作者:zhbzz2007 出处:http://www.cnblogs.com/zhbzz2007 欢迎转载,也请保留这段声明。谢谢!
1 简介
jieba分词主要是基于统计词典,构造一个前缀词典;然后利用前缀词典对输入句子进行切分,得到所有的切分可能,根据切分位置,构造一个有向无环图;通过动态规划算法,计算得到最大概率路径,也就得到了最终的切分形式。
2 实例讲解
以“去北京大学玩”为例,作为待分词的输入文本。
离线统计的词典形式如下,每一行有三列,第一列是词,第二列是词频,第三列是词性。
...
北京大学 2053 nt
大学 20025 n
去 123402 v
玩 4207 v
北京 34488 ns
北 17860 ns
京 6583 ns
大 144099 a
学 17482 n
...2.1 前缀词典构建
首先是基于统计词典构造前缀词典,如统计词典中的词“北京大学”的前缀分别是“北”、“北京”、“北京大”;词“大学”的前缀是“大”。统计词典中所有的词形成的前缀词典如下所示,你也许会注意到“北京大”作为“北京大学”的前缀,但是它的词频却为0,这是为了便于后面有向无环图的构建。
...
北京大学 2053
北京大 0
大学 20025
去 123402
玩 4207
北京 34488
北 17860
京 6583
大 144099
学 17482
...2.2 有向无环图构建
然后基于前缀词典,对输入文本进行切分,对于“去”,没有前缀,那么就只有一种划分方式;对于“北”,则有“北”、“北京”、“北京大学”三种划分方式;对于“京”,也只有一种划分方式;对于“大”,则有“大”、“大学”两种划分方式,依次类推,可以得到每个字开始的前缀词的划分方式。
在jieba分词中,对每个字都是通过在文本中的位置来标记的,因此可以构建一个以位置为key,相应划分的末尾位置构成的列表为value的映射,如下所示,
0: [0]
1: [1,2,4]
2: [2]
3: [3,4]
4: [4]
5: [5]对于0: [0],表示位置0对应的词,就是0 ~ 0,就是“去”;对于1: [1,2,4],表示位置1开始,在1,2,4位置都是词,就是1 ~ 1,1 ~ 2,1 ~ 4,即“北”,“北京”,“北京大学”这三个词。
对于每一种划分,都将相应的首尾位置相连,例如,对于位置1,可以将它与位置1、位置2、位置4相连接,最终构成一个有向无环图,如下所示,
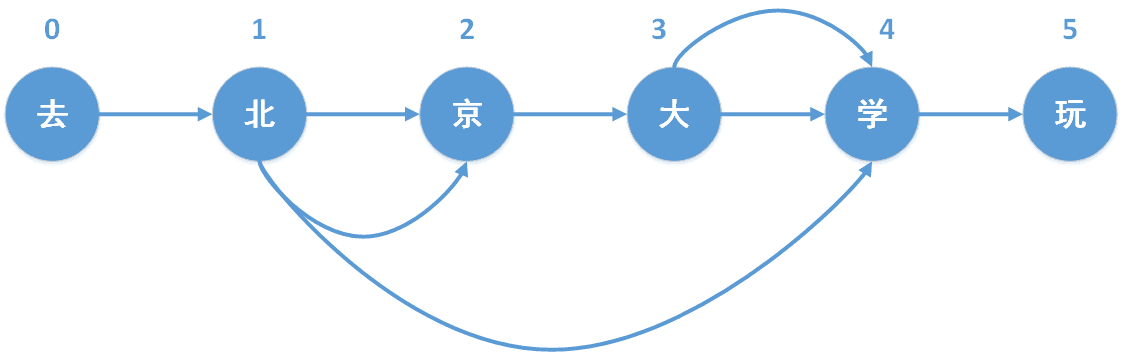
2.3 最大概率路径计算
在得到所有可能的切分方式构成的有向无环图后,我们发现从起点到终点存在多条路径,多条路径也就意味着存在多种分词结果,例如,
# 路径1
0 -> 1 -> 2 -> 3 -> 4 -> 5
# 分词结果1
去 / 北 / 京 / 大 / 学 / 玩
# 路径2
0 -> 1 , 2 -> 3 -> 4 -> 5
# 分词结果2
去 / 北京 / 大 / 学 / 玩
# 路径3
0 -> 1 , 2 -> 3 , 4 -> 5
# 分词结果3
去 / 北京 / 大学 / 玩
# 路径4
0 -> 1 , 2 , 3 , 4 -> 5
# 分词结果4
去 / 北京大学 / 玩
...因此,我们需要计算最大概率路径,也即按照这种方式切分后的分词结果的概率最大。在计算最大概率路径时,jieba分词采用从后往前这种方式进行计算。为什么采用从后往前这种方式计算呢?因为,我们这个有向无环图的方向是从前向后指向,对于一个节点,我们只知道这个节点会指向后面哪些节点,但是我们很难直接知道有哪些前面的节点会指向这个节点。
在采用动态规划计算最大概率路径时,每到达一个节点,它前面的节点到终点的最大路径概率已经计算出来。
3 源码分析
3.1 算法流程
jieba.__init__.py中实现了jieba分词接口函数cut(self, sentence, cut_all=False, HMM=True)。
jieba分词接口主入口函数,会首先将输入文本解码为Unicode编码,然后根据入参,选择不同的切分方式,本文主要以精确模式进行讲解,因此cut_all和HMM这两个入参均为默认值;
切分方式选择,
re_han = re_han_default
re_skip = re_skip_default块切分方式选择,
cut_block = self.__cut_DAG函数__cut_DAG(self, sentence)首先构建前缀词典,其次构建有向无环图,然后计算最大概率路径,最后基于最大概率路径进行分词,如果遇到未登录词,则调用HMM模型进行切分。本文主要涉及前三个部分,基于HMM的分词方法则在下一文章中详细说明。
3.2 前缀词典构建
get_DAG(self, sentence)函数会首先检查系统是否初始化,如果没有初始化,则进行初始化。在初始化的过程中,会构建前缀词典。
构建前缀词典的入口函数是gen_pfdict(self, f),解析离线统计词典文本文件,每一行分别对应着词、词频、词性,将词和词频提取出来,以词为key,以词频为value,加入到前缀词典中。对于每个词,再分别获取它的前缀词,如果前缀词已经存在于前缀词典中,则不处理;如果该前缀词不在前缀词典中,则将其词频置为0,便于后续构建有向无环图。
jieba分词中gen_pfdict函数实现如下,
# f是离线统计的词典文件句柄
def gen_pfdict(self, f):
# 初始化前缀词典
lfreq = {}
ltotal = 0
f_name = resolve_filename(f)
for lineno, line in enumerate(f, 1):
try:
# 解析离线词典文本文件,离线词典文件格式如第2章中所示
line = line.strip().decode('utf-8')
# 词和对应的词频
word, freq = line.split(' ')[:2]
freq = int(freq)
lfreq[word] = freq
ltotal += freq
# 获取该词所有的前缀词
for ch in xrange(len(word)):
wfrag = word[:ch + 1]
# 如果某前缀词不在前缀词典中,则将对应词频设置为0,
# 如第2章中的例子“北京大”
if wfrag not in lfreq:
lfreq[wfrag] = 0
except ValueError:
raise ValueError(
'invalid dictionary entry in %s at Line %s: %s' % (f_name, lineno, line))
f.close()
return lfreq, ltotal为什么jieba没有使用trie树作为前缀词典存储的数据结构?
参考jieba中的issue--不用Trie,减少内存加快速度;优化代码细节 #187,本处直接引用该issue的comment,如下,
对于get_DAG()函数来说,用Trie数据结构,特别是在Python环境,内存使用量过大。经实验,可构造一个前缀集合解决问题。
该集合储存词语及其前缀,如set(['数', '数据', '数据结', '数据结构'])。在句子中按字正向查找词语,在前缀列表中就继续查找,直到不在前缀列表中或超出句子范围。大约比原词库增加40%词条。
该版本通过各项测试,与原版本分词结果相同。
测试:一本5.7M的小说,用默认字典,64位Ubuntu,Python 2.7.6。
Trie:第一次加载2.8秒,缓存加载1.1秒;内存277.4MB,平均速率724kB/s;
前缀字典:第一次加载2.1秒,缓存加载0.4秒;内存99.0MB,平均速率781kB/s;
此方法解决纯Python中Trie空间效率低下的问题。
同时改善了一些代码的细节,遵循PEP8的格式,优化了几个逻辑判断。
3.2 有向无环图构建
有向无环图,directed acyclic graphs,简称DAG,是一种图的数据结构,顾名思义,就是没有环的有向图。
DAG在分词中的应用很广,无论是最大概率路径,还是其它做法,DAG都广泛存在于分词中。因为DAG本身也是有向图,所以用邻接矩阵来表示是可行的,但是jieba采用了Python的dict结构,可以更方便的表示DAG。最终的DAG是以{k : [k , j , ..] , m : [m , p , q] , ...}的字典结构存储,其中k和m为词在文本sentence中的位置,k对应的列表存放的是文本中以k开始且词sentence[k: j + 1]在前缀词典中的 以k开始j结尾的词的列表,即列表存放的是sentence中以k开始的可能的词语的结束位置,这样通过查找前缀词典就可以得到词。
get_DAG(self, sentence)函数进行对系统初始化完毕后,会构建有向无环图。
从前往后依次遍历文本的每个位置,对于位置k,首先形成一个片段,这个片段只包含位置k的字,然后就判断该片段是否在前缀词典中,
如果这个片段在前缀词典中,
1.1 如果词频大于0,就将这个位置i追加到以k为key的一个列表中;
1.2 如果词频等于0,如同第2章中提到的“北京大”,则表明前缀词典存在这个前缀,但是统计词典并没有这个词,继续循环;
如果这个片段不在前缀词典中,则表明这个片段已经超出统计词典中该词的范围,则终止循环;
然后该位置加1,然后就形成一个新的片段,该片段在文本的索引为[k:i+1],继续判断这个片段是否在前缀词典中。
jieba分词中get_DAG函数实现如下,
# 有向无环图构建主函数
def get_DAG(self, sentence):
# 检查系统是否已经初始化
self.check_initialized()
# DAG存储向无环图的数据,数据结构是dict
DAG = {}
N = len(sentence)
# 依次遍历文本中的每个位置
for k in xrange(N):
tmplist = []
i = k
# 位置k形成的片段
frag = sentence[k]
# 判断片段是否在前缀词典中
# 如果片段不在前缀词典中,则跳出本循环
# 也即该片段已经超出统计词典中该词的长度
while i < N and frag in self.FREQ:
# 如果该片段的词频大于0
# 将该片段加入到有向无环图中
# 否则,继续循环
if self.FREQ[frag]:
tmplist.append(i)
# 片段末尾位置加1
i += 1
# 新的片段较旧的片段右边新增一个字
frag = sentence[k:i + 1]
if not tmplist:
tmplist.append(k)
DAG[k] = tmplist
return DAG以“去北京大学玩”为例,最终形成的有向无环图为,
{0: [0], 1: [1,2,4], 2: [2], 3: [3,4], 4: [4], 5: [5]}3.3 最大概率路径计算
3.2章节中构建出的有向无环图DAG的每个节点,都是带权的,对于在前缀词典里面的词语,其权重就是它的词频;我们想要求得route = (w1,w2,w3,...,wn),使得 \(\sum weight(w_{i})\) 最大。
如果需要使用动态规划求解,需要满足两个条件,
- 重复子问题
- 最优子结构
我们来分析一下最大概率路径问题,是否满足动态规划的两个条件。
重复子问题
对于节点wi和其可能存在的多个后继节点Wj和Wk,
任意通过Wi到达Wj的路径的权重 = 该路径通过Wi的路径权重 + Wj的权重,也即{Ri -> j} = {Ri + weight(j)}
任意通过Wi到达Wk的路径的权重 = 该路径通过Wi的路径权重 + Wk的权重,也即{Ri -> k} = {Ri + weight(k)}即对于拥有公共前驱节点Wi的节点Wj和Wk,需要重复计算达到Wi的路径的概率。
最优子结构
对于整个句子的最优路径Rmax和一个末端节点Wx,对于其可能存在的多个前驱Wi,Wj,Wk...,设到达Wi,Wj,Wk的最大路径分别是Rmaxi,Rmaxj,Rmaxk,有,
Rmax = max(Rmaxi,Rmaxj,Rmaxk,...) + weight(Wx)于是,问题转化为,求解Rmaxi,Rmaxj,Rmaxk,...等,
组成了最优子结构,子结构里面的最优解是全局的最优解的一部分。
状态转移方程为,
Rmax = max{(Rmaxi,Rmaxj,Rmaxk,...) + weight(Wx)}jieba分词中计算最大概率路径的主函数是calc(self, sentence, DAG, route),函数根据已经构建好的有向无环图计算最大概率路径。
函数是一个自底向上的动态规划问题,它从sentence的最后一个字(N-1)开始倒序遍历sentence的每个字(idx)的方式,计算子句sentence[idx ~ N-1]的概率对数得分。然后将概率对数得分最高的情况以(概率对数,词语最后一个位置)这样的元组保存在route中。
函数中,logtotal为构建前缀词频时所有的词频之和的对数值,这里的计算都是使用概率对数值,可以有效防止下溢问题。
jieba分词中calc函数实现如下,
def calc(self, sentence, DAG, route):
N = len(sentence)
# 初始化末尾为0
route[N] = (0, 0)
logtotal = log(self.total)
# 从后到前计算
for idx in xrange(N - 1, -1, -1):
route[idx] = max((log(self.FREQ.get(sentence[idx:x + 1]) or 1) -
logtotal + route[x + 1][0], x) for x in DAG[idx])4 Reference
jieba分词学习笔记(三)