一.前言
由于前一段时间以及实现了基于keras深度学习框架下yolov3的算法,本来想趁着余热将自己的心得体会进行总结,但由于前几天有点事就没有完成计划,现在趁午休时间整理一下。
二.Keras框架的介绍
1.Keras是一个用Python编写的高级API,它提供了一个简单和模块化的API来创建和训练神经网络,同时也隐藏了大部分复杂的细节。其能够在TensorFlow、Theano或CNTK上运行。
2.keras的模型结构

常用模型有:序贯模型(Sequential)和函数式模型(Model),函数式模型应用更为广泛,序贯模型是函数式模型的一种特殊情况。
a)序贯模型(Sequential):单输入单输出,一条路通到底,层与层之间只有相邻关系,没有跨层连接。这种模型编译速度快,操作也比较简单
b)函数式模型(Model):多输入多输出,层与层之间任意连接。这种模型编译速度慢。
3. Keras搭建一个神经网络流程
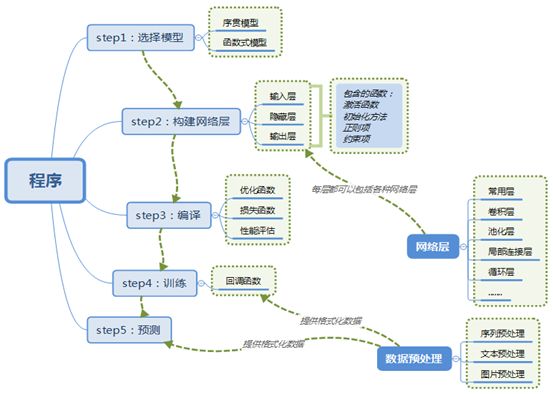
其中用到的优化函数,损失含函数,以及性能评估等请读者自己补脑和查找相关资料。
三.Yolov3算法的简介
1.yolo设计的理念
yolo是目前比较流行的目标检测算法,速度快结构简单。其他的目标检测算法也有RCNN,faster-RCNN, SSD等。 yolo先将图片分成S*S个块。每个单元格会预测B个边界框(bounding box)以及边界框的置信度(confidence score)。所谓置信度其实包含两个方面,一是这个框中目标存在的可能性大小,二是这个边界框的位置准确度。前者我们把它记做Pr(obj),若框中 没有目标物,则Pr(obj)=0,若含有目标物则Pr(obj)=1 。那么边界框的位置的准确度怎么去判断呢?我们使用了一种叫做IOU(交并比)的方法,意思就是说我预测的框与你真实的框相交的面积,和预测的框与真实框合并的面积的比例。我们可以记做 IOU(pred),那么置信度就可以定义为这两项相乘。边界框的大小和位置可以用四个值来表示,(x,y,w,h)注意,不要凭空想象是一个矩形对角两个点的位置坐标,这里面的x,y是指预测出的边界框的中心位置相对于这个格子的左上角位置的偏移量,而且这 个偏移量不是以像素为单位,而是以这个格子的大小为一个单位。
2. 算法在速度和精度上的提升可以查看如下图:

3.yolov3算法的缺点
1).YOLO对相互靠的很近的物体,还有很小的群体 检测效果不好,这是因为一个网格中只预测了两个框,并且只属于一类。
2).同一类物体出现的新的不常见的长宽比和其他情况时,泛化能力偏弱。
3).由于损失函数的问题,定位误差是影响检测效果的主要原因。尤其是大小物体的处理上还有待加强。
参考:
https://blog.csdn.net/zdy0_2004/article/details/74736656
https://blog.csdn.net/nanxiaoting/article/details/82497731
https://blog.csdn.net/Dongjiuqing/article/details/84763430