卷积神经网络的Tensorboard可视化
(作者:陈玓玏)
一、Windows下使用Tensorboard的方法
Tensorboard是TensorFlow自带的可视化工具,因为想知道神经网络的中间环节到底是如何变化的,比如损失函数的变化过程、参数的分布、参数更新的过程、卷积核的样子等等,所以需要用到Tensorboard来帮助我。
这里先记录一下生成了logs文件后查看Tensorboard中图片的方法,再来说怎么产生logs。
在Windows下,打开cmd,cd到你生成logs文件的目录下,也就是包含logs文件的那个目录,在命令行中输入:
D:\CDL_code\moxingtansuo\dnn>tensorboard --logdir=logs
如果你没有cd到logs所在的目录,直接在等号右边写完整路径也是可以的。
结果如下:
我这里有很多warning,这个warning产生是因为我运行了很多次代码,产生了很多个log文件,不过也不用担心,Tensorboard会把不同日志中的结果画在一起,都是可以看到的。
我们复制提示的网址,我这里是http://DZG0370:6006,最好是谷歌浏览器中打开,最好是路径中不包含中文,否则都有可能看不到图片。
二、 卷积神经网络中使用Tensorboard实现可视化
这里使用的数据集是minist,手写数字。
import tensorflow as tf
import numpy as np
import pandas as pd
from tensorflow.examples.tutorials.mnist import input_data
#将权重初始化为非0值,通过设置stddev加入了一定的噪声,避免对称性及0梯度
def weight_variable(shape):
initial = tf.truncated_normal(shape, stddev=0.1)
return tf.Variable(initial)
#定义初始化偏置项的函数,将偏置项初始化为一个较小的正数,避免最终神经元输出恒为0
def bias_variable(shape):
initial = tf.constant(0.1, shape=shape)
return tf.Variable(initial)
#定义卷积层,strides定义步长为1,padding定义边距为0,输入和输出是同样大小的
def conv2d(x, W):
return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding='SAME')
#池化层采用2*2的池化
def max_pool_2x2(x):
return tf.nn.max_pool(x, ksize=[1, 2, 2, 1],
strides=[1, 2, 2, 1], padding='SAME')
#加载mnist数据集
mnist = input_data.read_data_sets("D:/Users/chendile/AppData/Local/Temp/pip-uninstall-ktrcfkmd/users/chendile/appdata/local/continuum/anaconda3/lib/site-packages/tensorflow/examples/tutorials/mnist/MNIST_data/",one_hot=True)
#print(pd.DataFrame(mnist))
# 1.定义数据。在神经网络里我们需要定义的数据就是输入训练/测试数据,而变量用来存储网络模型里的各种参数。
#定义的是输入输出层,输入层有784个节点,输出层有10个节点,因为数字手写体识别是十分类
#placeholder是一个占位符,希望输入任意数量的784维的向量
x = tf.placeholder( tf.float32, [None, 784] )
y_ = tf.placeholder( tf.float32, [None, 10] )
#初始化第一层卷积层的权重矩阵和偏置项,5和5表示一个过滤器的一层是一个5*5的矩阵,1表示输入的通道数,32表示输出的通道数
#也就是说,输出有32个过滤器
W_conv1 = weight_variable([5, 5, 1, 32])
b_conv1 = bias_variable([32])
#因为是卷积神经网络,输入的x不应当是向量,而是矩阵,因此需要把向量恢复成28*28大小的像素矩阵,最后一个1表示这张灰度图像的通道数是1
x_image = tf.reshape(x, [-1,28,28,1])
#输入reshape后的x,进行卷积操作,并通过relu激活函数
h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1)
h_pool1 = max_pool_2x2(h_conv1)
#第二层卷积和第二层池化,64个过滤器,每个过滤器有32层
W_conv2 = weight_variable([5, 5, 32, 64])
b_conv2 = bias_variable([64])
h_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2) + b_conv2)
h_pool2 = max_pool_2x2(h_conv2)
#开始全连接层,经过两层卷积、两层池化后,图片大小变为7*7,全连接层使用1024个神经元
W_fc1 = weight_variable([7 * 7 * 64, 1024])
b_fc1 = bias_variable([1024])
#重新把图片从矩阵变为向量,输入全连接层
h_pool2_flat = tf.reshape(h_pool2, [-1, 7*7*64])
h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, W_fc1) + b_fc1)
#placeholder定义一个dropout的概率
keep_prob = tf.placeholder("float")
h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob)
#最后一层是输出层,激活函数是softmax,适用于多分类问题
W_fc2 = weight_variable([1024, 10])
b_fc2 = bias_variable([10])
y_conv=tf.nn.softmax(tf.matmul(h_fc1_drop, W_fc2) + b_fc2)
#评估模型
cross_entropy = -tf.reduce_sum(y_*tf.log(y_conv))
train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)
correct_prediction = tf.equal(tf.argmax(y_conv,1), tf.argmax(y_,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))
sess = tf.InteractiveSession()
sess.run(tf.initialize_all_variables())
for i in range(2):
batch = mnist.train.next_batch(50)
if i%100 == 0:
train_accuracy = accuracy.eval(feed_dict={
x:batch[0], y_: batch[1], keep_prob: 1.0})
print("step %d, training accuracy %g"%(i, train_accuracy))
print(i)
train_step.run(feed_dict={x: batch[0], y_: batch[1], keep_prob: 0.5})
#==================================这里是重点了,开始可视化的部分了==============================
#有时候我可能自己对参数的维度也不是特别清楚,就会输出查看一下,下面两句print,是查看维度的两种方法
print(h_conv1)
print(len(sess.run(h_conv1,feed_dict={x: batch[0], y_: batch[1], keep_prob: 0.5})[0][0][0]))
#可视化都是要将变量或图片的信息写入summary,这里我获取的是最后一轮迭代的第一层卷积的输出结果
#h_conv1_f2是这一个summary图片的名称,第二个参数是图片的具体数值,我这里是先通过sess.run获取h_conv1的值,
#然后通过[0,:,:,1]切片,表示取batch中第一个样本的第2个通道的图像来显示,其实不进行reshape也可以的,切片后的结果就已经是[1,28,28,1]维度的了
#但一定要记得,image可视化中,你所获取的图片的维度必须是四维,且最后一维的值必须是1/3/4中的一个,
#最后一个参数限制了这个summary中能够展示的图片的张数
img_resize_summary = tf.summary.image('h_conv1_f2', tf.reshape(sess.run(h_conv1,feed_dict={x: batch[0], y_: batch[1], keep_prob: 0.5})[0,:,:,1], [1, 28, 28, 1]), 1)
#这里是展示第一个过滤器的权重可视化之后的结果
img_resize_summary = tf.summary.image('w1', tf.reshape(sess.run(W_conv1,feed_dict={x: batch[0], y_: batch[1], keep_prob: 0.5})[:,:,:,0], [1, 5, 5, 1]), 1)
#在session中执行计算及写入等操作
#输出到logs,方便在tensorboard中显示
with tf.Session() as sess:
#FileWriter的第一个参数为logs的路径,也是你之后查看图片是需要用到的
summary_writer = tf.summary.FileWriter('D:/CDL_code/moxingtansuo/FMmoxingchangshi/logs',sess.graph)
#获取summary
summary_all = sess.run(img_resize_summary)
summary_writer.add_summary(summary_all,0)
summary_writer.close()
print("test accuracy %g"%accuracy.eval(feed_dict={
x: mnist.test.images, y_: mnist.test.labels, keep_prob: 1.0}))
第一层卷积的第一个过滤器输出的结果:

第一层卷积的第二个过滤器输出的结果:
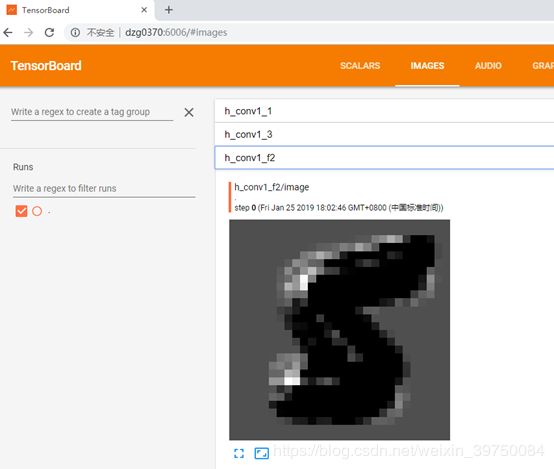
第一层卷积的第一个过滤器的权重:

三、 记录一个可能出现的Bug
Bug描述:Tensor must be 4-D with last dim 1, 3, or 4,bug
解决方案:我这里写的四维的最后一维是32,#因为输出图像的最后一个维度,也就是通道数必须是1/3/4,而我们的中间层通道数往往会比这几个数大很多,因此我们需要对中间层做一些切片处理,再写到summary
四、 参考资料
参考文章:https://blog.csdn.net/qq_40716944/article/details/80096302