hive自定义行分隔符
首先交代一下背景:
通过spring消费RMQ的数据写到hdfs,从一开始就预料到直接写textfile会有错行乱行的问题,所以一开始的方案是写parquet,经过验证后发现写parquet会有很多小文件(parquet文件落地后不能修改,不能追加),会对name node造成额外的压力,所以最终妥协写textfile 加自定义行分割符
-
查看hive默认的textfile 的inputformat

默认的TextInputFormat在hadoop-mapreduce-client-core包里面,主要代码:
public RecordReader<LongWritable, Text> getRecordReader(
InputSplit genericSplit, JobConf job,
Reporter reporter)
throws IOException {
reporter.setStatus(genericSplit.toString());
String delimiter = job.get("textinputformat.record.delimiter");
byte[] recordDelimiterBytes = null;
if (null != delimiter) {
recordDelimiterBytes = delimiter.getBytes(Charsets.UTF_8);
}
return new LineRecordReader(job, (FileSplit) genericSplit,
recordDelimiterBytes);
}
通过源码发现可以通过textinputformat.record.delimiter这个参数指定行分隔符,经过测试发现也能实现(至于为什么还要自定义inputformat,我们后面再说)


继续往下看LineRecordReader,主要代码
public LineRecordReader(Configuration job, FileSplit split,
byte[] recordDelimiter) throws IOException {
this.maxLineLength = job.getInt(org.apache.hadoop.mapreduce.lib.input.
LineRecordReader.MAX_LINE_LENGTH, Integer.MAX_VALUE);
start = split.getStart();
end = start + split.getLength();
final Path file = split.getPath();
compressionCodecs = new CompressionCodecFactory(job);
codec = compressionCodecs.getCodec(file);
// open the file and seek to the start of the split
final FileSystem fs = file.getFileSystem(job);
fileIn = fs.open(file);
if (isCompressedInput()) {
decompressor = CodecPool.getDecompressor(codec);
if (codec instanceof SplittableCompressionCodec) {
final SplitCompressionInputStream cIn =
((SplittableCompressionCodec)codec).createInputStream(
fileIn, decompressor, start, end,
SplittableCompressionCodec.READ_MODE.BYBLOCK);
in = new LineReader(cIn, job, recordDelimiter);
start = cIn.getAdjustedStart();
end = cIn.getAdjustedEnd();
filePosition = cIn; // take pos from compressed stream
} else {
in = new LineReader(codec.createInputStream(fileIn, decompressor), job, recordDelimiter);
filePosition = fileIn;
}
} else {
fileIn.seek(start);
in = new LineReader(fileIn, job, recordDelimiter);
filePosition = fileIn;
}
// If this is not the first split, we always throw away first record
// because we always (except the last split) read one extra line in
// next() method.
if (start != 0) {
start += in.readLine(new Text(), 0, maxBytesToConsume(start));
}
this.pos = start;
}
通过new LineReader(cIn, job, recordDelimiter);来进行行的读取,到此源码的追踪就结束了
-
既然可以通过参数实现自定义行分隔符,为什么还要自定义
通过set textinputformat.record.delimiter将会影响你整个session内使用的所有textfile格式的表,这样就会影响到其它表,这样不符合我的预期,我只是想对某些特殊的表进行自定行分隔符,所以还是要自定义inputformat,这样我只需要在建表的时候指定特定的inputformat就行了 -
实现自定义inputformat
首先根据自己的环境选择合适版本的依赖
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.0.0-cdh6.1.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>3.0.0-cdh6.1.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-annotations</artifactId>
<version>3.0.0-cdh6.1.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hive/hive-exec -->
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>2.1.1-cdh6.1.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/commons-logging/commons-logging -->
<dependency>
<groupId>commons-logging</groupId>
<artifactId>commons-logging</artifactId>
<version>1.1.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.slf4j/slf4j-api -->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.7.25</version>
</dependency>
创建DIYInputFormat继承FileInputFormat,下面我只贴出来需要修改的部分代码
//为了和原来的参数不冲突,这个key可以随意自行设置
// String delimiter = job.get("textinputformat.record.line.delimiter");
String delimiter = "#^#@%$#";
byte[] recordDelimiterBytes = null;
if (null != delimiter) {
recordDelimiterBytes = delimiter.getBytes(Charsets.UTF_8);
}
return new DIYLineRecordReader(job, (FileSplit) genericSplit,
recordDelimiterBytes);
然后创建DIYLineRecordReader继承org.apache.hadoop.util.LineReader ,下面是需要修改的代码
private static final String defaultFSep="\u0001";
private final static String defaultEncoding = "UTF-8";
this.FieldSep = job.get("textinputformat.record.fieldsep",defaultFSep);
this.encoding = job.get("textinputformat.record.encoding",defaultEncoding);
if (encoding.compareTo(defaultEncoding) != 0) {
String str = new String(value.getBytes(), 0, value.getLength(), encoding);
value.set(str);
}
if (FieldSep.compareTo(defaultFSep) != 0) {
String replacedValue = value.toString().replace(FieldSep, defaultFSep);
value.set(replacedValue);
}
在这里我是把行分割符写死了#^#@%$#,你也可以根据自己的需求进行自定义,莫急,稍后为附上完整的代码
- 打包,建表
用maven打包这里就不多说了,将打好的jar,放到hive的指定目录或者每次用的时候add进来,具体操作类似hive的自定义函数,参考文章自定义UDTF和hive自定义函数的永久注册,建表语句
CREATE TABLE `stu`(
`name` string,
`class` string,
`age` string,
`teacher` string,
`sex` string)
PARTITIONED BY (
`pt` string)
STORED AS
InputFormat 'com.wcf.hive.DIYInputFormat'
OutputFormat 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat';
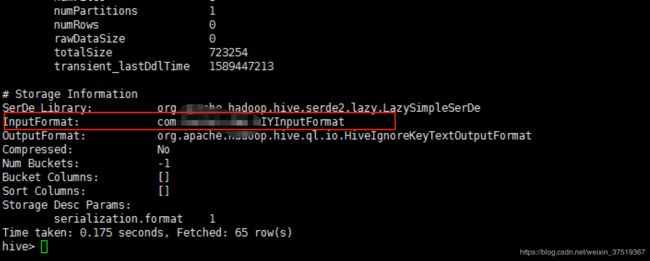
在建表的时候指定自定义的class即可,在这里我为了方便就用的固定的行分隔符,这样就不用每次去指定,方便省事,完整代码github链接,后面如果有时间的话会把写hdfs的关键代码再跟大家分享一下,如果你的需求可以接受把字段里面的\n都替换掉,那你就不用费劲这么搞了,个人觉得去改变原始的数据,这不太好,也显得不够专业