.dir
/home/centosm/hive/hivelog
Temporary local directory for added resources in the remote file system.
3、对derby 数据库进初始化
./bin/schematool -initSchema -dbType derby

上一步可能会出现如下问题:
Error: FUNCTION 'NUCLEUS_ASCII' already exists. (state=X0Y68,code=30000) org.apache.hadoop.hive.metastore.HiveMetaException: Schema initialization FAILED! Metastore state would be inconsistent !! * schemaTool failed *
解决方法:
mv metastore_db metastore_db.tmp
然后再执行上一步(./bin/schematool -initSchema -dbType derby)
三、内嵌模式安装安装成功后进行测试
-
1、创建如下测试表(在默认的default数据库中):
hive>
create table testDemo (year string,month int,num int)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ‘,’;
表创建成功后会在hadoop的该目录下生成对应的文件,在hadoop中的路径为:/user/hive/warehouse/testdemo -
2、在本地创建文件并按建表规则编辑test.txt文件,并将文件put到hdfs中
touch test.txt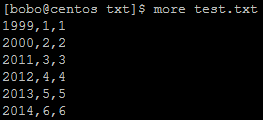
hadoop fs -put test.txt /user/hive/warehouse/testdemo
- put 进去之后可通过cat 命令查看该表对应的数据,如果要将这里的文件删除了,在hive中运行select * from testdemo并不会报错,只不过查出来的数据为空。当重新将数据put里去后,直接在hive中运行查询语句可查出对应的数据;

-
3、通过hive查询文件内容
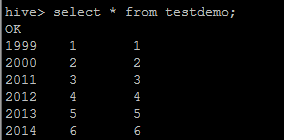
-
4、删除hdfs中的test.txt文件,重新上传编辑后的文件
hadoop fs -rmr /user/hive/warehouse/hive.db/testdemo/test.txt
编辑后的文件如下所示: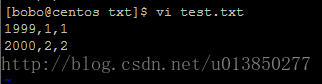
hadoop fs -put test.txt /user/hive/warehouse/testdemo
- 5、直接再次通过hive查询(查询之前没再对hive进行任何操作)

四、本地模式安装
-
这种安装方式和嵌入式的区别在于,不再使用内嵌的Derby作为元数据的存储介质,而是使用其他数据库比如MySQL来存储元数据。
-
这种方式是一个多用户的模式,运行多个用户client连接到一个数据库中。这种方式一般作为公司内部同时使用Hive。
-
这里有一个前提,每一个用户必须要有对MySQL的访问权利,即每一个客户端使用者需要知道MySQL的用户名和密码才行。
-
下面开始正式搭建,这里要求hadoop系统已经正常启动,且MySQL数据库已经正确安装。
1、创建hive用户,并赋予所有的权限:
CREATE USER 'hive'@'hostName' IDENTIFIED BY '123456';
GRANT ALL PRIVILEGES ON *.* TO hive IDENTIFIED BY '123456' WITH GRANT OPTION;
通过新增加的用户登录MySQL,创建一个数据库,这里命名为hive,数据库名是可以随意定义的。
mysql -u hive -p
create database hive;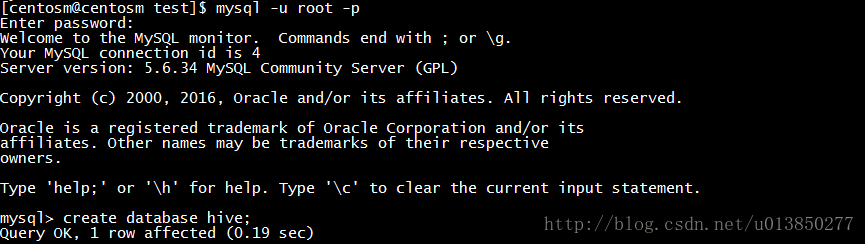
2、将MySQL的JDBC驱动包拷贝到hive的安装目录的lib中,驱动包自行查找下载。
mysql-connector-java-5.1.32-bin.jar
3、修改hive-site.xml文件
A、修改javax.jdo.option.ConnectionURL属性。
javax.jdo.option.ConnectionURL
jdbc:mysql://localhost/hive?createDatabaseIfNotExist=true
JDBC connect string for a JDBC metastore
B、修改javax.jdo.option.ConnectionDriverName属性。
javax.jdo.option.ConnectionDriverName
com.mysql.jdbc.Driver
Driver class name for a JDBC metastore
C、修改javax.jdo.option.ConnectionUserName属性。即数据库用户名。
javax.jdo.option.ConnectionUserName
hive
Username to use against metastore database
D、修改javax.jdo.option.ConnectionPassword属性。即数据库密码。
javax.jdo.option.ConnectionPassword
123456
password to use against metastore database
E、添加如下属性hive.metastore.local:
hive.metastore.local
true
controls whether to connect to remove metastore server or open a new metastore server in Hive Client JVM
F、修改hive.server2.logging.operation.log.location属性,因为默认的配置里没有指定具体的路径。
hive.server2.logging.operation.log.location
/tmp/hive/operation_logs
Top level directory where operation logs are stored if logging functionality is enabled
G、修改hive.exec.local.scratchdir属性。
hive.exec.local.scratchdir
/tmp/hive
Local scratch space for Hive jobs
H、修改hive.downloaded.resources.dir属性。
hive.downloaded.resources.dir
/tmp/hive/resources
Temporary local directory for added resources in the remote file system.
I、修改属性hive.querylog.location属性。
hive.querylog.location
/tmp/hive/querylog
Location of Hive run time structured log file
5、配置hive的log4j配置文件。(可不修改)
cp hive-log4j.properties.template hive-log4j.properties
五、本地模式安装安装成功后进行测试
该测试的数据准备与内嵌模式的一样。
-
1)create table test1 (year string,month int,num int) ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘,’;

-
2)准备数据hive1.txt 与hive2.txt并上传到warehouse/test1目录中


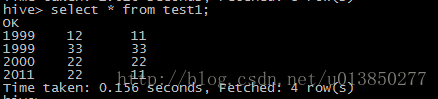
这里可以很明显看到运行通过hive select 查询的是一个目录下的所有文件的内容。
- 3)查询sql中存储的元数据,这里hive存储的数据设定在test数据库中
当hive安装成功并进行首次执行后,test对应的数据库则会有如下表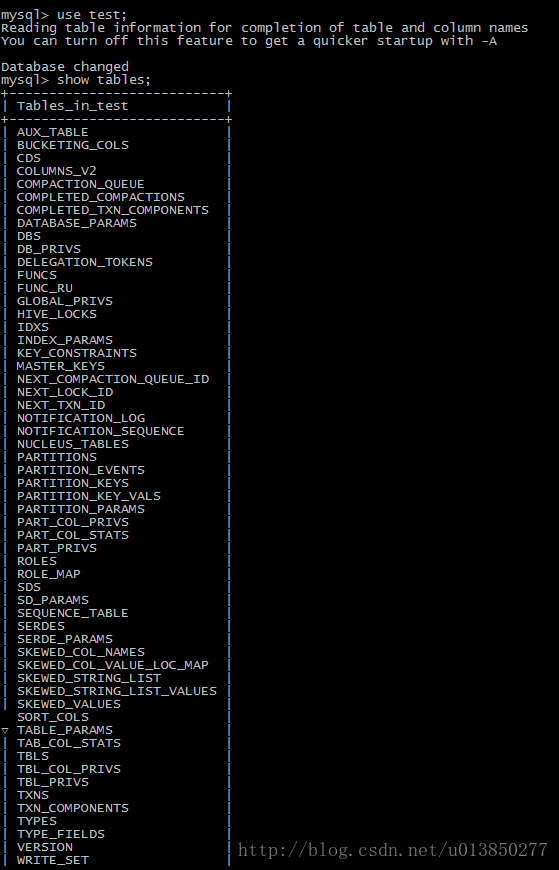
查询上表可得出如下结果:
对于上述各表可通过如下链接进行查询:
[一起学Hive]之十四-Hive的元数据表结构详解](http://www.cnblogs.com/1130136248wlxk/articles/5517909.html)