PyTorch入门实战教程笔记(七):MNIST 手写数字识别代码详解
PyTorch入门实战教程笔记(七):MNIST 手写数字识别代码详解
1. 流程
1 加载数据
2 建立模型
3 训练
4 测试
2. 代码实战
(1)文件1:utils.py辅助文件
# utils.py
import torch
from matplotlib import pyplot as plt
def plot_curve(data): #下降曲线的绘制
fig = plt.figure()
plt.plot(range(len(data)), data, color='blue') #
plt.legend(['value'], loc='upper right') #
plt.xlabel('step')
plt.ylabel('value')
plt.show()
def plot_image(img, label, name): # 画图片,帮助看识别结果
fig = plt.figure()
for i in range(6): # 6个图像,两行三列
# print(i) 012345
plt.subplot(2, 3, i+1)
plt.tight_layout() # 紧密排版
plt.imshow(img[i][0]*0.3081+0.1307, cmap='gray', interpolation='none')
# 均值是0.1307,标准差是0.3081,
plt.title("{}:{}".format(name, label[i].item()))
# name:image_sample label[i].item():数字
plt.xticks([])
plt.yticks([])
plt.show()
def one_hot(label, depth=10):
out = torch.zeros(label.size(0), depth)
idx = torch.LongTensor(label).view(-1, 1)
out.scatter_(dim=1, index=idx, value=1)
return out
(2)文件2:mnist_train.py主文件
import torch
from torch import nn
from torch.nn import functional as F
from torch import optim
import torchvision
from matplotlib import pyplot as plt
from utils import plot_curve, plot_image, one_hot
batch_size = 512
# step1.load_dataset
# 'mnist_data':加载mnist数据集,路径
# train=True:选择训练集还是测试
# download=True:如果当前文件没有mnist文件就会自动从网上去下载
# torchvision.transforms.ToTensor():下载好的数据一般是numpy格式,转换成Tensor
# torchvision.transforms.Normalisze((0.1307,), (0.3081,)):正则化过程,为了让数据更好的在0的附近均匀的分布
# 上面一行可注释掉:但是性能会差到百分之70,加上是百分之80,更加方便神经网络去优化
train_loader = torch.utils.data.DataLoader( # 加载训练集
torchvision.datasets.MNIST('mnist_data', train=True, download=True,
transform=torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
# torchvision.transforms.Normalize(
# (0.1307,), (0.3081,))
])),
batch_size=batch_size, shuffle=True)
# batch_size=batch_size:表示一次加载多少张图片
# shuffle = True 加载的时候做一个随机的打散
test_loader = torch.utils.data.DataLoader( # 加载测试集
torchvision.datasets.MNIST('mnist_data/', train=False, download=True,
transform=torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(
(0.1307,), (0.3081,)) # 均值是0.1307,标准差是0.3081,
# 这些系数都是数据集提供方计算好的数据
])),
batch_size=batch_size, shuffle=False) # 测试集不用打散
x, y = next(iter(train_loader))
print(x.shape, y.shape, x.min(), x.max())
# plot_image(x, y, 'image_sample')
#--------------------构造训练网络框架(三层)------------------------
class Net(nn.Module):
def __init__(self): # 初始化函数
super(Net, self).__init__()
# 新建三层 xw+b是一层
self.fc1 = nn.Linear(28*28, 256) # 这里的256是随机决定,小维度是这样的,经验
self.fc2 = nn.Linear(256, 64)
self.fc3 = nn.Linear(64, 10) # 28*28=784是输入, 10是10种分类,这两个是固定的。 256和64是经验决定
def forward(self, x):
# h1 = relu(xw+b) x: [b, 1, 28, 28]
x = F.relu(self.fc1(x))
# h2 = relu(h1w2+b2)
x = F.relu(self.fc2(x))
# h3 = h2w3+b3 最后一层加不加激活函数取决于具体的任务,输出是输出概率值
x = self.fc3(x) # 分类问题一般是softmax + mean squre error均方差 ,简单起见直接使用softmax
return x
net = Net() # 完成一个实例化
# net.parameters(): 会帮我们拿到权值 [w1, b1, w2, b2, w3, b3]
# momentum: 动量,帮助更好的优化的一个策略,后面会讲
# lv: 学习率
optimizer = optim.SGD(net.parameters(), lr=0.01, momentum=0.9) # 梯度下降的优化器
# 下面注释 @@@1、@@@2、@@@3为帮助loss可视化代码。
train_loss = [] # @@@1
# -------------------对整个数据集迭代3遍---------------------------
for epoch in range(3): # 对整个数据集迭代3遍
for batch_idx, (x, y) in enumerate(train_loader): # 对整个数据集迭代一次
# 这里是对一个batch迭代一次,一次batch 512张图片
# print(x.shape, y.shape) 输入 torch.Size([512, 1, 28, 28]) 输出 torch.Size([512])
# x: [b, 1, 28, 28], y: [512]
# 需要把输入tensor[b, 1, 28, 28] -> 打平为下面[b, feature]
# [b, 1, 28, 28] => [b, 784]
# x.view 参考:https://blog.csdn.net/zjc910997316/article/details/93472186
x = x.view(x.size(0), 28*28) # x.size(0)表示batch 512 (512, 1, 28, 28) -> (512, 748)
# => [b, 10]
out = net(x) # 经过了class Net(nn.Module):
# [b, 10]
y_onehot = one_hot(y)
# loss = mse(out, y_onehot) mse 是 均方差 mean squre error
loss = F.mse_loss(out, y_onehot) # todo 1:计算out与y_onehot之间的均方差,得到loss
optimizer.zero_grad() # 先对梯度进行清零
loss.backward() # todo 2:梯度计算过程,计算梯度
# w' = w - lr*grad learn rate学习率
optimizer.step() # todo 3:更新权值
train_loss.append(loss.item()) # @@@2
if batch_idx % 10 == 0: # 每隔10个batch打印一下
print(epoch, batch_idx, loss.item()) # 第几个大循环(一共3个), 第多少批次eg:10 20 30 , loss显示
plot_curve(train_loss) # @@@3
# we get optimal [w1, b1, w2, b2, w3, b3]
# 下面用测试集来进行测试
total_correct = 0
# x: [b, 1, 28, 28]
for x, y in test_loader:
x = x.view(x.size(0), 28*28)
out = net(x)
# out: [b, 10] => pred:[b]
pred = out.argmax(dim=1) # 取得[b, 10]的10个值的最大值所在位置的索引
correct = pred.eq(y).sum().float().item() # 当前batch中与y标签等,也就是预测对的总个数合计,item()取出它的数值
total_correct += correct
# ------------loss只是一个辅助指标,correct才是真正指标------------
total_num = len(test_loader.dataset)
acc = total_correct / total_num
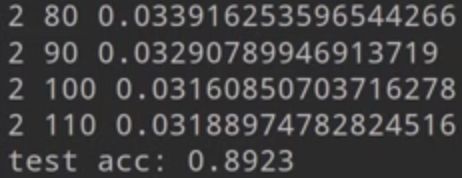
print('test acc:', acc) # test acc: 0.7799
x, y = next(iter(test_loader)) # 取一个batch,查看预测结果
out = net(x.view(x.size(0), 28*28))
pred = out.argmax(dim=1) # 取得[b, 10]的10个值的最大值所在位置的索引
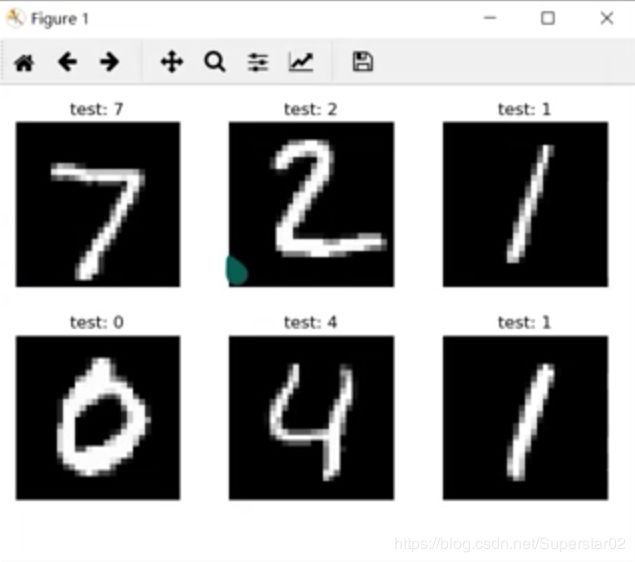
plot_image(x, pred, 'test')
3. 输出结果
loss函数图:

有迭代过程,有correct结果 0.8923
测试结果
4. 改进方法
1 增加一层

2 最后一层的输出可以使用softmax
参考:https://blog.csdn.net/gaoyueace/article/details/79027081
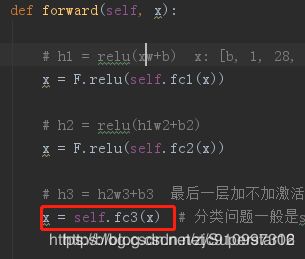
3 loss使用的是均方差mean squre error , 可以改成交叉熵The cross entropy
参考:https://blog.csdn.net/gaoyueace/article/details/79027081