2019独角兽企业重金招聘Python工程师标准>>> 
前言
文章是自己写了后先发到了公众号里,再转到了内部的KM。算是一个系列的学习笔记,一篇篇来。
本篇是大数据算法系列 第一篇《BitMap的原理和实现》,BitMap 的思想的和原理是很多算法的基础,因此我们以BitMap开篇。
既然是说大数据算法,我们先尝试给大数据算法一个定义,或者说是限定一下这个系列的范围。
大数据算法:在给定的资源约束下,以大数据为输入,在给定时间约束内可以计算出给定问题加过的算法。
大数据算法会有传统的算法有不一样的地方:
- 资源有约束
- 时间有约束
- 大数据作为输入
- 不一定是精确算法
前三点可以看作是对算法的要求,第四点可以看作是在大数据场景下算法可以做出的让步。比如说在10亿的数据中求 count distinct 操作,完全精确的算法会十分占用空间资源,而且也很难在快速计算出结果。如果这时候允许一定的误差,就可以在极短的时间使用少量的内容算出结果,比如基数估计算法中的Hyperloglog。
本系列会包括 BitMap、Roaring BitMap、Bloom Filter、Counting Bloom Filter、Linear Counting、Loglog Counting、HyperLogLog Counting 等算法。我会把这些算法一个个过一遍,看论文、写代码、整理学习笔记。
对于技术人员来讲,文章应该做到 图文码并茂,因此我会尽量做到每篇文章都有原理说明和示例代码的实现,原理说明会通过配图的方式来理解,代码的话会有一个比较简单的demo。
一、原理
基本原理
BitMap 的基本原理就是用一个 bit 来标记某个元素对应的 Value,而 Key 即是该元素。由于采用一 个bit 来存储一个数据,因此可以大大的节省空间。
我们通过一个具体的例子来说明 BitMap 的原理,假设我们要对 0-31 内的 3 个元素 (10, 17,28) 排序,那么我们就可以采用 BitMap 方法(假设这些元素没有重复)。
如下图,要表示 32 个数,我们就只需要 32 个 bit(4Bytes),首先我们开辟 4Byte 的空间,将这些空间的所有 bit 位都置为 0。

然后,我们要添加(10, 17,28) 这三个数到 BitMap 中,需要的操作就是在相应的位置上将0置为1即可。如下图,比如现在要插入 10 这个元素,只需要将蓝色的那一位变为1即可。
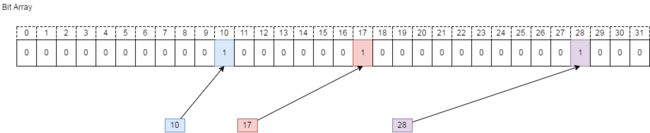
将这些数据插入后,假设我们想对数据进行排序或者检索数据是否存在,就可以依次遍历这个数据结构,碰到位为 1 的情况,就当这个数据存在。
字符串映射
BitMap 也可以用来表述字符串类型的数据,但是需要有一层Hash映射,如下图,通过一层映射关系,可以表述字符串是否存在。

当然这种方式会有数据碰撞的问题,但可以通过 Bloom Filter 做一些优化。
二、实现
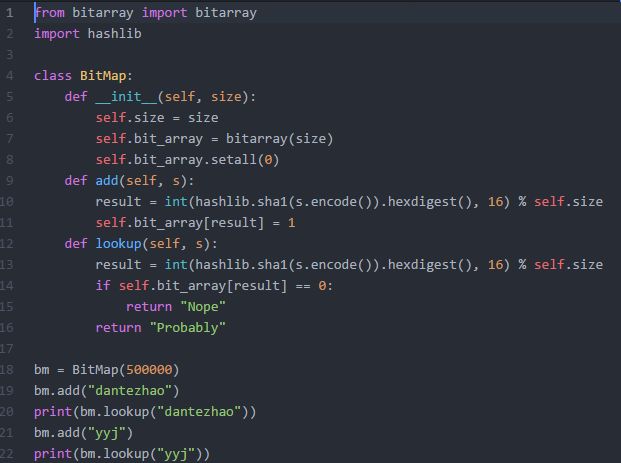
懂原理之后,还是要写代码来加深一下理解,这里用 Python 实现一个最基本的版本。
代码用到了 bitarry 库来直接操作 bit 数组;用 hashlib 来将字符串映射到数字,以便插入 BitMap。
代码很简单,看懂上面的原理的话,很容易就看懂了代码。
三、使用
BitMap 的使用场景很广泛,比如说 Oracle、Redis 中都有用到 BitMap。当然更多的系统会有比 BitMap 稍微复杂一些的算法,比如 Bloom Filter、Counting Bloom Filter,这些会在后面逐一展开。
下面举一个在算法中用到 BitMap 来解决问题的例子。
已知某个文件内包含一些电话号码,每个号码为8位数字,统计不同号码的个数。
在这里就不再做和其它算法的对比,直接说一下 BitMap 的思路。
8 位的整数,相当于是范围在(0,99999999),也就是说 99999999 个 bit,也就是 12M 左右的内存,比起用类似 HashMap 的方式的话能节省很大的空间。 可以理解为从0 到 99999999 的数字,每个数字对应一个 Bit位,所以只需要 12M 左右的内存表示了所有的 8 位数的电话。
查询的时候就很简单了,直接统计有多少位是 1 就可以了。
四、总结
BitMap 的思想在面试的时候还是可以用来解决不少问题的,然后在很多系统中也都会用到,算是一种不错的解决问题的思路。
但是 BitMap 也有一些局限,因此会有其它一些基于 BitMap 的算法出现来解决这些问题。
- 数据碰撞。比如将字符串映射到 BitMap 的时候会有碰撞的问题,那就可以考虑用 Bloom Filter 来解决,Bloom Filter 使用多个 Hash 函数来减少冲突的概率。
- 数据稀疏。又比如要存入(10,8887983,93452134)这三个数据,我们需要建立一个 99999999 长度的 BitMap ,但是实际上只存了3个数据,这时候就有很大的空间浪费,碰到这种问题的话,可以通过引入 Roaring BitMap 来解决。
算法比较成熟,因此参考的东西也挺多,就不再列参考了。
Refer:
[0] 拜托,面试官别问我「布隆过滤器」了(修订补充版)
https://bit.ly/2YHlKV4
[1] BitMap 的基本原理和实现
https://cloud.tencent.com/community/article/813907
[2] No.17【大数据算法】Bloom Filter 的数学背景
http://bit.ly/2gx6y84
[3] No.15【大数据算法】Bloom Filter 的基本原理和实现
http://bit.ly/2hYN5gT
[4] No.19 【大数据算法】Counting Bloom Filter 的原理和实现
http://bit.ly/2y02fNu
[5] 大数据计数原理1+0=1这你都不会算(八)No.60
http://bit.ly/2l7t64i
[6] 大数据分析常用去重算法分析『Bitmap 篇』
http://bit.ly/2ZLY2HR