MicrosoftAsia-Semantics-Aligned Representation Learning for Person Re-identification---论文阅读笔记和工程实现总结
给我一瓶酒,再给我一支烟,说code就code, 我没的是时间
杜绝白嫖,点赞再看
各位看官老爷,欢迎就坐观看。
博主Github链接:https://github.com/wencoast
摘要
一句话,同样是表达学习,但是他这里能满足在Re-ID任务中语义对齐。
In this paper, we propose a framework that drives the re-ID network to learn semantics-aligned feature representation through delicate supervision designs
提出了一个框架,一个驱动reID 网络学习语义对齐的feature representation through 精细的监督设计。
build a Semantics Aligning Network (SAN)(怎么实现的,让这个网络就是语义对齐的网络呢?) which consists of a base network as encoder (SA-Enc 语义对齐Enc) for re-ID[For re-ID的语义对齐编码器], and a decoder (SA-Dec) for reconstructing or regressing the densely semantics aligned full texture image [语义对齐解码器, 来重构和回归密集语义对齐的全纹理图像full texture image]
说明这个总的语义对齐网络是由语义对齐的编码器和语义对齐的解码器组成的。编码器和解码器各有分工,怎么分工的呢?
以解决person re-identification的目地作为监督信号和对齐的texture generation作为监督信号,也就是under the supervision of person re-identification and aligned texture generation.
在解码器中,除了重构 reconstruction loss, 我们添加Triplet ReID constraints over the feature maps as the perceptual losses (作为感知loss). 在inference阶段,解码器被discard, 从而实现了计算上更有效。消融研究确定了他们设计的有效性。
主要挑战在于
large variation in
- human pose
- capturing view points
- incompleteness of the bodies(due to occlusion)
而这些问题都会result in semantics misalignment across 2D images
什么是全纹理图像?
什么是纹理图像呢?
A texture image on the UV coordinate system represents the aligned full texture of the 3D surface of the person. 意思,在uv空间内获得的纹理图像表达人的3D surface的对齐的全纹理。 (因为人有通用的3D model) . 此外,Besides, a texture image contains all the texture of the full 3D surface pf a person.
不管来自哪个人,UV空间里纹理图像的纹理信息是对齐的。
Note that the texture images across different persons are densely semantically aligned. Dense Pose就是用来从person images获得dense semantics的. 合着本文用到的纹理图像是用DensePose获得的?
值得注意的是:用aligned texture image 来合成 person image of another pose or view不是MicrosoftAsia的创新点,这个工作是由FaceBook AI Research和Wang et al. 2019年时候做的。
- 对于不同的人的input images, the corresponding texture images are well semantics aligned.
- 在不同的texture image的相同空间位置上,语义是一样的。
- The person images with different visible semantics/regions, their texture images are semantics consistent/aligned since each one contains the ful texture/information of the 3D person surface
在本文中,学到的特征表达,在本质上就是语义对齐的。
为什么要用纹理图像?
- As the person identity is mainly characterized by textures.
因为person identity 主要用texture来特定化,因为3D human model的话,对于人而言,是有通用模型的。而另外的话,对于人的动作和姿态,大家都会做出那些动作和姿态。最大的区别就是在于外观上的纹理了,所以我觉得texture应该隶属于appearance. - Texture images for different persons/viewpoints/poses are densely semantically aligned, as illustrated in the following Figure.
- 对于不同person的输入图像,the corresponding texture image却是well semantics aligned.
- 首先,对于在不同texture image的相同空间位置,the semantics are the same. 该代表胳膊的地方都代表胳膊,该代表腿的地方都代表腿。
- 其次, for person images with different visible semantics/regions, 对于具有不同区域或者不同语义的行人图像,比如有的含完整上半身,有另外一张却只含上半身不含脑袋,就算是这,他们的texture image也是语义对齐的,since each one contains the full texure/information of the 3D person surface.
这不代表我那个就是包含full texture information of the 3D person surface的吧, 因为他们这个纹理图像确实很全面的,感觉是个360度。
他们也是把原图作为输入,但是他们用的模型SAN是在合成数据集上面训练过的, 然后这个模型被用于来生成pseudo ground-truth texture image.
那么问题就来了,如何在我目前的基础上,来得到full texture information of the 3D person surface?

我自己生成的是64×64,然后作者开源的是256×256的。

首先,纹理图像是产生于3D human surface, 而3D human surface又要依托于专门基于表面的坐标系,也就是UV space.

3D human surface上的each position (u,v) 会在texture image上有unique semantic identity具有唯一语义标识,例如在texture image右下角的
像素对应的是some semantics of a hand.
此外,一个texture image 包含 all the texture of the full 3D surface of a person. 然而一个普通的2D person image只有一部分the surface texture.
意思,texture是个360度,而普通2D person image只是某个视角,是这个意思么?
the full 3D surface of a person, 这块这个full具体什么意思?可以问问cena

如何做的Pseudo Groundtruth Texture Images Generation?
最奇怪的是: 明明只是由single image获得的texture image,作者们怎么把这个称为Pseudo Groundtruth Texture Images呢?
For any given input person image, we use a simplified SAN (i.e., SAN-PG) which consists of the SA-Enc and SA-Dec, but with only the reconstruction loss. 这个reconstruction loss是不是只有encoder-decoder里才有的呢?
是用的别的作者发布的本来3D scanned的纹理数据集 (SURREAL),再自己放上原input image, 合成一个a Paired Image Texture dataset (PIT)
什么是语义对不齐(Semantic Misalignment)?

- Spatial semantics misalignment 这个意思,虽然视角差不多,但是不同图像相同位置却对应着人体不同的语义(其实就是本质上是什么什么玩意?相对人而言,就是腿,肚子,胳膊什么的)。
比如一个是腿,另一个却是腹部。- Inconsistency of visible body regions/semantics 可以见到的语义都不一样,比如: 一个看到的是front side的腿,而另一个却是后面的腿。虽然都是腿,但是本质上语义压根不一样,一前一后的。从英文上看的话,意思一前一后of a person, 这样的话语义就是不一致的。
Alignment
- Explicitly exploit human pose/landmark information (body part alignment) 但是body part alignment is coarse.
而且在部分内within parts 仍然是对不齐的。
There is still spatial misalignment within the parts. - Based on estimated dense semantics (什么意思?能估计到具体的对应人体什么属性?)
语义对齐的好处:
To achieve fine-granularity spatial alignment (实现精细粒度的空间对齐)
语义对齐的最早工作是来自Guler, Neverova的2018那篇么?
Densely Semantically Aligned Person Re-Identification(CVPR2019)这篇的话
思想是把原来语义上对不齐的图像,wrap到规范的UV坐标系,然后这样就获得了语义对齐的图像,意思是先获得语义对齐的图像,然后把这些densely semantics aligned images作为输入, 再开展进一步的ReID任务?
但CVPR2019这篇还有问题,问题是:
the invisible body regions result in many holes in the warped images and thus the inconsistency of
visible body regions across images,尚且还存在dense semantics misalignment的问题。
Our work
引入了一个对齐的纹理生成子任务,aligned texture generation subtask, 然后在此基础上,with densely semantics aligned texture image 用的是不同于CVPR2019的, 这个多在texture上,这里是densely semantics aligned texture image.
-
Encoder
SA-Enc can be any baseline network used for person reID.
用于获得feature map of size h × w × c h\times w \times c h×w×c 然后的话,应该会再拉成一维的。
等下,应该是在拉成1D以前,先池化,在feature map上做average pool会得到the reID feature.
然后应该是在获得这个reID feature后后面跟着reID losses.为鼓励SA-Enc来learn semantically aligned features, 本文引入SA-Dec并对SA-Dec做些设置.
要求用SA-Dec在pseudo ground-truth supervision下来regress/generate the densely semantically aligned full texture image(为了简化,有时候叫texture image).
可见,这些semantics aligned texture image是由SA-Dec生成的. 然后的话,用的是合成的数据集来进行texture image generation的.怎么就引入和设置后就能实现语义对齐呢?
因为的是: empowering the encoded feature map with aligned full texture generation capability。 感觉是先通过编码器获得reID feature, 然后通过Decoder在解码的时候赋予上它对齐的纹理生成。
语义对齐约束被引入是因为赋予编码后的特征图以对齐的完整纹理生成,感觉是因为纹理生成的这个对齐性才对齐的呢
看来如何获得这个纹理生成应该很重要。也就是看SA-Dec怎么工作。
-
Decoder For generating densely semantically aligned full texture image with supervision.
At the SA-Dec, besides the reconstruction loss, Triplet ReID constraints over the feature maps as the perceptual metric.
之前那是reID loss这块这是reconstruction loss和Triplet ReID constraints. -
ReID 数据集本身没groundtruth aligned texture image, Generating pseudo groundtruth texture images by leveraging synthesized data with person image and aligned texture image pairs(这块这个对齐的纹理图像对哪来的呢?).
之所以能这么干的原因,都是因为:Figure4, 即一个Texture image和一个3D mesh(person image)再加上background, 再利用上合适的rendering参数, 就生成synthesized person image 此时没涉及解码器,所以,应该生成的这个带纹理的person image应该还不是语义对齐的。
Related Work
- Semantics Aligned Human Texture
A human body could be represented by a 3D mesh(例如SMPL)和a texture image as illustrated in the following figure. 就像下面这个图显示的一样,给定一个texture image,然后再加一个3D mesh, 就能通过rendering获得那个人的person image.


- 注意到: 没说,2D图像上的每一个点都有semantic identity, 而是说,3D mesh上的每个点都有唯一的semantic identity(这种唯一的标识使用UV空间里的(uv)坐标来表示的。)
3. The Semantic Alignment Network
在这个网络里把,in which densely semantically aligned full texture images are taken as supervision to drive the learning of semantics aligned features.
怎么做到的,怎么把另外一种信息用进来,并且作为监督的?
- 怎么用进来?
单独地先生成texture image的文件夹,然后把它里面的纹理图像通过下面的代码读入进来。
img = read_image(img_path)
img_texture = read_image(img_path.replace('images_labeled', 'texture_cuhk03_labeled'))
然后读进来以后,怎么再给网络用呢?用下面的代码:
def __getitem__(self, index):
return img, pid, camid, img_path, img_texture
到这一步,已经进来了。接下来看看到底怎么来作为监督信号被使用的?
下面这个图就是框架图,由一个为ReID编码的编码器,编码器说白了就是一个network(encoder for ReID), 然后还有一个decoder sub-network, 有了这个SA-Dec才generating densely semantically aligned full texture with supervision. 啥意思? 真正把texture image作为监督是通过SA-Dec实现的,对么?
model = models.init_model(name=args.arch, num_classes=dm.num_train_pids, loss={'xent', 'htri'})
这是把在ImageNet上面预训练的Resnet50(且FC512)作为architecture.

注意看到这里的loss
loss={set:2}{'htri','xent'}
num_classes={int}767 # 这是和xent结合使用的。
Encoder和Decoder怎么工作?
在Decoder部分,channel数量在逐渐减少,从2048的input_channel到final_channel的16,然后2D内的size在不断地增大。
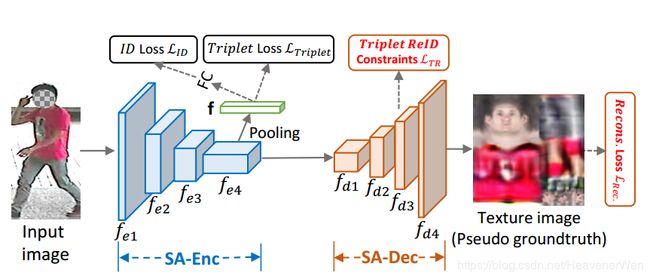
从这个图也可以看出来,REID的特征向量f和网络的FC不是一个玩意。FC才接ID loss, 然后之前的f直接接上Triplet loss, 为啥要接这个Triplet loss? 这里面这个Triplet loss在这怎么工作?
Encoder怎么工作?
好了,这个input image输入进来后,通过Encoder for ReID----编码器for ReID其实就是得到REID的feature vector能够在pooling后(更具体的是:对encoder的最后一层的feature map进行average pooling)得到这个ReID用的feature vector,疑问在于:那么的话,REID这个feature vector和FC是一个东西么? 应该不是吧? 然后的话,这个监督网络参数是用的ReID loss, 说白了就是cross entropy.

回答上面自己的疑问,感觉应该不是一个东西,因为:
保存在self.global_avgpool和保存在self.fc里的显然是两个不一样的东西
那这块这个Triplet Loss 的作用呢? 就是the ranking loss of triplet loss with batch hard miniing.
Decoder怎么工作?
注意看的Loss就是: L R e c L_{Rec} LRec

A decoder 形成以密集语义对齐的全纹理图像进行的监督。
然后就是解码器,解码器紧接着被添加(接着the last layer of the SA-Enc),就是为了在伪groundtruth texture image的约束下,让SA-Dec来重构或者回归出densely semantically aligned full texture image(这么看的话,好像再回归出来的长成另外一个样子,然后的话,回头可以打印出来显示下). 这相当于是用cuhk03的伪groundtruth texture image来做监督学习,比着样子学出来的感觉。
我们可以看出,作者专门为这个decoder工作部分写了个Class
输入咋就是2048么? 不是说紧紧地接着the last layer of the SA-Enc么?而last layer不是应该为512嘛?
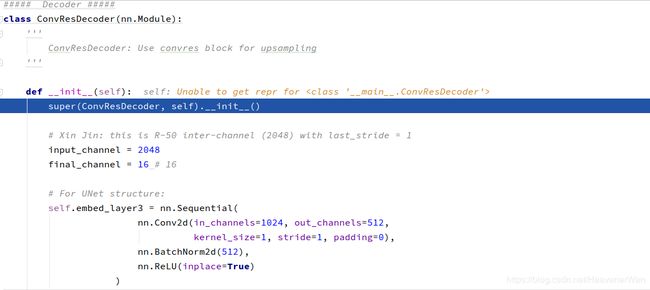
而且是先有一个UNet structure:(难道说的意思是:decoder的架构用U-Net而不是ResNet?)

紧接着还有如下别的类似的描述网络结构的东西:
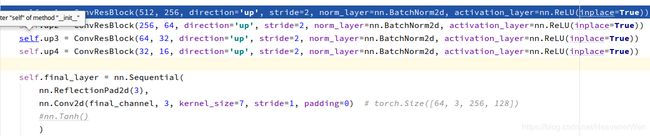
我们可以看到,
这块还有个Triplet , 之前那个叫Triplet Loss,然而这个叫做Triplet ReID Constraints ( L T R L_{TR} LTR).
In the SA-Dec, Triplet REID constraints are further incorporated at different layers/blocks as the high level perceptual metric to encourage identity preserving reconstruction
因为它是高级的perceptual metric,得以确保更加保持identity的重构。一样的尽可能近,不一样的尽可能远。
可以认为这是Encoder和decoder里的那个重构loss。 会进一步影响到重构出来的东西的好坏。
作为鼓励保留身份重建的高级感知指标
====
这块Triplet ReID Constraints的作用是让每个identity的,也就是自己和自己的更近,自己和别人的更远,从而达到自己的真是自己,也就是说是保持identity的reconstruction. 保identity的reconstruction. 然后这块这个Reconstruction loss也就是其实就是minimize L1 differences between the generated texture image(应该是带人的,而不是那个恶心的texture image) and its corresponding(pseudo groundtruth texture images)
然后的话,这块在解码器这还有个loss, 是为了让编码器继承让不同的identity更可分
是什么意思? 用这个loss来最小化同类特征的L2 difference然后最大化不同类的特征的差异。
生成的纹理过程。
工程实现
dm = ImageDataManager(use_gpu, **image_dataset_kwargs(args)) # dm是数据管理器。
dm = ImageDataManager(use_gpu, **image_dataset_kwargs(args))
image_dataset_kwargs是为ImageDataManager服务的一个函数,而ImageDataManager是data_manager.py里面定义的一个类。这就得看这个类以什么作为输入,并且以什么作为输出了。
class ImageDataManager(BaseDataManager):
"""
Image-ReID data manager
"""
更加具体的:
class ImageDataManager(BaseDataManager):
"""
Image-ReID data manager
"""
def __init__(self,
use_gpu,
source_names,
target_names,
root,
split_id=0,
height=256,
width=128,
train_batch_size=32,
test_batch_size=100,
workers=4,
train_sampler='',
num_instances=4, # number of instances per identity (for RandomIdentitySampler)
cuhk03_labeled=False, # use cuhk03's labeled or detected images
cuhk03_classic_split=False # use cuhk03's classic split or 767/700 split
):
在深入ImageDataManager之前,先康康image_dataset_kwargs函数。
def image_dataset_kwargs(parsed_args):
"""
Build kwargs for ImageDataManager in data_manager.py from
the parsed command-line arguments.
"""
return {
'source_names': parsed_args.source_names, # {list:1}['cuhk03'] 意思只处理cuhk03一个数据集
'target_names': parsed_args.target_names, # {list:1}['cuhk03'] 意思处理哪个就将其对应保存出来。所以还是cuhk03.
'root': parsed_args.root, # {str}'/project/snow_datasets/Re_ID_datasets/data' 这是存放cuhk03及其他数据集的上一级目录。
'split_id': parsed_args.split_id, # 0 split index (note: 0-based) 从0开始的split index 具体在哪里其作用呢?
'height': parsed_args.height, # 256 这是什么的尺寸? 图像的默认高度
'width': parsed_args.width, # 128 图像的默认宽度,但是re-id数据都不是这些尺寸啊
'train_batch_size': parsed_args.train_batch_size, # 4
'test_batch_size': parsed_args.test_batch_size, # 4
'workers': parsed_args.workers, # 4
'train_sampler': parsed_args.train_sampler, # 'RandomIdentitySampler' 好像是往出选identity而不是identity确定后随机选样本
'num_instances': parsed_args.num_instances, # 4 number of instances per identity (for RandomIdentitySampler)
'cuhk03_labeled': parsed_args.cuhk03_labeled, # True
'cuhk03_classic_split': parsed_args.cuhk03_classic_split # True 但是Lan他们的项目里用的是new split protocal(767/700)
}
# 这个函数的输入是解析出的args. 实参就是main.py里的args.
# 这个函数的输出是:将解析出的args某些key和value返回出来。
==后来我把--cuhk03_classsic_split给删除掉了, 然后再次传给**kwargs的时候就相当于里面的cuhk03_classsic_split=False. image_dataset_kwargs这个函数里面的return里面的项决定了kwargs的实际的可变长度。==
模型上的每个点,哪个点是可见的,并且对应
模型到这一步,只要能通过模型得到densepose.
先用CUHK03(labeled)
数据集统计:
- 分割方式:
767/700 - 涉及identity数目:
843+440+77+58+49第一个到第五个摄像机组的所有数据都用上
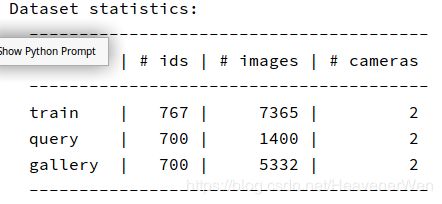
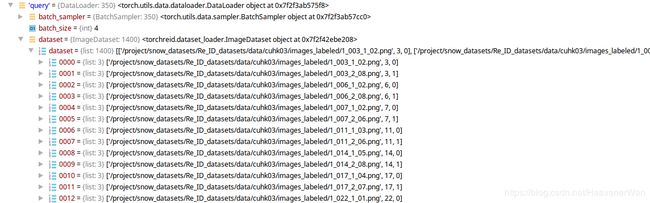
query={list:1400}
{要查找的}list里面的每个元素都是一个image, 然后格式如下:['/project/snow_datasets/Re_ID_datasets/data/cuhk03/images_labeled/1_003_1_01.png', 3, 0]
文件名的命名规则:
第一个数字:代表拍摄的摄像机组的编号,这意思是第一组
第二个由三个数组成的数据: 代表identity的编号,因为每个摄像机组获得的identity都不会超过843,所以三位数就够了。
第三个数字:代表摄像机组里的1号相机或者2号相机
第四个数字:代表这个人的第多少张图像,最多10张(从1到10).
————————————————
版权声明:本文为CSDN博主「贝勒的杭盖VanDebiao」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/HeavenerWen/article/details/106248257
剩下的3和0的意义:
3应该代表的是那个摄像机组下更具体的Identity的编号。 刚好和1_003_1_01.png里面的3是一个玩意。
0应该代表0方向还是1方向,因为每个组里有2个相机。0可以认为是拍侧向的那个相机,1可以认为是拍背面那个相机。
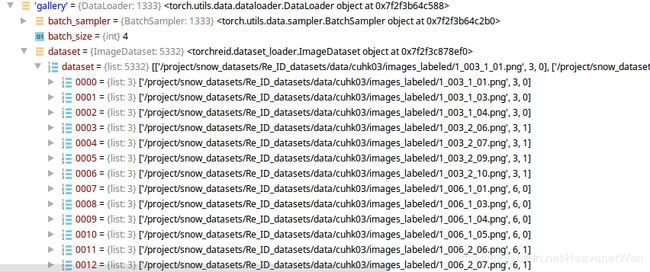
gallery={list:5332}
{所有的}list里面的每个元素都是一个image,

![]()
从这个Query集合的例子可以看出的是:在这里的Query集里,每个identity共有2个图像,分别来自0号和1号相机,也就是一个侧向和一个背向。而且怎么感觉都是第二张和第八张?是为了保障两个方向的样本都能被取到而作为query样本么?

num_gallery_cams={int}2
num_query_cams={int}2
num_train_cams={int}2

这块有一堆json,这些json是根据程序和用的数据集自动生成的,如果换成别的数据库的话,不知道还能不能正常生成。
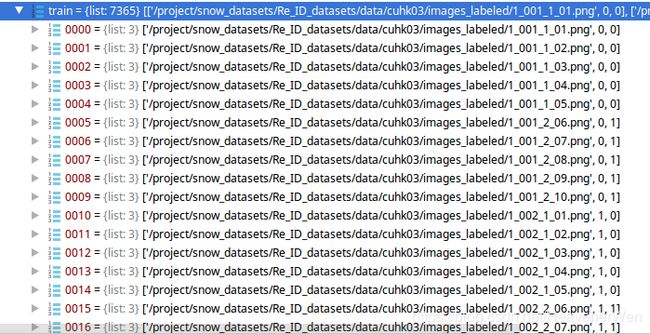
看看训练图像的这个格式,我们知道训练的identities是767个,这767个身份类别在测试时候都是没见过的。
1. ['/project/snow_datasets/Re_ID_datasets/data/cuhk03/images_labeled/1_001_1_01.png', 0, 0]
2. ['/project/snow_datasets/Re_ID_datasets/data/cuhk03/images_labeled/1_001_2_06.png', 0, 1]
3. ['/project/snow_datasets/Re_ID_datasets/data/cuhk03/images_labeled/1_002_1_01.png', 1, 0]
4. ['/project/snow_datasets/Re_ID_datasets/data/cuhk03/images_labeled/1_002_2_06.png', 1, 1]
5. ['/project/snow_datasets/Re_ID_datasets/data/cuhk03/images_labeled/1_004_1_01.png', 2, 0]
6. ['/project/snow_datasets/Re_ID_datasets/data/cuhk03/images_labeled/1_004_2_06.png', 2, 1]
# 这次的话,第二个item代表的应该是:767个ids的从0到766的label. **没错的,我检查过了,确实是0到766**
# 然后的话,第三个item代表的应该是: 0侧向摄像头还是1背向摄像头。
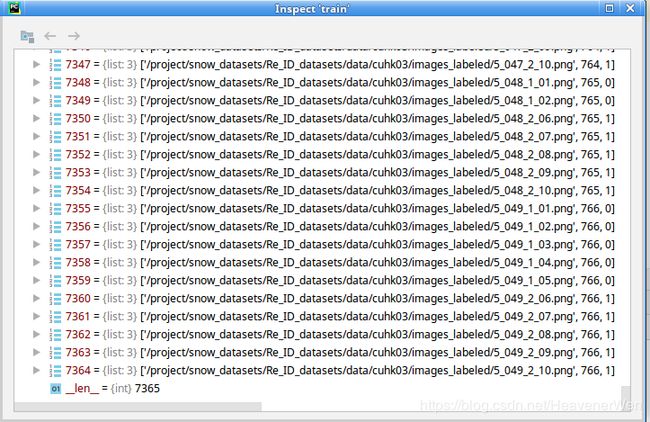
可以看出来,在他们这种测试协议下,5个摄像头组的数据都用到了。
pid += self._num_train_pids
pid = pid + self._num_train_pids = 0 + 0
= 1 + 0
= 2 + 0
# 查看self发现num_train_pids等于0.
然后我们看到了,在运行到self._num_train_cams += dataset.num_train_cams这句话的时候吧,我们知道,最后的self.train就变成下面这个样子了。

我们可以看出来最后是相当于img_path, pid, camid组合在一起的。然后,实际的训练到现在还没开始,不但实际训练没开始,连训练数据的导入还没开始,真正的把训练数据导入进去是从下面开始的
if self.train_sampler == 'RandomIdentitySampler':
self.trainloader = DataLoader(
ImageDataset(self.train, transform=transform_train), # ImageDataset 来自 from .dataset_loader import ImageDataset
sampler=RandomIdentitySampler(self.train, self.train_batch_size, self.num_instances),
batch_size=self.train_batch_size, shuffle=False, num_workers=self.workers,
pin_memory=self.pin_memory, drop_last=True
)
这里面的最重要的函数就是DataLoader,是在开头导入的,from torch.utils.data import DataLoader.
这个是pytorch的类,
pytorch document里的DataLoader
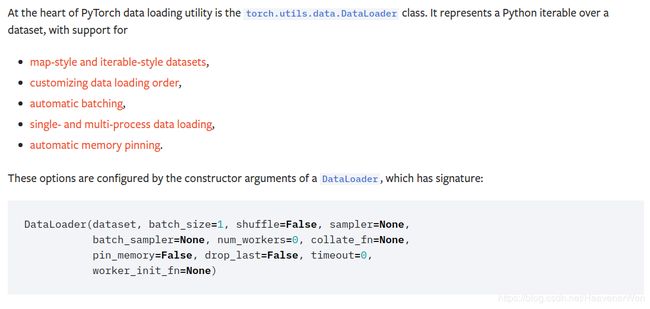
结合pytorch的类的官方API,我们发现dataset = ImageDataset(self.train, transform=transform_train). 然而,这里的又出来个ImageDataset. 这和ImageDataManager感觉很像啊,有点傻傻分不清的感觉。
from .dataset_loader import ImageDataset
# ImageDataset有是一个类。
# 更准确地将应该是ReID训练集专用的类
class ImageDataset(Dataset):
"""Image Person ReID Dataset"""
def __init__(self, dataset, transform=None):
self.dataset = dataset
self.transform = transform
self.totensor = ToTensor()
self.normalize = Normalize([.5, .5, .5], [.5, .5, .5])
def __len__(self):
return len(self.dataset)
def __getitem__(self, index):
img_path, pid, camid = self.dataset[index]
img = read_image(img_path)
# Add by Xin Jin, for getting texture:
img_texture = read_image(img_path.replace('images_labeled', 'texture_cuhk03_labeled'))
if self.transform is not None:
img = self.transform(img)
img_texture = self.normalize(self.totensor(img_texture))
return img, pid, camid, img_path, img_texture
可以把这个类看作如下:
class ImageDataset():
"""Image Person ReID Dataset"""
def __init__(self, dataset, transform=None):
self.dataset = dataset
self.transform = transform
self.totensor = ToTensor()
self.normalize = Normalize([.5, .5, .5], [.5, .5, .5])
def __len__(self):
return len(self.dataset)
def __getitem__(self, index):
img_path, pid, camid = self.dataset[index]
img = read_image(img_path)
然后再结合:dataset = ImageDataset(self.train, transform=transform_train), 我们可以看出
self.dataset = dataset = self.train
self.transform = transform_train
# 同时为这个self(也就是属于ImageDataset类的实例,更准确地说应该是ReID训练集专用的类)生成两属性
# 也就是:
self.totensor = ToTensor()
self.normalize = Normalize([.5, .5, .5], [.5, .5, .5])
然后就该到哪一步了,该到利用__getitem__得到对应的单个image的sample. 同时在这步骤中加入合成纹理。我应该看看论文,他们怎么描述的对这个纹理的获取和应用。
if self.transform is not None:
img = self.transform(img) # 对原图进行transform操作
img_texture = self.normalize(self.totensor(img_texture)) # 对纹理图像进行normalize操作,在normalize操作之前,先转化成tensor, 我们保留这个normalize操作不变。
return img, pid, camid, img_path, img_texture
然后, 就到了DataLoader的第二个参数 sampler,
sampler=RandomIdentitySampler(self.train, self.train_batch_size, self.num_instances)
这里的RandomIdentitySampler是个从下面导入的类
from .samplers import RandomIdentitySampler
这个类的具体信息:
class RandomIdentitySampler(Sampler):
"""
Randomly sample N identities, then for each identity,
randomly sample K instances, therefore batch size is N*K.
Args:
- data_source (list): list of (img_path, pid, camid).
- num_instances (int): number of instances per identity in a batch.
- batch_size (int): number of examples in a batch.
"""
然后这个类的实际功能是决定一个batch具体怎么得来。
def __init__(self, data_source, batch_size, num_instances):
self.data_source = data_source
self.batch_size = batch_size # 训练和测试的batch_size都是4。
self.num_instances = num_instances # 如下面定义,是每个identity选取的实例的数目。
self.num_pids_per_batch = self.batch_size // self.num_instances # 每个batch里面的identity的数量
# 因为batch里面总sample数目= 每个identity取多少个instance*多少个identity.
# 那么,这样的话,4/4=1.
self.index_dic = defaultdict(list)
for index, (_, pid, _) in enumerate(self.data_source):
self.index_dic[pid].append(index)
self.pids = list(self.index_dic.keys())
parser.add_argument('--num-instances', type=int, default=4,
help="number of instances per identity")
接下来就到了一个很关键的地方defaultdict:
from collections import defaultdict
# 这是在用python的官方库
python3.7官方API解释

什么是containner datatype呢?
先不关注这个细节, 先看看这个defaultdict什么作用呢? 为什么涉及defaultdict呢,因为It gets more interesting when the values in a dictionary are collections (lists, dicts, etc.) 当字典中的值是集合(列表,字典等)时,它会变得更加有趣。
defaultdict: dict subclass that calls a factory function to supply missing values dict子类,调用工厂函数以提供缺失值
对factory函数的解释
Quora对python factory function的解释
具体怎么使用以及defaultdict的工作原理的解释
解释defaultdict的博客
刚刚通过defaultdict(那句代码self.index_dic = defaultdict(list)得到的index_dic
index_dic={defaultdic:0}defaultdict(<class 'list'>, {})
In this case, the value (an empty list or dict) must be initialized the first time a given key is used. While this is relatively easy to do manually, the defaultdict type automates and simplifies these kinds of operations.
当字典中的值是集合(列表,字典等)时,它会变得更加有趣。在这种情况下,必须在首次使用给定键时初始化该值(一个空列表或字典)。 尽管这相对容易手动完成,但是defaultdict类型可以自动执行并简化这些类型的操作。
defaultdict(<class 'list'>, {0: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9], 1: [10, 11, 12, 13, 14]})
# 这意思,这个字典吧,字典中的值value是集合,所以会用到defaultdict.
字典类型如下:
defaultdict(
字典如下:
{0: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9], 1: [10, 11, 12, 13, 14]}
key如下:
0
1
value如下:
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
[10, 11, 12, 13, 14]
理解到现在这个程度的话,对接下来理解程序已经足够了。回头再细细研究defaultdict更具体的东西。
self.pids = list(self.index_dic.keys())
# 这句代码得到的是:
pids={list:767}[0, 1, 2, 3, ..., 766]
# 说明是在所有的id里面采样
我们看到__iter__函数了. 先不深入研究这部分代码,如果没对图像进行特别处理的话,先忽略这部分。
def __iter__(self):
batch_idxs_dict = defaultdict(list) # 同样的方法,讨论一个batch时候的情形
for pid in self.pids:
idxs = copy.deepcopy(self.index_dic[pid]) # python里面的赋值语句that do not copy objects, 而是在target和object之间创建绑定。不改变原来这个self.index_dic[pid].
if len(idxs) < self.num_instances:
idxs = np.random.choice(idxs, size=self.num_instances, replace=True)
random.shuffle(idxs)
batch_idxs = []
for idx in idxs:
batch_idxs.append(idx)
if len(batch_idxs) == self.num_instances:
batch_idxs_dict[pid].append(batch_idxs)
batch_idxs = []
For collections that are mutable or contain mutable items, a copy is sometimes needed so one can change one copy without changing the other.
对于可变或包含可变项的集合,有时需要一个副本,因此一个副本可以更改一个副本而不更改另一个副本。
copy.deep_copy的操作
copy.deepcopy(x[, memo])
Return a deep copy of x.
A deep copy constructs a new compound object and then, recursively, inserts copies into it of the objects found in the original. 深层副本将构造一个新的复合对象,然后递归地将原始对象中发现的对象的副本插入其中。
Two problems often exist with deep copy operations that don’t exist with shallow copy operations:
-
Recursive objects (compound objects that, directly or indirectly, contain a reference to themselves) may cause a recursive loop.
-
Because deep copy copies everything it may copy too much, such as
data which is intended to be shared between copies.
然后的话,根据不同的train_sampler,我们会有两种不同的self.trainloader.
这代码写得还是很不错的,这相当于对train数据组织完了,就到测试部分了。他们把对data(including train, test[query, gallery])都写到一个py文件data_manager.py里.
因为我现在是在训练,所以涉及测试的部分会有如下显示:

但是,在又读了一次cuhk03数据集后,
for name in self.target_names:
dataset = init_imgreid_dataset(
root=self.root, name=name, split_id=self.split_id, cuhk03_labeled=self.cuhk03_labeled,
cuhk03_classic_split=self.cuhk03_classic_split
) #
我发现testloader_dict内部的内容发生变化了。

其中,query的情况:
其中,gallery的情况:
经过如下代码:
self.testdataset_dict[name]['query'] = dataset.query
self.testdataset_dict[name]['gallery'] = dataset.gallery
testdataset_dict也发生了变化.
![]()
到这,才看到导数据(含train和test)完毕. 而且才是刚得到管理数据的对象dm,还没真正执行导入。
dm = ImageDataManager(use_gpu, **image_dataset_kwargs(args))
trainloader, testloader_dict = dm.return_dataloaders()
# 为什么返回的是:testloader_dict而不是testdataset_dict
而且这块这个return_dataloaders()这个函数吧,还是在data_manager.py里面用@property修饰过的函数。