PostgreSQL四类窗口函数总结
postgresql的窗口函数和Hive的hql基本一致,利用窗口函数能够解决绝大部分的常用业务数据分析需求。
先总结:
常用的4类窗口函数:
- 用于聚合计算的窗口函数:sum() over(); count() over(); avg() over;
- 用于分组排序的窗口函数:row_number() over(); rank() over(); dense_rank() over()
- 用于分组查询的窗口函数:ntile() over()
- 用于偏移分析的窗口函数:lag() over();lead() over();first_value() last_value()
---------------------------------------------------------------------------------------------------------------------------------------
一、聚合计算的窗口函数
1.1 sum() over()函数
订单表 t_order 源数据:

select *,sum(order_num) over(partition by region order by create_time) from t_order
在每个region内,根据create_time顺序,对amount进行累加。
高频使用。
1.2 count() over()函数
select *,count(order_num) over(partition by region order by create_time) from t_order将上面的案例的sum做一下修改调整
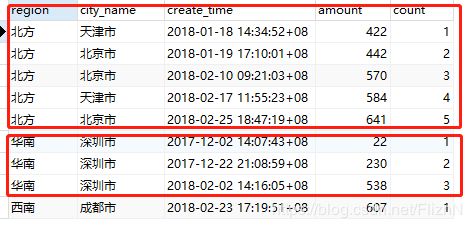
计算函数由sum改成了count,由向下累加改成了向下计数。类似于row_number(),低频使用。
==》avg() over() 函数同理;省略
二、分组排序的窗口函数
2.1 row_numer() over() 函数
select *,row_number() over(partition by region order by create_time) from t_order
select *,row_number() over(partition by region||city_name order by create_time) from t_order
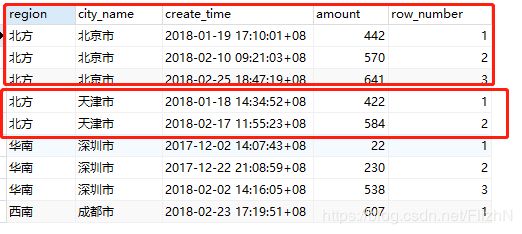
row_number()的作用是对数据进行排序。
第一个查询,在region分区里面,根据create_time对每个数据进行排序。
第二个查询,在region和city_name分区里面,根据create_time对每个数据进行排序。
2.2 rank() over() 函数
select *,row_number() over(partition by region order by city_name) from t_order
select *,rank() over(partition by region order by city_name) from t_order将排序改成城市排序,因为有部分城市有多个订单记录:
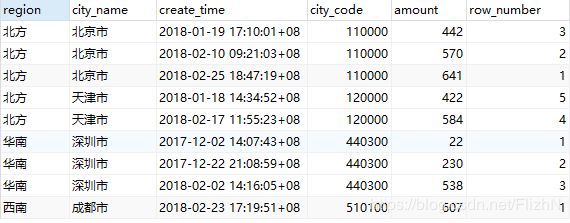

第一个查询,row_number() 排序时city_name相同排名不一样,继续向下排序,不留空位。(高频使用)
第二个查询,rank() 排序时city_name相同的排名一样,下一级排名留空。(低频使用)
第三个查询,dense_rank() 排序时city_name相同的排名一样,下一级排名不留空。
三、分组查询的窗口函数
3.1 ntile() over() 函数
select *
,ntile(5) over(order by create_time)
,ntile(2) over(partition by region order by create_time)
from t_order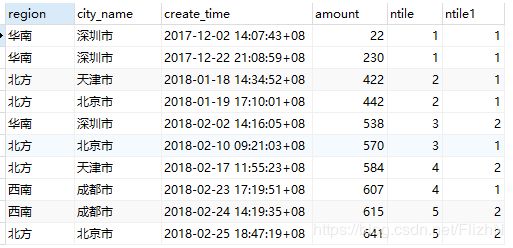
第一个分组,根据create_time顺序,将数据分成5等份
第二个分组,在每个region内,根据create_time顺序,将数据分成2等份
四、偏移分析的窗口函数
4.1 lag() over() 函数
select *
,lag(create_time,1,0) over(order by create_time )
,lag(create_time,1,0) over(order by create_time desc)
,lag(create_time,1,0) over(partition by region order by create_time )
,lag(create_time,1,0) over(partition by region order by create_time desc)
from t_order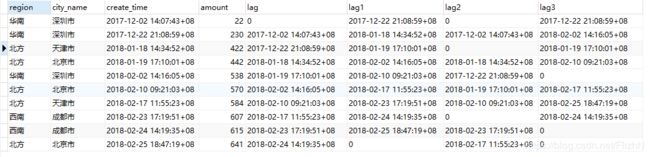
lag(exp_str,offset,defval) over(partion by ..order by …)
exp_str:字段名;offset:偏移量;defval:默认值
第一个查询:根据create_time顺序,获取create_time的上一条数据,空的数据用0补充。
第二个查询:在每个region内,根据create_time顺序,获取create_time的上一条数据,空的数据用0补充。
4.2 lead() over() 函数
select *
,lead(create_time,1,0) over(order by create_time )
,lead(create_time,1,0) over(order by create_time desc)
,lead(create_time,1,0) over(partition by region order by create_time )
,lead(create_time,1,0) over(partition by region order by create_time desc)
from t_order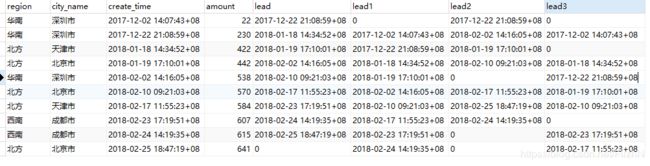
第一个查询:根据create_time顺序,获取create_time的下一条数据,空的数据用0补充。
第二个查询:在每个region内,根据create_time顺序,获取create_time的下一条数据,空的数据用0补充。
第三个查询:first_value()
取分组内排序后,截止到当前行,第一个值.
如果不指定ORDER BY,则默认按照记录在文件中的偏移量进行排序,会出现错误的结果
--------------------------------------------------------------------------------------------------------------------
窗口函数其他说明
1、在所有的SQL处理中,窗口函数都是最后一步执行,而且仅位于Order by字句之前。
2、当同一个select查询中存在多个窗口函数时,他们相互之间是没有影响的。
3、如果只使用partition by子句,未指定order by的话,我们的聚合是分组内的聚合。
4、order by子句会让输入的数据强制排序。