Spark sql 常见问题及优化
目录
- 数据倾斜
- 1.null值的处理
- 2.shell脚本整合spark-sql
- spark-submit 参数解析及调优
- 3.一个奇葩的问题(待解决)
- 4.未解决的问题
- 5.持续整理中...
数据倾斜
1.null值的处理
INSERT OVERWRITE TABLE tf_lte_prd_pd_inst_month PARTITION (month_id) SELECT
prvnce_id,
std_prvnce_cd ,...
FROM
(
SELECT
'${V_DATE}' month_id ,..., CASE
WHEN (
d.POST IN ('13', '14', '32', '19', '26')
OR e.ZQ_TYPE IN (10, 20, 30 )...
END channel_big_type_cd,
e.CHANNEL_TYPE_CD_3 channel_type_cd_3,
COALESCE (e.zq_type, '-1') AS CHANNEL_ATTR_CD,
COALESCE (d.post, '-1') AS STAFF_POST,
COALESCE (d.DRCT_STAFF_TYPE, '-1') AS DRCT_STAFF_TYPE,
CASE
WHEN d.post IN ('13', '14', '19', '32') THEN
'100100'...
END AS CHANNEL_TYPE_CD_2,
CASE
WHEN d.DRCT_STAFF_TYPE = '30'
AND d.POST IN ('13', '14', '32', '19', '26') THEN
'30'...
END AS DRCT_MKT_TYPE,
from_unixtime(
unix_timestamp(),
'yyyy/MM/dd HH:mm:ss'
) ETL_TIME
FROM
(
SELECT
*
FROM
tf_lte_prd_pd_inst_day m --4E+数据量
WHERE
m.day_id = concat(
substr(
from_unixtime(
unix_timestamp(),
'yyyyMMdd HH:mm:ss'
),
1,
6
),
'01'
)
) a
LEFT OUTER JOIN (
SELECT
O.OPERATORS_PRVNCE_ID ,...
FROM
TM_SALE_STAFF_INFO_M O --百万
WHERE
O.STAFF_CD IS NOT NULL
AND o.MONTH_ID = '${V_DATE}'
) D ON a.DVLP_STAFF_CD = D.STAFF_CD
LEFT OUTER JOIN (
SELECT
T1.SALE_OUTLETS_CD ,...
FROM
TM_SALE_OUTLETS_M T1 --百万
WHERE
t1.SALE_OUTLETS_CD IS NOT NULL
AND t1.MONTH_ID = '${V_DATE}'
) e ON a.SALE_OUTLETS_CD = e.SALE_OUTLETS_CD
) temp
- 需求
- 因原调度基于hive执行,现有需求提速,将现运行的脚本更改至基于spark运行,不同脚本的运行时间控制在不同的时间范围内!(上SQL原最大运行时间为120min,要求空控制在10min之内)
- 直接运行原sql,发现存在比较严重的数据倾斜现象(未截图,不复现了,以后遇见再截图)
- 经分析发现表m 为E级数量级表,表O、T 为百万级数据量级表。
- 执行下面sql,发现关联主键在主表中有半数为null值,在此考虑将null值进行处理。
- 分析:
1) spark 会将null值分配到一个节点进行运算,2E null值在一个节点一一进行匹配,会严重拖慢运行速度,spark的推断执行会启动一个相同的运行任务去运行这个task。
2)可行原因: null值处理成一个随机数的其他字段,会均匀分配到其他节点上,运行时查看yarn界面,数据分布基本均匀。 - 以上就是在升级提速过程中遇到的数据倾斜问题。
SELECT COUNT(1) FROM db_name.table_name WHERE DVLP_STAFF_CD IS NOT NULL AND DAY_ID = 20190301
UNION ALL
SELECT COUNT(1) FROM db_name.table_name WHERE DAY_ID = 20190301
– 处理null值的sql
create table ods_tmp_db.tmp_tf_lte_prd_pd_inst_month_${V_DATE}_yh as
select
...
,0 lte_flag
,D.OPERATORS_PRVNCE_ID, -- ```D表中的字段```
D.OPERATORS_LATN_ID,
D.STAFF_CD,
D.POST,
D.DRCT_STAFF_TYPE DRCT_STAFF_TYPE_nei
from
( select r.*,
case when DVLP_STAFF_CD is not null
and DVLP_STAFF_CD != ''
then DVLP_STAFF_CD
else concat(ceiling(rand() * -65535),'NULL')
end DVLP_STAFF_CD_r -- ```此处对null值进行处理,因spark sql on后面不支持加随机数```
from
(select * from ${v_source_table_01} m
WHERE m.day_id='20190201' --concat(substr(from_unixtime(unix_timestamp(), 'yyyyMMdd HH:mm:ss'),1,6),'01')
) r
) a
LEFT OUTER JOIN (SELECT O.OPERATORS_PRVNCE_ID,
O.OPERATORS_LATN_ID,
O.STAFF_CD STAFF_CD,
O.POST,
O.DRCT_STAFF_TYPE
FROM ${v_source_table_02} O
WHERE O.STAFF_CD is not null
and o.MONTH_ID='${V_DATE}') D
ON a.DVLP_STAFF_CD_r=D.STAFF_CD
运行结果:
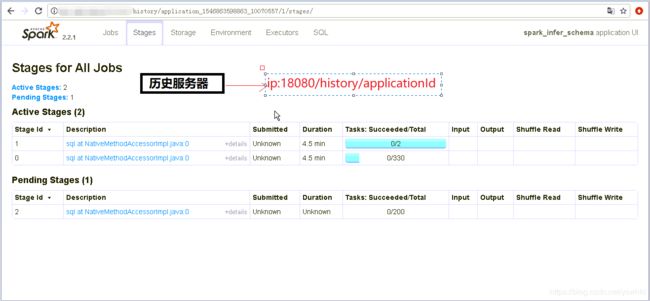


2.shell脚本整合spark-sql
简易开发:spark_submit + py脚本
$ vim spark_submit.sh
#! /bin/bash
echo 'this just a test'
/home/usr/lib/spark/bin/spark-submit \
--master yarn-cluster \
--files
--py-files
--jars
--driver-java-options="-Djava.security.auth.login.config=kafka_client_jaas.conf -XX:MaxPermSize=256m -XX:+UseConcMarkSweepGC" \
--conf "spark.executor.extraJavaOptions=-Djava.security.auth.login.config=kafka_client_jaas.conf -XX:+UseConcMarkSweepGC -verbose:gc -XX:+PrintGCDetails -XX:+PrintGCTimeStamps " \
--conf "spark.driver.maxResultSize=4g" \
--conf spark.sql.shuffle.partitions=2600 \
--conf spark.default.parallelism=300 \
--queue root.normal_queues.proccess.hxxt.yx \
--name "Example Program" \
--num-executors 30 \
--executor-cores 4 \
--driver-memory 8g \
--executor-memory 16g $1 $2 $3 $4 $5
py脚本
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import sys, os, time, traceback, uuid, datetime
from pyspark.sql import HiveContext
os.environ['PYTHON_EGG_CACHE'] = '/tmp'
reload(sys)
sys.setdefaultencoding('utf8')
from python_v2.bin.p_bat_dwm_spark_sc import CreateConnectSpark
from python_v2.bin.p_bat_core_send_mess import send_message
from python_v2.bin.p_bat_dwm_save_log import InsertLog
from python_v2.bin.p_bat_dwm_return_json import *
from python_v2.bin.p_bat_dwm_time_tools import PraseDate
from python_v2.bin.p_bat_gene_logic_extra import *
from python_v2.bin.p_bat_dwm_pif_table_check import pif_table_check
def p_dwd_mss_erp_bpeg_day(evt_id, key_value):
# 声明变量
script_name = '...'
v_succ_flag = 'R'
v_err_msg = ''
sc = None
sqlContext = None
v_frame = sys._getframe().f_code.co_name # 新增变量 存储方法名称
begin_time = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
V_ARG_OPTIME_LASTDAY = PraseDate(key_value['V_DATE'], "ARG_OPTIME_LASTDAY")
# 拼装SQL
sql = '''
DESC DWD_DB.DWD_MSS_ERP_BPEG_DAY
'''
cnt_sql = '''SELECT COUNT(1) FROM TB_NAME WHERE SOURCE_ID = '${V_PROV}' AND DAY_ID = '${V_DATE}' '''
# 替换参数
sql = sql.replace('${V_DATE}', key_value['V_DATE']).replace('${V_PROV}', key_value['V_PROV']).replace('${V_LASTDAY}', V_ARG_OPTIME_LASTDAY).replace('${ETL_TIME}', time.strftime("%Y-%m-%d %H:%M:%S",time.localtime()))
cnt_sql = cnt_sql.replace('${V_DATE}', key_value['V_DATE']).replace('${V_PROV}', key_value['V_PROV'])
# 获取hive客户端并连接
try:
sc = CreateConnectSpark()
sqlContext = HiveContext(sc)
sqlContext.sql('set hive.exec.dynamic.partition=true')
sqlContext.sql('set hive.exec.dynamic.partition.mode=nostrick')
print 'connect to hive successful !'
except Exception, e:
errorMsg = 'err_mess-获取sqlContext时出错!'
print errorMsg
# 记录测试阶段联调异常
InsertLog('', uuid.uuid1(), noticeId, '', 'execute_func', '', 'TF', '', errorMsg, '')
v_err_msg = 'Error: ' + traceback.format_exc(sys.stderr)
print v_err_msg
exit(1)
# 生成日志唯一标识
log_num = uuid.uuid1()
try:
# 执行sql前记录日志
InsertLog(key_value['V_DATE'], log_num, evt_id, script_name, v_frame, key_value, v_succ_flag, begin_time,
v_err_msg, sql, appId=sc.applicationId)
# 执行语句
print sql
sqlContext.sql(sql)
# 统计插入的记录条数
row_cnt = sqlContext.sql(cnt_sql).collect()[0][0]
print '记录数统计成功,本次插入记录数:' + str(row_cnt)
# 执行sql后更新日志结束时间
InsertLog(key_value['V_DATE'], log_num, evt_id, script_name, v_frame, key_value, 'S', begin_time, v_err_msg,
sql, row_cnt)
print 'sql execute successful !'
# 设置返回值并返回
result = {'flag': 'S', 'err_mess': '', 'row_cnt': row_cnt, 'log_num': log_num, 'appId': sc.applicationId,
'file_name': v_frame}
except Exception, e:
print 'sql execute failed !'
v_succ_flag = 'F'
v_err_msg = 'Error: ' + traceback.format_exc(sys.stderr)
# 修改为更新 更新结束时间、是否成功标识、失败sql、异常信息(截取部分信息)
InsertLog(key_value['V_DATE'], log_num, evt_id, script_name, v_frame, key_value, 'F', begin_time, v_err_msg,
sql)
# 设置返回值并返回
result = {'flag': 'F', 'err_mess': str(e), 'log_num': log_num, 'appId': sc.applicationId,
'file_name': v_frame}
finally:
print 'OVER'
return result
if __name__ == "__main__":
# 获取事件ID 获取源表ID
noticeId = sys.argv[1]
# 声明变量
errorMsg = ''
result = None
try:
# 消息触发 日表传'D',月表传'M'
logic_res = bat_judge('D', sys.argv)
# =================================================================================
# 定时触发 日表传'D',月表传'M'
# logic_res = timing_judge('D', sys.argv)
except Exception, e:
errorMsg = str(e)
print '解析参数时发生异常:', errorMsg
exit(0)
else:
try:
result = p_dwd_mss_erp_bpeg_day(noticeId, logic_res['dictMerged2'])
except Exception, e:
errorMsg = str(e)
# 记录测试阶段联调异常
InsertLog('', uuid.uuid1(), noticeId, '', result['file_name'], '', 'TF', '', errorMsg, '',
appId=result['appId'])
print '执行SQL过程中发生异常:', errorMsg
v_err_msg = 'Error: ' + traceback.format_exc(sys.stderr)
print v_err_msg
exit(0)
# 根据SQL执行结果,组装加工组件事件提交的kafka消息,成功失败ID,事件ID,目标表的MD5编码:分区帐期
if result['flag'] == 'F':
subscribe = ''
dataSet = ''
errorMsg = result['err_mess'][0:999]
mess_status = send_message('F', noticeId, subscribe, dataSet, errorMsg, appId=result['appId'])
else:
mess_status = send_message('S', noticeId, logic_res['all_param']['subscribe'],
logic_res['all_param']['dataSet'] % ('b50974a6a910303a63acc91d0270b9f4'), '',
result['row_cnt'], appId=result['appId'])
# 根据消息发送后的返回结果更新etl日志状态
print '主函数中mess_status的值:', mess_status
if mess_status:
InsertLog('', result['log_num'], '', '', '', '', 'NS', '', '', '', sql_st=result['flag'])
else:
InsertLog('', result['log_num'], '', '', '', '', 'NF', '', result['err_mess'] + '消息发送失败', '', sql_st='F')
print '程序正常结束'
exit(0)
spark-submit 参数解析及调优
通过在命令行输入 spark-sql --help / spark-shell --help / spark-submit --help 来获取当前命令帮助
通过spark-shell --version 来获取当前版本
`参考连接 http://spark.apachecn.org/#/`
--master MASTER_URL --> 运行模式
例:spark://host:port, mesos://host:port, yarn, or local.
--deploy-mode DEPLOY_MODE
Whether to launch the driver program locally ("client") or
on one of the worker machines inside the cluster ("cluster")
(Default: client).
--class CLASS_NAME --> 运行程序的main_class
例: com.jhon.hy.main.Test
--name NAME -->application 的名字
例:my_application
--jars JARS -->逗号分隔的本地jar包,包含在driver和executor的classpath下
例:/home/app/python_app/python_v2/jars/datanucleus-api-jdo-3.2.6.jar,/home/app/python_app/python_v2/jars/datanucleus-core-3.2.10.jar,/home/app/python_app/python_v2/jars/datanucleus-rdbms-3.2.9.jar,/home/app/python_app/python_v2/jars/mysql-connector-java-5.1.37-bin.jar,/home/app/python_app/python_v2/jars/hive-bonc-plugin-2.0.0.jar\
--exclude-packages -->用逗号分隔的”groupId:artifactId”列表
--repositories -->逗号分隔的远程仓库
--py-files PY_FILES -->逗号分隔的”.zip”,”.egg”或者“.py”文件,这些文件放在python app的
--files FILES -->逗号分隔的文件,这些文件放在每个executor的工作目录下面,涉及到的k-vge格式的参数,用 ‘#’ 连接,如果有自定义的log4j 配置,也放在此配置下面
例:/home/app/python_app/python_v2/jars/kafka_producer.jar,/home/app/python_app/python_v2/resources/....cn.keytab#.....keytab,/home/app/python_app/python_v2/resources/app.conf#app.conf,/home/app/python_app/python_v2/resources/hive-site.xml,/home/app/python_app/python_v2/resources/kafka_client_jaas.conf#kafka_client_jaas.conf
--properties-file FILE --> 默认的spark配置项,默认路径 conf/spark-defaults.conf
--conf PROP=VALUE --> 任意的spark配置项
例: --conf "spark.driver.maxResultSize=4g" \
--conf spark.sql.shuffle.partitions=2600 \
--conf spark.default.parallelism=300 \
--driver-memory MEM Memory for driver (e.g. 1000M, 2G) (Default: 1024M).
--driver-java-options Extra Java options to pass to the driver.
--driver-library-path Extra library path entries to pass to the driver.
--driver-class-path Extra class path entries to pass to the driver. Note that
jars added with --jars are automatically included in the
classpath.
--executor-memory MEM Memory per executor (e.g. 1000M, 2G) (Default: 1G).
--proxy-user NAME User to impersonate when submitting the application.
This argument does not work with --principal / --keytab.
--help, -h Show this help message and exit.
--verbose, -v Print additional debug output.
--version, Print the version of current Spark.
Spark standalone with cluster deploy mode only:
--driver-cores NUM Cores for driver (Default: 1).
Spark standalone or Mesos with cluster deploy mode only:
--supervise If given, restarts the driver on failure.
--kill SUBMISSION_ID If given, kills the driver specified.
--status SUBMISSION_ID If given, requests the status of the driver specified.
Spark standalone and Mesos only:
--total-executor-cores NUM Total cores for all executors.
Spark standalone and YARN only:
--executor-cores NUM Number of cores per executor. (Default: 1 in YARN mode,
or all available cores on the worker in standalone mode)
YARN-only:
--driver-cores NUM Number of cores used by the driver, only in cluster mode
(Default: 1).
--queue QUEUE_NAME The YARN queue to submit to (Default: "default").
--num-executors NUM Number of executors to launch (Default: 2).
If dynamic allocation is enabled, the initial number of
executors will be at least NUM.
--archives ARCHIVES Comma separated list of archives to be extracted into the
working directory of each executor.
--principal PRINCIPAL Principal to be used to login to KDC, while running on
secure HDFS.
--keytab KEYTAB The full path to the file that contains the keytab for the
principal specified above. This keytab will be copied to
the node running the Application Master via the Secure
Distributed Cache, for renewing the login tickets and the
delegation tokens periodically.
--num-executors 30 \ 启动的executor数量。默认为2。在yarn下使用
--executor-cores 4 \ 每个executor的核数。在yarn或者standalone下使用
--driver-memory 8g \ Driver内存,默认1G
--executor-memory 16g 每个executor的内存,默认是1G
`通常我们讲用了多少资源是指: num-executor * executor-cores 核心数,--num-executors*--executor-memory 内存`
`因现在所在公司用的是spark on yarn 模式,以下涉及调优主要针对目前所用`
--num-executors 这个参数决定了你的程序会启动多少个Executor进程来执行,YARN集群管理
器会尽可能按照你的设置来在集群的各个工作节点上,启动相应数量的Executor
进程。如果忘记设置,默认启动两个,这样你后面申请的资源再多,你的Spark程
序执行速度也是很慢的。
调优建议: 这个要根据你程序运行情况,以及多次执行的结论进行调优,太多,无法充分利用资
源,太少,则保证不了效率。
--executor-memory 这个参数用于设置每个Executor进程的内存,Executor的内存很多时候决
定了Spark作业的性能,而且跟常见的JVM OOM也有直接联系
调优建议:参考值 --> 4~8G,避免程序将整个集群的资源全部占用,需要先看一下你队列的最大
内存限制是多少,如果是公用一个队列,你的num-executors * executor-memory
最好不要超过队列的1/3 ~ 1/2
-- executor-cores
参数说明:
该参数用于设置每个Executor进程的CPU core数量。这个参数决定了每个Executor进程并行执行task线程的能力。因为每个CPU core同一时间只能执行一个
task线程,因此每个Executor进程的CPU core数量越多,越能够快速地执行完分配给自己的所有task线程。
参数调优建议:
Executor的CPU core数量设置为2~4个较为合适。同样得根据不同部门的资源队列来定,可以看看自己的资源队列的最大CPU core限制是多少,再依据设置的
Executor数量,来决定每个Executor进程可以分配到几个CPU core。同样建议,如果是跟他人共享这个队列,那么num-executors * executor-cores不要超过
队列总CPU core的1/3~1/2左右比较合适,也是避免影响其他同学的作业运行。
--driver-memory
参数说明:
该参数用于设置Driver进程的内存。
参数调优建议:
Driver的内存通常来说不设置,或者设置1G左右应该就够了。唯一需要注意的一点是,如果需要使用collect算子将RDD的数据全部拉取到Driver上进行处理,
那么必须确保Driver的内存足够大,否则会出现OOM内存溢出的问题。
--spark.default.parallelism
参数说明:
该参数用于设置每个stage的默认task数量。这个参数极为重要,如果不设置可能会直接影响你的Spark作业性能。
参数调优建议:
Spark作业的默认task数量为500~1000个较为合适。很多同学常犯的一个错误就是不去设置这个参数,那么此时就会导致Spark自己根据底层HDFS的block数量
来设置task的数量,默认是一个HDFS block对应一个task。通常来说,Spark默认设置的数量是偏少的(比如就几十个task),如果task数量偏少的话,就会
导致你前面设置好的Executor的参数都前功尽弃。试想一下,无论你的Executor进程有多少个,内存和CPU有多大,但是task只有1个或者10个,那么90%的
Executor进程可能根本就没有task执行,也就是白白浪费了资源!因此Spark官网建议的设置原则是,设置该参数为num-executors * executor-cores的2~3倍
较为合适,比如Executor的总CPU core数量为300个,那么设置1000个task是可以的,此时可以充分地利用Spark集群的资源。
--spark.storage.memoryFraction
参数说明:
该参数用于设置RDD持久化数据在Executor内存中能占的比例,默认是0.6。也就是说,默认Executor 60%的内存,可以用来保存持久化的RDD数据。根据你选择
的不同的持久化策略,如果内存不够时,可能数据就不会持久化,或者数据会写入磁盘。
参数调优建议:
如果Spark作业中,有较多的RDD持久化操作,该参数的值可以适当提高一些,保证持久化的数据能够容纳在内存中。避免内存不够缓存所有的数据,导致数据只
能写入磁盘中,降低了性能。但是如果Spark作业中的shuffle类操作比较多,而持久化操作比较少,那么这个参数的值适当降低一些比较合适。此外,如果发现
作业由于频繁的gc导致运行缓慢(通过spark web ui可以观察到作业的gc耗时),意味着task执行用户代码的内存不够用,那么同样建议调低这个参数的值。
--spark.shuffle.memoryFraction
参数说明:
该参数用于设置shuffle过程中一个task拉取到上个stage的task的输出后,进行聚合操作时能够使用的Executor内存的比例,默认是0.2。也就是说,Executor
默认只有20%的内存用来进行该操作。shuffle操作在进行聚合时,如果发现使用的内存超出了这个20%的限制,那么多余的数据就会溢写到磁盘文件中去,此时
就会极大地降低性能。
参数调优建议:
如果Spark作业中的RDD持久化操作较少,shuffle操作较多时,建议降低持久化操作的内存占比,提高shuffle操作的内存占比比例,避免shuffle过程中数据过多
时内存不够用,必须溢写到磁盘上,降低了性能。此外,如果发现作业由于频繁的gc导致运行缓慢,意味着task执行用户代码的内存不够用,那么同样建议调低
这个参数的值。
资源参数的调优,没有一个固定的值,需要根据自己的实际情况(包括Spark作业中的shuffle操作数量、RDD持久化操作数量以及spark web ui中显示的作业gc情况),
合理地设置上述参
3.一个奇葩的问题(待解决)
NoViableAltException(313@[192:1: tableName : (db= identifier DOT tab= identifier -> ^( TOK_TABNAME $db $tab) |tab= identifier -> ^( TOK_TABNAME $tab) );])
at org.antlr.runtime.DFA.noViableAlt(DFA.java:158)
at org.antlr.runtime.DFA.predict(DFA.java:144)
at org.apache.hadoop.hive.ql.parse.HiveParser_FromClauseParser.tableName(HiveParser_FromClauseParser.java:4747)
at org.apache.hadoop.hive.ql.parse.HiveParser.tableName(HiveParser.java:45918)
at org.apache.hadoop.hive.ql.parse.HiveParser_IdentifiersParser.tableOrPartition(HiveParser_IdentifiersParser.java:9653)
at org.apache.hadoop.hive.ql.parse.HiveParser.tableOrPartition(HiveParser.java:45845)
at org.apache.hadoop.hive.ql.parse.HiveParser.destination(HiveParser.java:44909)
at org.apache.hadoop.hive.ql.parse.HiveParser.insertClause(HiveParser.java:44189)
at org.apache.hadoop.hive.ql.parse.HiveParser.regularBody(HiveParser.java:41195)
at org.apache.hadoop.hive.ql.parse.HiveParser.queryStatementExpressionBody(HiveParser.java:40413)
at org.apache.hadoop.hive.ql.parse.HiveParser.queryStatementExpression(HiveParser.java:40283)
at org.apache.hadoop.hive.ql.parse.HiveParser.execStatement(HiveParser.java:1590)
at org.apache.hadoop.hive.ql.parse.HiveParser.statement(HiveParser.java:1109)
at org.apache.hadoop.hive.ql.parse.ParseDriver.parse(ParseDriver.java:202)
at org.apache.hadoop.hive.ql.parse.ParseDriver.parse(ParseDriver.java:166)
sql
https://issues.apache.org/jira/browse/SPARK-11972
sql_01 = '''
INSERT OVERWRITE TABLE '${v_aim_table_01}' PARTITION (
MONTH_ID,
PRVNCE_ID,
BATCH_NBR,
SEIAL_NBR,
LATN_ID
) SELECT
PROD_INST_ID,
UIM_CARD_TYPE_CD,
IMSI,
USER_3G_FLAG,
CARD_TYPE,
WIFI_FLAG,
RETRANS_NBR, -- `substr(input__file__name ,- 21, 2),` ?难道是这个?
from_unixtime(
unix_timestamp(),
'yyyy/MM/dd HH:mm:ss'
),
PRMRY_CARD_PROD_INST_ID,
trim(MONTH_ID),
PRVNCE_ID, -- `substr(input__file__name ,- 10, 3),`
BATCH_NBR, -- `substr(input__file__name, - 18, 3),`
SEIAL_NBR, -- `substr(input__file__name ,- 14, 3),`
TRIM(LATN_ID)
FROM
'${v_source_table_01}' A1
WHERE MONTH_ID = '${in_month_id}'
AND PRVNCE_ID = '${in_prov_id}' `; 坑爹的分号?`
'''
sql_01 = sql_01.replace('${in_month_id}', in_month_id).replace('${in_prov_id}', in_prov_id) \
.replace('${v_source_table_01}', v_source_table_01).replace('${v_aim_table_01}', v_aim_table_01)

4.未解决的问题
hive中直接执行sql语句可以,但是放在脚本里面报错。
INSERT OVERWRITE TABLE SJZL.DWD_PRD_IDRY_MONTH PARTITION (PROV_ID, MONTH_ID) SELECT LATN_ID, PRVNCE_ID AS STD_PRVNCE_CD, LATN_ID AS STD_LATN_CD, PROD_INST_ID, IDRY_APP_ID, IDRY_APP_NM, IDRY_APP_CATE_CD, EFF_DATE, EXP_DATE, IDRY_STATUS, RETRANS_NBR, SEIAL_NBR, BATCH_NBR, from_unixtime(unix_timestamp(), 'yyyy/MM/dd HH:mm:ss'), PRVNCE_ID, MONTH_ID FROM SJZL.DWS_PRD_IDRY_MONTH A1 WHERE MONTH_ID = '201902' AND PRVNCE_ID = '811'
Py4JJavaError: An error occurred while calling o41.sql.
: org.apache.spark.SparkException: Job aborted due to stage failure: Task 0 in stage 0.0 failed 4 times, most recent failure: Lost task 0.3 in stage 0.0 (TID 3, A5-402
-NF5280M4-2017-562.BIGDATA.CHINATELECOM.CN): org.apache.hadoop.fs.viewfs.NotInMountpointException: getDefaultReplication on empty path is invalid
at org.apache.hadoop.fs.viewfs.ViewFileSystem.getDefaultReplication(ViewFileSystem.java:593)
at org.apache.hadoop.hive.ql.io.orc.WriterImpl.getStream(WriterImpl.java:2103)
at org.apache.hadoop.hive.ql.io.orc.WriterImpl.flushStripe(WriterImpl.java:2120)
at org.apache.hadoop.hive.ql.io.orc.WriterImpl.checkMemory(WriterImpl.java:352)
at org.apache.hadoop.hive.ql.io.orc.MemoryManager.notifyWriters(MemoryManager.java:168)
at org.apache.hadoop.hive.ql.io.orc.MemoryManager.addedRow(MemoryManager.java:157)
at org.apache.hadoop.hive.ql.io.orc.WriterImpl.addRow(WriterImpl.java:2413)
at org.apache.hadoop.hive.ql.io.orc.OrcOutputFormat$OrcRecordWriter.write(OrcOutputFormat.java:86)
at org.apache.spark.sql.hive.execution.InsertIntoHiveTable$$anonfun$org$apache$spark$sql$hive$execution$InsertIntoHiveTable$$writeToFile$1$1.apply(InsertIntoHi
veTable.scala:113)
at org.apache.spark.sql.hive.execution.InsertIntoHiveTable$$anonfun$org$apache$spark$sql$hive$execution$InsertIntoHiveTable$$writeToFile$1$1.apply(InsertIntoHi
veTable.scala:104)
at scala.collection.Iterator$class.foreach(Iterator.scala:727)
at scala.collection.AbstractIterator.foreach(Iterator.scala:1157)
at org.apache.spark.sql.hive.execution.InsertIntoHiveTable.org$apache$spark$sql$hive$execution$InsertIntoHiveTable$$writeToFile$1(InsertIntoHiveTable.scala:104
)
at org.apache.spark.sql.hive.execution.InsertIntoHiveTable$$anonfun$saveAsHiveFile$3.apply(InsertIntoHiveTable.scala:84)
at org.apache.spark.sql.hive.execution.InsertIntoHiveTable$$anonfun$saveAsHiveFile$3.apply(InsertIntoHiveTable.scala:84)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:66)
at org.apache.spark.scheduler.Task.run(Task.scala:89)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:227)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615)
at java.lang.Thread.run(Thread.java:745)
Driver stacktrace:
at org.apache.spark.scheduler.DAGScheduler.org$apache$spark$scheduler$DAGScheduler$$failJobAndIndependentStages(DAGScheduler.scala:1431)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$abortStage$1.apply(DAGScheduler.scala:1419)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$abortStage$1.apply(DAGScheduler.scala:1418)
at scala.collection.mutable.ResizableArray$class.foreach(ResizableArray.scala:59)
at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:47)
at org.apache.spark.scheduler.DAGScheduler.abortStage(DAGScheduler.scala:1418)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$handleTaskSetFailed$1.apply(DAGScheduler.scala:799)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$handleTaskSetFailed$1.apply(DAGScheduler.scala:799)
at scala.Option.foreach(Option.scala:236)
at org.apache.spark.scheduler.DAGScheduler.handleTaskSetFailed(DAGScheduler.scala:799)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.doOnReceive(DAGScheduler.scala:1640)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:1599)