Kafka
一、kafka
按照搭建hadoop完全分布式集群博文搭建完hadoop集群后,发现hadoop完全分布式集群自带了HDFS,MapReduce,Yarn等基本的服务,一些其他的服务组件需要自己重新安装,比如Hive,Hbase,sqoop,zookeeper,spark等,这些组件集群模式都在前面相关博文中有介绍,今天我们需要安装另外一个组件,它就是分布式消息系统Kafka。
Kafka介绍
Kafka是由LinkedIn开发的一个分布式基于发布/订阅的消息系统,使用Scala编写,它以可水平扩展和高吞吐率而被广泛使用。
Kafka是什么?举个例子,生产者消费者,生产者生产鸡蛋,消费者消费鸡蛋,生产者生产一个鸡蛋,消费者就消费一个鸡蛋,假设消费者消费鸡蛋的时候噎住了(系统宕机了),生产者还在生产鸡蛋,那新生产的鸡蛋就丢失了。再比如生产者很强劲(大交易量的情况),生产者1秒钟生产100个鸡蛋,消费者1秒钟只能吃50个鸡蛋,那要不了一会,消费者就吃不消了(消息堵塞,最终导致系统超时),消费者拒绝再吃了,”鸡蛋“又丢失了,这个时候我们放个篮子在它们中间,生产出来的鸡蛋都放到篮子里,消费者去篮子里拿鸡蛋,这样鸡蛋就不会丢失了,都在篮子里,而这个篮子就是”kafka“。鸡蛋其实就是“数据流”,系统之间的交互都是通过“数据流”来传输的(就是tcp、http什么的),也称为报文,也叫“消息”。消息队列满了,其实就是篮子满了,”鸡蛋“放不下了,那赶紧多放几个篮子,其实就是kafka的扩容。
就类似微博,有人发布消息,有人消费消息,这就是一个Kafka的场景。
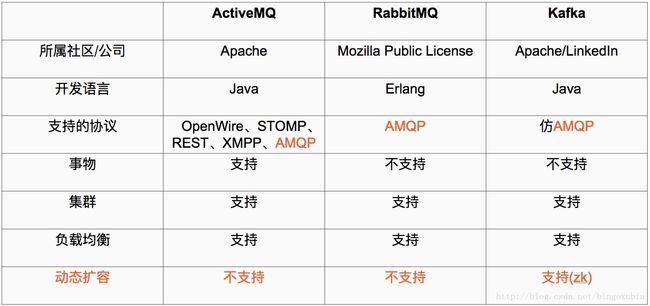
Kafka和其他主流分布式消息系统的对比
- 定义:
-
1、Java 和 scala都是运行在JVM上的语言。
2、erlang和最近比较火的和go语言一样是从代码级别就支持高并发的一种语言,所以RabbitMQ天生就有很高的并发性能,但是 有RabbitMQ严格按照AMQP进行实现,受到了很多限制。kafka的设计目标是高吞吐量,所以kafka自己设计了一套高性能但是不通用的协议,他也是仿照AMQP( Advanced Message Queuing Protocol 高级消息队列协议)设计的。
3、事物的概念:在数据库中,多个操作一起提交,要么操作全部成功,要么全部失败。举个例子, 在转账的时候付款和收款,就是一个事物的例子,你给一个人转账,你转成功,并且对方正常行收到款项后,这个操作才算成功,有一方失败,那么这个操作就是失败的。
对应消在息队列中,就是多条消息一起发送,要么全部成功,要么全部失败。3个中只有ActiveMQ支持,这个是因为,RabbitMQ和Kafka为了更高的性能,而放弃了对事物的支持 。
4、集群:多台服务器组成的整体叫做集群,这个整体对生产者和消费者来说,是透明的。其实对消费系统组成的集群添加一台服务器减少一台服务器对生产者和消费者都是无感之的。
5、负载均衡,对消息系统来说负载均衡是大量的生产者和消费者向消息系统发出请求消息,系统必须均衡这些请求使得每一台服务器的请求达到平衡,而不是大量的请求,落到某一台或几台,使得这几台服务器高负荷或超负荷工作,严重情况下会停止服务或宕机。
6、动态扩容是很多公司要求的技术之一,不支持动态扩容就意味着停止服务,这对很多公司来说是不可以接受的。
操作步骤
1. 安装Kafka之前需要安装zookeeper集群
请参考zookeeper集群搭建博文
2. 下载Kafka安装压缩包
Kafka2.11安装包下载地址,下载完毕后,上传到主节点的/opt目录下
Kafka其他版本安装包下载地址
3. 解压Kafka并更换目录名
# cd /opt
# tar -xzvf kafka_2.11-0.10.2.1.tgz
# mv kafka_2.11-0.10.2.1 kafka2.11
# chmod 777 -R /opt/kafka2.11 #为kafka目录进行授权
4. 配置环境变量
# vim /etc/profile
export KAFKA_HOME=/opt/kafka2.11
export PATH=$PATH:$KAFKA_HOME/bin #在最后添加这两行Kafka的配置
# source /etc/profile #使配置生效
5. 修改Kafka的server.properties配置
# cd /opt/kafka2.11/config
# vim server.properties
修改如下:
broker.id=1 #每台服务器的broker.id都不能相同
message.max.byte=5242880 #在log.retention.hours=168属性下加上如下三行配置
default.replication.factor=3
replica.fetch.max.bytes=5242880
zookeeper.connect=192.168.210.70:2181,192.168.210.71:2181,192.168.210.72:2181 #修改zookeeper引用外部的zookeeper
6. 将上述在其余节点也布置一下
# cd /opt
# scp -r kafka2.11 root@hadoop1:/opt/
# scp -r kafka2.11 root@hadoop2:/opt/
注意:修改环境变量,修改配置文件的broker.id
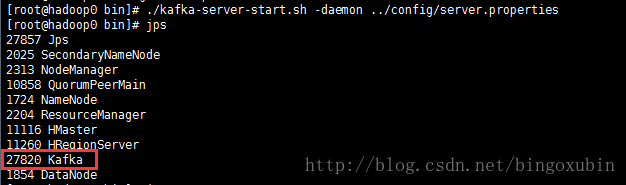
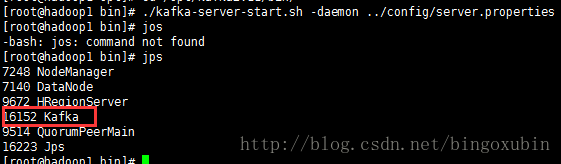
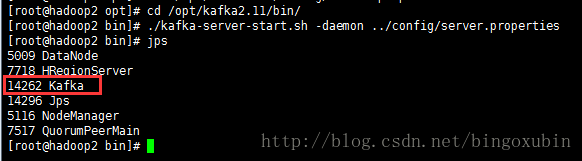
7. 启动服务
#从后台启动Kafka集群(3台都需要启动)
# cd /opt/kafka2.11/bin #进入到kafka的bin目录
# ./kafka-server-start.sh -daemon ../config/server.properties
主节点:
两个从节点:
二、测试
按照Hadoop完全分布式安装Kafka博文搭建完Kafka2.11集群后,需要简单试用,来体会Kafka的工作原理,以及如何进行使用,感受分布式消息队列系统。
操作步骤
思路:搭建了三个节点的Kafka集群,在主节点创建一个topic,作为生产者,两个从节点作为消费者分别看看能否接收数据,进行验证
步骤一,在主节点执行
创建topic及查看topic命令
#查看所有topic命令如下
# kafka-topics.sh -list -zookeeper 192.168.210.70:2181,192.168.210.71:2181,192.168.210.72:2181
# (rf参数副本数,par参数分区数,xubin是topic的名称)创建topic命令如下
# kafka-topics.sh --create --zookeeper 192.168.210.70:2181,192.168.210.71:2181,192.168.210.72:2181 --replication-factor 3 --partitions 1 --topic xubin
在主节点查看topic,发现没有,进行创建topic为xubin,重新进行查看topic,发现存在了!

同理,一开始在从节点上看不到topic,当在主节点上创建了topic后,在从节点也能查到topic!

步骤二,在主节点创建生产者,在两个从节点分别创建消费者
开启生产者以及消费者
#开启生产者命令如下:
# kafka-console-producer.sh --broker-list 192.168.210.70:9092,192.168.210.71:9092,192.168.210.72:9092 --topic xubin
#开启生产者命令如下:
# kafka-console-consumer.sh --zookeeper 192.168.210.70:2181,192.168.210.71:2181,192.168.210.72:2181 --topic xubin --from-beginning 消费者
在主节点开启生产者:

在两个从节点分别开启消费者:


步骤三,在生产者中输入信息,看消费者中是否能拿到数据
生产者:

消费者:


三、删除topic
按照Kafka集群的测试和简单试用博文进行了对Kafka的使用,与topic创建,并且模拟了消息的生产者,消息的消费者进行模拟环境,验证Kafka可以执行,但是想到,建立了topic,如何进行删掉呢?这是一个问题。
操作步骤
方法一:修改配置文件,通过命令删除
修改配置文件server.properties
# vim /opt/kafka2.11/config/server.properties
delete.topic.enable=true #添加这条配置
注:如果想删除topic,此项配置必须为true,默认为false。配置完重启kafka、zookeeper。
#然后,才能通过命令删除topic
# kafka-topics --delete --zookeeper 【zookeeper server】 --topic 【topic name】
方法二:不修改配置文件,直接强制删除
1、删除kafka存储目录/tmp/kafka-logs下对应的topic。【注:删除所有节点的topic目录】
2、进入zookeeper客户端删掉对应topic
# zkCli.sh -server 127.0.0.1:2181
找到topic目录
ls /brokers/topics
删掉对应topic
rmr /brokers/topic/topic-name
找到目录
ls /config/topics
删掉对应topic
rmr /config/topics/topic-name
[root@hadoop2 bin]# zkCli.sh -server 192.168.210.70:2181
Connecting to 192.168.210.70:2181
2017-11-23 17:19:11,418 [myid:] - INFO [main:Environment@100] - Client environment:zookeeper.version=3.4.10-39d3a4f269333c922ed3db283be479f9deacaa0f, built on 03/23/2017 10:13 GMT
2017-11-23 17:19:11,421 [myid:] - INFO [main:Environment@100] - Client environment:host.name=hadoop2
2017-11-23 17:19:11,421 [myid:] - INFO [main:Environment@100] - Client environment:java.version=1.8.0_152
2017-11-23 17:19:11,423 [myid:] - INFO [main:Environment@100] - Client environment:java.vendor=Oracle Corporation
2017-11-23 17:19:11,423 [myid:] - INFO [main:Environment@100] - Client environment:java.home=/opt/jdk1.8/jre
2017-11-23 17:19:11,423 [myid:] - INFO [main:Environment@100] - Client environment:java.class.path=/opt/zookeeper3.4.10/bin/../build/classes:/opt/zookeeper3.4.10/bin/../build/lib/*.jar:/opt/zookeeper3.4.10/bin/../lib/slf4j-log4j12-1.6.1.jar:/opt/zookeeper3.4.10/bin/../lib/slf4j-api-1.6.1.jar:/opt/zookeeper3.4.10/bin/../lib/netty-3.10.5.Final.jar:/opt/zookeeper3.4.10/bin/../lib/log4j-1.2.16.jar:/opt/zookeeper3.4.10/bin/../lib/jline-0.9.94.jar:/opt/zookeeper3.4.10/bin/../zookeeper-3.4.10.jar:/opt/zookeeper3.4.10/bin/../src/java/lib/*.jar:/opt/zookeeper3.4.10/bin/../conf:.:/opt/jdk1.8/lib/dt.jar:/opt/jdk1.8/lib/tools.jar
2017-11-23 17:19:11,423 [myid:] - INFO [main:Environment@100] - Client environment:java.library.path=/usr/java/packages/lib/amd64:/usr/lib64:/lib64:/lib:/usr/lib
2017-11-23 17:19:11,424 [myid:] - INFO [main:Environment@100] - Client environment:java.io.tmpdir=/tmp
2017-11-23 17:19:11,424 [myid:] - INFO [main:Environment@100] - Client environment:java.compiler=
2017-11-23 17:19:11,424 [myid:] - INFO [main:Environment@100] - Client environment:os.name=Linux
2017-11-23 17:19:11,424 [myid:] - INFO [main:Environment@100] - Client environment:os.arch=amd64
2017-11-23 17:19:11,424 [myid:] - INFO [main:Environment@100] - Client environment:os.version=3.10.0-327.el7.x86_64
2017-11-23 17:19:11,424 [myid:] - INFO [main:Environment@100] - Client environment:user.name=root
2017-11-23 17:19:11,424 [myid:] - INFO [main:Environment@100] - Client environment:user.home=/root
2017-11-23 17:19:11,424 [myid:] - INFO [main:Environment@100] - Client environment:user.dir=/opt/kafka2.11/bin
2017-11-23 17:19:11,425 [myid:] - INFO [main:ZooKeeper@438] - Initiating client connection, connectString=192.168.210.70:2181 sessionTimeout=30000 watcher=org.apache.zookeeper.ZooKeeperMain$MyWatcher@446cdf90
Welcome to ZooKeeper!
2017-11-23 17:19:11,446 [myid:] - INFO [main-SendThread(192.168.210.70:2181):ClientCnxn$SendThread@1032] - Opening socket connection to server 192.168.210.70/192.168.210.70:2181. Will not attempt to authenticate using SASL (unknown error)
JLine support is enabled
2017-11-23 17:19:11,501 [myid:] - INFO [main-SendThread(192.168.210.70:2181):ClientCnxn$SendThread@876] - Socket connection established to 192.168.210.70/192.168.210.70:2181, initiating session
2017-11-23 17:19:11,508 [myid:] - INFO [main-SendThread(192.168.210.70:2181):ClientCnxn$SendThread@1299] - Session establishment complete on server 192.168.210.70/192.168.210.70:2181, sessionid = 0x15fe7e814520010, negotiated timeout = 30000
WATCHER::
WatchedEvent state:SyncConnected type:None path:null
[zk: 192.168.210.70:2181(CONNECTED) 0] ls /brokers/topics
[xubin, xubin1]
[zk: 192.168.210.70:2181(CONNECTED) 1] ls /config/topics
[xubin, xubin1]
[zk: 192.168.210.70:2181(CONNECTED) 2]
注:两步全部执行才算彻底删除topic