HBASE2.2.2+hadoop3.1.3分布式集群搭建
以下安装基于已经安装了JDK的前提,如果还没有安装JDK需要自行安装。
安装zookeeper集群
备注:zookeeper集群每台服务器必须绑定hadoop集群和HBASE集群的hosts,不然会找不到对应的服务器
- 到官网上下载对应版本的zookeeper,笔者用的版本是:zookeeper-3.4.14
zookeeper官方下载地址 - 将下载好的压缩包分发到服务器上的/usr/local/目录下,并解压:
-> tar -zxvf zookeeper-3.4.14.tar.gz
解压后重命名文件文件名为zookeeper:
-> cp zookeeper-3.4.14 zookeeper - 进入/usr/local/zookeeper/conf/,从zoo_sample.cfg文件复制一份zoo.cfg文件,因为zookeeper默认会读取安装目录下的conf/zoo.cfg 作为启动配置文件;
-> cp zoo_sample.cfg zoo.cfg - 修改zoo.cfg文件,配置dataDir, dataLogDir, 和集群服务器列表
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
# 修改数据存放的目录
dataDir=/usr/local/zookeeper/data
# 修改日志存放的目录
dataLogDir=/usr/local/zookeeper/logs
# the port at which the clients will connect
clientPort=2181
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1
# 集群服务器列表
server.1=10.0.27.132:2888:3888
server.2=10.0.27.133:2888:3888
server.3=10.0.27.134:2888:3888
- 手动创建dataDir=/usr/local/zookeeper/data, dataLogDir=/usr/local/zookeeper/logs这两个文件夹,并创建myid文件(myid文件的内容为zoo.cfg里面配置的集群服务器唯一标识,例如:server.1=10.0.27.132:2888:3888对应的10.0.27.132这台服务器的myid就是1)
-> mkdir /usr/local/zookeeper/data
-> mkdir /usr/local/zookeeper/logs
-> echo 1 > myid (不同服务器的标识不同,以zoo.cfg配置的为准) - 把配置好的zookeeper文件夹分发到其他的服务器上,并把对应服务器上的myid文件修改为该服务器的唯一标识。在其他服务器上也手动创建dataDir=/usr/local/zookeeper/data, dataLogDir=/usr/local/zookeeper/logs这两个文件夹;
-> scp -r /usr/local/zookeeper 10.0.27.133:/usr/local/zookeeper
-> scp -r /usr/local/zookeeper 10.0.27.134:/usr/local/zookeeper - 在每台zookeeper服务器上,进入/usr/local/zookeeper/bin/ 目录,启动zookeeper集群
-> ./zkServer.sh start
注意:在所有的zookeeper服务器都运行完启动命令后,再根据 ./zkServer.sh status 命令查看zookeeper服务器启动情况,如果只启动了一部分服务器,运行 ./zkServer.sh status 查看命令可能无法查看启动状态 - 完成zookeeper集群安装
安装说明
注意HBASE和Hadoop之间不是所有版本都互相兼容的,需要上官网查询版本之间的兼容关系!
HBASE与Hadoop版本对应查询官网
官网查询版本对比如下:
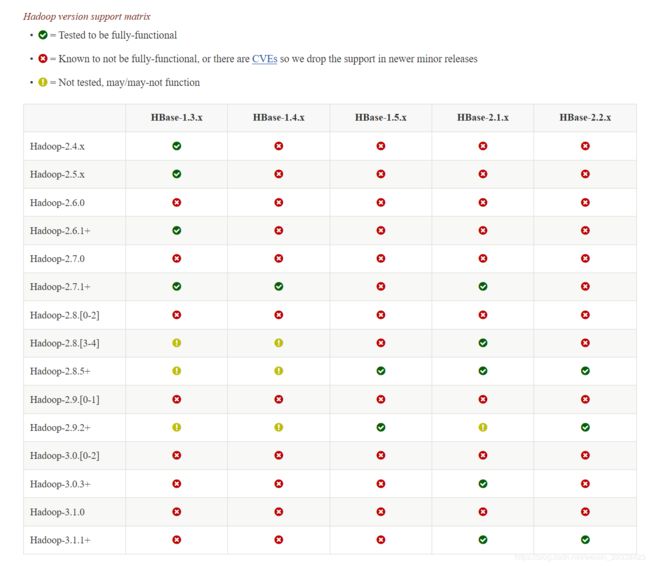
Hadoop安装包下载地址
HBASE安装包下载地址
本教程安装使用的Hadoop版本是:hadoop-3.1.3,HBASE版本是:hbase-2.2.2
安装Hadoop集群
有问题多阅读官方文档!有问题多阅读官方文档!有问题多阅读官方文档!
Hadoop官方文档
配置集群之间的免密登录
免密登录原理
每台主机authorized_keys文件里面包含想要免密登录主机的ssh公钥,就能实现免密登录,所以只要每台主机的authorized_keys文件里面都放入其他主机(需要无密码登录的主机)的ssh公钥就行了。
- 配置服务器集群的hosts文件,方便标识
-> vim /etc/hosts
10.0.27.132 hadoop.master01
10.0.27.133 hadoop.slave01
10.0.27.134 hadoop.slave02
-
在主节点上生成ssh密钥:
-> ssh-keygen -t rsa
-> cd ~/.ssh/ -
在主节点上将公钥拷到一个特定文件authorized_keys中
-> cp id_rsa.pub authorized_keys -
使用scp命令把主节点上的authorized_keys分发到其它节点,按照第一步的命名生成其它节点的ssh密钥,并把公钥追加到authorized_keys文件中:
-> scp authorized_keys [email protected]:/root/.ssh/
-> cat id_rsa.pub >> authorized_keys -
最后将所有服务器的公钥都添加好authorized_keys文件通过scp命令重新分发到集群中的所有服务器,完成后就可以使用ssh username 的命令互相免密登录。
-> ssh hadoop.slave01
安装并修改Hadoop配置文件
安装前注意事项:
本文配置的IP全部用hosts文件映射的服务器名代替,这种方式配置,hbase client所在的业务服务器想要连接hbase集群都需要配置对应的hosts文件!或者也可以把hadoop和hbase配置文件中的服务器全部显示用ip就无须在业务服务器配置hosts文件
- 下载Hadoop安装包,并上传到服务器上解压
Hadoop安装包下载地址
下载完后Windows系统可以通过FileZilla工具把安装包传到Linux服务器上,Mac系统可以直接使用scp名称上传。我上传到 /opt/ 目录下面,然后解压
-> tar -zxvf hadoop-3.1.3.tar.gz
- 配置Hadoop环境变量
-> vim /etc/profile
# Hadoop
# 该目录为解压安装目录
export HADOOP_HOME=/opt/hadoop-3.1.3
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
生效环境变量配置
-> source /etc/profile
- 修改配置文件
hadoop的配置文件在HADOOP_HOME/etc/hadoop/下,需要修改的配置文件有:hadoop-env.sh,core-site.xml
修改hadoop-env.sh文件,在文件结尾添加如下内容:
# JAVA_HOME路径,可用echo $JAVA_HOME获得
export JAVA_HOME=/usr/local/jdk1.8
# 为hadoop配置不同角色的用户,最好都配置上,不然就可能会有缺失用户配置而有问题
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
export HDFS_JOURNALNODE_USER=root
export HDFS_ZKFC_USER=root
配置core-site.xml文件:
<configuration>
<property>
<name>fs.defaultFSname>
<value>hdfs://hbaseclustervalue>
property>
<property>
<name>hadoop.tmp.dirname>
<value>/home/hadoop/tempdatavalue>
property>
<property>
<name>io.file.buffer.sizename>
<value>131072value>
property>
<property>
<name>ha.zookeeper.quorumname>
<value>hadoop.master01:2181,hadoop.slave01:2181,10.0.27.129:2181value>
property>
configuration>
配置hdfs-site.xml文件:
引入JQM机制官方文档
<configuration>
<property>
<name>dfs.namenode.name.dirname>
<value>/home/hadoop/hadoopdatavalue>
property>
<property>
<name>dfs.datanode.data.dirname>
<value>/home/hadoop/datavalue>
property>
<property>
<name>dfs.blocksizename>
<value>134217728value>
property>
<property>
<name>dfs.replicationname>
<value>3value>
property>
<property>
<name>dfs.nameservicesname>
<value>hbaseclustervalue>
property>
<property>
<name>dfs.ha.namenodes.hbaseclustername>
<value>nn1,nn2value>
property>
<property>
<name>dfs.namenode.rpc-address.hbasecluster.nn1name>
<value>hadoop.master01:8020value>
property>
<property>
<name>dfs.namenode.rpc-address.hbasecluster.nn2name>
<value>hadoop.slave01:8020value>
property>
<property>
<name>dfs.namenode.http-address.hbasecluster.nn1name>
<value>hadoop.master01:9870value>
property>
<property>
<name>dfs.namenode.http-address.hbasecluster.nn2name>
<value>hadoop.slave01:9870value>
property>
<property>
<name>dfs.namenode.shared.edits.dirname>
<value>qjournal://hadoop.master01:8485;hadoop.slave01:8485;hadoop.slave02:8485/hbaseclustervalue>
property>
<property>
<name>dfs.client.failover.proxy.provider.hbaseclustername>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvidervalue>
property>
<property>
<name>dfs.ha.fencing.methodsname>
<value>
sshfence
shell(/bin/true)
value>
property>
<property>
<name>dfs.ha.fencing.ssh.private-key-filesname>
<value>/root/.ssh/id_rsavalue>
property>
<property>
<name>dfs.journalnode.edits.dirname>
<value>/home/hadoop/jnodedata/jnode_edits_dirvalue>
property>
<property>
<name>dfs.ha.automatic-failover.enabledname>
<value>truevalue>
property>
configuration>
配置yarn-site.xml文件:
<configuration>
<property>
<name>yarn.resourcemanager.hostnamename>
<value>hadoop.master01value>
property>
<property>
<name>yarn.resourcemanager.webapp.addressname>
<value>hadoop.master01:8088value>
property>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
configuration>
修改mapred-site.xml文件:
<configuration>
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
configuration>
配置从节点workers文件,添加从节点服务器:
hadoop.slave01
hadoop.slave02
- 把Hadoop安装包分发到其他节点,并给每个节点配置环境变量
-> scp -r /opt/hadoop-3.1.3 hadoop.slave01:/opt/hadoop-3.1.3/
启动Hadoop
启动注意事项:
启动前必须要关闭服务器的防火墙,不然会导致节点之间无法连接而报错:No Route to Host from hadoop.master01/10.0.27.132 to hadoop.slave01:8485 failed on socket timeout exception : java.net.NoRouteToHostException: No route to host.
不关闭防火墙web界面也会无法访问。
查看防火墙状态
-> firewall-cmd --state
关闭防火墙
-> systemctl stop firewalld.service
- 首次启动Hadoop集群需要格式化和初始化一些信息,必须要按顺序执行以下命令用于初始化集群,命令位于$HADOOP_HOME/bin目录下,配置过环境变量就无须指定命令的目录
# 1.首先在配置了JournalNode服务的每台服务器上都执行命令,必须至少有3个JournalNode守护进程,
# 当使用N个JournalNodes运行时,系统最多可以容忍(N - 1) / 2个故障,并继续正常运行。
# 执行命令后可通过jps看到JournalNode进程
hdfs --daemon start journalnode
# 2.在配置的一台master服务器上(nn1=hadoop.master01)执行格式化nameNode命令(否则会导致HDFS文件系统连接不上)
# 格式化命令要求dfs.journalnode.edits.dir参数配置的文件存储目录是空文件夹,否则无法格式化
hdfs namenode -format
# 3.在格式化后的master服务器上运行HDFS启动命令(不先启动namenode节点,备用namenode服务器运行
# hdfs namenode -bootstrapStandby时会无法连接已格式化的namenode节点同步元数据):
$HADOOP_HOME/sbin/start-dfs.sh
# 4.在其余的备用master服务器上(nn2=hadoop.slave01)执行命令(执行该命令是为了将已格式化的NameNode元数据目录内容
# 复制到其他未格式化的NameNode,同时确保JournalNode(由dfs.namenode.shared.edits.dir配置)包含足够的编辑事务
# 以能够启动两个NameNode,否则会导致备用namenode节点无法启动):
hdfs namenode -bootstrapStandby
# 5.停止所有的hadoop进程,然后格式化zookeeper,在任意一台master服务器上执行命令
./stop-all.sh
hdfs zkfc -formatZK
# 6.到master节点的sbin目录下执行stop-all.sh停止所有hadoop进程,再依次到每台JournalNode服务器上启动journalnode守护进程,最后在master节点的服务器上执行start-all.sh启动命令,就可以访问namenode的web界面查看所有namenode的状态:
hdfs --daemon start journalnode
./start-all.sh
首次安装成功之后再次启动hadoop集群:
1)先在每台JournalNode服务器上执行命令(必须先启动JournalNode进程,不然namenode节点无法正常启动):
hdfs --daemon start journalnode
2)JournalNode进程启动之后再执行命令($HADOOP_HOME/sbin/ 目录下):
./start-all.sh
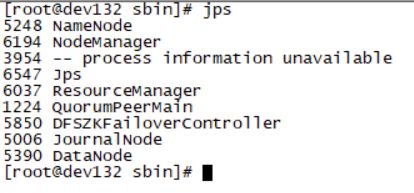
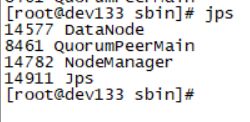
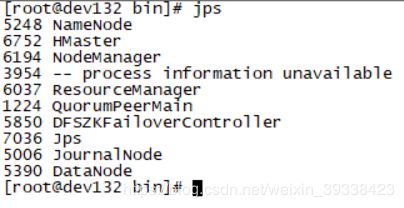
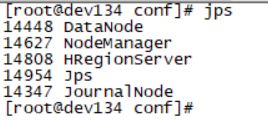
- 使用jps命令查看Hadoop进程
master节点和备用master节点启动了JournalNode,NameNode,NodeManager,ResourceManager,DataNode,DFSZKFailoverController 六个进程
从节点启动了JournalNode,DataNode,NodeManager三个进程
- 输入ip:port,Hadoop不同版本的web界面的端口号会不大一样,具体参考官方文档:
Hadoop官方文档
Hadoop3.1.3分布式部署官方文档
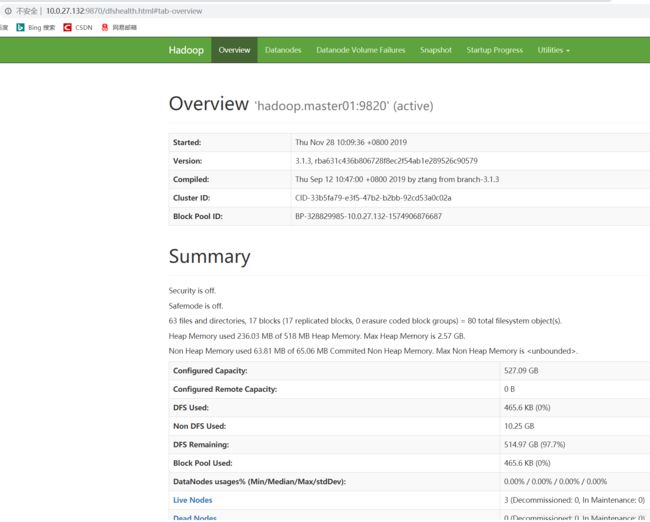
Hadoop3.1.3版本web界面的端口号如下图所示:

访问hadoop.master01:9870,hadoop.slave01:9870,查看已激活的nameNode和备用namenode信息如下图(已激活的namenode状态是active,备用namenode的状态是standby):
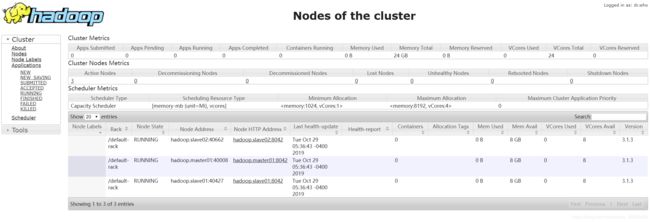
访问ip:8088,查看resourceManager信息如下图:
安装HBASE集群
HBASE分布式部署官方文档
下载HBASE安装包
HBASE安装包下载地址
本教程下载的是2.2.2的版本
Windows使用Filezilla工具,Mac使用scp命令把安装包上传到服务器上,解压
-> tar -zxvf hbase-2.2.2-bin.tar.gz
安装前注意事项:
- 检查HBASE集群每台服务器的时间是否是一致的,不然会导致集群启动异常,检查服务器时间用命令:date -R
安装并修改HBASE配置文件
hbase的配置文件在 HBASE_HOME/conf 下,需要修改的配置文件有:hbase-env.sh,hbase-site.xml,regionservers,backup-masters(改文件需要手动创建)
- 配置hbase-env.sh文件,该文件用于设置HBase的工作环境,包括 JAVA和其他环境变量的配置,该文件的改动需要重启HBase才能生效(默认配置文件中有详细的配置都注释掉了,可以):
# JAVA_HOME路径,可用echo $JAVA_HOME获得
export JAVA_HOME=/usr/local/jdk1.8
# 关闭Hbase自带的zookeeper集群
export HBASE_MANAGES_ZK=false
- 配置hbase-site.xml文件,HBase主要的配置文件,该文件可覆盖HBase的默认配置,可以在HBase Web UI的HBase配置选项中查看整个集群的有效配置,包括默认和覆盖的:
<configuration>
<property>
<name>hbase.rootdirname>
<value>hdfs://hbasecluster/hbasevalue>
property>
<property>
<name>hbase.cluster.distributedname>
<value>truevalue>
property>
<property>
<name>hbase.zookeeper.quorumname>
<value>hadoop.master01:2181,hadoop.slave01:2181,10.0.27.129:2181value>
property>
<property>
<name>hbase.zookeeper.property.dataDirname>
<value>/usr/local/zookeeper/datavalue>
property>
<property>
<name>hbase.master.info.portname>
<value>16010value>
property>
<property>
<name>hbase.regionserver.info.portname>
<value>16030value>
property>
<property>
<name>hbase.unsafe.stream.capability.enforcename>
<value>falsevalue>
property>
configuration>
- 新建 backup-masters文件,添加备份HMaster机器名,该文件不能写注释,启动时会把注释的那行当成服务器列表而导致启动失败:
hadoop.slave01
- 修改regionservers配置文件,添加HBase集群中运行RegionSever的主机名或IP列表,每行一个(分布式部署可以把默认的一行localhost删除掉),该文件不能写注释,启动时会把注释的那行当成服务器列表而导致启动失败:
hadoop.slave01
hadoop.slave02
-
Hadoop引入JQM负载均衡机制需要把Hadoop的core-site.xml和hdfs-site.xml两个配置文件拷贝到HBASE的配置文件目录中,不然会导致HBASE集群无法启动。不引入JQM就无须拷贝。
-
把hbase安装目录分发给其他节点,按照官方文档的提示,所有节点的配置文件信息要保持完全一样
-> scp -r /opt/hbase-2.2.2 hadoop.slave01:/opt/hbase-2.2.2/
启动HBASE服务
在master节点运行启动命令,会同步启动master的备份节点和regionServer节点:
-> ./start-hbase.sh
master服务器和备用master服务器会启动HMaster,HRegionServer两个进程
slave服务器会启动HRegionServer一个进程
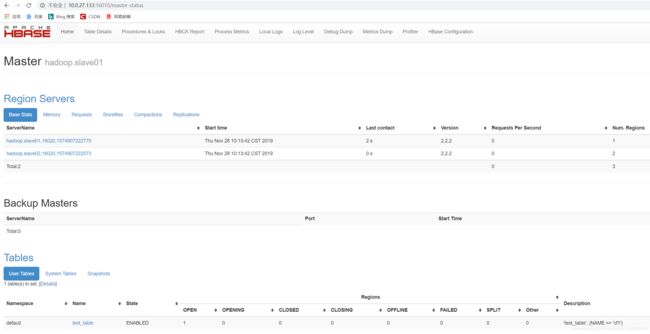
输入:hadoop.master01:16010,hadoop.slave01:16010,访问web界面如下(hadoop.master01显示是 Master节点,hadoop.slave01显示是backup节点):
hbase常用命令
重启HMaster节点:
当active HMaster节点挂掉之后,backup HMaster会自动称为active状态,可以进入到宕机的HMaster服务器上运行命令重启HMaster节点,重启后的HMaster就会变成backup HMaster,重启命令如下:
-> ./hbase-daemon.sh start master
重启regionServer节点: