应对挑战,做好预见性维护的数据准备
本文关键点
机器学习(ML)在工业物联网(IIoT )领域的数据管理和预测分析中发挥着重要的作用。
预见性维护(PdM)应用程序旨在将机器学习应用于工业物联网数据集,以减少职业危害、机器停机时间,以及其他成本。
了解机器学习行业从业者所面临的数据准备的挑战,以及与预测维护相关的数据摄取和特征工程的解决方案。
使用数据流管理工具(如streamset或Apache Nifi)可以使数据摄取流程的开发和管理更加容易。
通常,长短时记忆(Long Short-Term Memory, LSTM)算法用于预测时间序列数据中的罕见事件。由于一般在预测维护应用中故障是非常罕见的,所以它的建模很适合使用LSTM算法。
机器学习使技术人员能够用数据做出很奇妙的事情。它与物联网驱动的网络化制造系统在齐头并进地发展,物联网也被称为工业物联网(Industrial IoT),它使可用于统计建模的数据呈指数级增长。
预见性维护(PdM)应用程序旨在将机器学习应用于工业物联网数据集,检测机器何时出现与过去故障相关的特征,从而减少职业危害、机器停机时间和其他成本。在这个过程中,预测性维护向工厂操作员提供信息,帮助他们采取预防或纠正措施,例如:
以较低的速度或较低的压力运行机器,将总体故障的发作推迟,
现场是否有备用设备,以及
安排在合适的时间进行维护。
实施预见性维护涉及到从数据准备开始到应用机器学习结束的流程。从业人员都知道,为了使机器学习有效,数据准备需要做大量的工作,然而,在机器学习的相关著作中这些挑战却不断地被忽视,而其作者更喜欢去讲解概念上的数据集。
在本文中,我希望通过讨论与预测维护相关的数据摄取和特征工程的解决方案,帮助机器学习行业从业者应对所面临的一些最困难的数据准备的挑战。
数据摄取
预见性维护的第一步是需要数据采集。工业仪表通常与振动、红外热、电流、油脂中的金属颗粒等物理量的测量密不可分。这些数据通常来源于工业控制网络中所连接的可编程逻辑控制器上的传感器。通过开发人员友好的协议(如REST和MQTT),桥接控制和公司网络的数据网关很方便就能访问到这些数据。还应考虑带外数据源(如操作员日志或天气数据),这也很重要,因为它们也可以包含与故障事件相关的信号。如下图1说明了这些类型的数据资产之间的相互关系。
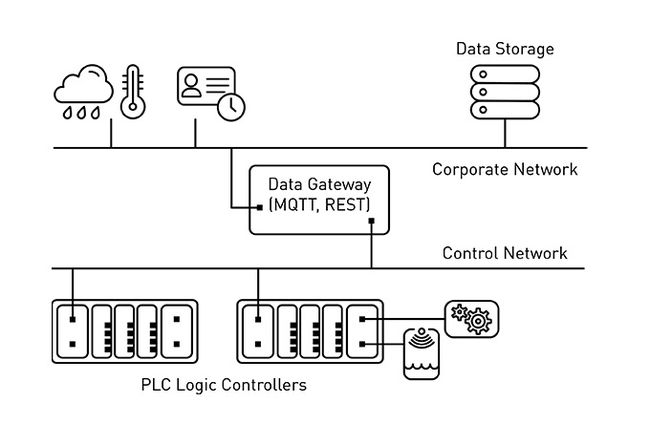
数据流水线设计
数据摄取是由连续收集和存储数据的过程完成的。这些流程可以按定制应用程序来实现,但通常使用数据流管理工具(如StreamSets 或者Apache Nifi)更容易开发和管理。这些工具为创建和管理数据流水线带来了许多优势,例如:
简化流水线的开发和部署。像streamset和Nifi提供的集成开发环境(ide),可以帮助把创建流水线所需的代码降到最少。它们还集成了实用工具用于监控和调试数据流。此外,这些工具还支持具有流版本控制和持续交付等功能DevOps流程。
防止不要因为扩大规模、模式漂移和拓扑迁移而导致故障。数据流管理工具可以作为分布式系统中变更的重要角色。它们为处理增加的负载提供了合理的伸缩方式。例如,streamset利用Kubernetes实现了弹性可伸缩性,预计Nifi在不久的将来也会这样做。在演进基线模式时,数据源也可以引入了颠覆性的变更。streamset和Nifi使你能够在即时重定向或重新格式化消息的数据验证阶段处理模式漂移。基础设施的结构拓扑也可以在应用程序生命周期中发生变化。streamset和Nifi使您能够定义拓扑无关的数据流,这些数据流可以跨边缘、预置、云和混合云基础设施运行,而不会牺牲数据的弹性或隐私性。
为了让您了解数据流管理工具的功能,我准备了一个简单的streamset项目,您可以在装有Docker的笔记本电脑上运行它。该项目演示了一个流水线,该流水线将工业采暖、通风和空调(HVAC)系统记录的时间序列数据流转到OpenTSDB中,以便在Grafana中进行可视化。
- 创建一个用来桥接容器的docker网络:
docker network create mynetwork- 启动StreamSets、OpenTSDB 和 Grafana:
docker run -it -p 18630:18630 -d --name sdc --network mynetwork \\streamsets/datacollectordocker run -dp 4242:4242 --name hbase --network mynetwork \\petergrace/opentsdb-dockerdocker run -d -p 3000:3000 --name grafana --network mynetwork \\grafana/grafana访问http://localhost:3000 打开Grafana,并以admin / admin登录
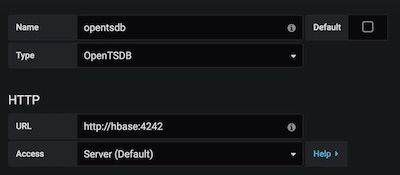
将http://hbase:4242 作为一个OpenTSDB 数据源添加到Grafana。如果你不知道如何添加数据源,可以参考 Grafana 文档。你的数据源定义应该看起来如下图2中的截屏所示。
下载这个Grafana 仪表盘文件。
导入这个文件到Grafana里。如果你不知道如何导入仪表盘,可以看一下Grafana 的文档。你的导入对话框看起来应该如下截图所示。

- 下载、解压和复制这个HVAC 数据到StreamSets 容器:
unzip mqtt.json.gzdocker cp mqtt.json sdc:/tmp/mqtt.json访问http://localhost:18630 打开StreamSets,并以admin / admin登录
下载并导入 f流流水线ollowing pipeline 到StreamSets中。如果你不了解如何导入流水线,请参考 StreamSets 文档。
在 “Parse MQTT JSON” 阶段你将看到一个关于缺少类库的警告,单击该阶段并按照提示安装这个Jython 类库即可。

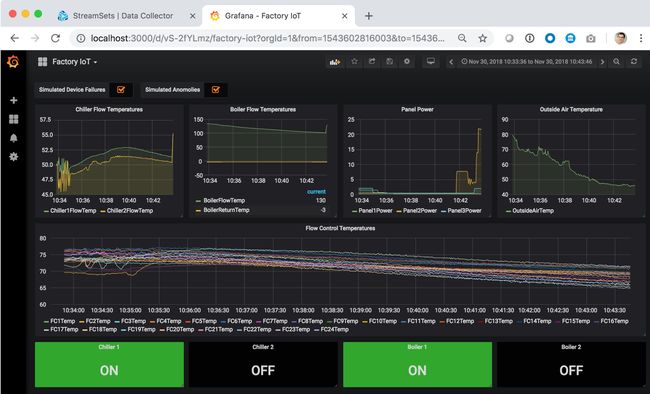
- 运行StreamSets 流水线。几分钟之后,StreamSets 仪表盘看起来应如下图5截屏所示。

- 让这个流水线运行几分钟之后,Grafana dashboard 仪表盘看起来应如下图6截屏所示。
希望通过设置这个流水线和对streamset的研究,您能够了解数据流管理工具可以做什么了。
流水线 – 文件, 表, 还是流?
数据流水线有起点和终点 ,也就是源和接收器。正如前面所提到的,MQTT和REST API通常都用于读取数据,但是流水线在哪里结束差别很大,这取决于用例。例如,如果您的目标只是为了遵从法规而归档数据,那么您可能让流水线终结为一个文件就可以了,因为文件很容易创建和压缩,能最小化存储成本。如果您的目标是在像Grafana之类的监控工具中开发仪表板和警报,从而获取装配线上的关键指标,那么您就可以使流水线通往OpenTSDB这样的时间序列数据库。对于预见性维护,确定如何持久化数据时的其他需求也有重要作用。我们来考虑一下文件、表和流的相对优势,以确定为预见性维护设计数据流水线的最佳方式:
文件:文件可以用来有效地读写数据。如果它们不是太大,也可以很容易压缩和移动。但是,如果文件变得很大(比如千兆字节)或者变得非常多(比如上千个)时,就会导致难以管理,从而出现问题。除了难以移动之外,在大型文件中搜索和更新数据可能也会非常慢,因为它们的内容没有索引。此外,尽管文件可以让你以最大的灵活性用任意格式保存数据,但它们缺少用于模式验证的内置函数。因此,如果您在保存损坏的数据前忽略了验证,没有丢弃它们,那么就不得不在稍后数据清理时面对艰难的任务。
流:比如Apache Kafka,流被设计成通过发布/订阅接口将数据分发给任意数量的使用者。这在运行多个数据处理器(如机器学习的推断任务)时非常有用,因此它们不一定非要全都连接到原始数据源,这种做法很没有必要,而且无法伸缩。像文件一样,流也可以非常快速地摄取数据。与文件不同的是,流提供了根据模式验证传入数据的能力(例如使用Apache Spark中的case类—我将在后面进行演示)。将流水线终结为流的缺点是它们是不可变的。一旦数据到了流中,就不能修改了。若想更新流中的数据,惟一的方法是将其复制到新流中。如果训练数据不可变,那么对于预见性维护就不可取了,因为它阻止了诸如剩余使用寿命(RUL)等特征在发生重要事件(如机器故障)后进行回溯性更新。
数据库表:可以进行模式验证吗?可以。可以进行更新吗?可以。可以加索引吗?可以!如果数据库提供二级索引,那么表索引尤其有用,因为它们可以加速查询多个变量的请求。如上提到过流的发布/订阅接口的优点;数据库也能提供这些优点吗?同样,答案仍是肯定的,当然前提是数据库提供了更改数据捕获(change-data-capture, CDC)流。数据库的一个缺点是不能像文件或流那样快速地写入数据。然而,有许多方法可以加速写操作。一种方法是将流水线终结在流上。在这种情况下,流可以用于两个目的。第一,它们可以缓冲高速脉冲;第二,它们可以将高速流水线分发给多个使用者,这些使用者可以横向外扩展共同将必要的吞吐量写入到一个数据库中。当流和数据库运行在相同的底层数据平台上时,这尤其有效,情况与MapR类似。同样值得注意的是,MapR-DB提供了二级索引和CDC流。
将MapR 作为预见性维护的数据平台
工业物联网需要一个以速度和容量伸缩的数据平台。此外,模型开发要求机器学习工程师能够在概念上快速迭代。MapR通过将流、数据库和文件存储聚合在一个线性伸缩的高性能数据平台上来实现这一点,它提供的特征使数据科学家能够快速探索数据、开发模型和使这些模型运转,而不会遇到阻力。
特征工程
机器学习的潜力在于它能够在数据中找到可泛化的模式。传统的统计常常使用数据缩减技术来合并数据样本,而机器学习则是在精度(想象成行)和维数(想象成列)都很高的数据集上蓬勃发展。为使您了解预见性维护推理模型需要消化多少数据量,请设想以下情况:
制造过程可以以有时速度为每秒多达数千个样品(例如,振动传感器)的设备来测量数百个指标。
失败通常不常见(例如,每月一次)。
ML只能预测可以从训练数据中泛化的事件。如果事件很少发生,那么肯定需要长得多的时间来收集数据。一个好的做法是使用跨越数百个事件的数据集来训练模型。
所以,鉴于工业物联网数据本质上就具备丰富的精度和维度,同时预见性维护需要看到成百上千个罕见的故障案例,所以数据平台规模过去常常存储的训练数据不仅必须按摄取速度和可扩展的存储伸缩,而且还要考虑运维常常在训练数据中查找和获取相关特征。这个过程称为特征工程,它对机器学习能否成功至关重要,因为它是领域特定知识发挥作用的点。
特征构建
特征工程经常涉及到向训练数据中添加新列,从而简化手动或自动化分析。这些特征可以帮助人们使用分析工具探索数据,并且它们对于机器算法检测所需的模式来说通常非常关键。特征创建可以通过在摄取过程中增加原始数据或者追溯式地更新训练数据来实现。为了了解其工作原理,我们来看一个例子。
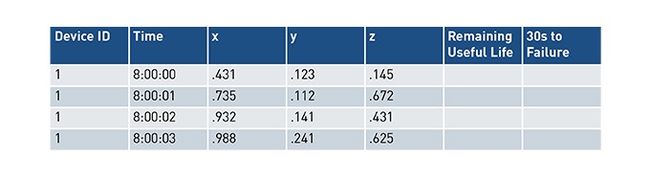
制造过程的一个简单工业物联网数据集如下图所示:
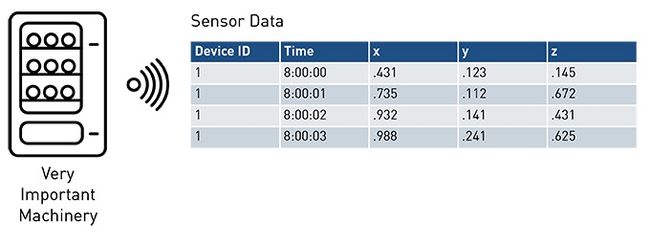
时间戳、设备ID和三个名为x、y和z的指标,代表来自控制网络的性能指标。当我们对表进行扩展以包含操作员日志和其他带外数据源时,它看起来是这样的:

为了将操作员和天气列添加到这个表中,必须要做什么?我们一起来讨论一下。
受控的数据源和公司网络通常是不同步的。因此,操作员和天气日志中的时间戳将与工业物联网数据中的时间戳不同。统一这些时间戳保持在一定的密度,能够更好地回答所提出的问题,比如“显示Joe操作的机器的所有物联网数据”。这种数据集成非常适合在夜间进行批量的处理,因为更新一天的工业物联网记录可能需要很长时间。与其每次让人通过基于时间的查询同时访问物联网和日志字段,重复地进行这些处理,倒不如一次性花成本(例如,每晚)把数据都整合好。因此,当您查看如上所示的表时,要识别出幕后的Spark作业或其他一些数据集成任务,必须将操作员/天气日志与工业物联网日志连接起来,并将它们统一为同一时间戳。
实现这个任务的方法有很多,但是当这些日志位于不同的数据竖井中时,将它们合并到一个统一的特征表中将很缓慢。这就是为什么数据流水线将数据汇聚灵活的数据平台如此重要,因为在这种平台中可以以最小的数据移动运行数据集成。
特征提取
特征提取涉及组合变量以生成更有用的字段。例如,将日期和时间字段按组成部分进行分割是很有用的,这样您就可以轻松地根据在这一天的几点、在一周中的哪天、月亮的相位(谁知道呢,对吧?)等来划分训练数据子集。在批处理作业或流作业中很容易就能实现这种类型的特征提取,因为可以用Java、Python和Scala等语言来实现这些作业,而这些语言都有一些用于简化日期/时间操作的库。但实现一个SQL函数来判断日期/时间值是否在周末要困难得多。添加一个_weekend属性,同时在流作业或批处理作业中增加一个特征表,这样可以使手动分析更加容易,并有助于机器学习算法在一周内泛化模式。
特征滞后
预见性维护是一种称为监督式机器学习的机器学习,因为它涉及到构建一个预测标签的模型,基于的是这些标签如何映射到训练数据中的特征。预见性维护最常用的两种标签是:
接下来n步失败的可能性(例如,“即将失败”)
下一次故障前的剩余时间(或机器周期)(如“剩余使用寿命”)
第一个特征可以使用二进制分类模型进行预测,该模型输出指定时间窗口内的故障概率(例如,“我有90%的把握判断在未来50小时内会发生故障”)。第二个特征可以使用回归模型进行预测,该模型输出剩余使用寿命的值(RUL)。这些变量是滞后的,这意味着直到故障事件发生之前都不能为它们分配标签。
当出现故障时,可以计算这些滞后变量的值,并将其回溯更新到特征表中。
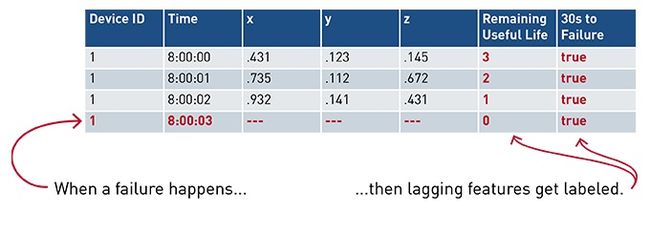
如果失败事件很罕见,但是工业物联网数据非常多,那么特征滞后回溯标记可能会导致大规模的表更新。在下一节中,我将讨论Apache Spark和MapR-DB这两项技术如何协作来解决这个挑战。
具有MapR-DB 和 Spark的可伸缩特征工程
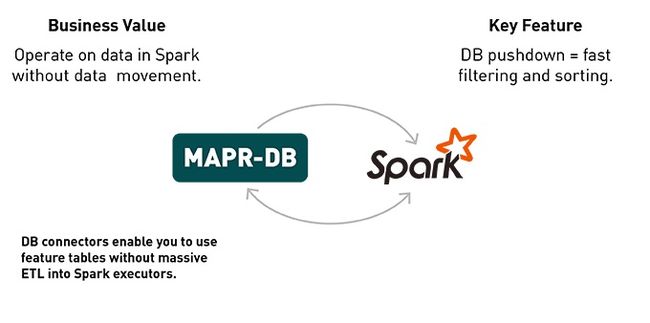
预见性维护的特征表很容易就会超出一台计算机上存储和处理的能力。将这些数据分布在一组机器上可以增加能力,但是如果您最终仍然需要将数据移回一台机器上进行分析和模型训练,可能就不希望这样做了。为了避免数据移动和单点故障,存储和计算都需要做成分布式的。Apache Spark和MapR-DB为这个任务提供了一个方便的解决方案。
Mapr-DB是一个分布式NoSQL数据库,它提供了构建大型特征表所需的伸缩性和模式灵活性。
Apache Spark提供了分布式计算功能,从而可以突破单机内存容量的限制进行特征表的分析。
如果使用针对Spark的MapR-DB链接器,则不再需要将整个特征表复制到Spark进程中了。而是由MapR-DB在本地执行筛选器,对从Spark SQL中提交的数据进行排序,只将结果数据返回给Spark。
预见性维护特征工程实例
我为一个工业暖通空调系统构建了一个概念上的预见性维护应用程序,它展示了几个使用MapR-DB和Spark进行特征工程的例子。你可以在Github项目中找到这个演示的代码和文档。下面摘取了一部分,通过实例来解释前面讨论的特征工程概念。
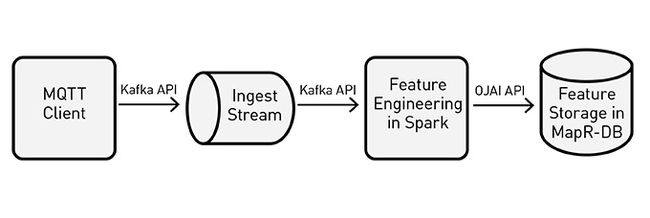
此应用程序的数据流水线由MQTT客户端组成,该客户机使用Kafka API将空调系统数据发布到流中。当Spark进程使用这些记录时,摄取流缓冲这些记录,并用派生出的特征将它们持久化到MapR-DB中的一个表中。流水线如下所示:
下面的Scala代码展示了如何使用Spark读取流记录:
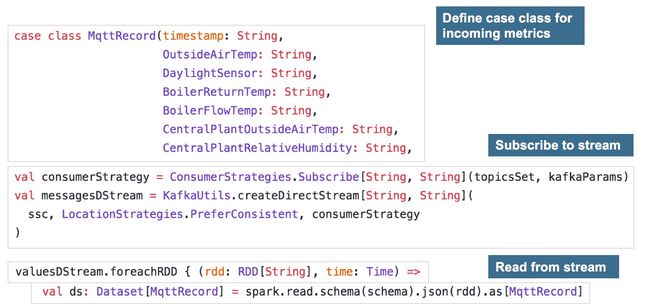
上面的代码创建了一个含有原始MQTT记录的数据集对象。这个数据集可以通过派生出的特征加以丰富,如下所示:
(注意,字段名称以下划线开头的表示是派生的特征。)

然后使用OJAI API将这个丰富过的数据集保存到MapR-DB中,如下所示:

到目前为止,MapR-DB中的特征表包含了空调系统传感器的值和一些派生的特征,如_weekend,但是滞后的变量AboutToFail和retain usefullife的值仍然没有赋值。
Spark作业用于接收流上的故障通知和更新滞后的变量,看起来如下所示:
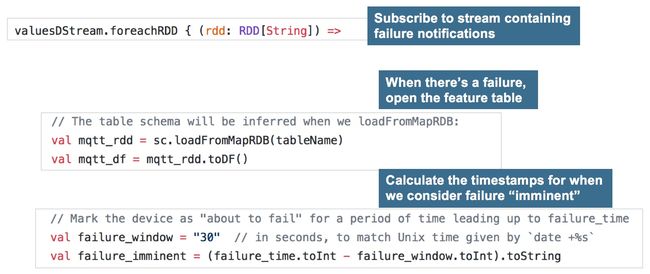
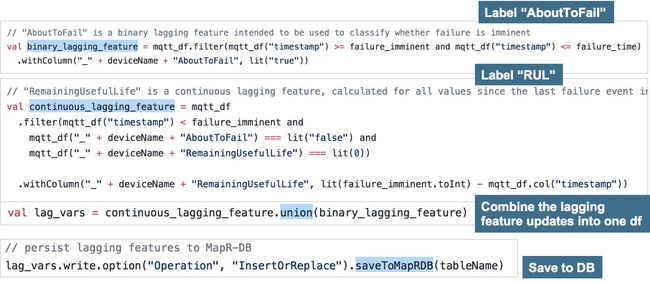
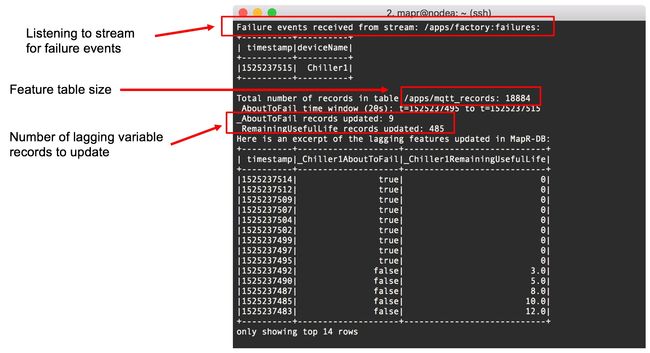
当这个Spark作业收到一个失败通知时,会计算滞后变量的值,然后将这些值回溯更新到MapR-DB中的特征表中。如图13,演示了应用程序中对此过程的输出。
预见性维护算法示例
在前几节中,我讲到了记录与导致故障事件的条件相关数据的技术,以便可以通过机器学习训练预见性维护模型。在这一节中,我将讨论如何处理这些数据,以及如何实际训练一个能够预测故障的模型。
长短时记忆(Long Short-Term Memory, LSTM)算法通常用于预测时间序列数据中的罕见事件。由于故障在预见性维护应用中非常罕见,所以它的建模很适合使用LSTM算法。对于大多数流行的机器学习框架,都有现成的LSTM示例。我选择Keras来实现上面讨论的“即将失败”指标的LSTM算法。如果你想了解更多细节,请阅读我在GitHub上发布的Jupyter笔记本。
我的LSTM实现了使用一张特征表(如上面所述)来训练一个模型,该模型预测一台机器在50个周期内是否可能出现故障。结果不错,如下所示:
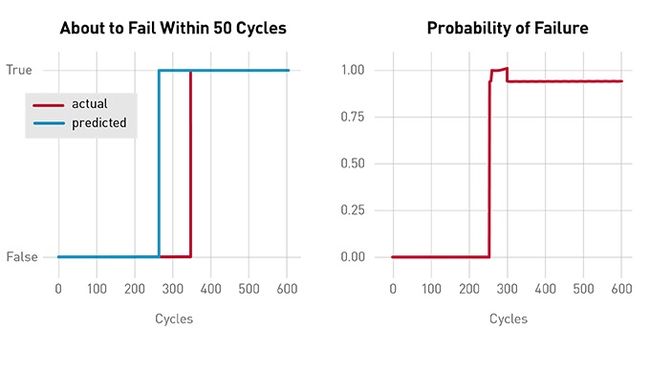
这是一个很不错的结果,因为它在故障实际出现之前就预测出来了,而且预测的准确率很高(\u0026gt;90%)。在下面的例子中,模型做了一个没有用的预测,因为它只是在故障出现之后才预测出来的:

使用不同的训练数据集来更好地理解LSTM的灵敏性是件很有意思的事。在我的Jupyter笔记本中,解释了如何合并数据集和训练模型,所以你也可以按这种方式在你的笔记本上使用LSTM进行实验。为了使数据准备和LSTM实现的步骤更容易理解,我刻意地只使用了该练习中的部分特征。这些就留待你在我发布在GitHub上的笔记本中查找吧,在此就不加以赘述了。
总结
机器学习有可能比过去使用的传统方法使预测维护策略更有效。然而,由于工业物联网数据源的高带宽、现实生活中机械故障的稀缺性以及训练模型需要高解析度数据,预测维护给数据工程带来了重大挑战。为了预见性地维护应用程序,任何敢于开发和部署机器学习的有效性还将取决于一个基础数据平台,随着数据科学家迭代特征工程概念和模型的发展,该平台的独立需求是,不仅能够存储数据,而且数据访问还要畅通无阻。
关于作者
Ian Downard 是一位MapR的数据工程师和开发者传道士。他喜欢学习和分享工具和流程相关的知识,使DataOps团队能够将机器学习应用到生产中。Ian负责协调俄勒冈州波特兰市的Java用户组,并在这里和这里撰写关于大数据的文章。
查看英文原文:[Conquering the Challenges of Data Preparation for Predictive Maintenance](