【计算机视觉】数据预处理-统一图片大小-image_resize-crop-pad-SPPnet-OpenCV-Python实现
问题
在做CNN的时候,大部分的神经网络模型要求输入的图片大小是固定的。但是由于数据来源的不同,大多数情况下会遇到数据集的图片大小不统一的问题。
比如下面这张图片的大小是333*500,现在要处理为256*256大小的图片。

import numpy as np
from PIL import Image
img_path = 'data/input/img/3771.jpg'
image = Image.open(img_path)
img = np.array(image)
print(img.shape)
(333, 500, 3)
解决办法
常用的方法有三种。
crop和pad是两种传统的办法。spp net(Spatial Pyramid Pooling 空间金字塔池化)是一种新的解决方案。
安装文章相关的Python库
pip install Pillow numpy opencv-python
crop
crop是一种常用的图片预处理方法。这个方法会改变原来的图像,截取主要的信息,忽略其他信息。
下面通过图片来理解这种方法。
width, high, channel = img.shape
width_new, high_new = (256, 256)
img_crop = img[width-width_new:, (high-256)//2:high-((high-256)//2),:]
print(img_crop.shape)
(256, 256, 3)

使用的是numpy的二维数据切片。
pad
pad是一种填充方法,在图片的四周填充指定的值。这种方法不会改变原来的数据的形态,不会丢失图像的原始信息。
首先将图片的长和宽统一为max(width, hight)的大小。
# 计算长和宽的差值
dim_diff = np.abs(high - width)
# 计算上下左右分别需要填充多少个维度
pad1, pad2 = dim_diff // 2, dim_diff - dim_diff // 2
pad = (0, 0, pad1, pad2) if high <= width else (pad1, pad2, 0, 0)
top, bottom, left, right = pad
# 使用opencv的copyMakeBorder函数进行填充
pad_value = 0
img_pad = cv2.copyMakeBorder(img, top, bottom, left, right, cv2.BORDER_CONSTANT, None, pad_value)
print(img_dst.shape)
(500, 500, 3)

dst_size = (256, 256)
img_resize = cv2.resize(img_pad, dst_size, interpolation = cv2.INTER_AREA)
print(img_resize.shape)
(256, 256, 3)

direct resize
直接对原来的图像进行resize。这种方法会丢失原来图像的原始信息,比如图像的形态,结构。
dst_size = (256, 256)
img_resize = cv2.resize(img, dst_size, interpolation = cv2.INTER_AREA)
print(img_resize.shape)
(256, 256, 3)

SPPnet
SPPnet设计
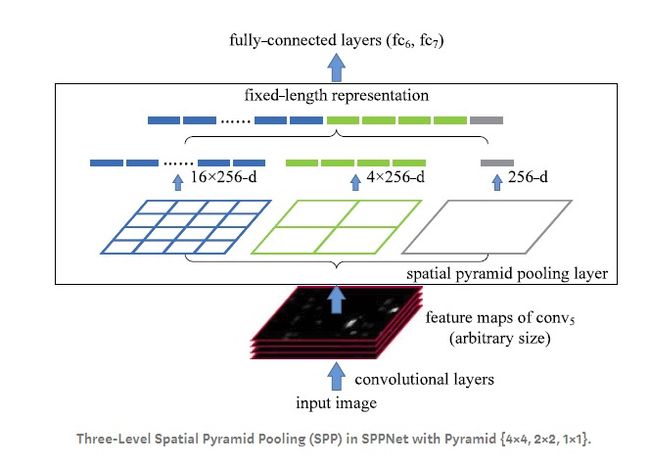
SPPnet的处理方法和传统方法不同,它不会改变原图的大小,而是在卷积层和全连接层之间添加几个不同窗口大小的maxpool池化层,将卷积层传过来的特征数量固定为某个值,这样就可以在不改变图片尺寸的情况下,让原来的神经网络继续良好的运行。
上图中采用的是三层的金字塔池化,池化方式是maxpool,pyramid level设置为(4,2,1)。黑色图片代表卷积之后的特征图,接着以不同大小的块来提取特征,分别是4x4,2x2,1x1。4x4表示将特征图切分为4x4=16个小的特征图,如图左侧16个蓝色小格子的图;2x2表示将特征图切分为2x2=4个小的特征图,如图中间4个绿色小格子的图;1x1表示对整个特征图进行池化,如图右侧的灰色格子;其中256代表channels。这样一来就可以得到16+4+1=21种不同的块(Spatial bins),每个块提取出一个特征,如maxpool,就是计算每个块的最大值,从而得到一个输出单元,最终得到一个21x256维特征的输出,然后进入全连接层。
window size和stride size确定
## 使用TensorFlow实现SPPnet
def Sppnet(conv5, spatial_pool_size):
############### get feature size ##############
height=int(conv5.get_shape()[1])
width=int(conv5.get_shape()[2])
############### get batch size ##############
batch_num=int(conv5.get_shape()[0])
for i in range(len(spatial_pool_size)):
############### stride ##############
stride_h=int(np.ceil(height/spatial_pool_size[i]))
stride_w=int(np.ceil(width/spatial_pool_size[i]))
############### kernel ##############
window_w=int(np.ceil(width/spatial_pool_size[i]))
window_h=int(np.ceil(height/spatial_pool_size[i]))
############### max pool ##############
max_pool=tf.nn.max_pool(conv5, ksize=[1, window_h, window_w, 1], strides=[1, stride_h, stride_w, 1],padding='SAME')
if i==0:
spp=tf.reshape(max_pool, [batch_num, -1])
else:
############### concat each pool result ##############
spp=tf.concat(axis=1, values=[spp, tf.reshape(max_pool, [batch_num, -1])])
return spp
https://medium.com/coinmonks/review-sppnet-1st-runner-up-object-detection-2nd-runner-up-image-classification-in-ilsvrc-906da3753679
https://github.com/ShaoQiBNU/CV-SPPnet