文件操作命令 cp、mv、rm 底层原理
cp、mv、rm 命令到底做了什么?
何处望神州?满眼风光北固楼。千古兴亡多少事?悠悠。不尽长江滚滚流。
年少万兜鍪,坐断东南战未休。天下英雄谁敌手?曹刘。生子当如孙仲谋。
- cpmvrm 命令到底做了什么
- 缘起
- inode 结构
- 硬链接
- 符号链接
- unlink 命令
- rm 命令
- rename 命令
- mv 命令
- cp 命令
- 结语
缘起
在linux 系统中上线时经常会遇到需要替换原有可执行程序的操作,我通常的做法是:
- 删除原有可执行文件。例如:rm a.out
- 以相同的文件名把新的可执行文件放到原文件的位置:mv b.out a.out
- 重启服务。
一直以来都是如此操作的,也没有出现过什么问题。但是在操作过程中经常会战战兢兢,老觉得程序正在执行时,删除对应磁盘文件的操作是”釜底抽薪“,觉得正在运行的程序会崩溃,可是这种情形从来没有出现过。
直到有一天,我没有使用rm 命令,而是想用 cp 命令直接覆盖旧的可执行文件,得到了以下提示:
Text file busy而报这个错的原因是有进程正在使用这一文件。那为什么用 rm 命令删除正在运行的可执行文件可以成功而用cp 命令覆盖却不行呢?于是决定对 cp、rm、mv 等常用文件操作命令进行深入的解析,从而为后面的研究打下基础。
在下一篇中,我将详细阐述删除正在被使用的文件时,运行的程序为什么不会崩溃,以及替换可执行程序时为何 rm 会成功而 cp 会失败。
inode 结构
了解文件操作命令例如rm、mv、cp的底层原理时,需要先了解 linux 中文件系统的基本原理。
在linux 系统中,磁盘通常被格式化为 ext3 或 ext4 格式,这两种文件系统对文件的存储和访问是通过一种被称为 inode 即 i 节点的机制来实现的。对于 inode,在维基百科上有如下的解释:
“An inode stores all the information about a regular file, directory, or other file system object, except its data and name. ”
可见,每个文件都对应一个 i 节点,i 节点存储了除文件名和文件内容之外的所有信息。
除文件名和文件内容之外,一个文件还有哪些信息呢?其实这些额外的信息和文件的存储及读写方式有关。当我们读写文件时,通常是以流的形式,即认为文件的内容是连续的。但是在磁盘上,一个文件的内容通常是由多个固定大小的数据块即block构成的,并且这些数据块通常是不连续的。这时就需要一个额外的数据结构来保存各数据块的位置、数据块之间的顺序关系、文件大小、文件访问权限、文件的拥有者及修改时间等信息,即文件的元信息,而维护这些元信息的数据结构就被称为 i 结点。可以说,一个i 节点中包含了进程访问文件时所需要的所有信息。
由于一个文件的数据块是不连续的,属于同一文件的数据块可能遍布整个磁盘,因而可以认为 i 节点中含有一个帮助定位文件数据块的 “目录结构”。i 节点原理如下图所示(来自于网络,侵删):

可见,i节点中主要有两大部分,一部分是i 节点号与文件名的对应表,另一部分就是i 节点对应文件的元信息,其中的指针指向了磁盘上的构成文件的多个数据块。在图中可以看出,每个i 节点号对应一个文件。
由于i节点存储了文件的元信息,因而 i节点本身也是要占用磁盘空间的。 i 节点的内容独立于文件内容,这里有必要区分“更改文件本身”的内容和更改“文件对应的i节点” 的内容。当对文件执行写入、编辑后保存等更改文件内容的操作时,我们更改的是文件内容本身。而更改i节点信息通常有如下情形:
- 更改文件内容后,导致文件元信息发生了变化,例如文件的大小、文件的访问时间等,这时文件对应i 节点的信息也会发生变化。
- 文件的拥有者、访问权限发生了变化,例如对文件执行了 chown、chgrp、chmod 等命令。
因而,inode 内容发生了变化,对应的文件内容不一定发生了变化。
在 linux 系统中用 i 节点号来标识一个i 节点。 i 节点号是一个整数,在单个磁盘分区中是唯一的。linux 中挂载多个磁盘分区时,不同的分区中可能有相同的 i 节点号,本文只考虑单一的磁盘分区,因而认为 i 节点号是唯一的。
硬链接
一般情况下,一个文件名对应一个i 节点。但是linux 提供了一种共享 i 节点的方法——硬链接。例如对 data.txt 创建一个硬链接,之后查看 data.txt 的 i 节点的信息:

可见,这时有两个文件名链接到同一个i 节点上,这里的i 节点的链接数是2。可以认为,硬链接文件和原文件就是同一个文件,只不过有两个名字,类似于 C++ 中的引用。当一个文件有多个链接时,删除其中一个文件名并不会删除文件本身,而只是减少文件的链接数。当链接数为 0 时,文件内容才会真正被删除。
符号链接
除了硬链接,linux 系统还提供了一种符号链接。符号链接并不增加目标文件 i 节点的链接数。符号链接本身也是一个文件,其中存储了目标文件的完整路径,类似于windows系统中的快捷方式。符号链接与硬链接的另一个区别是符号链接可以对目录建立链接,而硬链接不能对目录建立链接。因为如果允许对目录建立硬链接,有可能形成链接环。符号链接的使用及属性如下:
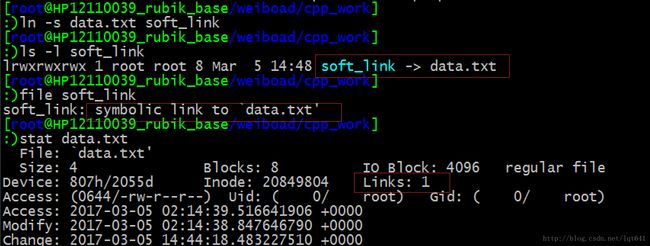
可见,符号链接并不增加 i 节点的链接数。
unlink 命令
unlink 命令的 man page 中说明其调用了 unlink(file) 系统调用,于是追根溯源,查看 unlink 系统调用的man page,得到了以下信息:
unlink() deletes a name from the filesystem. If that name was the last link to a file and no processes have the file open the file is deleted and the space it was using is made available
for reuse.
If the name was the last link to a file but any processes still have the file open the file will remain in existence until the last file descriptor referring to it is closed.
If the name referred to a symbolic link the link is removed.
If the name referred to a socket, fifo or device the name for it is removed but processes which have the object open may continue to use it.
可以看出,unlink 用于删除文件名。删除文件名是指在原目录下不再含有此文件名。要注意的是,这里的表述是删除文件名,并不一定删除磁盘上文件的内容。只有在文件的链接数为1,即当前文件名是文件的最后一个链接并且有没有进程打开此文件的时候,unlink() 才会真正删除文件内容。用 unlink 真正的删除一个文件内容,必须同时满足以上两个条件。
如果文件链接数为1,但是仍然有进程打开这一文件,那么 unlink 后,虽然在原目录中已经没有了被删除文件的名字,但是实际上系统还是保留了这一文件,直到打开这一文件的所有进程全部关闭此文件后,系统才会真正删除磁盘上的文件内容。由此可见,用unlink直接删除打开的文件是安全的。删除已经打开的文件,对使用此文件的进程,不会有任何影响,也不会导致进程崩溃(注意这里讨论的是删除已被打开的文件,通常是数据文件,并未讨论删除正在运行的可执行文件)。
对于符号链接,unlink 删除的是符号链接本身,而不是其指向的文件。
rm 命令
rm 命令也是删除文件。为了查看rm 与 unlink 的区别,用 strace 跟踪执行 rm 命令时使用的系统调用:
# strace rm data.txt 2>&1 | grep 'data.txt'
execve("/bin/rm", ["rm", "data.txt"], [/* 13 vars */]) = 0
lstat("data.txt", {st_mode=S_IFREG|0644, st_size=10, ...}) = 0
stat("data.txt", {st_mode=S_IFREG|0644, st_size=10, ...}) = 0
access("data.txt", W_OK) = 0
unlink("data.txt") = 0跟踪 unlink 命令的结果:
# strace unlink data.txt 2>&1 | grep 'data.txt'
execve("/bin/unlink", ["unlink", "data.txt"], [/* 13 vars */]) = 0
unlink("data.txt") 可以看出,在linux 中,rm 命令比 unlink 命令多了一些权限的检查,之后也是调用了 unlink() 系统调用。在文件允许删除的情况下,rm 命令和 unlink 命令其实是没有区别的。
rename 命令
rename 命令通常用于重命名文件,由于本文研究的是文件的移动和删除,因而只需关注 rename 最简单的使用方法:
# strace rename data.txt dest_file data.txt 2>&1 | egrep 'data.txt|dest_file'
execve("/usr/bin/rename", ["rename", "data.txt", "dest_file", "data.txt"], [/* 13 vars */]) = 0
rename("data.txt", "dest_file") = 0可以看出,rename 就是对 rename() 系统调用的封装。
查看 man page 可以看出,当目标文件已经存在时,在权限允许的情况下,rename() 会直接覆盖原来的文件。这里“覆盖原有文件”可能有两种情况:
- 将原文件清空后写入
- 删除了旧文件后新建一个同名文件
通过执行下面的命令可以区分出 rename() 执行的 “覆盖” 到底是哪一种情况:

可见,在目标文件 dest_file 已经存在的情况下,执行 rename 后,dest_file 的 i 节点号发生了变化,因而rename() 系统调用的作用类似于上述第二种情形:即删除文件后再新建一个同名文件。
mv 命令
mv 命令通常用于重命名文件。当目标文件不存在时,跟踪其执行过程:
# strace mv data.txt dest_file 2>&1 | egrep 'data.txt|dest_file'
execve("/bin/mv", ["mv", "data.txt", "dest_file"], [/* 13 vars */]) = 0
stat("dest_file", 0x7ffe1b4aab50) = -1 ENOENT (No such file or directory)
lstat("data.txt", {st_mode=S_IFREG|0644, st_size=726, ...}) = 0
lstat("dest_file", 0x7ffe1b4aa900) = -1 ENOENT (No such file or directory)
rename("data.txt", "dest_file") = 0当目标文件存在时:
# strace mv src_data data.txt 2>&1 | egrep 'src_data|data.txt'
execve("/bin/mv", ["mv", "src_data", "data.txt"], [/* 13 vars */]) = 0
stat("data.txt", {st_mode=S_IFREG|0644, st_size=726, ...}) = 0
lstat("src_data", {st_mode=S_IFREG|0644, st_size=726, ...}) = 0
lstat("data.txt", {st_mode=S_IFREG|0644, st_size=726, ...}) = 0
stat("data.txt", {st_mode=S_IFREG|0644, st_size=726, ...}) = 0
access("data.txt", W_OK) = 0
rename("src_data", "data.txt") = 0可以看出,mv 的主要功能就是检查初始文件和目标文件是否存在及是否有访问权限,之后执行 rename 系统调用,因而,当目标文件存在时,mv 的行为由 rename() 系统调用决定,即类似于删除文件后再重建一个同名文件。
cp 命令
对于cp 命令,当目标文件不存在时:
# strace cp data.txt dest_data 2>&1 | egrep 'data.txt|dest_data'
execve("/bin/cp", ["cp", "data.txt", "dest_data"], [/* 13 vars */]) = 0
stat("dest_data", 0x7fff135827f0) = -1 ENOENT (No such file or directory)
stat("data.txt", {st_mode=S_IFREG|0644, st_size=726, ...}) = 0
stat("dest_data", 0x7fff13582640) = -1 ENOENT (No such file or directory)
open("data.txt", O_RDONLY) = 3
open("dest_data", O_WRONLY|O_CREAT, 0100644) = 4当目标文件存在时:

可见,如果目标文件存在,在执行cp 命令之后,文件的 inode 号并没有改变,并且可以看出,cp 使用了 open 及O_TRUNC 参数打开了目标文件。因而当目标文件已经存在时,cp 命令实际是清空了目标文件内容,之后把新的内容写入目标文件。
结语
至此,我们已经了解了常用的文件操作命令的原理,特别需要关注的是 cp 命令。当目标文件存在时,cp 命令并不是先删除已经存在的目标文件,而是将原目标文件内容清空后再写入。了解这一点对下一篇研究 “覆盖使用中的文件” 将会非常有帮助。
本篇的主要目的是让读者了解 linux 下文件系统的组织方式及常用的操作文件命令的工作原理。有了本篇的知识后,我们就可以深入的研究 ”覆盖或删除正在被使用的文件“ 时操作系统的的行为了,也就能理解在用 cp 命令更新可执行文件时出现 ”Text file busy“ 的原因了。具体的内容,将会在下篇中说明。
我就是我,疾驰中的企鹅。
我就是我,不一样的焰火。
