基于KNN算法的图像内容分类
一,KNN算法原理
1,KNN算法思想
这种算法把要分类的对象(例如一个特征向量)与训练集中已知类标记的所有对象进行对比,并由k近邻对指派到哪个类进行投票。例如一个未知样本数据x需要归类,总共有ABC三个类别,那么离x距离最近的有k个邻居,这k个邻居里有k1个邻居属于A类,k2个邻居属于B类,k3个邻居属于C类,如果k1>k2>k3,那么x就属于A类,也就是说x的类别完全由邻居来推断出来。
2,KNN算法实现步骤:即“找邻居 + 投票决定”
(1)计算测试对象到训练集中每个对象的距离(通常用欧式距离)
(2)按照距离的远近排序
(3)选取与当前测试对象最近的k的训练对象,作为该测试对象的邻居
(4)统计这k个邻居的类别频率
(6)k个邻居里频率最高的类别,即为测试对象的类别
3,KNN算法的一个简单二维示例
随机生成两组训练和测试数据,并且第二组数据呈环状分布
实现KNN数据的可视化
# -*- coding: utf-8 -*-
import pickle
from pylab import *
from PCV.classifiers import knn
from PCV.tools import imtools
pklist=['points_normal.pkl','points_ring.pkl']
figure()
# load 2D points using Pickle
for i, pklfile in enumerate(pklist):
with open(pklfile, 'rb') as f:
class_1 = pickle.load(f)
class_2 = pickle.load(f)
labels = pickle.load(f)
# load test data using Pickle
with open(pklfile[:-4]+'_test.pkl', 'rb') as f:
class_1 = pickle.load(f)
class_2 = pickle.load(f)
labels = pickle.load(f)
model = knn.KnnClassifier(labels,vstack((class_1,class_2)))
# test on the first point
print (model.classify(class_1[0]))
#define function for plotting
def classify(x,y,model=model):
return array([model.classify([xx,yy]) for (xx,yy) in zip(x,y)])
# lot the classification boundary
subplot(1,2,i+1)
imtools.plot_2D_boundary([-6,6,-6,6],[class_1,class_2],classify,[1,-1])
titlename=pklfile[:-4]
title(titlename)
show() 图1
图1
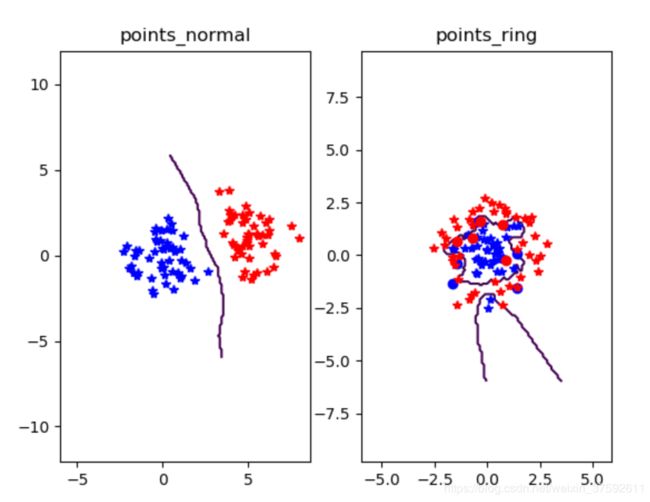 图2
图2
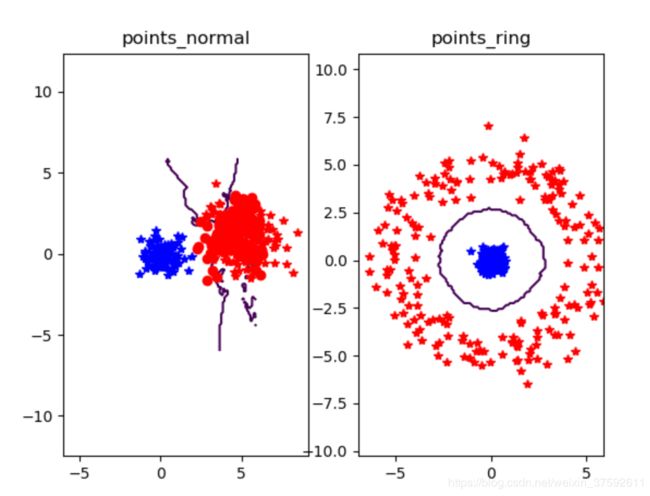 图3
图3
上图两种类别分别用红色和蓝色的+好表示,错误的分类用o表示
从实验结果可以看出,当样本数据分布较为均匀的时候用K近邻算法分类的效果较好(如图1),但是当样本的数据都差不多时,knn近邻算法的分类效果就不是很好了,如图2 的poing_img所显示的,两种类别的样本数据距离较近,这是用knn近邻算法分类显示很多错误发分类;此外从实现中发现,knn算法的运行速度较慢,由于knn算法每一次分类都会重新进行全局运算,当样本的数据量大时运算速度很慢;而且knn算法的分类效果还取决于k的大小,当k太小容易造成过拟合问题,当k太大时,造成预测不准确例如图三显示,k=20(图1,图2k=3)时points_nomal出现大量的分类错误。当然,knn算法的优点也很明显,算法容易理解,很简单,对异常值不敏感等。
二,基于Knn算法的图像分类
1,用稠密SIFT作为图像特征
要对图像进行分类,首先需要一个特征向量来表示一幅图像,本实验中用稠密SIFT特征向量描绘一幅图像的特征向量。即在整幅图像上用一个规则的网格应用SIFT描述子可以得到稠密SIFT的表示形式。dense sift将表达目标的矩形区域分成相同大小的矩形块,计算每一个小块的SIFT特征,再对各个小块的稠密SIFT特征在中心位置进行采样,建模目标的表达.然后度量两个图像区域的不相似性,先计算两个区域对应小块的Bhattacharyya距离,再对各距离加权求和作为两个区域间的距离。
2,为什么要用densif提取图像特征
我们发现,图像识别问题大多用Dense-SIFT,而图像检索总是用SIFT。dense-SIFT在图像检索上的性能不如SIFT检测子的性能好。对于图像识别问题来说,由于有充足的训练样本,可以采用密集采样,是因为密集采样后的点,会通过训练后的分类器进行了进一步的筛选。所以,无需人工干预特征点的选取。 而检索问题则不同了,大多数情况下我们并没有训练样本。因此,我们需要利用人的经验过滤区分性低的点(除此之外还引入了IDF进一步加权)。因此,大部分检索问题都利用了检测子,而不是密集采样。
3,稠密SIFT描述子的例子
dense sift与sift算法代码不同地方主要在下面这个函数中:
def process_image_dsift(imagename,resultname,size=20,steps=10,force_orientation=False,resize=None):
""" Process an image with densely sampled SIFT descriptors
and save the results in a file. Optional input: size of features,
steps between locations, forcing computation of descriptor orientation
(False means all are oriented upwards), tuple for resizing the image."""
im = Image.open(imagename).convert('L')
if resize!=None:
im = im.resize(resize)
m,n = im.size
if imagename[-3:] != 'pgm':
#create a pgm file
im.save('tmp.pgm')
imagename = 'tmp.pgm'
# create frames and save to temporary file
scale = size/3.0
x,y = meshgrid(range(steps,m,steps),range(steps,n,steps))
xx,yy = x.flatten(),y.flatten()
frame = array([xx,yy,scale*ones(xx.shape[0]),zeros(xx.shape[0])])
savetxt('tmp.frame',frame.T,fmt='%03.3f')
path = os.path.abspath(os.path.join(os.path.dirname("__file__"),os.path.pardir))
path = path + "\\python3-ch08\\win32vlfeat\\sift.exe "
if force_orientation:
cmmd = str(path+imagename+" --output="+resultname+
" --read-frames=tmp.frame --orientations")
else:
cmmd = str(path+imagename+" --output="+resultname+
" --read-frames=tmp.frame")
os.system(cmmd)
print ('processed', imagename, 'to', resultname)
在一幅图像上实现densift描述子
# -*- coding: utf-8 -*-
from PCV.localdescriptors import sift, dsift
from pylab import *
from PIL import Image
dsift.process_image_dsift('example.jpg','example.dsift',10,5,resize=(803,803))
l,d = sift.read_features_from_file('example.dsift')
im = array(Image.open('example.jpg'))
sift.plot_features(im,l,True)
title('dense SIFT')
show() 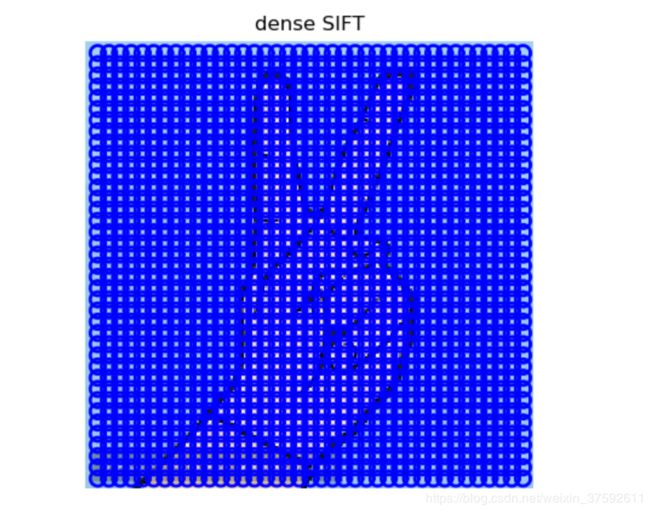
3,手势识别
实验中用静态手势图像3,A,B,C,F,P(1),进行识别;首先利用train文件夹里的数据进行训练,利用在利用test利的图像进行测试。
# -*- coding: utf-8 -*-
from PCV.localdescriptors import dsift
import os
from PCV.localdescriptors import sift
from pylab import *
from PCV.classifiers import knn
def get_imagelist(path):
""" Returns a list of filenames for
all jpg images in a directory. """
return [os.path.join(path,f) for f in os.listdir(path) if f.endswith('.ppm')]
def read_gesture_features_labels(path):
# create list of all files ending in .dsift
featlist = [os.path.join(path,f) for f in os.listdir(path) if f.endswith('.dsift')]
# read the features
features = []
for featfile in featlist:
l,d = sift.read_features_from_file(featfile)
features.append(d.flatten())
features = array(features)
# create labels
labels = [featfile.split('/')[-1][0] for featfile in featlist]
return features,array(labels)
def print_confusion(res,labels,classnames):
n = len(classnames)
# confusion matrix
class_ind = dict([(classnames[i],i) for i in range(n)])
confuse = zeros((n,n))
for i in range(len(test_labels)):
confuse[class_ind[res[i]],class_ind[test_labels[i]]] += 1
print ('Confusion matrix for')
print (classnames)
print (confuse)
filelist_train = get_imagelist('gesture/train')
filelist_test = get_imagelist('gesture/test')
imlist=filelist_train+filelist_test
# process images at fixed size (50,50)
for filename in imlist:
featfile = filename[:-3]+'dsift'
dsift.process_image_dsift(filename,featfile,10,5,resize=(50,50))
features,labels = read_gesture_features_labels('gesture/train/')
test_features,test_labels = read_gesture_features_labels('gesture/test/')
print(test_labels)
classnames = unique(labels)
# test kNN
k = 1
knn_classifier = knn.KnnClassifier(labels,features)
res = array([knn_classifier.classify(test_features[i],k) for i in
range(len(test_labels))])
# accuracy
acc = sum(1.0*(res==test_labels)) / len(test_labels)
print ('Accuracy:', acc)
print_confusion(res,test_labels,classnames)
测试图片如下:



 图1
图1
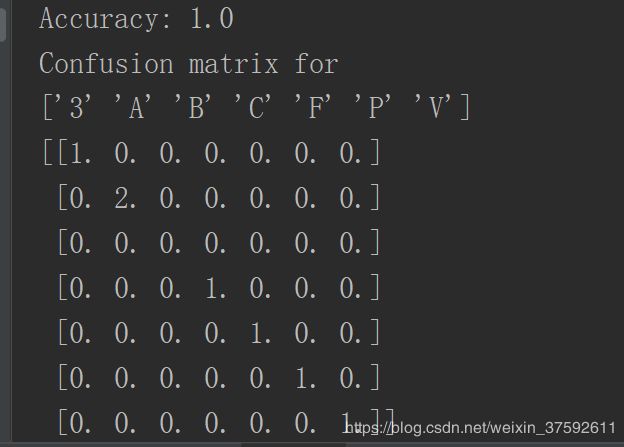 图2
图2
图1,是用199张图片对图片进行分类,并用矩阵表示分类结果。识别的准确率为81.9%通过输出的矩阵表明P很容易被分为V。图2是用网上查找的五张图片对图像进行分类实验结果的准确率到达100%.分类的效果很好。