大厂面试关于多线程和高并发阻塞队列问题
- 阻塞队列
- SynchronousQueue
- Callable接口
- 阻塞队列的应用——生产者消费者
- 传统模式
- 阻塞队列模式
- 阻塞队列的应用——线程池
- 线程池基本概念
- 线程池创建方式
- 线程池创建的七个参数
- 线程池底层原理
- 线程池的拒绝策略
- 实际生产使用哪一个线程池?
- 自定义线程池参数选择
- 死锁编码和定位
阻塞队列
概念:当阻塞队列为空时,获取(take)操作是阻塞的;当阻塞队列为满时,添加(put)操作是阻塞的。
好处:阻塞队列不用手动控制什么时候该被阻塞,什么时候该被唤醒,简化了操作。
体系:Collection→Queue→BlockingQueue→七个阻塞队列实现类。
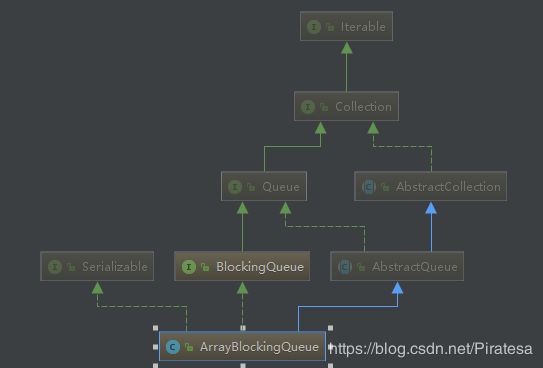
| 类名 | 作用 |
|---|---|
| ArrayBlockingQueue | 由数组构成的有界阻塞队列 |
| LinkedBlockingQueue | 由链表构成的有界阻塞队列 |
| PriorityBlockingQueue | 支持优先级排序的无界阻塞队列 |
| DelayQueue | 支持优先级的延迟无界阻塞队列 |
| SynchronousQueue | 单个元素的阻塞队列 |
| LinkedTransferQueue | 由链表构成的无界阻塞队列 |
| LinkedBlockingDeque | 由链表构成的双向阻塞队列 |
粗体标记的三个用得比较多,许多消息中间件底层就是用它们实现的。
需要注意的是LinkedBlockingQueue虽然是有界的,但有个巨坑,其默认大小是Integer.MAX_VALUE,高达21亿,一般情况下内存早爆了(在线程池的ThreadPoolExecutor有体现)。
API:抛出异常是指当队列满时,再次插入会抛出异常;返回布尔是指当队列满时,再次插入会返回false;阻塞是指当队列满时,再次插入会被阻塞,直到队列取出一个元素,才能插入。超时是指当一个时限过后,才会插入或者取出。
| 方法类型 | 抛出异常 | 返回布尔 | 阻塞 | 超时 |
|---|---|---|---|---|
| 插入 | add(E e) | offer(E e) | put(E e) | offer(E e,Time,TimeUnit) |
| 取出 | remove() | poll() | take() | poll(Time,TimeUnit) |
| 队首 | element() | peek() | 无 | 无 |
SynchronousQueue
队列只有一个元素,如果想插入多个,必须等队列元素取出后,才能插入,只能有一个“坑位”,用一个插一个,
Callable接口
与Runnable的区别:
- Callable带返回值。
- 会抛出异常。
- 覆写
call()方法,而不是run()方法。
Callable接口的使用:
public class CallableDemo {
//实现Callable接口
class MyThread implements Callable {
@Override
public Integer call() throws Exception {
System.out.println("callable come in ...");
return 1024;
}
}
public static void main(String[] args) throws ExecutionException, InterruptedException {
//创建FutureTask类,接受MyThread。
FutureTask futureTask = new FutureTask<>(new MyThread());
//将FutureTask对象放到Thread类的构造器里面。
new Thread(futureTask, "AA").start();
int result01 = 100;
//用FutureTask的get方法得到返回值。
int result02 = futureTask.get();
System.out.println("result=" + (result01 + result02));
}
}
注意:futureTask.get()这个方法一定要放到最后,不然会造成阻塞主要 是因为Unsafe和CAS原理
queued = UNSAFE.compareAndSwapObject(this, waitersOffset,q.next = waiters, q);
源码:
/**
* Awaits completion or aborts on interrupt or timeout.
*
* @param timed true if use timed waits
* @param nanos time to wait, if timed
* @return state upon completion
*/
private int awaitDone(boolean timed, long nanos)
throws InterruptedException {
final long deadline = timed ? System.nanoTime() + nanos : 0L;
WaitNode q = null;
boolean queued = false;
for (;;) {
if (Thread.interrupted()) {
removeWaiter(q);
throw new InterruptedException();
}
int s = state;
if (s > COMPLETING) {
if (q != null)
q.thread = null;
return s;
}
else if (s == COMPLETING) // cannot time out yet
Thread.yield();
else if (q == null)
q = new WaitNode();
else if (!queued)
queued = UNSAFE.compareAndSwapObject(this, waitersOffset,
q.next = waiters, q);
else if (timed) {
nanos = deadline - System.nanoTime();
if (nanos <= 0L) {
removeWaiter(q);
return state;
}
LockSupport.parkNanos(this, nanos);
}
else
LockSupport.park(this);
}
}
阻塞队列的应用——生产者消费者
传统模式
传统模式使用Lock来进行操作,需要手动加锁、解锁。
public void increment() throws InterruptedException {
lock.lock();
try {
//1 判断 如果number=1,那么就等待,停止生产
while (number != 0) {
//等待,不能生产
condition.await();
}
//2 干活 否则,进行生产
number++;
System.out.println(Thread.currentThread().getName() + "\t" + number);
//3 通知唤醒 然后唤醒消费线程
condition.signalAll();
} catch (Exception e) {
e.printStackTrace();
} finally {
//最后解锁
lock.unlock();
}
}
阻塞队列模式
使用阻塞队列就不需要手动加锁了,
/**
*
*/
package com.matao.concurrent.blockingqueue;
import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.SynchronousQueue;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.atomic.AtomicInteger;
/**
* @author MT
*
*/
//volatile + atomicInteger +CAS + 线程交互 + 原子引用
public class ProdConsBlockQueueDemo {
public static void main(String[] args) {
MyResource myResource = new MyResource(new SynchronousQueue<>());
new Thread(() -> {
System.out.println(Thread.currentThread().getName() + "\t生产线程启动");
try {
myResource.myProd();
} catch (Exception e) {
e.printStackTrace();
}
}, "prod").start();
new Thread(() -> {
System.out.println(Thread.currentThread().getName() + "\t消费线程启动");
try {
myResource.myCons();
} catch (Exception e) {
e.printStackTrace();
}
}, "cons").start();
try {
TimeUnit.SECONDS.sleep(5);
} catch (Exception e) {
e.printStackTrace();
}
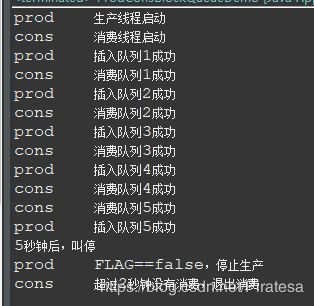
System.out.println("5秒钟后,叫停");
myResource.stop();
}
}
class MyResource {
private volatile boolean FLAG = true; //默认开启,进行生产+消费
private AtomicInteger atomicInteger = new AtomicInteger();
private BlockingQueue blockingQueue;
public MyResource(BlockingQueue blockingQueue) {
this.blockingQueue = blockingQueue;
}
public void myProd() throws Exception {
String data = null;
boolean retValue;
while (FLAG) {
data = atomicInteger.incrementAndGet() + "";//++i
retValue = blockingQueue.offer(data, 2L, TimeUnit.SECONDS);
if (retValue) {
System.out.println(Thread.currentThread().getName() + "\t" + "插入队列" + data + "成功");
} else {
System.out.println(Thread.currentThread().getName() + "\t" + "插入队列" + data + "失败");
}
TimeUnit.SECONDS.sleep(1);
}
System.out.println(Thread.currentThread().getName() + "\tFLAG==false,停止生产");
}
public void myCons() throws Exception {
String res;
while (FLAG) {
res = blockingQueue.poll(2L, TimeUnit.SECONDS);
if (null == res || res.equalsIgnoreCase("")) {
FLAG = false;
System.out.println(Thread.currentThread().getName() + "\t超过2秒钟没有消费,退出消费");
return;
}
System.out.println(Thread.currentThread().getName() + "\t消费队列" + res + "成功");
}
}
public void stop() {
this.FLAG = false;
}
}
阻塞队列的应用——线程池
线程池基本概念
概念:线程池主要是控制运行线程的数量,将待处理任务放到等待队列,然后创建线程执行这些任务。如果超过了最大线程数,则等待。
优点:
- 线程复用:不用一直new新线程,重复利用已经创建的线程来降低线程的创建和销毁开销,节省系统资源。
- 提高响应速度:当任务达到时,不用创建新的线程,直接利用线程池的线程。
- 管理线程:可以控制最大并发数,控制线程的创建等。
体系:Executor→ExecutorService→AbstractExecutorService→ThreadPoolExecutor。ThreadPoolExecutor是线程池创建的核心类。类似Arrays、Collections工具类,Executor也有自己的工具类Executors。
线程池创建方式
现在线程池已经是五种了,分别是:
1.newScheduledThreadPool
2.newWorkStealingThreadPool
3.newFixedThreadPool
4.newSingleThreadExecutor
5.newCachedThreadPool
newFixedThreadPool:使用LinkedBlockingQueue实现,定长线程池。

源码:
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue());
}
newSingleThreadExecutor:使用LinkedBlockingQueue实现,一池只有一个线程。

源码:
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue()));
}
newCachedThreadPool:使用SynchronousQueue实现,变长线程池。

源码:
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue());
}
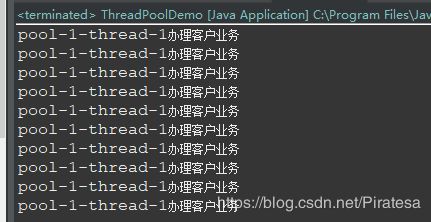
Demo 主要验证newCachedThreadPool 分别是加上时间停顿和没加的情况
public class ThreadPoolDemo {
public static void main(String[] args) {
// ExecutorService threadPool = Executors.newFixedThreadPool(5);
// ExecutorService threadPool = Executors.newSingleThreadExecutor();
ExecutorService threadPool = Executors.newCachedThreadPool();
for(int i = 1; i <= 10; i++){
threadPool.execute(() ->{
System.out.println(Thread.currentThread().getName() + "办理客户业务\t");
});
try {
TimeUnit.MILLISECONDS.sleep(200);
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
threadPool.shutdown();
}
}
public class ThreadPoolDemo {
public static void main(String[] args) {
//ExecutorService threadPool = Executors.newFixedThreadPool(5);
// ExecutorService threadPool = Executors.newSingleThreadExecutor();
ExecutorService threadPool = Executors.newCachedThreadPool();
for(int i = 1; i <= 10; i++){
threadPool.execute(() ->{
System.out.println(Thread.currentThread().getName() + "办理客户业务\t");
});
/*try {
TimeUnit.MILLISECONDS.sleep(200);
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}*/
}
threadPool.shutdown();
}
}
线程池创建的七个参数
| 参数 | 意义 |
|---|---|
| corePoolSize | 线程池常驻核心线程数 |
| maximumPoolSize | 能够容纳的最大线程数 |
| keepAliveTime | 空闲线程存活时间 |
| unit | 存活时间单位 |
| workQueue | 存放提交但未执行任务的队列 |
| threadFactory | 创建线程的工厂类 |
| handler | 等待队列满后的拒绝策略 |
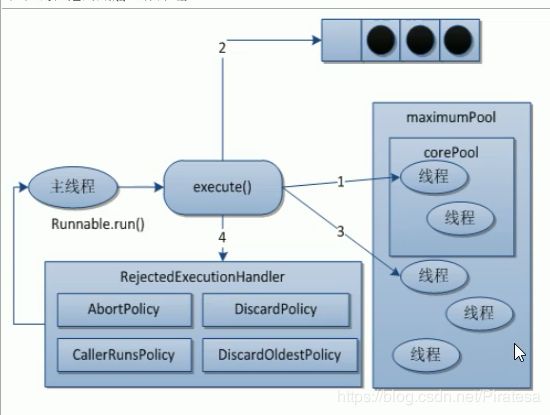
理解:线程池的创建参数,就像一个银行。
corePoolSize就像银行的“当值窗口“,比如今天有2位柜员在受理客户请求(任务)。如果超过2个客户,那么新的客户就会在等候区(等待队列workQueue)等待。当等候区也满了,这个时候就要开启“加班窗口”,让其它3位柜员来加班,此时达到最大窗口maximumPoolSize,为5个。如果开启了所有窗口,等候区依然满员,此时就应该启动”拒绝策略“handler,告诉不断涌入的客户,叫他们不要进入,已经爆满了。由于不再涌入新客户,办完事的客户增多,窗口开始空闲,这个时候就通过keepAlivetTime将多余的3个”加班窗口“取消,恢复到2个”当值窗口“。
线程池底层原理
原理图:上面银行的例子,实际上就是线程池的工作原理。
流程图:
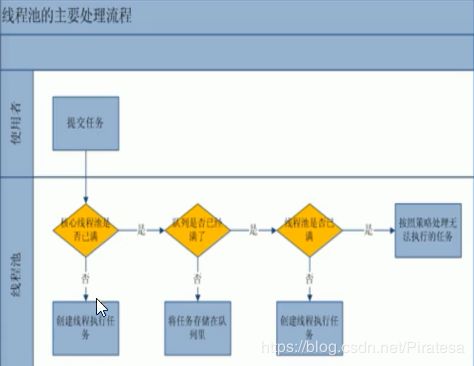
新任务到达→
如果正在运行的线程数小于corePoolSize,创建核心线程;大于等于corePoolSize,放入等待队列。
如果等待队列已满,但正在运行的线程数小于maximumPoolSize,创建非核心线程;大于等于maximumPoolSize,启动拒绝策略。
当一个线程无事可做一段时间keepAliveTime后,如果正在运行的线程数大于corePoolSize,则关闭非核心线程。
线程池的拒绝策略
当等待队列满时,且达到最大线程数,再有新任务到来,就需要启动拒绝策略。JDK提供了四种拒绝策略,分别是。
- AbortPolicy:默认的策略,直接抛出
RejectedExecutionException异常,阻止系统正常运行。 - CallerRunsPolicy:既不会抛出异常,也不会终止任务,而是将任务返回给调用者。
- DiscardOldestPolicy:抛弃队列中等待最久的任务,然后把当前任务加入队列中尝试再次提交任务。
- DiscardPolicy:直接丢弃任务,不做任何处理。
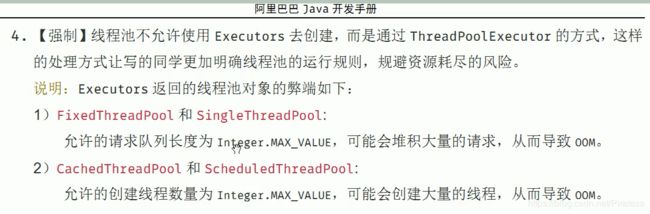
实际生产使用哪一个线程池?
单一、可变、定长都不用!原因就是FixedThreadPool和SingleThreadExecutor底层都是用LinkedBlockingQueue实现的,这个队列最大长度为Integer.MAX_VALUE,显然会导致OOM。所以实际生产一般自己通过ThreadPoolExecutor的7个参数,自定义线程池。
ExecutorService threadPool=new ThreadPoolExecutor(2,5,
1L,TimeUnit.SECONDS,
new LinkedBlockingQueue<>(3),
Executors.defaultThreadFactory(),
new ThreadPoolExecutor.AbortPolicy());
自定义线程池参数选择
对于CPU密集型任务,所谓的CPU密集型的意思就是任务需要大量的运算而没有阻塞,CPU一直高速运算

对于IO密集型任务,尽量多配点,可以是CPU线程数*2,或者CPU线程数/(1-阻塞系数)。

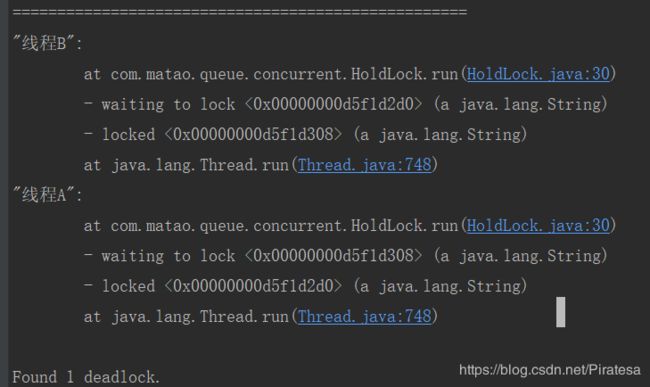
死锁编码和定位
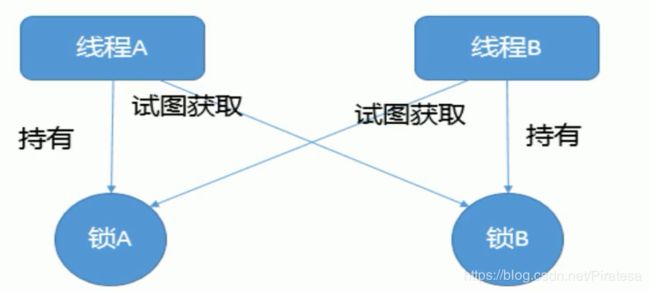
造成死锁的原因:
1.系统资源不足
2.资源分配不当
3.进程运行推进的顺序不合适
主要是两个命令配合起来使用,定位死锁。
jps指令:jps -l可以查看运行的Java进程。
package com.matao.queue.concurrent;
import java.util.concurrent.TimeUnit;
public class HoldLock implements Runnable {
String lockA;
String lockB;
/**
*
*/
public HoldLock(String lockA,String lockB) {
this.lockA = lockA;
this.lockB = lockB;
}
@Override
public void run() {
synchronized (lockA) {
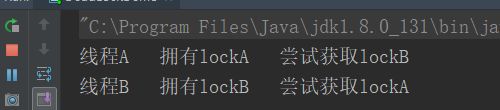
System.out.println(Thread.currentThread().getName() + "\t拥有" + lockA + "\t尝试获取" + lockB);
//睡眠一会
try {
TimeUnit.MICROSECONDS.sleep(500);
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
synchronized (lockB) {
System.out.println(Thread.currentThread().getName() + "贪心之徒");
}
}
}
}
package com.matao.queue.concurrent;
public class DeadLockDemo {
public static void main(String[] args) {
String lockA = "lockA";
String lockB = "lockB";
HoldLock holdLock = new HoldLock(lockA, lockB);
new Thread(new HoldLock(lockA, lockB),"线程A").start();
new Thread(new HoldLock(lockB, lockA),"线程B").start();
}
}
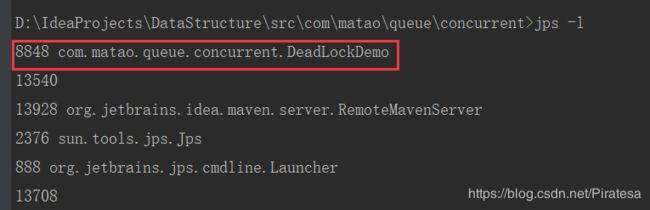
jstack指令:jstack pid可以查看某个Java进程的堆栈信息,同时分析出死锁。