用于Java开发机器学习和深度学习的Vector API(翻译)
本文介绍了用于Java开发机器学习和深度学习的Vector API
英语原文链接 https://software.intel.com/en-us/articles/vector-api-developer-program-for-java
Vector API教程
- 介绍
- 什么是SIMD?
- 什么是Vector API?
- Vector 接口
- Vector Type
- Vector 运算
- 机器学习中的性能提升
- 基本线性代数子程序(BLAS)
- 图像处理过滤
- 编写Vector代码
- 在Java *中使用Vector API
- 简单的矢量循环
- 教程:编写own-vector算法
- 教程:所有关于Vector API的知识
- 入门
- 构筑Vector API
- 将JDK8二进制文件设置为JAVA_HOME
- 下载并编译Panama源码
- 使用Panama JDK构建自己的应用程序
- 运行你的应用程序
- IDE配置
- 配置IntelliJ以进行OpenJDK Panama开发
- Vector 范例
- BLAS机器学习
- BLAS-I
- BLAS-II(DSPR)
- BLAS-III(DSYR2K)
- BLASS-III(DGEMM)
- 金融服务(FSI)算法
- GetOptionPrice
- BinomialOptions
介绍
如今,大数据应用程序,分布式深度学习和人工智能解决方案可以直接在现有的Apache Spark *或Apache Hadoop *集群之上运行,并可以从有效的横向扩展中受益。为了在这些应用程序中获得理想的数据并行性,Open JDK Project Panama提供了Vector API。用于Java *软件的Vector API开发人员计划 提供了广泛的方法,可以丰富Java开发人员的机器学习和深度学习体验。
视频地址:https://www.youtube.com/embed/X49ucwtwuU0?feature=oembed&enablejsapi=1
本文向Java开发人员介绍Vector API,说明了如何在Java程序中开始使用API,并提供了矢量算法的示例。提供了有关如何构建矢量API以及如何使用它来构建Java应用程序的分步详细信息。此外,我们提供了有关如何在Java中为自己的算法实现Vector代码(后文翻译为矢量或向量)以提高性能的详细教程。
什么是SIMD?
单指令多数据(SIMD)允许在多个数据点上同时执行相同的操作,这得益于应用程序中数据级别的并行性。现代CPU具有高级SIMD操作支持,例如提供SIMD(指令)加速功能的AVX2,AVX3。
大数据应用程序(例如Apache Flink,Apache Spark机器学习库和Intel Big DL,数据分析和深度学习培训工作负载等)运行高度数据并行的算法。Java中的强大的SIMD支持将为扩展其中一些领域提供途径。
什么是Vector API?
用于Java *软件的Vector API开发人员项目使使用Java编写计算密集型应用程序,机器学习和人工智能算法,在没有Java本机接口(JNI)性能开销或对不可移植的本机代码的进一步维护需求的情况下,成为可能。API引入了一组用于对分大小的vector-types进行数据并行操作的方法,以便直接在Java中进行编程,而无需任何有关底层CPU的知识。JVM JIT编译器将这些低级API进一步有效地映射到现代CPU上的SIMD指令,以实现所需的性能加速;否则,将使用默认的VM实现将Java字节码映射为硬件指令。
Vector 接口
Vector API接口如下所示:
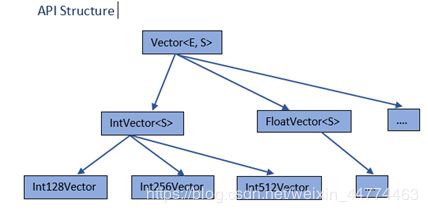
Vector Type
Vector Type(Vector
1 Element types: Byte, Short, Integer, Long, Float, and Double
2 Shape types (bit-size): 128, 256, and 512
选择矢量形状以将它们紧密映射到CPU平台上可用的最大SIMD寄存器上。
Vector 运算
所有这些Vector类型都可以使用基本的Vector-Vector功能。典型的算术和三角函数的矢量运算均以掩码格式提供。mask用于if-else类型的条件操作。
示例部分展示了如何在程序中使用 Vector mask。
01 public abstract class DoubleVector>> implements Vector {
02 Vector add (Vector v2);
03 Vector add (Vector o, Mask m);
04 Vector mul (Vector v2);
05 Vector mul (Vector o, Mask m);
06 ….
07 Vector sin ();
08 Vector sin (Mask m);
09 Vector sqrt (),
10 …
11}
Vector API还提供了金融服务行业(FSI)和机器学习应用程序中经常需要的更高级的Vector操作。
01public abstract class IntVector>> implements Vector {
02int sumAll ();
03 void intoArray(int[] a, int ix);
04 void intoArray (int [] is, int ix, Mask m);
05 Vector fromArray (int [] fs, int ix);
06 Vector blend (Vector o, Mask m);
07 Vector shuffle (Vector o, Shuffle s);
08 Vector fromByte (byte f);
09 …
10 }
机器学习中的性能提升
基本线性代数子程序(BLAS)
使用Vector实现BLAS I,II和III 例程可以将性能提高3-4倍。
BLAS I和II 例程通常在Apache Spark机器学习库中使用。这些适用于班轮模型和决策树的分类和回归,协同过滤和聚类以及降维问题。BLAS-III例程(例如GEMM)广泛用于解决人工智能中使用的深度学习和神经网络问题。

*Open JDK Project Panama source build 0918201709182017。Java Hotspot 64位服务器VM(混合模式)。操作系统版本:Cent OS 7.3 64位
英特尔®至强®铂金8180处理器(使用512字节和1024字节的浮点数据块)。
JVM选项:-XX:+ UnlockDiagnosticVMOptions -XX:-CheckIntrinsics -XX:TypeProfileLevel = 121 -XX:+ UseVectorApiIntrinsics
图像处理过滤
使用Vector API,棕褐色过滤的速度最高可提高6倍。

编写Vector代码
在Java *中使用Vector API
Vector接口是com.oracle.vector软件包的一部分,我们从Vector API开始,在程序中导入以下内容。根据向量类型,用户可以选择导入FloatVector,IntVector等。
1import jdk.incubator.vector.FloatVector;
2 import jdk.incubator.vector.Vector;
3 import jdk.incubator.vector.Shapes;
矢量类型(Vector
‘E’:元素类型,广泛支持int,float和double基本类型。
“ S”指定矢量的形状或按位大小。
在使用向量运算之前,程序员必须创建一个第一个向量实例来捕获元素类型和向量形状。使用该特定大小和形状的矢量可以被创建。
1 private static final FloatVector.FloatSpecies
species = (FloatVector.FloatSpecies ) Vector.speciesInstance (Float.class, Shapes.S_256_BIT);
2 IntVector.IntSpeciesispec = (IntVector.IntSpecies ) Vector.speciesInstance(Integer.class, Shapes.S_512_BIT);
从此以后,用户可以创建FloatVector
简单的矢量循环
在本节中,我们提供了矢量API编程的风格。Vector API白皮书<使用Java 编写自矢量算法以提高性能>中提供了有关如何编写矢量算法的详细技巧和窍门。BLAS和FSI例程的示例矢量代码示例可在后续章节中找到。
第一个示例展示两个数组的向量加法。程序使用诸如fromArray(),intoArray()之类的向量操作将向量加载/存储到数组中。
向量add()运算用于算术运算。
1 public static void AddArrays (float [] left, float [] right, float [] res, int i) {
2 FloatVector.FloatSpecies species = (FloatVector.FloatSpecies)
3 Vector.speciesInstance (Float.class, Shapes.S_256_BIT);
4 FloatVector l = species.fromArray (left, i);
5 FloatVector r = species.fromArray (right, i);
6 FloatVector lr = l.add(r);
7 lr.intoArray (res, i);
8}
通过使用species.length()查询向量大小来编写向量循环。考虑下面的标量循环,它将数组A和B相加并将结果存储到数组C中。
1 for (int i = 0; i < C.length; i++) {
2 C[i] = A[i] + B[i];
3 }
向量化循环如下所示:
01 public static void add (int [] C, int [] A, int [] B) {
02 IntVector.IntSpecies species =
03 (IntVector.IntSpecies) Vector.speciesInstance(Integer.class, Shapes.S_256_BIT);
04 int i;
05 for (i = 0; (i + species.length()) < C.length; i += species.length ()) {
06 IntVector av = species.fromArray (A, i);
07 IntVector bv = species.fromArray (B, i);
08 av.add(bv).intoArray(C, i);
09 }
10 for (; i < C.length; i++) { // Cleanup loop
11 C[i] = A[i] + B[i];
12 }
13 }
也可以以长度不可知的方式编写该程序,而与向量大小无关。随后的程序通过Shape设置矢量代码的参数。
01public class AddClass>> {
02 private final FloatVector.FloatSpecies spec;
03 AddClass (FloatVector.FloatSpecies v) {spec = v; }
04 //vector routine for add
05 void add (float [] A, float [] B, float [] C) {
06 int i=0;
07 for (; i+spec.length () av = spec.fromArray (A, i);
09 FloatVector bv = spec.fromArray (B, i);
10 av.add (bv).intoArray(C, i);
11 }
12 //clean up loop
13 for (;i 条件语句中的运算可以使用掩码以矢量形式编写。
标量例程如下,
1for (int i = 0; i < SIZE; i++) {
2 float res = b[i];
3 if (a[i] > 1.0) {
4 res = res * a[i];
5 }
6 c[i] = res;
7 }
使用mask的Vector例程如下。
01public void useMask (float [] a, float [] b, float [] c, int SIZE) {
02 FloatVector.FloatSpecies species = (FloatVector.FloatSpecies ) Vector.speciesInstance Float.class, Shapes.S_256_BIT);
03 FloatVector tv=species.broadcast (1.0f); int i = 0;
04 for (; i+ species.length() < SIZE; i+ = species.length()){
05 FloatVector rv = species.fromArray (b, i);
06 FloatVector av = species.fromArray (a, i);
07 Vector.Mask mask = av.greaterThan (tv);
08 rv.mul (av, mask).intoArray(c, i);
09 }
10 //后续处理
11}
教程:编写own-vector算法
这些示例应为您提供一些在Oracle Java *中进行矢量编程的准则和最佳实践,以帮助您成功地编写自己的计算密集型算法的矢量版本。
更多有关信息,请参见PDF附件。
教程:所有关于Vector API的知识
网址1 https://www.youtube.com/embed/jRyD1EIOOis?feature=oembed&enablejsapi=1
网址2 https://www.youtube.com/embed/videoseries?list=PLX8CzqL3ArzXJ2EGftrmz4SzS6NRr6p2n&enablejsapi=1
入门
构筑Vector API
本节假定用户熟悉基本的Linux实用程序。
将JDK8二进制文件设置为JAVA_HOME
Panama项目需要在系统上使用JDK8。可以从此位置下载JDK 。
#export JAVA_HOME = / pathto / jdk1.8-u91
#export PATH = $ JAVA_HOME / bin:$ PATH
下载并编译Panama源码
可以使用商业资源控制管理工具下载Project Panama的源码。
# hg clone http://hg.openjdk.java.net/panama/panama/
# source get_source.sh
# ./configure
# make all
使用Panama JDK构建自己的应用程序
我们需要将vector.jar文件从包含Panama源的父文件目录中复制到Java应用程序的位置。
01import jdk.incubator.vector.IntVector;
02import jdk.incubator.vector.Shapes;
03import jdk.incubator.vector.Vector;
04
05public class HelloVectorApi {
06 public static void main(String[] args) {
07 IntVector.IntSpecies species =
08 (IntVector.IntSpecies) Vector.speciesInstance(
09 Integer.class, Shapes.S_128_BIT);
10 int val = 1;
11 IntVector hello = species.broadcast(val);
12 if (hello.sumAll() == val * species.length()) {
13 System.out.println("Hello Vector API!");
14 }
15 }
16}
运行你的应用程序
/pathto/panama/build/linux-x86_64-normal-server-release/images/jdk/bin/java --add-modules=jdk.incubator.vector -XX:TypeProfileLevel=121 HelloVectorApi
IDE配置
配置IntelliJ以进行OpenJDK Panama开发
1)创建一个新项目。如果是刚安装IntelliJ或没有打开过项目,则在出现的窗口中点击“Create New Project”(您可以在下面的窗口中看到)。
否则,File > New > Project… 也有相同的效果。

2)在出现的“New Project”窗口中,确保选择左侧的Java。选择Panama编译作为Project SDK。
如果尚未将Panama build设置为Project SDK,请按右侧的“New…”按钮。否则,请转到步骤4。
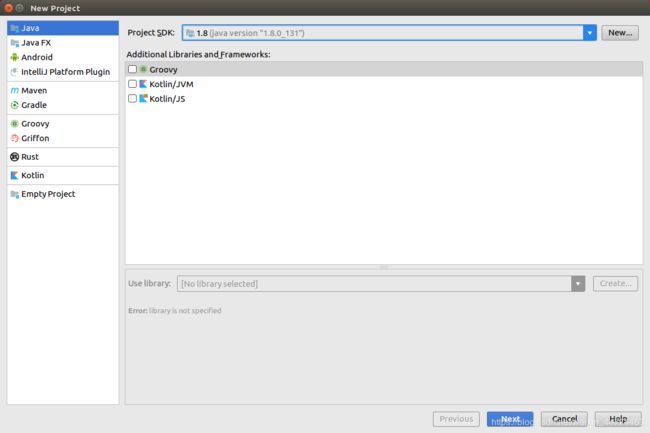
3)弹出的窗口叫做“Select Home Directory for JDK”。您要选择的路径是/ path / to / panama / build / linux-x86_64-normal-server-release / images / jdk。点击确定。
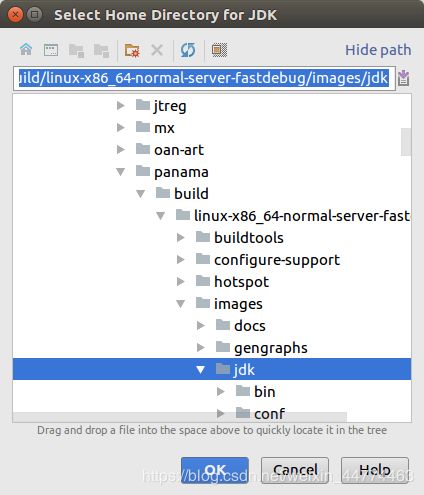
4)单击下一步。此时,您可以选择从模板创建项目。继续并选择“Command Line App”,然后再次单击下一步。

5)为您的项目命名和位置,然后单击“完成”。
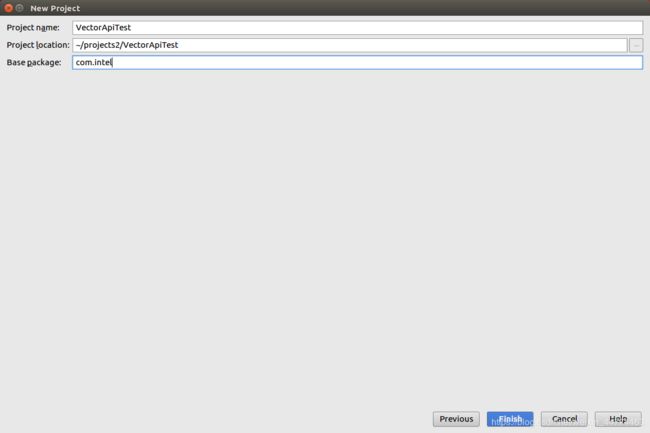
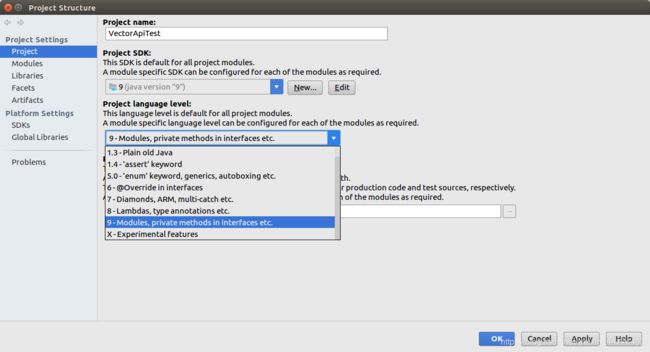
6)创建项目后,需要执行几个步骤才能成功使用Vector API。转到File > Project Structure…
7)确保在左窗格中选择了“项目”。将“Project language level:”更改为“9 - Modules, private methods in interfaces etc.”。最后,点击OK。
8)在显示目录结构的左窗格中,右键单击“ src”文件夹。导航到New > module-info.java
9)在此文件中,添加以下行“ requires jdk.incubator.vector;”。保存文件。
10)返回Main.java。添加使用API的所需代码。有关示例,请参见HelloVectorApi.java。
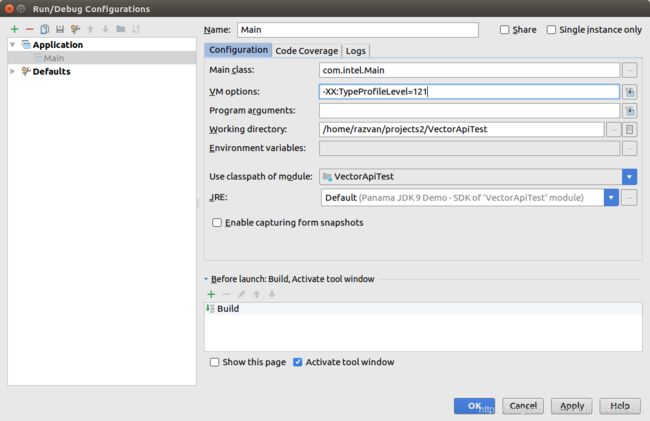
11)在运行应用程序之前,需要编辑运行配置。按下带有“play”按钮旁边的带有类名的按钮。您应该看到“Edit Configurations…”。点击。
12)在VM选项中,需要添加“ -XX:TypeProfileLevel = 121 -XX:+ UseVectorApiIntrinsics”。这两项在以后都可能成为可选的。如果您想开启/关闭将VectorApi转换为优化的x86内在函数的优化(出于稳定性考虑),您将需要添加:
“-XX:-UseVectorApiIntrinsics”。
13)按下“play”按钮以编译并运行该应用程序。在终端窗口的屏幕底部,您应该看到“ Hello Vector API!”或任何应用程序打印出的输出。
Vector 范例
BLAS机器学习
版权所有2017英特尔公司
如果满足以下条件,则允许以源代码和二进制形式进行重新分发和使用,无论是否经过修改,都可以:
1.重新分发源代码必须保留以上版权声明,此条件列表和以下免责声明。
2.以二进制形式重新分发必须在分发随附的文档和/或其他材料中复制以上版权声明,此条件列表以及以下免责声明。
3.未经事先特别书面许可,不得使用版权所有者的姓名或其贡献者的名字来认可或促销从本软件衍生的产品。
版权持有者和贡献者按“原样”提供此软件,不提供任何明示或暗示的担保,包括但不限于针对特定目的的适销性和适用性的暗示担保。在任何情况下,版权持有人或贡献者均不对任何直接,间接,偶发,特殊,专有或后果性的损害(包括但不限于,替代商品或服务的购买,使用,数据,或业务中断),无论基于合同,严格责任或侵权行为(包括疏忽或其他方式),无论是出于任何责任,无论是否出于使用本软件的目的,即使已经事先告知,也已作了规定。
BLAS-I
01import jdk.incubator.vector.DoubleVector;
02import jdk.incubator.vector.Vector;
03import jdk.incubator.vector.Shapes;
04import java.lang.Math;
05
06public class BLAS {
07
08
09
10 static void VecDaxpy(double[] a, int a_offset, double[] b, int b_offset, double alpha) {
11 DoubleVector.DoubleSpecies spec= (DoubleVector.DoubleSpecies) Vector.speciesInstance(Double.class, Shapes.S_512_BIT);
12 DoubleVector alphaVec = spec.broadcast(alpha);
13 int i = 0;
14 for (; (i + a_offset+ spec.length()) < a.length && (i + b_offset + spec.length()) < b.length; i += spec.length()) {
15 DoubleVector bv = spec.fromArray(b, i + b_offset);
16 DoubleVector av = spec.fromArray(a, i + a_offset);
17 bv.add(av.mul(alphaVec)).intoArray(b, i + b_offset);
18 }
19
20 for (; i+a_offset < a.length && i+b_offset spec= (FloatVector.FloatSpecies) Vector.speciesInstance(Float.class, Shapes.S_256_BIT);
25
26 int i = 0;
27 for (; (i + a_offset+spec.length()) < a.length && (i+b_offset+spec.length()) bv = spec.fromArray(b, i + b_offset);
30 FloatVector av = spec.fromArray(a, i + a_offset);
31 FloatVector alphaVec = spec.broadcast(alpha);
32 bv.add(av.mul(alphaVec)).intoArray(b, i + b_offset);
33 }
34
35 for (; i+a_offset < a.length && i+b_offset spec= (DoubleVector.DoubleSpecies) Vector.speciesInstance(Double.class, Shapes.S_512_BIT);
41
42 int i = 0; double sum = 0;
43 for (; (i + a_offset + spec.length()) < a.length && (i + b_offset+ spec.length()) < b.length; i += spec.length()) {
44 DoubleVector l = spec.fromArray(a, i + a_offset);
45 DoubleVector r = spec.fromArray(b, i + b_offset);
46 sum+=l.mul(r).sumAll();
47 }
48 for (; (i + a_offset < a.length) && (i + b_offset < b.length); i++) sum += a[i+a_offset] * b[i+b_offset]; //tail
49 }
50
51 static void VecDdotFloat(float[] a, int a_offset, float[] b, int b_offset) {
52 FloatVector.FloatSpecies spec= (FloatVector.FloatSpecies) Vector.speciesInstance(Float.class, Shapes.S_256_BIT);
53
54 int i = 0; float sum = 0;
55 for (; i+a_offset + spec.length() < a.length && i+b_offset+spec.length() l = spec.fromArray(a, i + a_offset);
57 FloatVector r = spec.fromArray(b, i + b_offset);
58 sum+=l.mul(r).sumAll();
59 }
60 for (; i+a_offset < a.length && i+b_offset BLAS-II(DSPR)
01
import jdk.incubator.vector.DoubleVector;
02
import jdk.incubator.vector.Vector;
03
import jdk.incubator.vector.Shapes;
04
05public class BLAS_II {
06
07 public static void VecDspr(String uplo, int n, double alpha, double[] x, int _x_offset, int incx, double[] ap, int _ap_offset) {
08 DoubleVector.DoubleSpecies spec= (DoubleVector.DoubleSpecies) Vector.speciesInstance(Double.class, Shapes.S_512_BIT);
09
10 double temp = 0.0;
11 int i = 0;
12 int ix = 0;
13 int j = 0;
14 int jx = 0;
15 int k = 0;
16 int kk = 0;
17 int kx = 0;
18 kk = 1;
19 if (uplo.equals("U")) {
20 // * Form A when upper triangle is stored in AP.
21 if (incx == 1) {
22 for (j=0; j tv = spec.broadcast(temp);
26 for (i=0, k=kk; i+spec.length()<=j && i + _x_offset + spec.length() < x.length && k + _ap_offset + spec.length() < ap.length; i+= spec.length(), k+=spec.length()) {
27 DoubleVector av = spec.fromArray(ap, k+_ap_offset);
28 DoubleVector xv = spec.fromArray(x, i+_x_offset);
29
av.add(xv.mul(tv)).intoArray(ap,k+_ap_offset);
30
}
31
for (; i<=j && i + _x_offset < x.length && k + _ap_offset tv=spec.broadcast(temp);
45
k = kk;
46
for (i=j; i+spec.length() av = spec.fromArray(ap, k+_ap_offset);
48
DoubleVector xv = spec.fromArray(x, i+_x_offset);
49
av.add(xv.mul(tv)).intoArray(ap,k+_ap_offset);
50
}
51
for (; i spec= (DoubleVector.DoubleSpecies) Vector.speciesInstance(Double.class, Shapes.S_512_BIT);
10
double temp = 0.0;
11
int i = 0;
12
int ix = 0;
13
int j = 0;
14
int jx = 0;
15
int kx = 0;
16
17
if (uplo.equals("U") && incx == 1) {
18
for (j=0; j tv = spec.broadcast(temp);
22
for (i=0; (i+spec.length())<=j && i+_x_offset+spec.length() xv = spec.fromArray(x, i+_x_offset);
24
DoubleVector av = spec.fromArray(a, i+j*lda+_a_offset);
25
av.add(xv.mul(tv)).intoArray(a,i+j*lda+_a_offset);
26
}
27
for (; i<=j && i+j*lda+_a_offset tv = spec.broadcast(temp);
38
for (i=j; (i+spec.length()) xv = spec.fromArray(x,i+_x_offset);
40
DoubleVector av = spec.fromArray(a,i+j*lda+_a_offset);
41
av.add(xv.mul(tv)).intoArray(a,i+j*lda+_a_offset);
42
}
43
for (; i BLAS-III(DSYR2K)
001
import jdk.incubator.vector.FloatVector;
002
import jdk.incubator.vector.DoubleVector;
003
import jdk.incubator.vector.Shapes;
004
import jdk.incubator.vector.Vector;
005
006
public class BLAS3DSYR2K {
007
008
009
public void VecDsyr2k(String uplo, String trans, int n, int k, double alpha, double[] a, int _a_offset, int lda, double[] b, int _b_offset, int ldb, double beta, double[] c, int _c_offset, int Ldc) {
010
DoubleVector.DoubleSpecies spec= (DoubleVector.DoubleSpecies) Vector.speciesInstance(Double.class, Shapes.S_512_BIT);
011
double temp1 = 0.0;
012
double temp2 = 0.0;
013
int i = 0;
014
int info = 0;
015
int j = 0;
016
int l = 0;
017
int nrowa = 0;
018
boolean upper = false;
019
if (trans.equals("N")) {
020
nrowa = n;
021
} else {
022
nrowa = k;
023
} // Close else.
024
DoubleVector zeroVec = spec.broadcast(0.0D);
025
DoubleVector betaVec = spec.broadcast(beta);
026
upper = uplo.equals("U");
027
if (alpha == 0.0) {
028
if (upper) {
029
if (beta == 0.0) {
030
for (j = 0; j < n; j++) {
031
i = 0;
032
for (; (i + spec.length()) < j; i += spec.length()) {
033
zeroVec.intoArray(c, i + j * Ldc + _c_offset);
034
}
035
for (; i < j; i++) {
036
c[i + j * Ldc + _c_offset] = 0.0;
037
}
038
}
039
} else {
040
for (j = 0; j < n; j++) {
041
i = 0;
042
for (; (i + spec.length()) < j; i += spec.length()) {
043
DoubleVector cV = spec.fromArray(c, i + j * Ldc + _c_offset);
044
cV.mul(betaVec).intoArray(c, i + j * Ldc + _c_offset);
045
}
046
for (; i < j; i++) {
047
c[i + j * Ldc + _c_offset] = beta * c[i + j * Ldc + _c_offset];
048
}
049
}
050
}
051
}
052
053
//lower
054
else {
055
if (beta == 0.0) {
056
for (j = 0; j < n; j++) {
057
i = j;
058
for (; i + spec.length() < n; i += spec.length()) {
059
zeroVec.intoArray(c, i + j * Ldc + _c_offset);
060
}
061
for (; i < n; i++) {
062
c[i + j * Ldc + _c_offset] = 0.0;
063
}
064
}
065
} else {
066
for (j = 0; j < n; j++) {
067
i = j;
068
for (; i + spec.length() < n; i += spec.length()) {
069
DoubleVector cV = spec.fromArray(c, i + j * Ldc + _c_offset);
070
cV.mul(betaVec).intoArray(c, i + j * Ldc + _c_offset);
071
}
072
}
073
for (; i < n; i++) {
074
c[i + j * Ldc + _c_offset] = beta * c[i + j * Ldc + _c_offset];
075
}
076
}
077
}
078
}
079
//start operations
080
if (trans.equals("N")) {
081
// * Form C := alpha*A*B**T + alpha*B*A**T + C.
082
if (upper) {
083
for (j = 0; j < n; j++) {
084
if (beta == 0.0) {
085
i = 0;
086
for (; i + spec.length() < j; i += spec.length()) {
087
zeroVec.intoArray(c, i + j * Ldc + _c_offset);
088
}
089
for (; i < j; i++) {
090
c[i + j * Ldc + _c_offset] = 0.0;
091
}
092
093
} else if (beta != 1.0) {
094
i = 0;
095
for (; i + spec.length() < j; i += spec.length()) {
096
DoubleVector cV = spec.fromArray(c, i + j * Ldc + _c_offset);
097
cV.mul(betaVec).intoArray(c, i + j * Ldc + _c_offset);
098
}
099
for (; i < j; i++) {
100
c[i + j * Ldc + _c_offset] = beta * c[i + j * Ldc + _c_offset];
101
}
102
}
103
104
for (l = 0; l < k; l++) {
105
if ((a[j + l * lda + _a_offset] != 0.0) || (b[j + l * ldb + _b_offset] != 0.0)) {
106
temp1 = alpha * b[j + l * ldb + _b_offset]; DoubleVector tv1 = spec.broadcast(temp1);
107
temp2 = alpha * a[j + l * lda + _a_offset]; DoubleVector tv2 = spec.broadcast(temp2);
108
i = 0;
109
for (; (i + spec.length()) < j; i += spec.length()) {
110
DoubleVector cV = spec.fromArray(c, i + j * Ldc + _c_offset);
111
DoubleVector bV = spec.fromArray(b, i + l * ldb + _b_offset);
112
DoubleVector aV = spec.fromArray(a, i + l * lda + _a_offset);
113
cV.add(aV.mul(tv1)).add(bV.mul(tv2)).intoArray(c, i + j * Ldc + _c_offset);
114
}
115
for (; i < j; i++) {
116
c[i + j * Ldc + _c_offset] = c[i + j * Ldc + _c_offset] + a[i + l * lda + _a_offset] * temp1 + b[i + l * ldb + _b_offset] * temp2;
117
}
118
}
119
}
120
}
121
} else {
122
123
for (j = 0; j < n; j++) {
124
if (beta == 0.0) {
125
i = j;
126
for (; (i + spec.length()) < n; i += spec.length()) {
127
zeroVec.intoArray(c, i + j * Ldc + _c_offset);
128
}
129
for (; i < n; i++) {
130
c[i + j * Ldc + _c_offset] = 0.0;
131
}
132
} else if (beta != 1.0) {
133
i = j;
134
for (; (i + spec.length()) < n; i += spec.length()) {
135
DoubleVector cV = spec.fromArray(c, i + j * Ldc + _c_offset);
136
cV.mul(betaVec).intoArray(c, i + j * Ldc + _c_offset);
137
}
138
for (; i < n; i++) {
139
c[i + j * Ldc + _c_offset] = beta * c[i + j * Ldc + _c_offset];
140
}
141
}
142
for (l = 0; l < k; l++) {
143
if ((a[j + l * lda + _a_offset] != 0.0) || (b[j + l * ldb + _b_offset] != 0.0)) {
144
temp1 = alpha * b[j + l * ldb + _b_offset]; DoubleVector tv1 = spec.broadcast(temp1);
145
temp2 = alpha * a[j + l * lda + _a_offset]; DoubleVector tv2 = spec.broadcast(temp2);
146
i = j;
147
for (; i + spec.length() < n; i += spec.length()) {
148
DoubleVector cV = spec.fromArray(c, i + j * Ldc + _c_offset);
149
DoubleVector aV = spec.fromArray(a, i + l * lda + _a_offset);
150
DoubleVector bV = spec.fromArray(b, i + l * ldb + _b_offset);
151
cV.add(aV.mul(tv1)).add(bV.mul(tv2)).intoArray(c, i + j * Ldc + _c_offset);
152
}
153
for (; i < n; i++) {
154
c[i + j * Ldc + _c_offset] = c[i + j * Ldc + _c_offset] + a[i + l * lda + _a_offset] * temp1 + b[i + l * ldb + _b_offset] * temp2;
155
}
156
}
157
}
158
}
159
}
160
} else {
161
162
// * Form C := alpha*A**T*B + alpha*B**T*A + C.
163
if (upper) {
164
for (j = 0; j < n; j++) {
165
for (i = 0; i < j; i++) {
166
temp1 = 0.0;
167
temp2 = 0.0;
168
l = 0;
169
for (; l + spec.length() < k; l += spec.length()) {
170
DoubleVector aV1 = spec.fromArray(a, l + i * lda + _a_offset);
171
DoubleVector bV1 = spec.fromArray(b, l + j * ldb + _b_offset);
172
DoubleVector aV2 = spec.fromArray(a, l + j * lda + _a_offset);
173
DoubleVector bV2 = spec.fromArray(b, l + i * ldb + _b_offset);
174
temp1 += aV1.mul(bV1).sumAll();
175
temp2 += aV2.mul(bV2).sumAll();
176
}
177
for (; l < k; l++) {
178
temp1 = temp1 + a[l + i * lda + _a_offset] * b[l + j * ldb + _b_offset];
179
temp2 = temp2 + b[l + i * ldb + _b_offset] * a[l + j * lda + _a_offset];
180
}
181
if (beta == 0.0) {
182
c[i + j * Ldc + _c_offset] = alpha * temp1 + alpha * temp2;
183
} else {
184
c[i + j * Ldc + _c_offset] = beta * c[i + j * Ldc + _c_offset] + alpha * temp1 + alpha * temp2;
185
}
186
}
187
}
188
} else {
189
for (j = 0; j < n; j++) {
190
for (i = j; i < n; i++) {
191
temp1 = 0.0;
192
temp2 = 0.0;
193
l = 0;
194
for (; l+spec.length() < k; l+=spec.length()) {
195
DoubleVector aV1=spec.fromArray(a,l + i * lda + _a_offset);
196
DoubleVector bV1=spec.fromArray(b,l + j * ldb + _b_offset);
197
DoubleVector bV2=spec.fromArray(b,l + i * ldb + _b_offset);
198
DoubleVector aV2=spec.fromArray(a,l + j * lda + _a_offset);
199
temp1+=aV1.mul(bV1).sumAll();
200
temp2+=aV2.mul(bV2).sumAll();
201
}
202
for (; l < k; l++) {
203
temp1 = temp1 + a[l + i * lda + _a_offset] * b[l + j * ldb + _b_offset];
204
temp2 = temp2 + b[l + i * ldb + _b_offset] * a[l + j * lda + _a_offset];
205
}
206
if (beta == 0.0) {
207
c[i + j * Ldc + _c_offset] = alpha * temp1 + alpha * temp2;
208
} else {
209
c[i + j * Ldc + _c_offset] = beta * c[i + j * Ldc + _c_offset] + alpha * temp1 + alpha * temp2;
210
}
211
}
212
}
213
}
214
}
215
216
}
217
218
static public void VecDsyr2kFloat(String uplo, String trans, int n, int k, float alpha, float[] a, int _a_offset, int lda, float[] b, int _b_offset, int ldb, float beta, float[] c, int _c_offset, int Ldc) {
219
FloatVector.FloatSpecies spec= (FloatVector.FloatSpecies) Vector.speciesInstance(Float.class, Shapes.S_256_BIT);
220
float temp1 = 0.0f;
221
float temp2 = 0.0f;
222
int i = 0;
223
int info = 0;
224
int j = 0;
225
int l = 0;
226
int nrowa = 0;
227
boolean upper = false;
228
if (trans.equals("N")) {
229
nrowa = n;
230
} else {
231
nrowa = k;
232
} // Close else.
233
//FloatVector zeroVec = spec.broadcast(0.0f);
234
// FloatVector betaVec = spec.broadcast(beta);
235
upper = uplo.equals("U");
236
if (alpha == 0.0) {
237
if (upper) {
238
if (beta == 0.0) {
239
for (j = 0; j < n; j++) {
240
i = 0;
241
for (; (i + spec.length()) < j; i += spec.length()) {
242
FloatVector zeroVec = spec.broadcast(0.0f);
243
zeroVec.intoArray(c, i + j * Ldc + _c_offset);
244
}
245
for (; i <= j; i++) {
246
c[i + j * Ldc + _c_offset] = 0.0f;
247
}
248
}
249
} else {
250
for (j = 0; j < n; j++) {
251
i = 0;
252
for (; (i + spec.length()) <= j; i += spec.length()) {
253
FloatVector cV = spec.fromArray(c, i + j * Ldc + _c_offset);
254
FloatVector betaVec = spec.broadcast(beta);
255
cV.mul(betaVec).intoArray(c, i + j * Ldc + _c_offset);
256
}
257
for (; i <= j; i++) {
258
c[i + j * Ldc + _c_offset] = beta * c[i + j * Ldc + _c_offset];
259
}
260
}
261
}
262
}
263
264
//lower
265
else {
266
if (beta == 0.0) {
267
for (j = 0; j < n; j++) {
268
i = j;
269
for (; i + spec.length() < n; i += spec.length()) {
270
FloatVector zeroVec = spec.broadcast(0.0f);
271
zeroVec.intoArray(c, i + j * Ldc + _c_offset);
272
}
273
for (; i < n; i++) {
274
c[i + j * Ldc + _c_offset] = 0.0f;
275
}
276
}
277
} else {
278
for (j = 0; j < n; j++) {
279
i = j;
280
for (; i + spec.length() < n; i += spec.length()) {
281
FloatVector cV = spec.fromArray(c, i + j * Ldc + _c_offset);
282
FloatVector betaVec = spec.broadcast(beta);
283
cV.mul(betaVec).intoArray(c, i + j * Ldc + _c_offset);
284
}
285
}
286
for (; i < n; i++) {
287
c[i + j * Ldc + _c_offset] = beta * c[i + j * Ldc + _c_offset];
288
}
289
}
290
}
291
}
292
//start operations
293
if (trans.equals("N")) {
294
// * Form C := alpha*A*B**T + alpha*B*A**T + C.
295
if (upper) {
296
for (j = 0; j < n; j++) {
297
if (beta == 0.0) {
298
i = 0;
299
for (; i + spec.length() <= j; i += spec.length()) {
300
FloatVector zeroVec = spec.broadcast(0.0f);
301
zeroVec.intoArray(c, i + j * Ldc + _c_offset);
302
}
303
for (; i <= j; i++) {
304
c[i + j * Ldc + _c_offset] = 0.0f;
305
}
306
307
} else if (beta != 1.0) {
308
i = 0;
309
for (; i + spec.length() <= j; i += spec.length()) {
310
FloatVector cV = spec.fromArray(c, i + j * Ldc + _c_offset);
311
FloatVector betaVec = spec.broadcast(beta);
312
cV.mul(betaVec).intoArray(c, i + j * Ldc + _c_offset);
313
}
314
for (; i <= j; i++) {
315
c[i + j * Ldc + _c_offset] = beta * c[i + j * Ldc + _c_offset];
316
}
317
}
318
319
for (l = 0; l < k; l++) {
320
if ((a[j + l * lda + _a_offset] != 0.0) || (b[j + l * ldb + _b_offset] != 0.0)) {
321
temp1 = alpha * b[j + l * ldb + _b_offset];
322
temp2 = alpha * a[j + l * lda + _a_offset];
323
i = 0;
324
for (; (i + spec.length()) <= j; i += spec.length()) {
325
FloatVector cV = spec.fromArray(c, i + j * Ldc + _c_offset);
326
FloatVector bV = spec.fromArray(b, i + l * ldb + _b_offset);
327
FloatVector aV = spec.fromArray(a, i + l * lda + _a_offset);
328
FloatVector tv1 = spec.broadcast(temp1);
329
FloatVector tv2 = spec.broadcast(temp2);
330
cV.add(aV.mul(tv1)).add(bV.mul(tv2)).intoArray(c, i + j * Ldc + _c_offset);
331
}
332
for (; i <= j; i++) {
333
c[i + j * Ldc + _c_offset] = c[i + j * Ldc + _c_offset] + a[i + l * lda + _a_offset] * temp1 + b[i + l * ldb + _b_offset] * temp2;
334
}
335
}
336
}
337
}
338
} else {
339
340
for (j = 0; j < n; j++) {
341
if (beta == 0.0) {
342
i = j;
343
for (; (i + spec.length()) < n; i += spec.length()) {
344
FloatVector zeroVec = spec.broadcast(0.0f);
345
zeroVec.intoArray(c, i + j * Ldc + _c_offset);
346
}
347
for (; i < n; i++) {
348
c[i + j * Ldc + _c_offset] = 0.0f;
349
}
350
} else if (beta != 1.0) {
351
i = j;
352
for (; (i + spec.length()) < n; i += spec.length()) {
353
FloatVector cV = spec.fromArray(c, i + j * Ldc + _c_offset);
354
FloatVector betaVec = spec.broadcast(beta);
355
cV.mul(betaVec).intoArray(c, i + j * Ldc + _c_offset);
356
}
357
for (; i < n; i++) {
358
c[i + j * Ldc + _c_offset] = beta * c[i + j * Ldc + _c_offset];
359
}
360
}
361
for (l = 0; l < k; l++) {
362
if ((a[j + l * lda + _a_offset] != 0.0) || (b[j + l * ldb + _b_offset] != 0.0)) {
363
temp1 = alpha * b[j + l * ldb + _b_offset];
364
temp2 = alpha * a[j + l * lda + _a_offset];
365
i = j;
366
for (; i + spec.length() < n; i += spec.length()) {
367
FloatVector cV = spec.fromArray(c, i + j * Ldc + _c_offset);
368
FloatVector aV = spec.fromArray(a, i + l * lda + _a_offset);
369
FloatVector bV = spec.fromArray(b, i + l * ldb + _b_offset);
370
FloatVector tv1 = spec.broadcast(temp1);
371
FloatVector tv2 = spec.broadcast(temp2);
372
cV.add(aV.mul(tv1)).add(bV.mul(tv2)).intoArray(c, i + j * Ldc + _c_offset);
373
}
374
for (; i < n; i++) {
375
c[i + j * Ldc + _c_offset] = c[i + j * Ldc + _c_offset] + a[i + l * lda + _a_offset] * temp1 + b[i + l * ldb + _b_offset] * temp2;
376
}
377
}
378
}
379
}
380
}
381
} else {
382
383
// * Form C := alpha*A**T*B + alpha*B**T*A + C.
384
if (upper) {
385
for (j = 0; j < n; j++) {
386
for (i = 0; i < j; i++) {
387
temp1 = 0.0f;
388
temp2 = 0.0f;
389
l = 0;
390
for (; l + spec.length() < k; l += spec.length()) {
391
FloatVector aV1 = spec.fromArray(a, l + i * lda + _a_offset);
392
FloatVector bV1 = spec.fromArray(b, l + j * ldb + _b_offset);
393
FloatVector aV2 = spec.fromArray(a, l + j * lda + _a_offset);
394
FloatVector bV2 = spec.fromArray(b, l + i * ldb + _b_offset);
395
temp1 += aV1.mul(bV1).sumAll();
396
temp2 += aV2.mul(bV2).sumAll();
397
}
398
for (; l < k; l++) {
399
temp1 = temp1 + a[l + i * lda + _a_offset] * b[l + j * ldb + _b_offset];
400
temp2 = temp2 + b[l + i * ldb + _b_offset] * a[l + j * lda + _a_offset];
401
}
402
if (beta == 0.0) {
403
c[i + j * Ldc + _c_offset] = alpha * temp1 + alpha * temp2;
404
} else {
405
c[i + j * Ldc + _c_offset] = beta * c[i + j * Ldc + _c_offset] + alpha * temp1 + alpha * temp2;
406
}
407
}
408
}
409
} else {
410
for (j = 0; j < n; j++) {
411
for (i = j; i < n; i++) {
412
temp1 = 0.0f;
413
temp2 = 0.0f;
414
l = 0;
415
for (; l+spec.length() < k; l+=spec.length()) {
416
FloatVector aV1=spec.fromArray(a,l + i * lda + _a_offset);
417
FloatVector bV1=spec.fromArray(b,l + j * ldb + _b_offset);
418
FloatVector bV2=spec.fromArray(b,l + i * ldb + _b_offset);
419
FloatVector aV2=spec.fromArray(a,l + j * lda + _a_offset);
420
temp1+=aV1.mul(bV1).sumAll();
421
temp2+=aV2.mul(bV2).sumAll();
422
}
423
for (; l < k; l++) {
424
temp1 = temp1 + a[l + i * lda + _a_offset] * b[l + j * ldb + _b_offset];
425
temp2 = temp2 + b[l + i * ldb + _b_offset] * a[l + j * lda + _a_offset];
426
}
427
if (beta == 0.0) {
428
c[i + j * Ldc + _c_offset] = alpha * temp1 + alpha * temp2;
429
} else {
430
c[i + j * Ldc + _c_offset] = beta * c[i + j * Ldc + _c_offset] + alpha * temp1 + alpha * temp2;
431
}
432
}
433
}
434
}
435
}
436
437
}
438
439
} // End class.
BLASS-III(DGEMM)
001
import jdk.incubator.vector.DoubleVector;
002
import jdk.incubator.vector.Shapes;
003
import jdk.incubator.vector.Vector;
004
005
public class BLAS3GEMM {
006
007
008
009
void VecDgemm(String transa, String transb, int m, int n, int k, double alpha, double[] a, int a_offset, int lda, double[] b, int b_offset, int ldb, double beta, double[] c, int c_offset, int ldc) {
010
DoubleVector.DoubleSpecies spec= (DoubleVector.DoubleSpecies) Vector.speciesInstance(Double.class, Shapes.S_512_BIT);
011
double temp = 0.0;
012
int i = 0;
013
int info = 0;
014
int j = 0;
015
int l = 0;
016
int ncola = 0;
017
int nrowa = 0;
018
int nrowb = 0;
019
boolean nota = false;
020
boolean notb = false;
021
DoubleVector zeroVec = spec.broadcast(0.0);
022
023
if (m == 0 || n == 0 || ((alpha == 0 || k == 0) && beta == 1.0))
024
return;
025
//double temp=0.0;
026
if (alpha == 0.0) {
027
if (beta == 0.0) {
028
for (j = 0; j < n; j++) {
029
for (i = 0; (i + spec.length()) < m && (i + j * ldc + c_offset+spec.length()) bv = spec.broadcast(beta);
042
for (i = 0; (i + spec.length()) < m && (i + j * ldc + c_offset+spec.length()) cv = spec.fromArray(c, i + j * ldc + c_offset);
044
cv.mul(bv).intoArray(c, i + j * ldc + c_offset);
045
}
046
for (; i < m && i + j * ldc + c_offset bv = spec.broadcast(beta);
067
for (i = 0; (i + spec.length()) < m && (i + j * ldc + c_offset+spec.length()) cv = spec.fromArray(c, i + j * ldc + c_offset);
069
cv.mul(bv).intoArray(c, i + j * ldc + c_offset);
070
}
071
for (; i < m && (i + j * ldc + c_offset) tv = spec.broadcast(temp);
078
for (i = 0; (i + spec.length()) < m && (i + l * lda + a_offset+spec.length()) av = spec.fromArray(a, i + l * lda + a_offset);
080
DoubleVector cv = spec.fromArray(c, i + j * ldc + c_offset);
081
cv.add(av.mul(tv)).intoArray(c, i + j * ldc + c_offset); //tv.fma(av, cv).toDoubleArray(c, i+j*ldc+c_offset);
082
}
083
for (; i < m && (i + l * lda + a_offset) av = spec.fromArray(a, l + i * lda + a_offset);
094
DoubleVector bv = spec.fromArray(b, l + j * ldb + b_offset);
095
temp += av.mul(bv).sumAll();
096
}
097
for (; l < k && l + i * lda + a_offset bv = spec.broadcast(beta);
121
for (i = 0; (i + spec.length()) < m && (i + j * ldc + c_offset+spec.length()) cv = spec.fromArray(c, i + j * ldc + c_offset);
123
cv.mul(bv).intoArray(c, i + j * ldc + c_offset);
124
}
125
for (; i < m && i + j * ldc + c_offset tv = spec.broadcast(temp);
134
for (i = 0; (i + spec.length()) < m && (i + j * ldc + c_offset+spec.length()) cv = spec.fromArray(c, i + j * ldc + c_offset);
136
DoubleVector av = spec.fromArray(a, i + l * lda + a_offset);
137
cv.add(tv.mul(av)).intoArray(c, i + j * ldc + c_offset); //tv.fma(av, cv).toDoubleArray(c, i + j * ldc + c_offset);
138
}
139
for (; i < m && (i + j * ldc + c_offset) av = spec.fromArray(a, l + i * lda + a_offset);
151
DoubleVector bv = spec.fromArray(b, j + l * ldb + b_offset);
152
temp += av.mul(bv).sumAll();
153
}
154
for (; l < k && (l + i * lda + a_offset) 金融服务(FSI)算法
GetOptionPrice
01
import jdk.incubator.vector.DoubleVector;
02
import jdk.incubator.vector.Shapes;
03
import jdk.incubator.vector.Vector;
04
05
public class FSI_getOptionPrice {
06
07
08
public static double getOptionPrice(double Sval, double Xval, double T, double[] z, int numberOfPaths, double riskFree, double volatility)
09
{
10
double val=0.0 , val2=0.0;
11
double VBySqrtT = volatility * Math.sqrt(T);
12
double MuByT = (riskFree - 0.5 * volatility * volatility) * T;
13
14
//Simulate Paths
15
for(int path = 0; path < numberOfPaths; path++)
16
{
17
double callValue = Sval * Math.exp(MuByT + VBySqrtT * z[path]) - Xval;
18
callValue = (callValue > 0) ? callValue : 0;
19
val += callValue;
20
val2 += callValue * callValue;
21
}
22
23
double optPrice=0.0;
24
optPrice = val / numberOfPaths;
25
return (optPrice);
26
}
27
28
29
public static double VecGetOptionPrice(double Sval, double Xval, double T, double[] z, int numberOfPaths, double riskFree, double volatility) {
30
DoubleVector.DoubleSpecies spec= (DoubleVector.DoubleSpecies) Vector.speciesInstance(Double.class, Shapes.S_512_BIT);
31
double val = 0.0, val2 = 0.0;
32
33
double VBySqrtT = volatility * Math.sqrt(T);
34
DoubleVector VByVec = spec.broadcast(VBySqrtT);
35
double MuByT = (riskFree - 0.5 * volatility * volatility) * T;
36
DoubleVector MuVec = spec.broadcast(MuByT);
37
DoubleVector SvalVec = spec.broadcast(Sval);
38
DoubleVector XvalVec = spec.broadcast(Xval);
39
DoubleVector zeroVec =spec.broadcast(0.0D);
40
41
//Simulate Paths
42
int path = 0;
43
for (; (path + spec.length()) < numberOfPaths; path += spec.length()) {
44
DoubleVector zv = spec.fromArray(z, path);
45
DoubleVector tv = MuVec.add(VByVec.mul(zv)).exp(); //Math.exp(MuByT + VBySqrtT * z[path])
46
DoubleVector callValVec = SvalVec.mul(tv).sub(XvalVec);
47
callValVec = callValVec.blend(zeroVec, callValVec.greaterThan(zeroVec));
48
val += callValVec.sumAll();
49
val2 += callValVec.mul(callValVec).sumAll();
50
}
51
//tail
52
for (; path < numberOfPaths; path++) {
53
double callValue = Sval * Math.exp(MuByT + VBySqrtT * z[path]) - Xval;
54
callValue = (callValue > 0) ? callValue : 0;
55
val += callValue;
56
val2 += callValue * callValue;
57
}
58
double optPrice = 0.0;
59
optPrice = val / numberOfPaths;
60
return (optPrice);
61
}
62
}
BinomialOptions
01
import jdk.incubator.oracle.vector.*;
02
03
public class FSI_BinomialOptions {
04
05
06
07
public static void VecBinomialOptions(double[] stepsArray, int STEPS_CACHE_SIZE, double vsdt, double x, double s, int numSteps, int NUM_STEPS_ROUND, double pdByr, double puByr) {
08
DoubleVector.DoubleSpecies spec= (DoubleVector.DoubleSpecies) Vector.speciesInstance(Double.class, Shapes.S_512_BIT);
09
IntVector.IntSpecies ispec = (IntVector.IntSpecies) Vector.speciesInstance(Integer.class, Shapes.S_512_BIT);
10
11
// double stepsArray [STEPS_CACHE_SIZE];
12
DoubleVector sv = spec.broadcast(s);
13
DoubleVector vsdtVec = spec.broadcast(vsdt);
14
DoubleVector xv = spec.broadcast(x);
15
DoubleVector pdv = spec.broadcast(pdByr);
16
DoubleVector puv = spec.broadcast(puByr);
17
DoubleVector zv = spec.broadcast(0.0D);
18
IntVector inc = ispec.fromArray(new int[]{0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15}, 0);
19
IntVector nSV = ispec.broadcast(numSteps);
20
int j;
21
for (j = 0; (j + spec.length()) < STEPS_CACHE_SIZE; j += spec.length()) {
22
IntVector jv = ispec.broadcast(j);
23
Vector tv = jv.add(inc).cast(Double.class).mul(spec.broadcast(2.0D)).sub(nSV.cast(Double.class));
24
DoubleVector pftVec=sv.mul(vsdtVec.mul(tv).exp()).sub(xv);
25
pftVec.blend(zv,pftVec.greaterThan(zv)).intoArray(stepsArray,j);
26
}
27
for (; j < STEPS_CACHE_SIZE; j++) {
28
double profit = s * Math.exp(vsdt * (2.0D * j - numSteps)) - x;
29
stepsArray[j] = profit > 0.0D ? profit : 0.0D;
30
}
31
32
for (j = 0; j < numSteps; j++) {
33
int k;
34
for (k = 0; k + spec.length() < NUM_STEPS_ROUND; k += spec.length()) {
35
DoubleVector sv0 = spec.fromArray(stepsArray, k);
36
DoubleVector sv1 = spec.fromArray(stepsArray, k + 1);
37
pdv.mul(sv1).add(puv.mul(sv0)).intoArray(stepsArray, k); //sv0 = pdv.fma(sv1, puv.mul(sv0)); sv0.intoArray(stepsArray,k);
38
}
39
for (; k < NUM_STEPS_ROUND; ++k) {
40
stepsArray[k] = pdByr * stepsArray[k + 1] + puByr * stepsArray[k];
41
}
42
}
43
}
44
45
}
有关编译器优化的更多完整信息,请参见优化注意事项。
| 附件 | 大小 |
|---|---|
| PDF icon Vector API writing own-vector final 9-27-17.pdf | 1.03 MB |