完全分布式hadoop集群搭建
考虑到以后还会去配置,总结记录一下这几天迈过的坑。
准备工作:
两台笔记本,其中一台主机,一台节点。(条件限制,我只有两台)
需要提前下载好的文件:
VMware-workstation-full-14.1.2-8497320.exe
ubuntu-18.04.1-desktop-amd64.iso
jdk-10.0.2_linux-x64_bin.tar.gz
hadoop-2.7.7.tar.gz
开始搭建:
Step 1 安装虚拟机
1. 分别在两台主机上安装VMware和ubuntu虚拟机。这两项安装过程就不多说了,网上教程一大堆。
注1:为了防止后续配置会有不可逆转的错误,安装完虚拟机请先克隆一个以防万一)
注2:在安装的过程重会让你创建用户,如果你以后不想再创建专门为hadoop集群的用户,请你保证在两台主机上的虚拟机创建的用户名一致!
2. 启动两台虚拟机,分别对主机名进行重命名。
ytt@ubuntu:~$ sudo vim etc/hostname修改后重启,
![]()
![]()
Step 2 现在让两台虚拟机之间能ping通
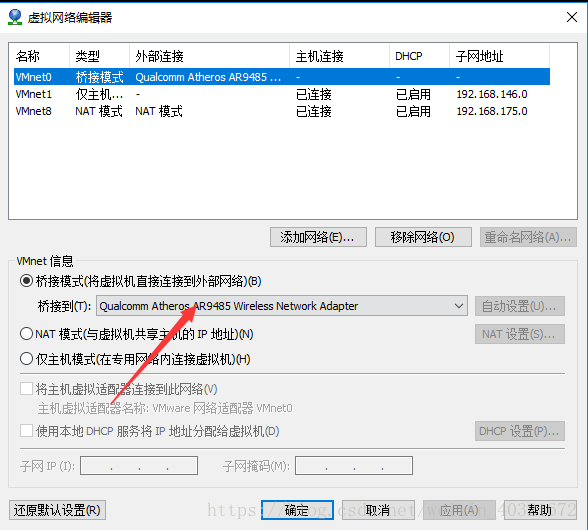
1. 因为不同主机上的两台虚拟机要互通,那么虚拟机网络配置要为桥接模式且IP地址设置为静态,具体见这篇文章https://blog.csdn.net/tiramisu_L/article/details/80557772
注:图片红箭头一定要按自己本机情况选择,要是选自动的话你会后悔的,终于ping通了然后莫名奇妙的吃个饭的时间就连不上了。
2.因为要以主机名的形式ping,故依次在两台虚拟机命令行输入sudo vim /etc/hosts ,修改后内容如下图所示:

3.ping通的效果图:

Step 3 配置免密登陆
先各自配:
1.安装SSH
sudo apt install ssh
2.生成公钥、私钥
ssh-keygen -t rsa -P '' 此处有回车,直接过就行,下一步Overwrite 输入y
3.把id_rsa.pub追加到授权的key里面去
cd .ssh
cat id_rsa.pub >> authorized_keys
chmod 600 authorized_keys
5.测试是否可以用ssh无密码登录本地localhost
ssh localhost
exit
现在master要配置对子节点slave进行免密登陆,此步只用在子节点上执行:
cd .ssh
scp ytt@master:~/.ssh/id_rsa.pub ./master_rsa.pub
cat master_rsa.pub >> authorized_keys
执行完后,回到主节点master,输入ssh slave也可免密登陆了。
Step 4 安装jdk和hadoop
1. jdk安装
由于准备将JDK安装至/usr/lib/jvm下,所以先到/usr/lib/目录下建立jvm文件夹
cd /usr/lib/
sudo mkdir jvm
解压:
sudo tar zxvf /home/ytt/java/jdk-10.0.2_linux-x64_bin.tar.gz -C /usr/lib/jvm
配置环境变量:
nano ~/.bashrc
在第一行前面增加:
export JAVA_HOME=/usr/lib/jvm/jdk-10.0.2
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=.:$CLASSPATH:$JAVA_HOME/lib:$JRE_HOME/lib
export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
立即生效:
source ~/.bashrc
2. hadoop安装
我们选择将 Hadoop 安装至/usr/local/
sudo tar -zxvf /home/ytt/java/hadoop-2.7.7.tar.gz -C /usr/local
cd /usr/local/
sudo mv ./hadoop-2.7.7/ ./hadoop # 将文件夹名改为hadoop
sudo chown -R ytt ./hadoop # 修改文件权限
配置环境变量:
nano ~/.bashrc
打开界面后,在之前配置的JAVA_HOME后面输入:
export HADOOP_INSTALL=/usr/local/hadoop
export PATH=$PATH:$HADOOP_INSTALL/bin
export PATH=$PATH:$HADOOP_INSTALL/sbin
export HADOOP_MAPRED_HOME=$HADOOP_INSTALL
export HADOOP_COMMON_HOME=$HADOOP_INSTALL
export HADOOP_HDFS_HOME=$HADOOP_INSTALL
export YARN_HOME=$HADOOP_INSTALL
立即生效:
source ~/.bashrc
验证是否成功,用两个命令:java -version、hadoop version
Step4这一大步在两个虚拟机都同样的配好。
Step 5 Hadoop的环境配置(这一大步只在master上配置)
cd 到/usr/local/hadoop/etc/hadoop文件夹中,有5个配置文件:slaves,core-site.xml,hdfs-site.xml,mapred-site.xml,yarn-site.xml.我们来一个一个严格按以下配。
1. 执行sudo vim slaves,在localhost后一行添加两台虚拟机的主机名:
master
slave
2.core-site.xml
3.hdfs-site.xml
4.配置mapre-site.xml
从模板文件复制一个xml,执行命令:mv mapred-site.xml.template mapred-site.xml
执行命令:sudo vim mapred-site.xml
5.yarn-site.xml
这些都完事之后,格式化namenode,只格式化一次。
hadoop namenode -format
注:格式化多次之后datanode又会启动不起来了,这时又要按照这个https://blog.csdn.net/u012500868/article/details/78164572配,这个需要重启,关机重启一次挺麻烦的。
主节点的hadoop环境我们配完了,那么子节点呢?我们依然在主节点上配置子节点的环境,直接复制过去就可以。
sudo /usr/local/
scp -r hadoop ytt@slave:/usr/local/
Step 6 启动集群
在主节点master进入到/usr/local/hadoop/sbin下,执行start-all.sh,然后输入jps,看见:
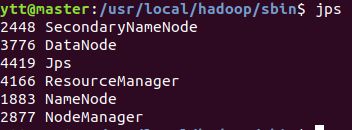
然后去子节点输入jps查看,我们看见:

必须是这样,不然别往下进行了,排错吧。
Step 7 第一个测试
1.向hadoop集群提交第一MapReduce任务(wordcount)
在主节点master上,进入hadoop目录(/usr/local/hadoop),依次执行:
bin/hdfs dfs -mkdir -p /data/input
touch my_wordcount.txt
vim my_wordcount.txt (随便输几个词)
hdfs dfs -put my_wordcount.txt /data/input
查看结果:hdfs dfs -ls /data/input
2.向Hadoop提交单词统计任务,命令如下:
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.7.jar wordcount /data/input/my_wordcount.txt /data/output/my_wordcount
查看结果:

至此,大功告成。