Python中利用BeautifulSoup4反查包含文本内容的标签
目录
- 1 问题引出
- 2 问题分析
- 3 解决方案
1 问题引出
编写爬取Amazon服装行业数据时,遇到一个问题:根据文本内容Next反查包含它的父标签。请看下面HTML片段
<li class="a-last">
<a href="/s?k=red+tshirt&i=fashion-mens&page=2&qid=1588904638&ref=sr_pg_1">Next
<span class="a-letter-space">span>
<span class="a-letter-space">span>→a>
li>
我需要根据Next反查包含它的标签a,以此获取href属性的值。最近编写很多爬虫项目,积累了一定的经验,于是,我认为上述很简单,编写如下代码:
# testBs.py
from bs4 import BeautifulSoup
import re
str = """Next→ """
soup = BeautifulSoup(str,'lxml')
a = soup.find('a',text=re.compile(r"Next"))
print(a)
运行后,如下:
![]()
也就是说,查不到标签a。
2 问题分析
若将HTML片段改为标签a下不含子标签span的话,即
<li class="a-last">
<a href="/s?k=red+tshirt&i=fashion-mens&page=2&qid=1588904638&ref=sr_pg_1">Nexta>
li>
则上述代码可以得到结果:

我分析,肯定是代码a = soup.find('a',text=re.compile(r"Next"))有问题。那么针对原HTML片段,为了不受查询标签a的限制,我将核心代码改为:
a = soup.find(text=re.compile(r"Next"))
print(a)
运行结果为:
![]()
这是一个好的象征,离成功近了一步。经过查阅BeautifulSoup4的资料,此时得到的对象是一个BeautifulSoup.NavigableString对象,我们可以利用代码查看变量a的信息:
from bs4 import BeautifulSoup
import re
import pprint
str = """Next→ """
soup = BeautifulSoup(str,'lxml')
a = soup.find(text=re.compile(r"Next"))
#print(a)
pprint.pprint(a.__dict__)
运行结果为:
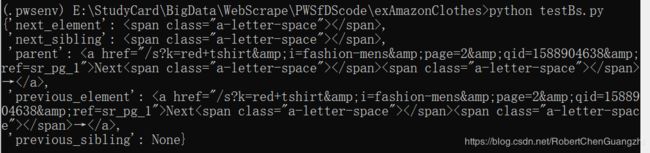
那么此时我们的问题答案已经很明了了。
3 解决方案
最终,利用文本内容(且与其同一层还有其他标签)反查包含它的标签的属性值的代码如下:
from bs4 import BeautifulSoup
import re
import pprint
str = """Next→ """
soup = BeautifulSoup(str,'lxml')
a = soup.find(text=re.compile(r"Next"))
print(a.parent.get('href'))
代码运行结果为:
![]()
完美!!!