Python3:Pandas的简单使用4(针对DataFrame的操作:离散化,数据拼接,合并,画图)
1.声明
当前的内容用于本人复习,主要包括当前Pandas数据的离散化,拼接操作,合并数据,还有画图操作
2.数据的离散化(分组后离散化)
# 数据离散化,就是在制定的范围中写入数据,如果当前的数据满足,就使用1表示,否者使用0表示
# 例如: 具有以下数据,某商店具有以下价格的商品,查看当前商品存在的区间
# good1 100 good2 150 good3 180 good4 =120 good5 =200
# 100-120 120-150 150-200
# 显示的结果为: good1 1 0 0
# good2 0 1 0
# good3 0 0 1
# good4 1 0 0
# good5 0 0 1
# 当前的表示方法就是上面的,这就是离散化
# 下面使用Pandas实现数据的离散化
import pandas as pd
import numpy as np
goods = np.random.randint(10, 20, 10)
pd_series = pd.Series(goods, index=["商品{}".format(i + 1) for i in range(len(goods))])
print(pd_series)
# 使用自动分配区间的方式
pd_qcut_result = pd.qcut(pd_series, 5)
print("用于数据当前的数据区间的01的图:\n{}".format(pd.get_dummies(pd_qcut_result)))
print("用于获取每个区间的数据的个数:\n{}".format(pd.value_counts(pd_qcut_result)))
print("=" * 25)
print("使用自定义分组方式实现离散操作!")
# 使用自定义的分组方式实现分组操作
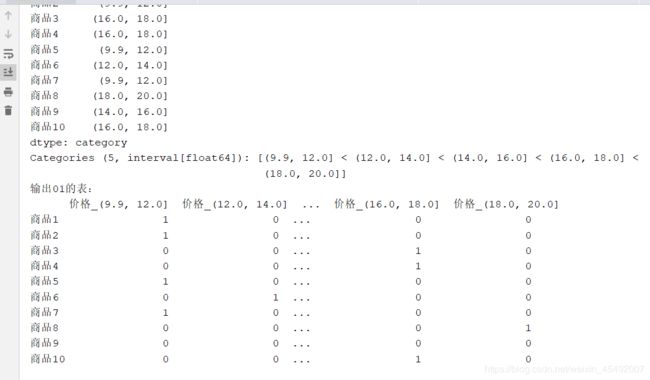
bins = [9.9, 12, 14, 16, 18, 20] # 分组的数据
diy_cut_series = pd.cut(pd_series, bins=bins)
print(diy_cut_series)
print("输出01的表:\n{}".format(pd.get_dummies(diy_cut_series, prefix="价格")))
# 输出每个区间的统计个数
print("输出每个区间的统计个数:\n{}".format(pd.value_counts(diy_cut_series)))
结果:
总结:
实现离散化操作的时候需要两步:1.对数据进行分组,2.对数据进行离散化
1.分组的时候可以使用pd.pcut()进行自动分组,使用pd.cut()按照指定方式分组
2.离散化操作是在分组数据后的操作,直接对分组的数据执行:pd.get_dummies()获取01的数据
3.数据的拼接(concat)
# 使用当前的pandas实现数据的合并
# 使用当前的数据拼接方式需要使用当前的pd.concat这个方式,同样可以指定当前的拼接的方式:水平拼接以及垂直拼接
import pandas as pd
import numpy as np
pd_datas = np.random.randint(10, 100, (5, 5))
days = ["第{}天".format(i + 1) for i in range(5)]
shops = ["第{}家店".format(i + 1) for i in range(5)]
pd_dataFrame = pd.DataFrame(pd_datas, index=days, columns=shops)
print("查看5家店生成的数据的结果:\n{}".format(pd_dataFrame.head()))
# 实现数据的拼接的操作
# 模拟第二个数据
pd_datas2 = np.random.randint(10, 100, (5, 2))
shops2 = ["第6家店", "第7家店"]
pd_dataFrame2 = pd.DataFrame(pd_datas2, index=days, columns=shops2)
# 查看生成的数据结果:
print("查看生成的另外两家店的销售结果:\n{}".format(pd_dataFrame2))
# 指定按照垂直方向合并数据的结果
pd_concat_result = pd.concat((pd_dataFrame, pd_dataFrame2), axis=1)
print("查看合并后的数据的结果:\n{}".format(pd_concat_result))
# 使用当前的水平方向的合并的结果,
pd_concat_result = pd.concat((pd_dataFrame, pd_dataFrame2), axis=0)
print("查看合并后的数据的结果:\n{}".format(pd_concat_result))
结果:

总结:
1.进行数据的拼接操作的时候使用pd.concat()方式将两个数据合并,需要指定axis(合并的方式)
2.在拼接数据的时候会如果数据没有的地方就会显示NaN,否者显示正常
4.数据的合并(merge)
# 当前的包主要是用于实现数据的合并的操作,不是上面的数据的拼接操作,是用于数据的合并操作
# 当前的数据的合并操作主要使用:pd.merge方式合并指定的两张表的数据,这个表中的数据主要使用的是关联关系实现的数据操作(主要使用的是内联外联左连接右链接)
import pandas as pd
# 存在成绩表
pd_scores = [[1, 50, 60, 70],
[2, 60, 70, 80],
[3, 70, 80, 90],
[4, 80, 90, 100],
]
pd_scores_index = ["zs", "ls", "ww", "zl"]
pd_scores_columns = ["编号", "语文", "数学", "外语"]
pd_socres_dataFrame = pd.DataFrame(pd_scores, index=pd_scores_index, columns=pd_scores_columns)
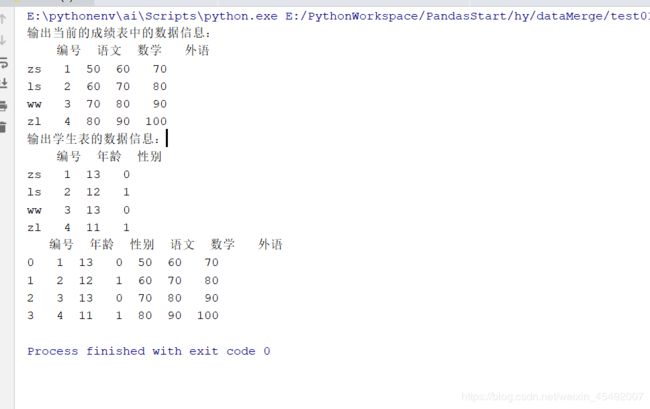
print("输出当前的成绩表中的数据信息:\n{}".format(pd_socres_dataFrame))
# pd.merge()
# 假设存在学生表
pd_students = [[1, 13, 0],
[2, 12, 1],
[3, 13, 0],
[4, 11, 1]]
pd_students_index = ["zs", "ls", "ww", "zl"]
pd_students_columns = ["编号", "年龄", "性别"]
pd_students_dataFrame = pd.DataFrame(pd_students, index=pd_students_index, columns=pd_students_columns)
print("输出学生表的数据信息:\n{}".format(pd_students_dataFrame))
# 现在开始使用合并操作实现数据的合并
pd_merge_result = pd.merge(left=pd_students_dataFrame, right=pd_socres_dataFrame, how="inner", on="编号")
print(pd_merge_result)
结果:
总结:
1.使用pd.merge()的时候需要指定当前的参数left和right,还有特定的how
2.默认how为inner表示内连接方式,这个how的数据就像当于数据库表之间的连接,内联外联左联右联等
3.通过on方式指定按照什么连接相当于数据库表连接的on
5.画图操作
# 使用当前的pandas实现当前的画图的操作
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['KaiTi'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False
# 使用当前的Series方式画图
pd_series = pd.Series([i for i in np.random.randint(5, 10, 10)], index=["第{}天".format(i) for i in range(10)])
pd_series.plot()
# 使用当前的DataFrame方式进行当前的画图的操作
columns = ["第{}家店".format(i + 1) for i in range(5)]
index = ["第{}天".format(i + 1) for i in range(5)]
pd_dataFrame = pd.DataFrame(np.random.randint(5, 10, (5, 5)), index=index, columns=columns)
pd_dataFrame.plot()
plt.show()
结果:

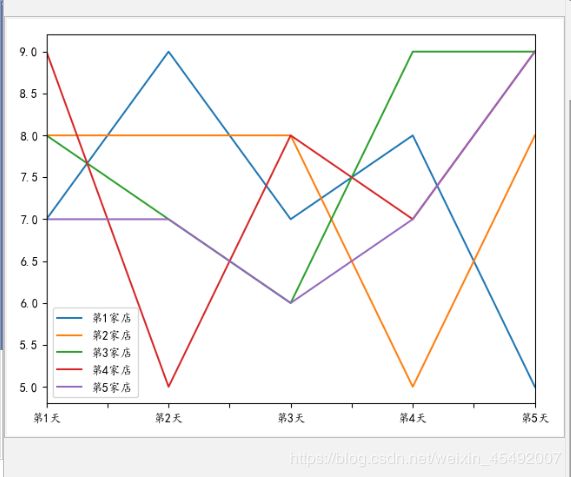
画图的时候直接使用plot即可,可以指定当前的kind表示使用什么样式画图
6.总结
1.当前的离散化操作就是显示01的数据分布操作,需要先分组然后再离散化
2.数据的拼接使用pd.concat需要指定拼接的方式axis,注意没有写入的数据就会保持NaN
3.数据的合并,就是数据表之间的合并操作类似数据库的表之间的连接操作
以上纯属个人见解,如有问题请联系本人!