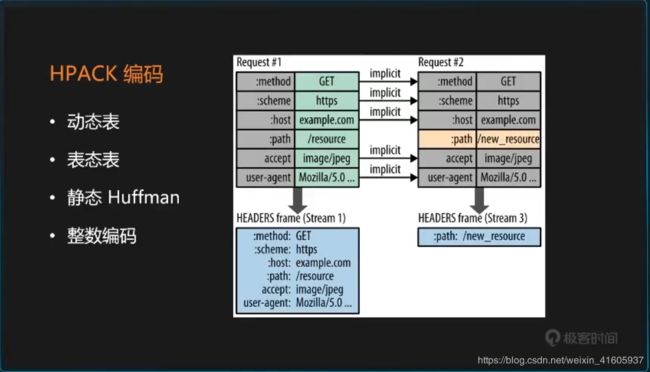
高级程序员学习——计算机网络
1 什么要TCP的三次握手机制?为什么需要三次握手?
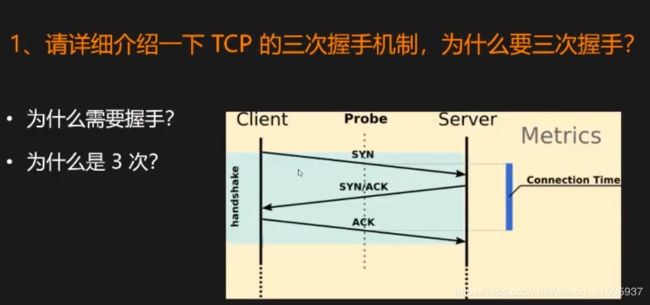
三次握手的最主要目的是保证连接是双工的,可靠更多的是通过重传机制来保证的。我们常常听到TCP三次握手,都知道TCP是面向连接的、可靠的协议,而UDP是无连接的、不可靠的。
- TCP 可靠性: 接收方收到的数据是完整, 有序, 无差错的。
- UDP 不可靠性: 接收方接收到的数据可能存在部分丢失, 顺序也不一定能保证。
TCP和UDP的区别?
TCP,Transmission Control Protocol 的缩写,即传输控制协议。
- 面向连接,即必须在双方建立可靠连接之后,才会收发数据
- 信息包头 20 个字节
- 建立可靠连接需要经过3次握手
- 断开连接需要经过4次挥手
- 需要维护连接状态
- 报文头里面的确认序号、累计确认及超时重传机制能保证不丢包、不重复、按序到达拥有流量控制及拥塞控制的机制
UDP,User Data Protocol 的缩写,即用户数据报协议。
- 不建立可靠连接,无需维护连接状态
- 信息包头 8 个字节
- 接收端,UDP 把消息段放在队列中,应用程序从队列读消息.
- 不受拥挤控制算法的调节
- 传送数据的速度受应用软件生成数据的速率、传输带宽、源端和终端主机性能的限制
- 面向数据报,不保证接收端一定能收到
应用场景选择
- 对实时性要求高和高速传输的场合下使用UDP;在可靠性要求低,追求效率的情况下使用UDP;
- 需要传输大量数据且对可靠性要求高的情况下使用TCP
为何要四次分手呢?
TCP协议是一种面向连接的、可靠的、基于字节流的运输层通信协议。TCP是全双工模式,当A主机关闭是的如果B中没有关闭连接的,B还是能够接受A发送的消息,但是A中已经关闭了,那么就会占用的相关的资源。
2 简单介绍的http的协议的缓存处理流程 ?
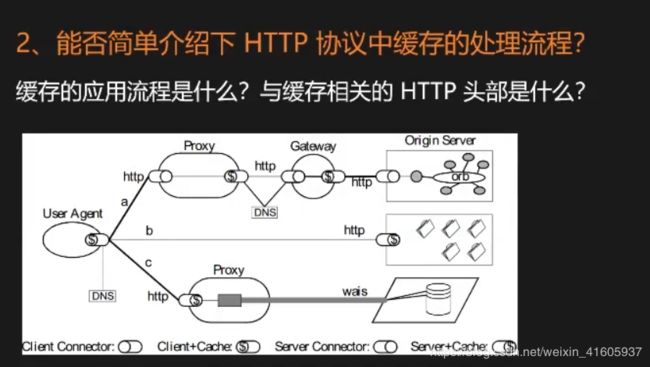


缓存的分类:缓存分为服务端侧(server side,比如 Nginx、Apache)和客户端侧(client side,比如 web browser)。
服务端缓存又分为 代理服务器缓存 和 反向代理服务器缓存(也叫网关缓存,比如 Nginx反向代理、Squid等),其实广泛使用的 CDN 也是一种服务端缓存,目的都是让用户的请求走”捷径“,并且都是缓存图片、文件等静态资源。
客户端侧缓存一般指的是浏览器缓存,目的就是加速各种静态资源的访问,想想现在的大型网站,随便一个页面都是一两百个请求,每天 pv 都是亿级别,如果没有缓存,用户体验会急剧下降、同时服务器压力和网络带宽都面临严重的考验。

浏览器缓存机制详解:浏览器缓存控制机制有两种:HTML Meta标签 vs. HTTP头信息
浏览器缓存机制,其实主要就是HTTP协议定义的缓存机制(如: Expires; Cache-control等)。但是也有非HTTP协议定义的缓存机制,如使用HTML Meta 标签,Web开发者可以在HTML页面的
节点中加入标签,代码如下:上述代码的作用是告诉浏览器当前页面不被缓存,每次访问都需要去服务器拉取。使用上很简单,但只有部分浏览器可以支持,而且所有缓存代理服务器都不支持,因为代理不解析HTML内容本身。而广泛应用的还是 HTTP头信息 来控制缓存,下面我主要介绍HTTP协议定义的缓存机制。
HTTP头信息控制缓存
浏览器第一次请求流程图
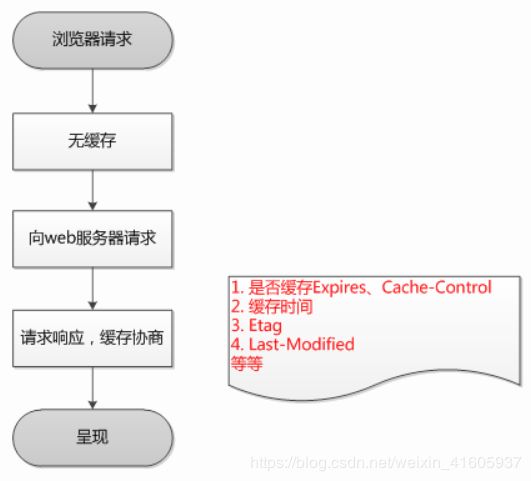
浏览器再次请求时:
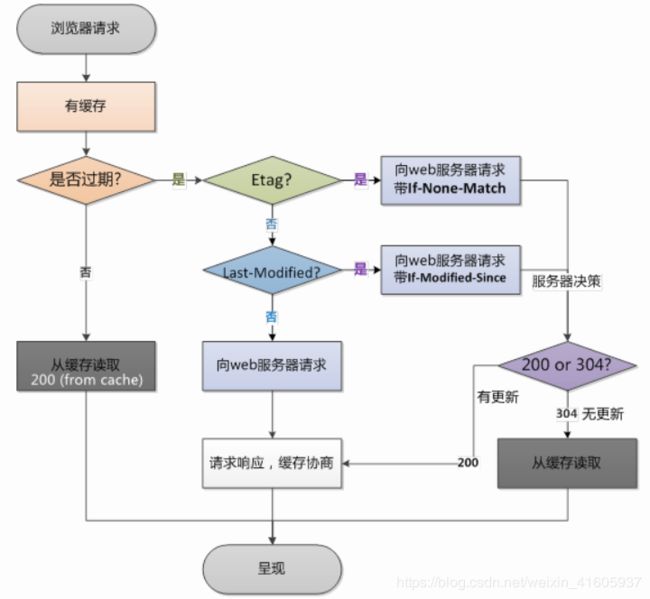
1.Cache-Control
请求/响应头,缓存控制字段,可以说是控制http缓存的最高指令,要不要缓存也是它说了算。
它有以下常用值
1.1 no-store:所有内容都不缓存
1.2 no-cache:缓存,但是浏览器使用缓存前,都会请求服务器判断缓存资源是否是最新,它是个比较高贵的存在,因为它只用不过期的缓存。
1.3 max-age=x(单位秒) 请求缓存后的X秒不再发起请求,属于http1.1属性,与下方Expires(http1.0属性)类似,但优先级要比Expires高。
1.4 s-maxage=x(单位秒) 代理服务器请求源站缓存后的X秒不再发起请求,只对CDN缓存有效(这个在后面会细说)
1.5 public 客户端和代理服务器(CDN)都可缓存
1.6 private 只有客户端可以缓存
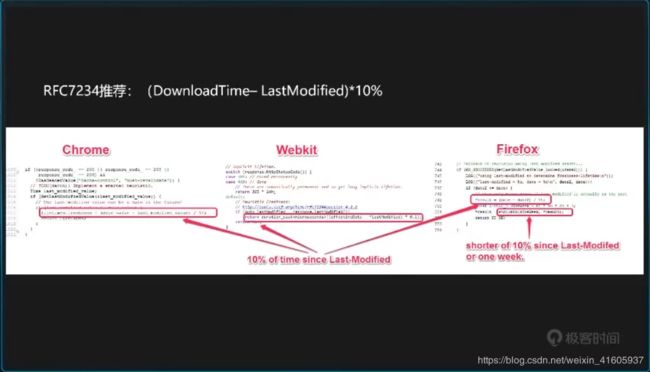
2.Expires
响应头,代表资源过期时间,由服务器返回提供,GMT格式日期,是http1.0的属性,在与max-age(http1.1)共存的情况下,优先级要低。
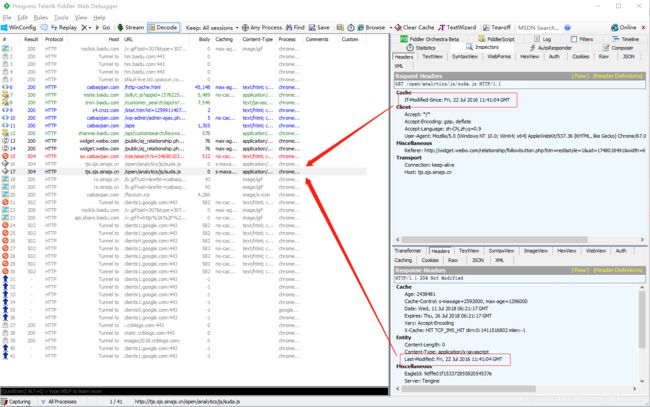
3.Last-Modified
响应头,资源最新修改时间,由服务器告诉浏览器。
4.if-Modified-Since
请求头,资源最新修改时间,由浏览器告诉服务器(其实就是上次服务器给的Last-Modified,请求又还给服务器对比),和Last-Modified是一对,它两会进行对比。
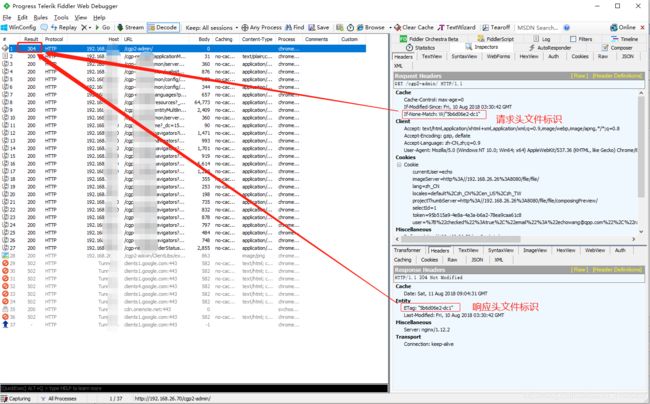
5.Etag
响应头,资源标识,由服务器告诉浏览器。
6.if-None-Match
请求头,缓存资源标识,由浏览器告诉服务器(其实就是上次服务器给的Etag),和Etag是一对,它两会进行对比。




什么是CDN: 了解CDN缓存,先得知道什么是CDN,CDN是构建在网络之上的内容分发网络,依靠部署在各地的边缘服务器,通过中心平台的负载均衡、内容分发、调度等功能模块,使用户就近获取所需内容,降低网络拥塞,提高用户访问响应速度和命中率。CDN的关键技术主要有内容存储和分发技术(较为官方的说明)。

3在URl 中输入后 计算网络的的层面的是怎么样的一种流程

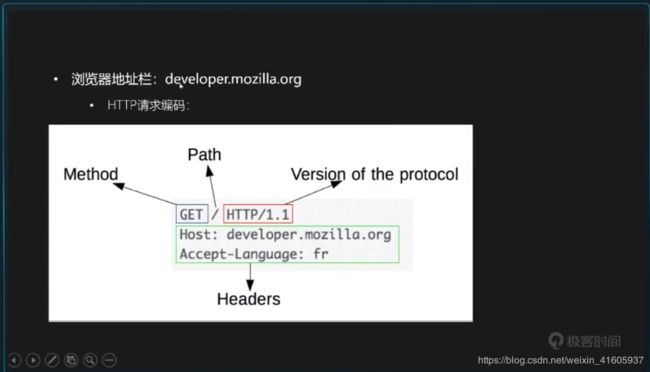
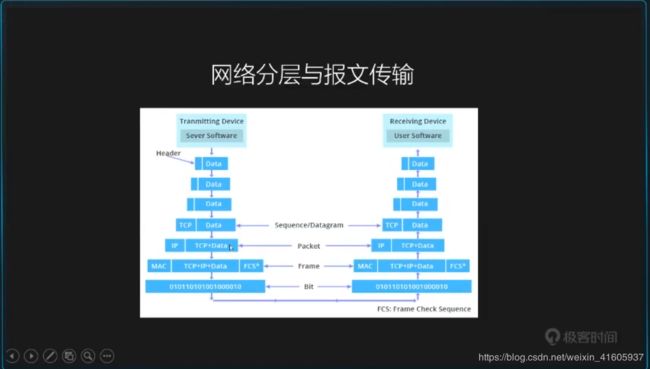
输入url发生的事情:就从计算机网络几个层讲了一下
- 1. 浏览器首先判断使用的是什么协议(ftp/http),然后对URL进行安全检查。最后浏览器查看缓存,如果请求的对象在缓存中并且是比较新的。那么直接跳到步骤9
- 2. 浏览器请求OS返回服务器的IP地址
- 3. 操作系统启动DNS查询并向浏览器返回服务器的IP地址
- 4. 浏览器使用TCP协议建立与服务器的连接
- 5. 浏览器通过TCP连接发出HTTP请求
- 6. 浏览器收到HTTP响应。这时候浏览器可能关闭TCP连接,或者继续使用它来请求其他数据。
- 7. 浏览器检查响应报文的状态码。并根据不同的状态码做不同的处理。
- 8. 如果响应是可缓存的,那么就存储在缓存区。
- 9. 浏览器解码响应报文(比如文件是压缩的就需要解压缩)
- 10. 浏览器渲染响应的数据。
总结:分为两个阶段: 1寻找的服务器的IP 地址 2 与服务的连接 通信 数据的传输 3 资源的缓存 带第二次在一次访问的情况。
4 什么是长连接?什么是短连接?http长连接有哪些有优点?缺点的是什么? 为什么会对头阻塞的情况?

前提:
- HTTP/1.0默认使用短连接,HTTP/1.1开始默认使用长连接;
- HTTP协议的长连接和短连接,实质就是TCP协议的长连接和短连接;
- TCP协议建立连接需要3次握手,断开连接需要4次握手,这个过程会消耗网络资源和时间;
定义:
- 长连接:在一个TCP连接上可以发送多个数据包,但是如果没有数据包发送时,也要双方发检测包以维持这个长连接;三次握手后连接,不断开连接,保持客户端和服务端通信,直到服务器超时自动断开连接,或者客户端主动断开连接。
- 短连接:当双方需要数据交互的时候,就建立一个TCP连接,本次交互完之后就断开这个连接;三次握手后建立连接,发送数据包并得到服务器返回的结果后,通过客户端和服务器的四次握手后断开连接。
优缺点:
- 长连接可以省去较多建立连接和断开连接的操作,所以比较节省资源和时间,但是长连接如果一直存在的话,需要很多探测包的发送来维持这个连接,这对服务器将是很大的负担;
- 相对而言,短连接不需要服务器承担太大负担,只要存在的连接就是有用的连接,但如果客户端请求频繁,就会在TCP的建立连接和断开连接上浪费较大的资源和时间。
什么时候用长连接,短连接?
- 长连接多用于操作频繁,点对点的通讯,而且连接数不能太多情况,。每个TCP连接都需要三步握手,这需要时间,如果每个操作都是先连接,再操作的话那么处理速度会降低很多,所以每个操作完后都不断开,次处理时直接发送数据包就OK了,不用建立TCP连接。例如:数据库的连接用长连接, 如果用短连接频繁的通信会造成socket错误,而且频繁的socket 创建也是对资源的浪费。
- 而像WEB网站的http服务一般都用短链接,因为长连接对于服务端来说会耗费一定的资源,而像WEB网站这么频繁的成千上万甚至上亿客户端的连接用短连接会更省一些资源,如果用长连接,而且同时有成千上万的用户,如果每个用户都占用一个连接的话,那可想而知吧。所以并发量大,但每个用户无需频繁操作情况下需用短连好。
5介绍close_wait的状态的原因?
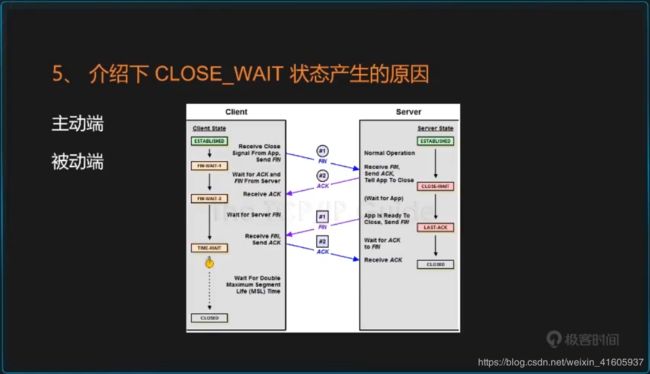
常用的三个状态是:ESTABLISHED 表示正在通信,TIME_WAIT 表示主动关闭,CLOSE_WAIT 表示被动关闭。
因为linux分配给一个用户的文件句柄是有限的,而TIME_WAIT和CLOSE_WAIT两种状态如果一直被保持,那么意味着对应数目的通道就一直被占着,而且是“占着茅坑不使劲”,一旦达到句柄数上限,新的请求就无法被处理了,接着就是大量Too Many Open Files异常,tomcat崩溃。。。
一.服务器保持了大量TIME_WAIT状态
这种情况比较常见,一些爬虫服务器或者WEB服务器(如果网管在安装的时候没有做内核参数优化的话)上经常会遇到这个问题,这个问题是怎么产生的呢?从 上面的示意图可以看得出来,TIME_WAIT是主动关闭连接的一方保持的状态,对于爬虫服务器来说他本身就是“客户端”,在完成一个爬取任务之后,他就会发起主动关闭连接,从而进入TIME_WAIT的状态,然后在保持这个状态2MSL(max segment lifetime)时间之后,彻底关闭回收资源。为什么要这么做?明明就已经主动关闭连接了为啥还要保持资源一段时间呢?这个是TCP/IP的设计者规定 的,主要出于以下两个方面的考虑:
1.防止上一次连接中的包,迷路后重新出现,影响新连接(经过2MSL,上一次连接中所有的重复包都会消失)
2.可靠的关闭TCP连接。在主动关闭方发送的最后一个 ack(fin) ,有可能丢失,这时被动方会重新发fin, 如果这时主动方处于 CLOSED 状态 ,就会响应 rst 而不是 ack。所以主动方要处于 TIME_WAIT 状态,而不能是 CLOSED 。另外这么设计TIME_WAIT 会定时的回收资源,并不会占用很大资源的,除非短时间内接受大量请求或者受到攻击。
值得一说的是,对于基于TCP的HTTP协议,关闭TCP连接的是Server端,这样,Server端会进入TIME_WAIT状态,可想而知,对于访 问量大的Web Server,会存在大量的TIME_WAIT状态,假如server一秒钟接收1000个请求,那么就会积压 240*1000=24000个 TIME_WAIT的记录,维护这些状态给Server带来负担。当然现代操作系统都会用快速的查找算法来管理这些 TIME_WAIT,所以对于新的 TCP连接请求,判断是否hit中一个TIME_WAIT不会太费时间,但是有这么多状态要维护总是不好。
二.服务器保持了大量CLOSE_WAIT状态
TIME_WAIT状态可以通过优化服务器参数得到解决,因为发生TIME_WAIT的情况是服务器自己可控的,要么就是对方连接的异常,要么就是自己没有迅速回收资源,总之不是由于自己程序错误导致的。但是CLOSE_WAIT就不一样了,从上面的图可以看出来,如果一直保持在CLOSE_WAIT状态,那么只有一种情况,就是在对方关闭连接之后服务器程序自己没有进一步发出ack信号。换句话说,就是在对方连接关闭之后,程序里没有检测到,或者程序压根就忘记了这个时候需要关闭连接,于是这个资源就一直被程序占着。个人觉得这种情况,通过服务器内核参数也没办法解决,服务器对于程序抢占的资源没有主动回收的权利,除非终止程序运行。
在那边日志里头我举了个场景,来说明CLOSE_WAIT和TIME_WAIT的区别,这里重新描述一下:
服务器A是一台爬虫服务器,它使用简单的HttpClient去请求资源服务器B上面的apache获取文件资源,正常情况下,如果请求成功,那么在抓取完 资源后,服务器A会主动发出关闭连接的请求,这个时候就是主动关闭连接,服务器A的连接状态我们可以看到是TIME_WAIT。如果一旦发生异常呢?假设 请求的资源服务器B上并不存在,那么这个时候就会由服务器B发出关闭连接的请求,服务器A就是被动的关闭了连接,如果服务器A被动关闭连接之后程序员忘了 让HttpClient释放连接,那就会造成CLOSE_WAIT的状态了。所以如果将大量CLOSE_WAIT的解决办法总结为一句话那就是:问题出在服务器程序里头啊。
6 多播是怎么实现的?

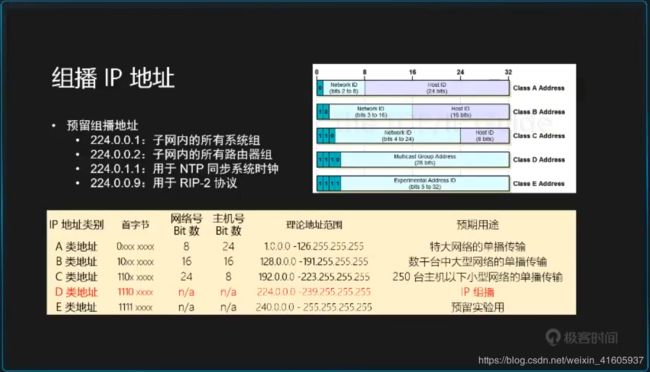
1、组播是基于路由器之上实现的,要想网络内支持组播,需要有能够管理组播组的路由器或是三层交换机(带部分路由功能的交换机)。通常在我们的网络中,都会支持组播,即我们的程序可以使用组播技术,视频会议就使用这个技术。
2、IP网络的多播一般通过多播IP地址来实现。多播IP地址就是D类IP地址,即224.0.0.0至239.255.255.255之间的IP地址。通常选择230之后的地址,使用UDP协议,把每个客户端(收端和发端)的socket都加入到这个地址上,之后客户端往这个地址上发送一个消息后,在这个组里的其他客户端都可以监听收到这个消息。
3、在java中,java.net.MulticastSocket具有组播的功能,它是DatagramSocket的子类。具体程序如下:
4、广播功能:
使用255.255.255.255(或者是192.168.10.255,具体ip地址上设置第四个参数为255是本网段的广播地址)的IP地址,所有的客户端都监听这个地址,发这个地址上发送消息,其他的客户端都会接收到。
java中使用java.net.DatagramSocket来完成监听和发送,发送信息前,要开启广播,即调用socket的setbroadcast(true)。
7服务器的最大连接数的多少?

linux下怎么实现高并发?
linux下高并发的优化的操作?
8 TCP和UDP的区别?
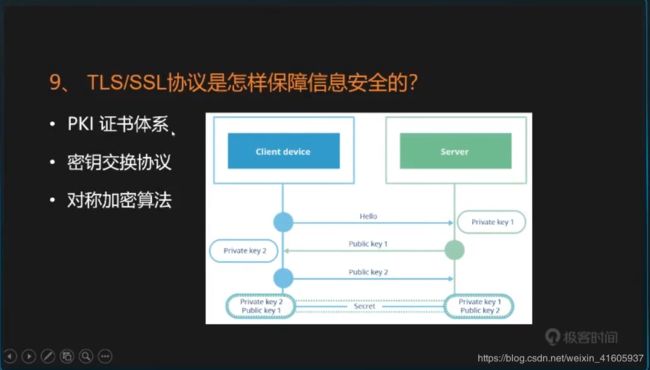
9TLS/SSL是怎么实现的信息保障安全?
10Http2.0的有哪些优点?