视频编码未来简史
首先我们回顾一下视频编码的历史,视频编码起源于广播电视,在很长一段时间里视频编解码的变革主要推动力是来自于广播电视。当然,今天我们看互联网的视频编码是速度越来越快,昨天在ICET2017年世界大会上,ICET的主席还说到以前一个编码是十年更新一版,但是现在从H.265最新进展的来看,可能不到十年。
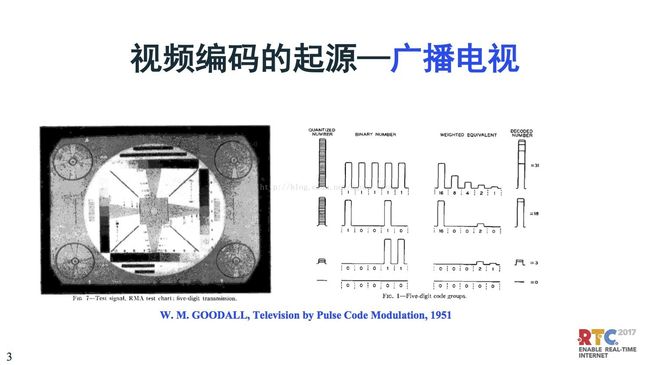
我们看到这个图,大家可能在小的时候见到过,电视上一个圆盘,这是最主要的电视测试信号,这是1951年第一部数字电视和广播。这个起源是脉冲调制编码,相当于一个脉冲一个象素值,比较早的是用固定的比特,用8比特表示图象电视信号编码传输。这是在广播电视领域。

到了我们计算机行业,计算机诞生于1946年,但是在计算机上出现图象是到了1957年, Kirsch是第一幅数字图象的创造者,他用他的儿子做了第一章数字图像。2007年是这一幅图象诞生50周年,现在是60周年了,原来的小baby现在也已经是50、60岁的老头了。今天的数字图象,已经到了4K甚至8K。
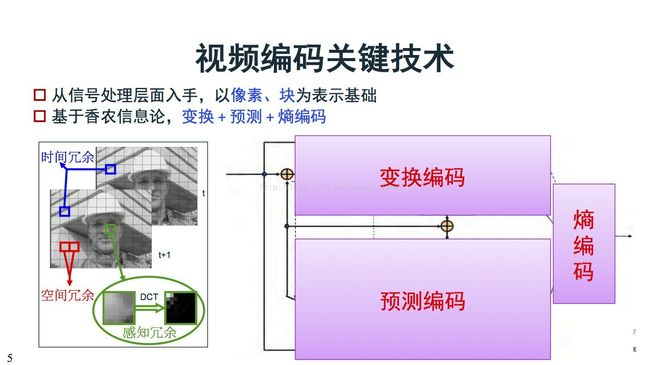
到了编码,编码的原理是因为视频里面有很多冗余,包括连续两幅图象出现的时域冗余,还有人眼对高频信息不敏感的感知冗余,还有对感知不敏感的感知冗余。基于这个原理,我现在视频编解码框架早期261开始,一直到今天266快出来了,框架基本上没有太多变化。
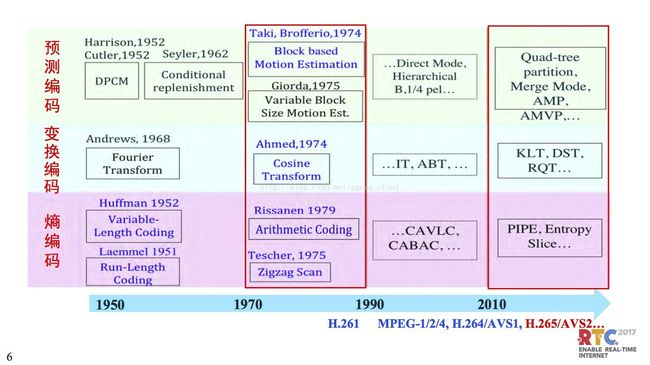
在这个框架里面,我们说它的编码技术可以主要分成三大块。其中一部分是变换编码,刚刚提到通过变换把高频信息把冗余信息去除掉。其中还有空域、时域把冗余信息去除掉。还有预测编码,还有熵编码。这是三大块编码的技术。
如果看三大块的编码技术,实际上是1950年差不多,1946年计算机诞生,1948年是相对信息论,50年代初开始了数字化开始视频数字编码时代。在早期由于计算能力限制,基本上是基于象素去处理,都是机遇统计去处理,像我们看到的huffma编程统计编码技术。计算能力增强了之后现在有基于块的处理。原来只能是基于图象去做,后面才可以基于块的处理,基于块的运动估计、运动补偿,像块大小也可以变化,今天我们看到的H.264、265都是这样。
变换,在70年代末的时候,基本上奠定了我们今天的视频编码行业,也就是说40年来基本上都是处于老瓶新酒的状态。再看后面这是最近几年的情况,当然265也有几年历史了,这是看到这块的进展,包括像变换这块有正象变换。这是视频编码的技术发展。
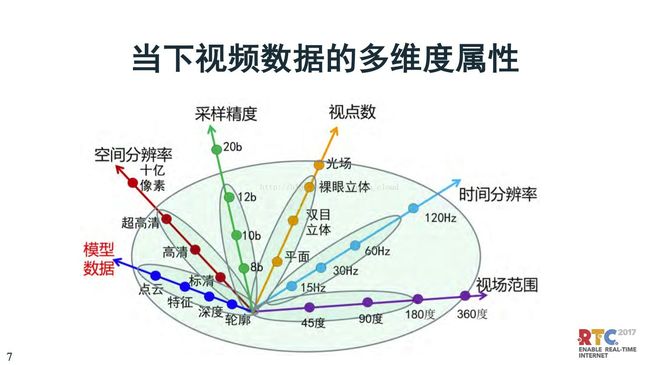
再看当下的视频编码技术进展。首先是空间的分辨率,从原来的小图象到标清、到高清、再到超高清。第二,是时间分辨率,从原来的15帧,还有更高的20帧,到120。第三,采样精度,现在的 HDR高动态范围电视,至少是10比特了,但是10比特够不够,将来还会发展,也可能到了20比特。第四,视点数和视场范围,这两个是密切相关的。视频传的不是一路视频,可能是两路,可能是多路,这是视点数。视频的范围,看到的角度,越来越宽,这是视场范围。第五,模型数据。模型数据是包括轮廓对象的刻划。深度数据,还包括特征,对图像内容、对象的认识。还有是点云,完全可以把对象重建出来,远景重现就依赖这项技术。
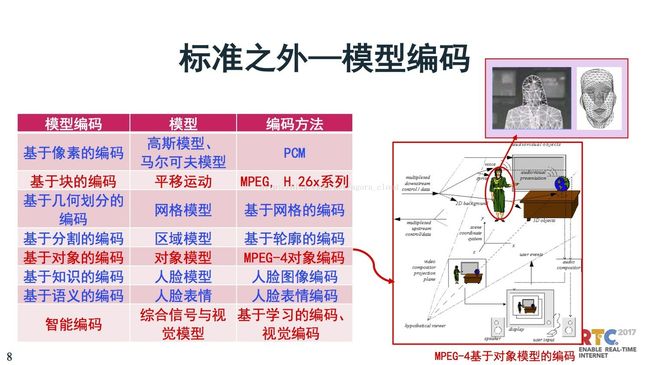
模型编码,是标准之外的编码。模型编码这个概念也是比较久了,大概在80年代后期,一直到90年代中期的时候,曾经有一个很大的呼声,模型编码是第二类编码,但是今天为止我们发现二代始终没上台,始终在用原来的二代。模型编码的概念很光,可以把原基于象素的编码都可以涵盖,也是模型,只不过它的模型是基于信号模型。当然我们熟悉的是对象模型,这个概念很新,但是它也没有用起来,也是有很多问题,在这里提到场景的解析,人和场地的解析。
更进一步,包括对人这块,对人的身体、人的脸可以更精度的建模型,这对于编码尝试也很多。所以这对应表格上是在早期过去编码历史也有反应,包括基于人脸模型,甚至人脸哭和笑,只要是做好模型,将来传很少的数据就可以还原。
当然最后边的发展最后还提到智能编码,这是综合了信号与视觉的模型,基于学习的视频编码。

再看看视频编码的发展趋势。4K越来越流行。我们看到互联网广播,包括最近广东也开会提出下一步要提出4K电视广播技术,我们北京也提出2022年冬奥会是8K的试播。上图可以对比一下,有测试8K,左上角的高清多么小。当然8K视频不只是分辨率的问题,还有配套的技术,包括采样精度、帧率和声音。

这是关于压缩的发展趋势是8K。但是我们说的8K它并不只是分辨率的问题,下面还有象素、更高精度。这是10亿象素的相机拍摄的一张照片,图片一直放大,可以清楚的看到“太和殿”三个字。

刚刚说的主要是分辨率的增长。分辨率上去之后,并不是说要传一个更大的视频,对于后端来说,意味着可以可以提供更多的视频应用形式。其中一个是AR和VR。现在4K做VR的视觉效果还是有问题的,还是需要更高的视频带宽和视频精度去传输。模型编码,对AR也有更大的提升作用。
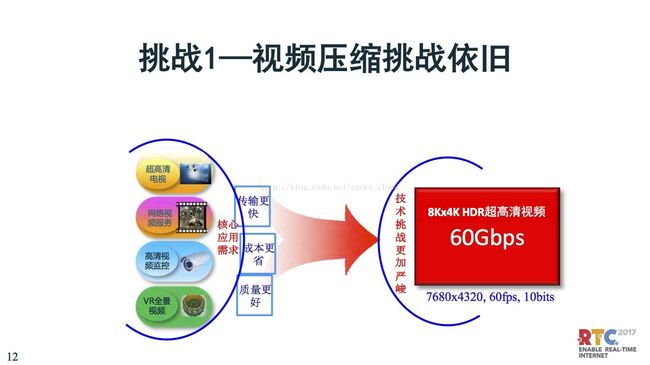
刚刚讲了这么多,如果看挑战,一个是说数据量的压缩,依然是比较严峻的。8K、4K、HDR这样的视频,原始数据级是60Gbps。
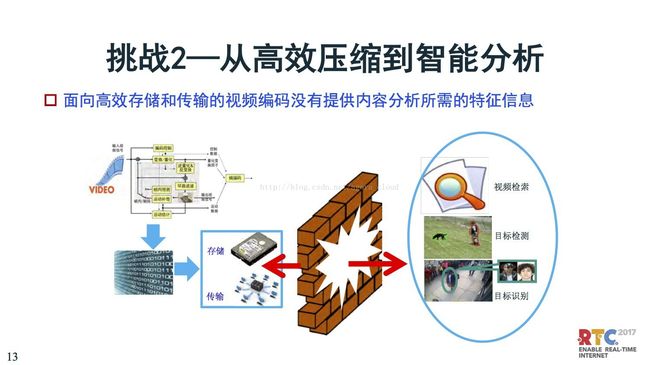
第二个挑战是,从压缩到分析。刚刚讲到视频编码的第一个推动作用是广播电视,看到更好的视觉质量。但是到今天为止,世界上好多视频,比如监控,并不是人要去看的,是计算机要去看的。我们没有人去盯监控视频,希望计算机来能够完成分析。目前的压缩是面向存储和传输,降低带宽占用,但是分析的支持相当弱。所以,很多视频分析的研究是在压缩完之后进行。但是,随着现在前期分析识别技术越来越强,很多视频分析开始在视频编码时就进行智能分析、智能编码。

最新进展我也快速过一下,一个是最关心的JEM266,高通推动新一代的发展,最早是在MPEG会议提出,提出HM—KTA—1.0,到2020年制定新的标准。
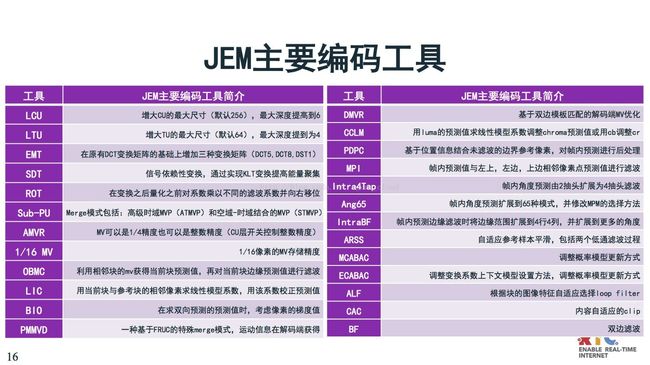
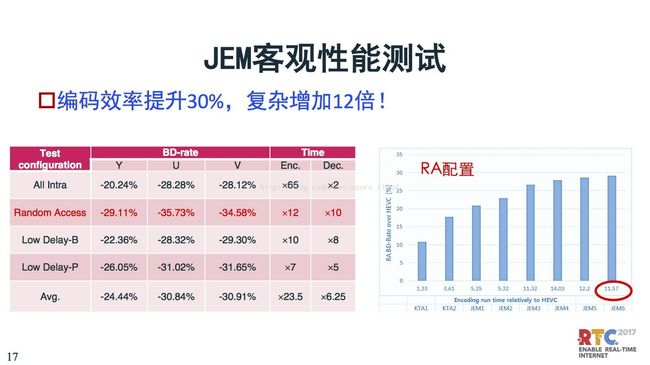
JEM的性能有很大提升。客观性测试上,编码效率已经提升了30%,复杂度增加了12倍,这对编码实现还是很有压力的。这是刚刚出来的雏形,后端肯定会在复杂度和性能之间的做更多优化做更多技术。
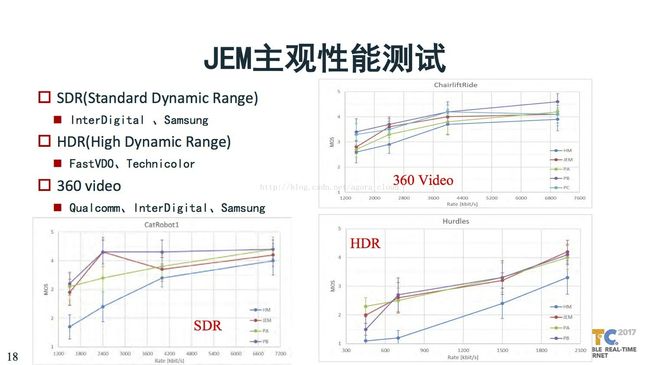
最近已经有几家平台基于JEM做了一些尝试,可以看到他们的测试结果。在SDR、HDR、360video三个平台,可以看到基本上原来的码率下一半的时候可以达到同等的要求。这个对8K很有吸引力。
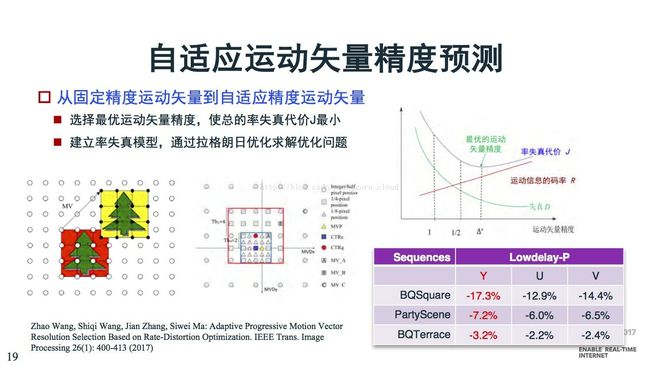
从固定精度运动矢量到自适应精度运动矢量,离预测中心比较近是,用高精度,比较远时用低精度,以此来节省运动矢量编码的码率。
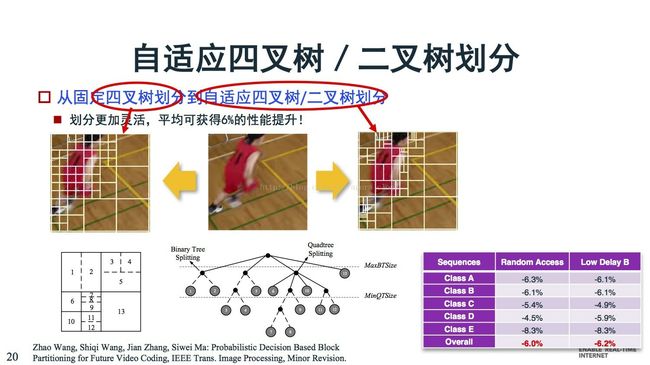
第二个是关于划分,划分模式太多,大家在选择起来比较头疼。
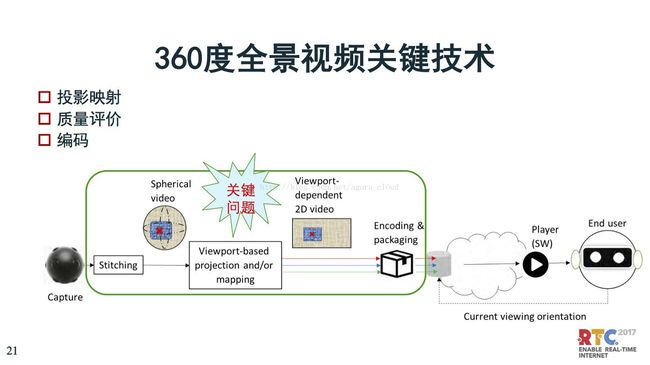
再说一下360,基本上是把投影拼接,拼接完了之后再压缩编码。在这个环节里面最重要的是投影数据,投影数据决定你要压缩什么、丢失什么,对整个VR的体验影响很多。这是很重要的方向。
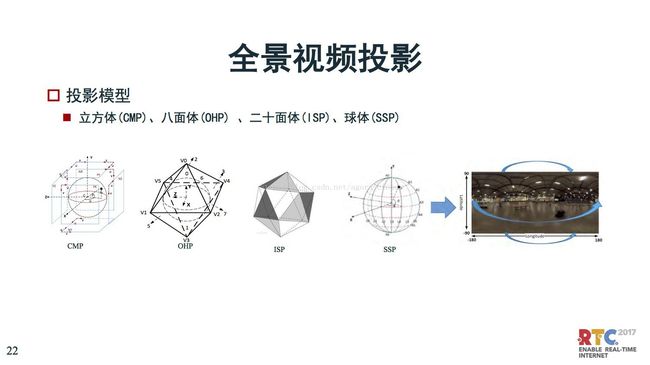
从图象这块我们可以看到全景视频投影,从立方体、八面体、二十面体、球体,JEM里面有十几种投影方式。
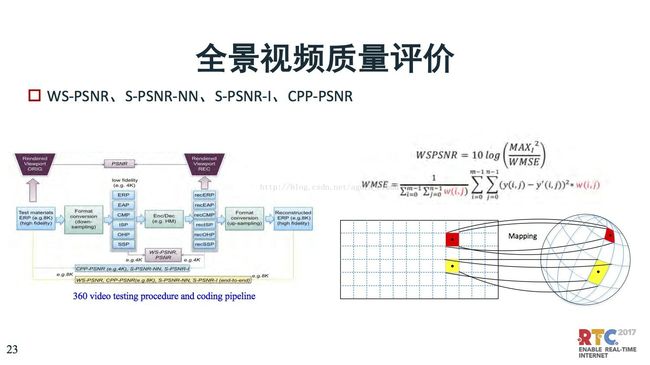
对于质量评价不一样,当然这种质量评价也是影响你编码工具的设计,这儿有一个WSPSNR的概念因为它是从球面投到平面上去,有些数据丢了,如何计算WSPSNR很难,当然还有很多其他的方式。
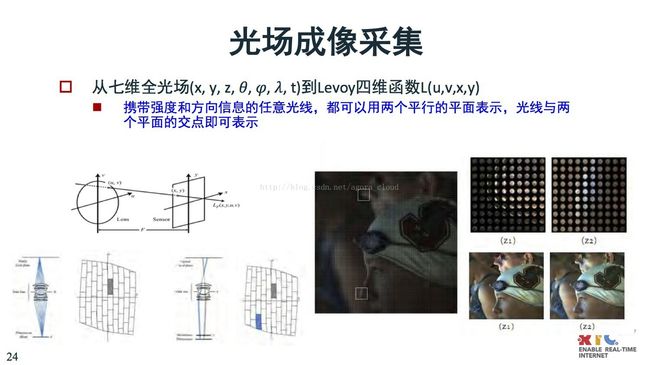
刚刚讲到JEM的技术。像光场这块原来是聚焦一个图象,现在是把不同方向的内容光线记录下来,一遍是利用相机阵列,或者微透镜成像。
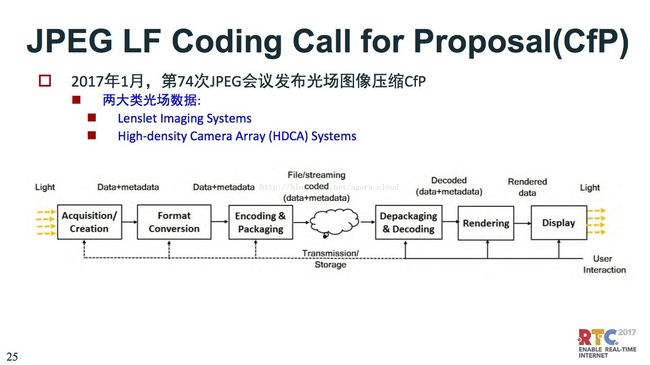
广场图像压缩,JPEG比较积极,它是在2017年1月份发布光场图象压缩平台。
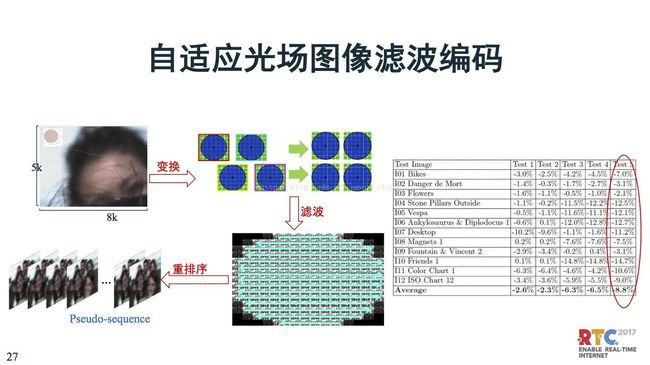
在这里我们做了初步探索,对光场图象里面有很多问题,每一个小透镜采集的光和图象不一样,中间有很多差异。弄完之后实际上每个滤波就是一个视频,每一个小透镜就是一个小图象,这些差异需要处理。

再后来数据采集就是点云采集,把人脸模型变成动画场面。后面我们要把三维场景传输过去,这是下一步场景三维模型建模的技术发展方向。在这块MPE也是比较迅速。
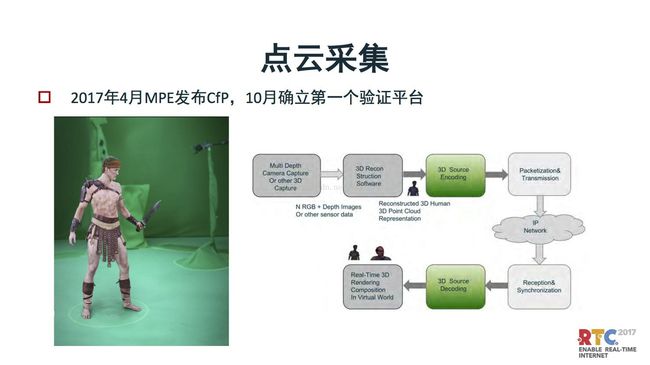
在今年4微分发布的CFP,大概10月份确立第一个验证平台,这个是类似于AR、VR可以把动态模型用三维模型传输过去。
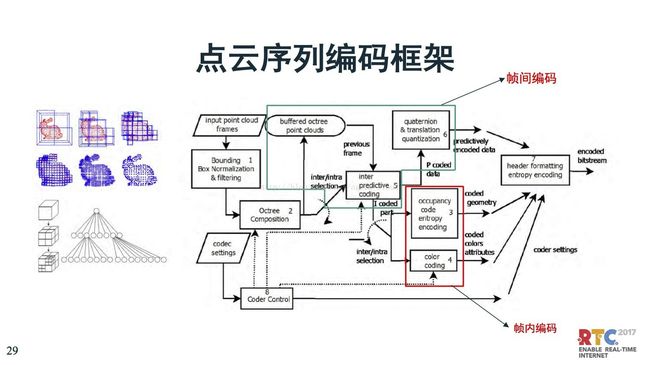
这块是序列编码框架,把编码数据包装到每一个盒子里面,当然对于点云的数据要复杂的多一些。
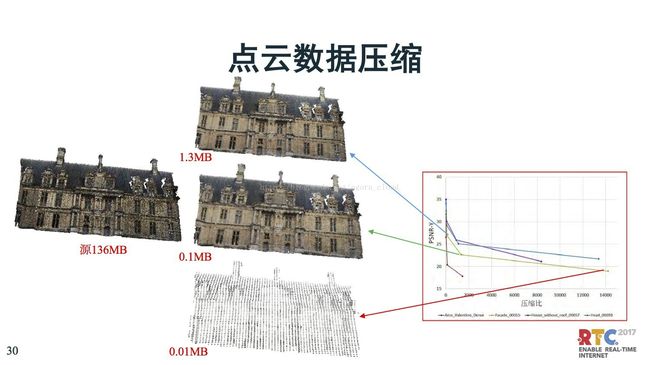
这是对比的效果图,可以看到这是原始数据,一帧电晕可能是136MB,我们看到压缩一千倍、一万倍,信息会丢掉不少。
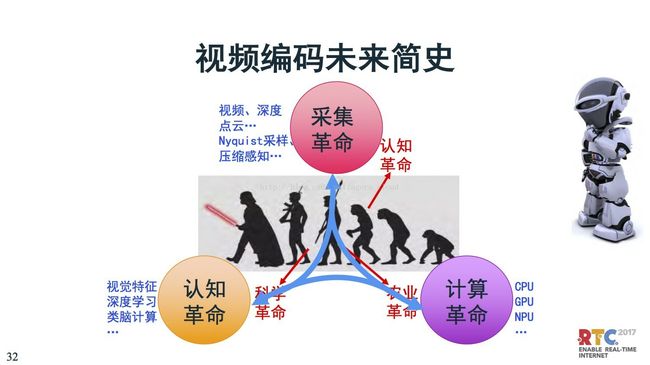
下面讨论关于未来,本来简史我们很熟悉,包括人类简史、未来简史,包括赫拉利讲到人类简史说三个革命,一个是认知革命,因为认知革命会制造工具,还有一个是农业革命可以养活更多的人,因为有个更多的人,才有人力去搞科学革命。
在视频编码方面,我把认知革命改成“采集革命”。视频采集的深度、点云、以及压缩感知,Nyquist采样定理等对采集有很大影响。采集是编码的源头,采集会影响到编码的框架设计。
第二个计算革命,刚刚说农业可以创造更多的粮产,可以养活更多的人。在视频编码领域,能编码,是因为计算能力的支持。计算的初期是基于像素、后来是基于块,现在有更多更复杂的计算。早期是CPU,后来GPU,现在有NPU。这些计算能力很强大,但是视频编码目前还没有利用上这些计算能力。目前正在探索,利用这些计算能力现在在探索基于神经网络的编码,就是想利用这种更高效的计算能力。
第三个是科学革命,我认为对于编码来说是认知革命。认识视频里的内容,对内容有所识别。这里面包括简单的视觉特征,高级一点是深度学习,更高级是类脑计算学习。这个过程是支持未来视频编码的方向。
这三者相辅相成,采集有新东西了,计算能力要跟上。计算越强会支持采集。同样对于认知也是,计算能力更强也会加强认知。所以这三者是相互支撑的关系。
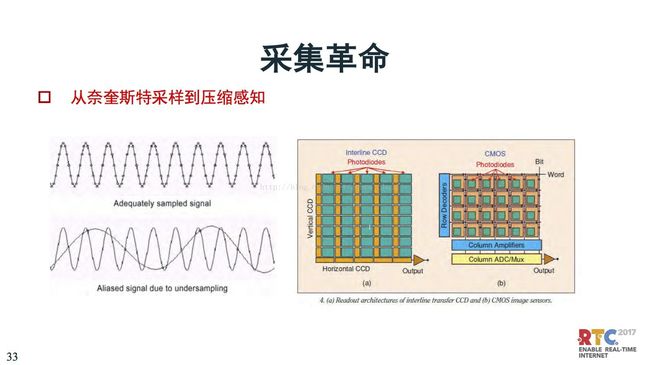
我们下面看采集革命,输出的时候是离散的数字信号,这里面最有名的就是奈奎斯特采样定理,是要过采样。4K、8K那么大,采集到的数据有很多是冗余的,是为了重建。
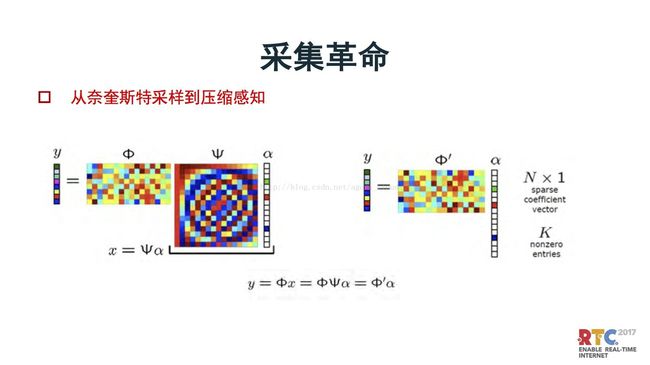
但是这种采集,与人眼的处理差别是很大的。这里引入了压缩感知,采样时强调稀疏采样。

这里面一个直接的应用,e是原图象。采样时通过系数采样,只采样20%的象素,采集到的是a,再基于稀疏图象的原理还原成e。数据量大大降低。
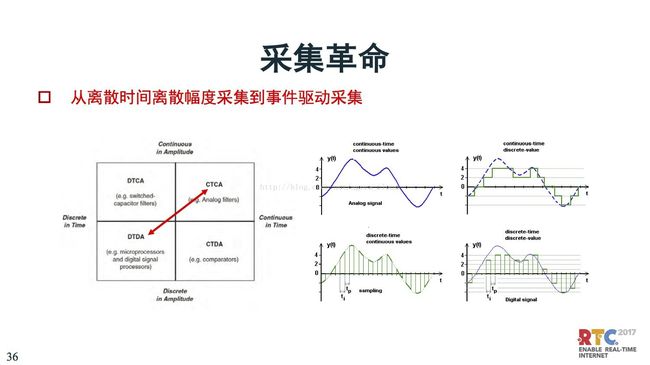
信号采集在时间上和幅度上都是离散的,这就是离散信号。但是离散信号带来的问题就是数据量增加特别多。这都是过采样的方式。
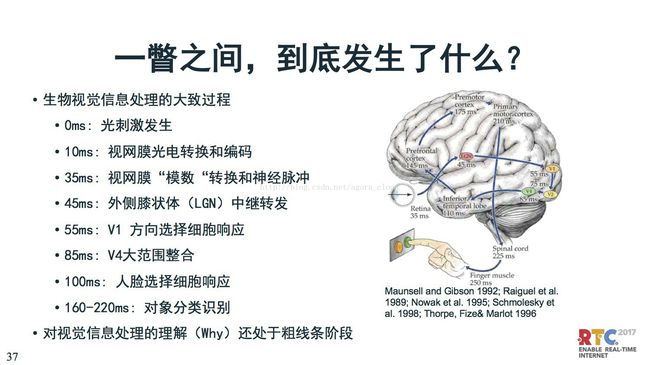
但是人脑的采集过程是,一开始是光刺激发生,通过视网膜光电转换和编码,最后通过视网膜认出来。从图像出来到人脑把这个图像认出来,需要经过160ms。肯定今天的采集技术是比人眼采集频率高很多,但是智能分析识别上人要比设备高很多。
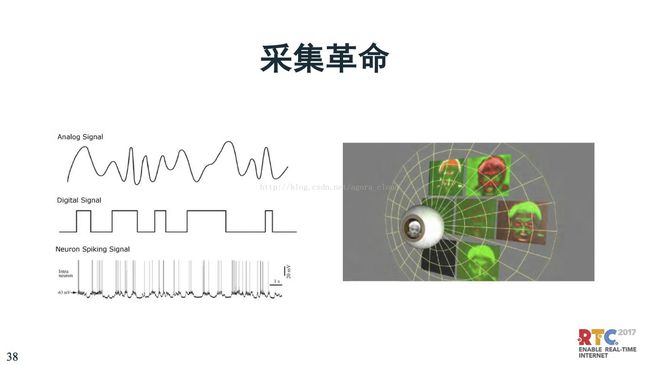
人脸采集不一样,上面是模拟信号,下面是数据信号,实际上我们人眼被称之为神经脉冲编码,是指当人看到一个东西如果没有发生变化,是不发放神经脉冲的,相当于不传信号。所以,人脑的功耗是特别的。如果人脑的功耗也很高,就会把大脑烧掉。所以,人是靠很低功耗的计算,来实现分析识别。

这是一个很低功耗的图象传感器,区别于传统的CMOS、CCD,做阵列刷新。这是一种事件驱动的采集,对于事件的发生分析,精度要求是很高效。
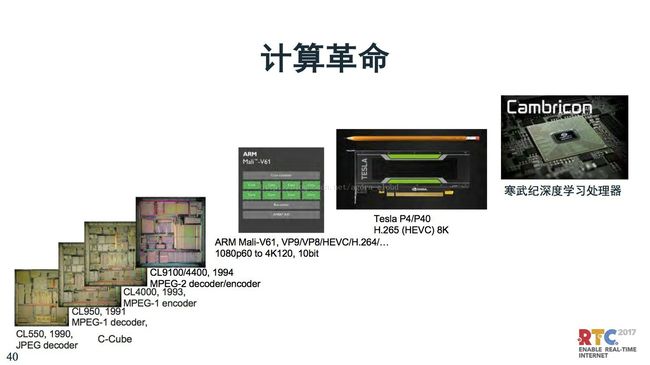
计算革命我也有一些思考.一个是我们知道前端计算,对于视频编解码都有专门的芯片,比如早期的C-Cube的处理器,VCD、DVD都使用这种处理器。最近有很强的ARM处理器可以支持4K,Tesla在使用的H.265编解码器,可以处理8K。最新的寒武纪深度学习神经网络处理器。
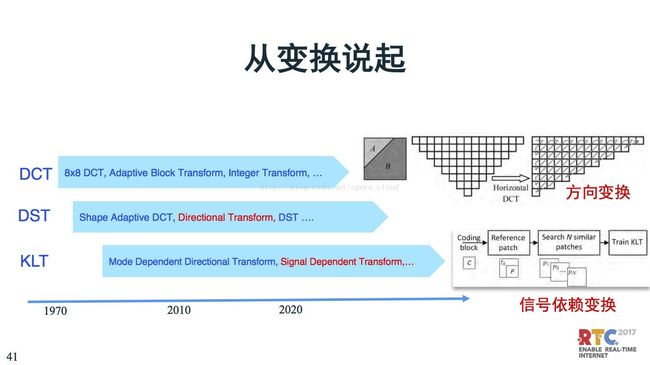
这里我们还是从变换说起,变换是视频编码很重要的模块,最早的变化是基于8x8 DCT。DCT的好处是当信号相关性很强,相关系数达到0.95的时候,DCT就是最优的变换。但是实际信号差别很大,如果图像一旦有边缘,DCT就变得不高效,因为相关性降低了。这是就提出了基于方向的变化,排列一下,分别进行相关性变换。基于这种原理,扩展出了DST,离散正弦变化。到了正弦变化之后还不算完,在H.265发展过程开始通过寻来找KLT最优变换。在H.266提出了更新的做法,原来是离线训练,H.266中使用在线训练,通过前面一两帧的数据在线训练。
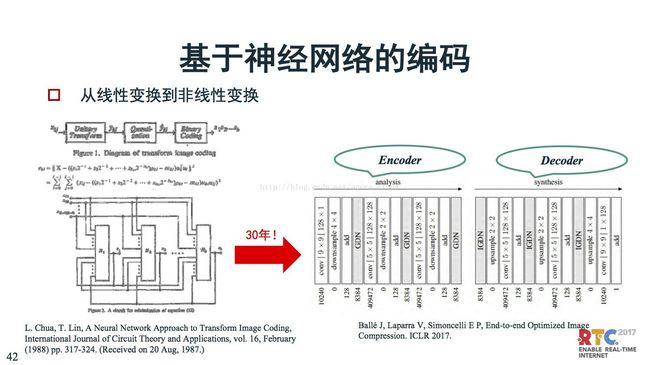
1987年,神经网络编码提出。最近,Google开始引发关于神经网络编码的革命。这么多年的发展,神经网络编码的原理,基本上还是想通的。

上文讲的是神经网络可以进行更多的计算,那么这里给一个例子,进行这么多计算,作用在哪?左边是缩倍率示意图,右边是编码复杂度示意图,我们关注最后面两个,一个是JPEG和Residual(基于神经网络的编码)的GRU和CPU。压缩倍率,JPEG和Residual的都是15倍。在计算复杂度上,如果把JPEG当做是1,那么Residual在GPU上进行的编码复杂度是3200,在CPU上的是26万。
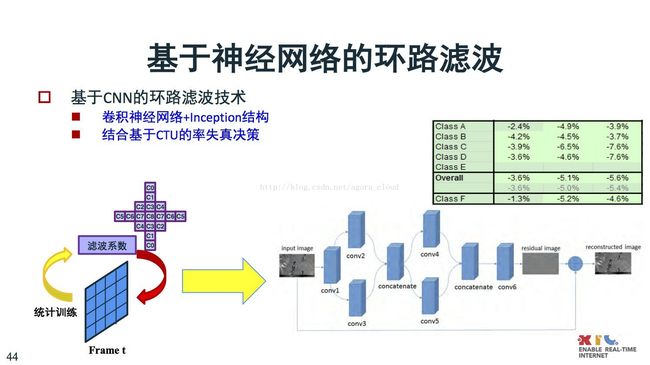
原来做滤波是做统计,求一个最优的滤波系数。这也可以用神经网络代替,基于神经网络做滤波,不训练,直接通过神经网络就能计算的特别好。
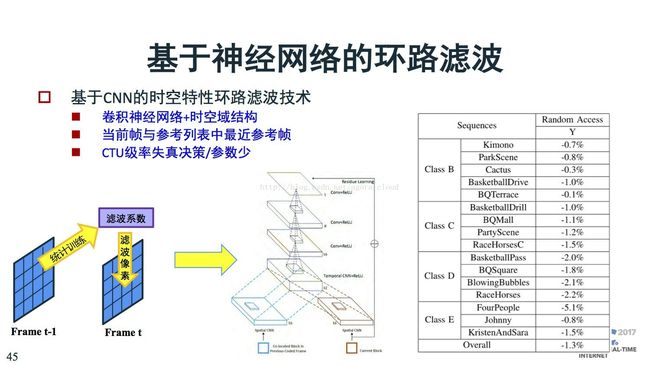
前文是基于空域的滤波。还有基于时域的,像和帧之间的相关性,也可以用上,通过训练改善优化,都能获得性能的提升。

神经网络也可以做生成预测。
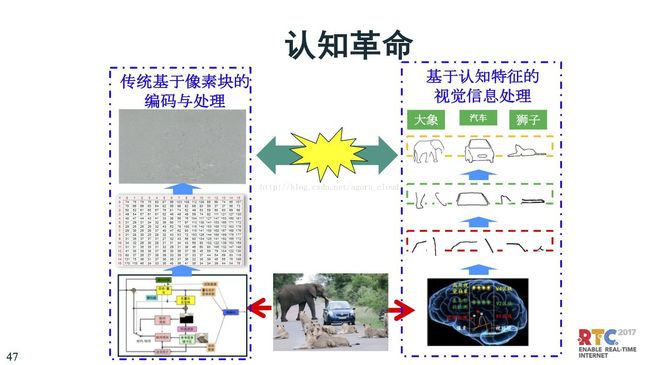
最后一块是认知革命。认知革命是讲前端处理都是基于块,我们看到的块都是像素值、是数。但是人脑处理的时候从边缘到轮廓到对象,差别很大。如果更高效、更智能的编码,应该是基于特征的编码,才可以做更高效的分析处理。

近期就是基于特征的编码(CDVA),最新的2018年的标准。视频监控是一个典型应用。上百万路视频,如果是传统的编码,数据量达到1Tbps,如果是CDVA,则数据量降到10Gbps,上万倍压缩比。传很少的数据达到分析识别的目的。
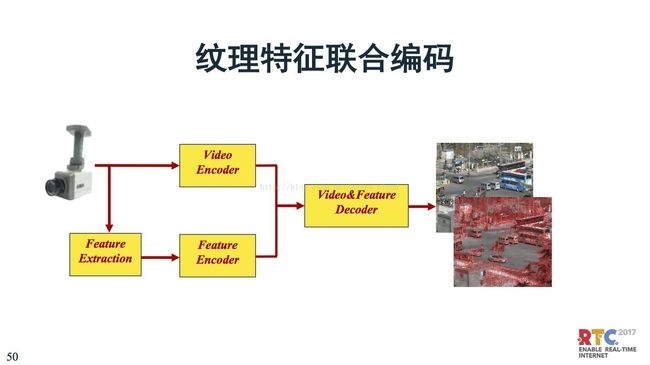
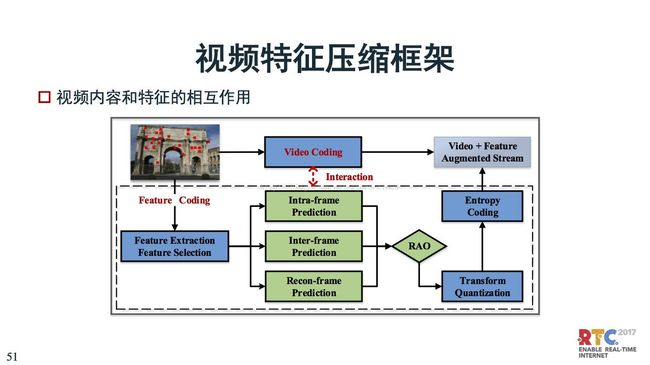
纹理特征联合编码,现在已经有一些方案了。一路传视频、一路传特征,来辅助分析识别。
总结:
4K正在普 ,8K是未来趋势,下一代标准值得关注
采集革命进一步扩展了视觉数据的维度,丰富了视觉数据编码的多样性
采集、计算和认知技术的融合,使得智能编码成为可能