One-Stage Inpainting with Bilateral Attention and Pyramid Filling Block
论文链接:https://arxiv.org/abs/1912.08642
源码地址:https://github.com/KumapowerLIU/One-Stage-Inpainting-with-Bilateral-Attention-and-Pyramid-Filling-Block
1. 引言
这篇论文解决的问题是图像修复(Image inpainting): a task to generate the alternative structures and textures of plausible hypothesis for missing regions in corrupted input images.
早期的工作的思路是texture synthesis,但是这些方法没有集合语义信息,只是重建局部的纹理模式。近年来,基于深度学习的图像修复方法开始出现,早期的方法没能有效利用上下文信息, 因此,容易产生noise patterns和texture artifacts。
在这篇论文中,作者提出了一个双阶段的模型,训练分为两步(the first training is to recover meaningful structures and the second training is to generate textures)。其中,第一次是利用简单的U-net修复出目标的结构,在第一次训练中label没有纹理。第一次训练完成后,利用第一次训练的得到的参数进行第二次训练,第二次的label就是原图(有纹理),这样就能够在测试的时候节省很多时间。同时,在第二次训练时,加入了Bilateral Attention 和 Pyramid Filling Block 提升效果。
论文的贡献有三点:(1)提出了 bilateral attention layer,作用为 characterize the value and distance relationship between deep feature patches to ensure local correlation and long-term continuity. (2)提出了 pyramid filtering block,作用为 fill the hole regions of deep features progressively by using high-level contextual semantic features. (3)设计 training strategy,减少了测试阶段的 inference time。
2. 方法框架
2.1 总体架构
第一次训练的架构如下图所示。作者表示,这里使用了Image-to-image translation with conditional adversarial networks 中提到的网络架构,但是去掉了最后一层。
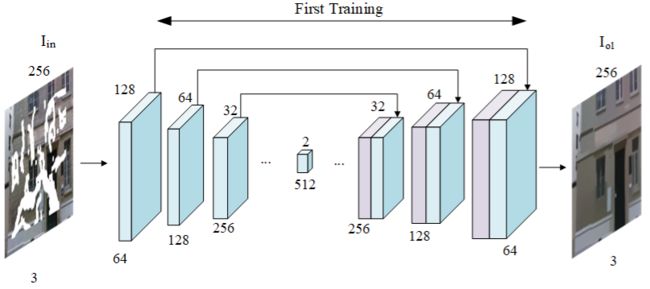
第二次训练的架构如下图所示。编码器和解码器使用的是第一次训练中得到的参数,同时,在这个网络中使用了 BA-layer,PF-block 和 SE-block。作用分别是:PF-block filled the feature maps from deep to shallow. SE-block optimizes the feature maps in the channel dimension, and the BA-layer reconstructs it in spatial dimension.

作者指出,论文最重要的部分是 attention 方法。
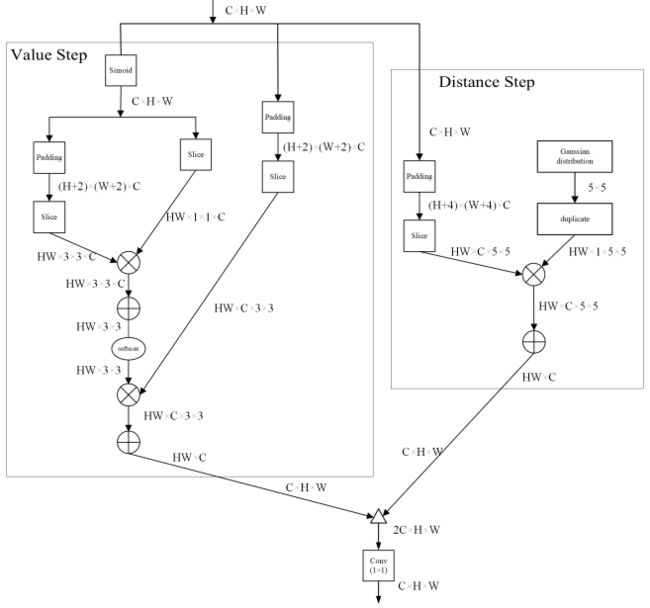
2.2 Bilateral attention
作者指出,受到传统双边滤波算法的启发,提出了从值和距离两个角度描述特征相似程度,类似于双边滤波。具体来说,具体来说,以当前的特征点为中心,计算其与周围8个点包括它自己的值的相似度(其实就是3×3的kernel),这里可以用点积来计算,并将这9个值分别乘以这些权重然后相加得到新的特征点。同时,我们以当前特征点为中心,利用高斯分布,来刻画其与周围24个点(5×5的kernel)的相似度,然后同样进行加权相加,得到新的特征点,最后这两个特征点拼接并降维得到最后的特征图,整体架构如下图所示:
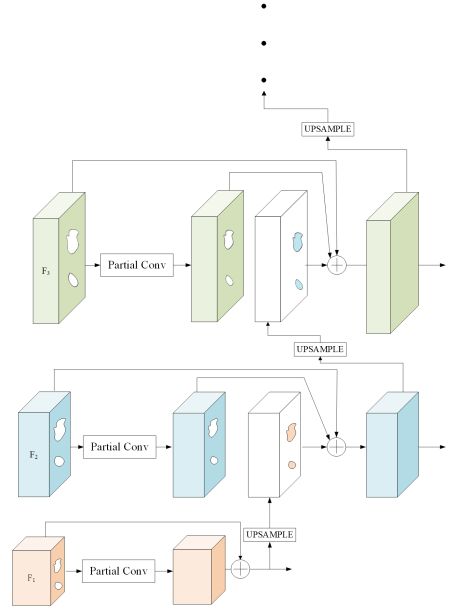
2.3 金字塔修复模块
在这个模块中,利用已经被填满的高级语义特征逐步填充浅层的特征,具体来说从高到低采用金字塔架构逐步填充特征,并把这些特征利用skip-connection的方式连接到decoder,同时我们采用short-cut的方式将原特征图与填充完的特征图进行连接,这是因为在经过第一次训练阶段之后,马赛克区域并不是完全无效的。
3. 效果与结论

从实验效果上来看,该算汉的效果优于当前主流方法。总结起来,论文工作为三方面:The bilateral attention layer ensures the local correlation and long-term continuity of feature patches. Meanwhile, the pyramid fill block helps our model fill void regions with high-level semantic information to achieve better predictions. Moreover, the one-stage architecture is effective in reducing the time.