python信用评分卡建模(附代码,博主录制)
https://study.163.com/course/introduction.htm?courseId=1005214003&utm_campaign=commission&utm_source=cp-400000000398149&utm_medium=share
参考https://blog.csdn.net/weixin_39445556/article/details/84502260
本章我们来学习L-BFGS算法.L-BFGS是机器学习中解决函数最优化问题比较常用的手段,本文主要包括以下六部分:
1-L-BFGS算法简介
2-牛顿法求根问题
3-牛顿法求函数的驻点
4-牛顿法求驻点的本质
5-BFGS算法
6-L-BFGS算法
1-L-BFGS算法简介
我们知道算法在计算机中运行的时候是需要很大的内存空间的.就像我们解决函数最优化问题常用的梯度下降,它背后的原理就是依据了泰勒一次展开式.泰勒展开式展开的次数越多,结果越精确,没有使用三阶四阶或者更高阶展开式的原因就是目前硬件内存不足以存储计算过程中演变出来更复杂体积更庞大的矩阵.L-BFGS算法翻译过来就是有限内存中进行BFGS算法,L是limited memory的意思.
那算法为什么叫BFGS呢,请看下图:

上图中从左到右依次是Broyden,Fletcher,Goldfarb,Shanno.四位数学家名字的首字母是BFGS,所以算法的名字就叫做BFGS算法.接下来我们就一起来学习BFGS算法的内容.
学习BFGS必须要先了解牛顿法的求根问题.
2-牛顿法求根问题
牛顿发现,一个函数的跟从物理的角度就可以根据函数图像迭代求得.牛顿法求根的思路是:
a.在X轴上随机一点,经过做X轴的垂线,得到垂线与函数图像的交点.
b.通过做函数的切线,得到切线与X轴的交点.
c.迭代a/b两步.
下面附上一张动图方便理解:

通过图片我们可以看到.在X轴上取的点会随着迭代次数的增加而越来越接近函数的根.经过无限多次的迭代,就等于函数的根.但牛顿法在实际应用的时候我们不会让算法就这么迭代下去,所以当和相同或者两个值的差小于一个阈值的时候,就是函数的根.
那么问题来了,怎么样找到的导函数与X轴的交点.请看下图:
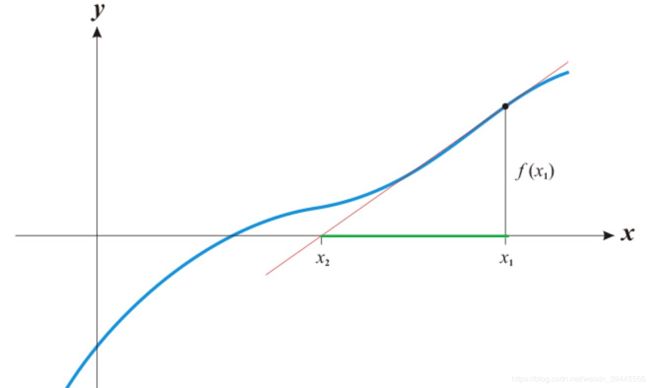
图片是上边动图从![]() 到
到![]() 的动作.可以看到,三角形绿色的直角边的值是
的动作.可以看到,三角形绿色的直角边的值是![]() -
- ![]() ,
, ![]() 是已知的(随机出来的),而且函数表达式
是已知的(随机出来的),而且函数表达式![]() 也是已知的(不知道要求的函数咱们折腾啥呢).所以三角形的另一条直角边
也是已知的(不知道要求的函数咱们折腾啥呢).所以三角形的另一条直角边![]() 也是已知的.根据导函数定义,函数
也是已知的.根据导函数定义,函数![]() 在
在![]() 点的导函数就是
点的导函数就是![]() (公式一).
(公式一).
公式一变换一下得到:(公式二 ),同理可以得出每一次迭代的表达式都是(公式三).
所以,根据牛顿法求根的思路,我们可以总结(模仿)一下使用牛顿法求根的步骤:
a.已知函数的情况下,随机产生点.
b.由已知的点按照的公式进行k次迭代.
c.如果与上一次的迭代结果相同或者相差结果小于一个阈值时,本次结果就是函数的根.
以上为牛顿法的求根的思路.
3-牛顿法求函数的驻点
我们知道,机器学习过程中的函数最优化问题,大部分优化的都是目标函数的导函数,我们要求得导函数为零时的点或近似点来作为机器学习算法表现最好的点.现在我们知道了牛顿求根法,那把牛顿求根法的函数换成咱们要优化的导函数不就行了么.要求的的导函数为零的点叫做驻点.所以用牛顿法求函数驻点同求函数的根是没有任何区别的.只是公式二中的变为了,原来的变成了一阶导函数的导函数也就是二阶导函数,求的迭代公式如下:
(公式四)
这样,我们通过几何直觉,得到了求解函数根的办法,那这么厉害的一个想法,有没有什么理论依据作为支撑呢?当然有了,要不我也不这么问.
4-牛顿法求驻点的本质
牛顿法求驻点的本质其实是二阶泰勒展开.我们来看二阶泰勒展开式:
是我们要求解的原函数的近似式.当我们要对原函数求解时,可以直接求得的导函数 令时的结果就是原函数的解.所以对求导,消去常数项后得到公式如下:
经过变换后所得的公式就是上边的公式四.所以,牛顿法求驻点的本质就是对函数进行二阶泰勒展开后变换所得到的结果.
在一元函数求解的问题中,我们可以很愉快的使用牛顿法求驻点,但我们知道,在机器学习的优化问题中,我们要优化的都是多元函数,所以x往往不是一个实数,而是一个向量.所以将牛顿求根法利用到机器学习中时,x是一个向量,也是一个向量,但是对求导以后得到的是一个矩阵,叫做Hessian矩阵.等价公式如下:
公式中,为公式四种的,代表二阶导函数的倒数.
当x的维度特别多的时候,我们想求得是非常困难的.而牛顿法求驻点又是一个迭代算法,所以这个困难我们还要面临无限多次,导致了牛顿法求驻点在机器学习中无法使用.有没有什么解决办法呢?请看博客开头的照片,四位数学家在向你微笑....
5-BFGS算法
BFGS算法是通过迭代来逼近的算法.逼近的方式如下:
(公式五)
公式五中的 就是.,. 是原函数的导函数.
的迭代公式复杂无比,还好我们不用记住它.BFGS是通过迭代来逼近矩阵,第一步的D矩阵是单位矩阵.
我们要通过牛顿求驻点法和BFGS算法来求得一个函数的根,两个算法都需要迭代,所以我们干脆让他俩一起迭代就好了.两个算法都是慢慢逼近函数根,所以经过k次迭代以后,所得到的解就是机器学习中目标函数导函数的根.这种两个算法共同迭代的计算方式,我们称之为On The Fly.个人翻译:让子弹飞~
回顾一下梯度下降的表达式 ,在BFGS算法迭代的第一步,单位矩阵与梯度g相乘,就等于梯度g,形式上同梯度下降的表达式是相同的.所以BFGS算法可以理解为从梯度下降逐步转换为牛顿法求函数解的一个算法.
虽然我们使用了BFGS算法来利用单位矩阵逐步逼近H矩阵,但是每次计算的时候都要存储D矩阵,D矩阵有多大呢.假设我们的数据集有十万个维度(不算特别大),那么每次迭代所要存储D矩阵的结果是74.5GB.我们无法保存如此巨大的矩阵内容,如何解决呢?
使用L-BFGS算法.
6-L-BFGS算法:
我们每一次对D矩阵的迭代,都是通过迭代计算和得到的.既然存不下D矩阵,那么我们存储下所有的和,想要得到就用单位矩阵同存储下的和到和计算就可以了.这样一个时间换空间的办法可以让我们在数据集有10000个维度的情况下,由存储10000 x 10000的矩阵变为了存储十个1 x 10000的10个向量,有效节省了内存空间.
但是,仅仅是这样还是不够的,因为当迭代次数非常大的时候,我们的内存同样存不下.这个时候只能丢掉一些存不下的数据.假设我们设置的存储向量数为100,当s和y迭代超过100时,就会扔掉第一个s和y,存储到和到,每多一次迭代就对应的扔掉最前边的s和y.这样虽然损失了精度,但确可以保证使用有限的内存将函数的解通过BFGS算法求得到.
所以L-BFGS算法可以理解为对BFGS算法的又一次近似..
到这里,L-BFGS算法的逻辑和由来就已经讲解完毕了文章中唯一没有讲到的地方就是BFGS算法的推导过程,因为推导过程比较长而且不是我们学习的重点.如果大家有兴趣的话可以去百度BFGS算法推导过程.
python风控建模实战lendingClub(博主录制,catboost,lightgbm建模,2K超清分辨率)
https://study.163.com/course/courseMain.htm?courseId=1005988013&share=2&shareId=400000000398149

微信扫二维码,免费学习更多python资源
