【何之源-21个项目玩转深度学习】——Chapter2-2.1.3 Tensorflow的数据读取机制
何之源,知乎上的一个大大,推出了一本TF的实践书,本文是在看其资料时做的源码分析。
首先贴出其代码:
# coding:utf-8
import os
if not os.path.exists('read'):
os.makedirs('read/')
# 导入TensorFlow
import tensorflow as tf
# 新建一个Session
with tf.Session() as sess:
# 我们要读三幅图片A.jpg, B.jpg, C.jpg
filename = ['A.jpg', 'B.jpg', 'C.jpg']
# string_input_producer会产生一个文件名队列
filename_queue = tf.train.string_input_producer(filename, shuffle=False, num_epochs=5)
# reader从文件名队列中读数据。对应的方法是reader.read
reader = tf.WholeFileReader()
key, value = reader.read(filename_queue)
# tf.train.string_input_producer定义了一个epoch变量,要对它进行初始化
tf.local_variables_initializer().run()
# 使用start_queue_runners之后,才会开始填充队列
threads = tf.train.start_queue_runners(sess=sess)
i = 0
while True:
i += 1
# 获取图片数据并保存
image_data = sess.run(value)
with open('read/test_%d.jpg' % i, 'wb') as f:
f.write(image_data)
# 程序最后会抛出一个OutOfRangeError,这是epoch跑完,队列关闭的标志开头的coding=utf-8和coding:utf-8的作用是一样的。
作用是声明python代码的文本格式是utf-8,python按照utf-8的方式来读取程序。
如果不加这个声明,无论代码中还是注释中有中文都会报错。注意一点无论中间是:还是=,其中coding与它们之间都不能有空格。 (对于coding:utf-8和unicode概念详细可参考:coding=utf-8以及中文字符前加u的解释)
import os为了导入系统路径,判断当前目录下是否存在‘read’文件夹,如果不存在则创建。(详细可参考:import os用法总结)
with tf.Session() as sess: 表示启动一个会话,相比sess=tf.Session(),好处在于可实现自动关闭会话,而后者需要写sess.close()来关闭会话。 所有定义的操作op都需要再会话中才被执行,其中t.eval() 执行的动作就是 tf.Session().run(t)。(可参考:计算图,会话,tensor,feed, fetch概念)
tf.train.string_input_producer()的函数原型如下:
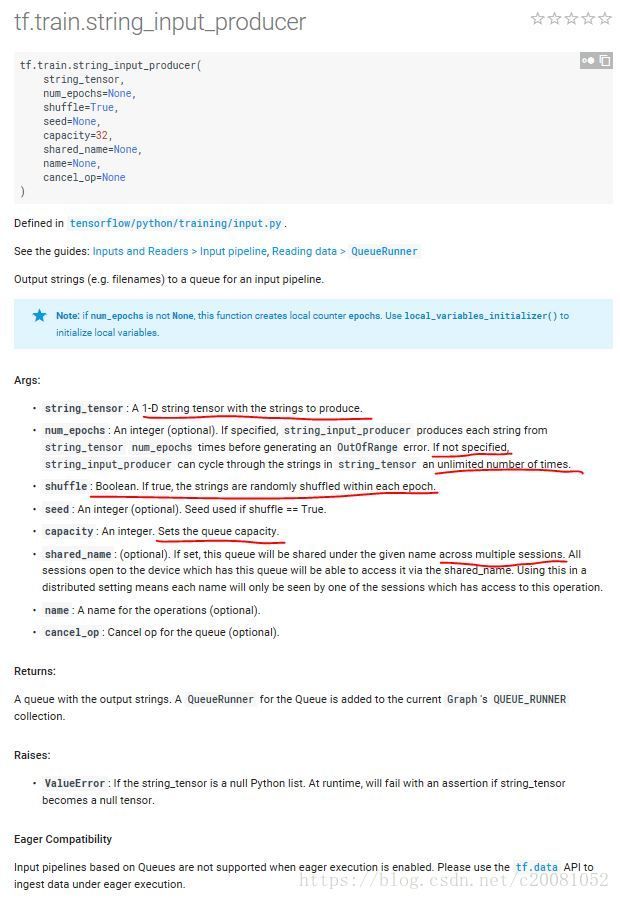
代码中传入的就是1-D的string tensor,注意默认的shuffle(打乱操作)是true的,容量大小是32(如未指定)。该函数把我们需要的全部文件打包为一个tf内部的queue类型,之后tf开文件就从这个queue中取目录了。
代码采用tf.WholeFileReader()来读取队列内容,其实Tensorflow读取器依据读取数据格式不同,提供了不同的读取器,例如:
- tf.ReaderBase
- tf.TextLineReader
- tf.WholeFileReader
- tf.IdentityReader
- tf.TFRecordReader
- tf.FixedLengthRecordReader
读取器差异可参考:数据读取器详细介绍
tensorflow的数据输入:tensorflow数据输入
tf.train.start_queue_runners 开始运行计算图中所有的队列。tf.train.start_queue_runners(sess=sess)这一步一定要运行,且其位置要在定义好读取graph之后,在真正run之前,其作用是把queue里边的内容初始化,不跑这句一开始string_input_producer那里就没用,整个读取流水线都没用了。原型如下:
tf.train.start_queue_runners(
sess=None,
coord=None,
daemon=True,
start=True,
collection=tf.GraphKeys.QUEUE_RUNNERS
)
sess:Sessionused to run the queue ops. Defaults to the default session.coord: OptionalCoordinatorfor coordinating the started threads.daemon: Whether the threads should be marked asdaemons, meaning they don't block program exit.start: Set toFalseto only create the threads, not start them.collection: AGraphKeyspecifying the graph collection to get the queue runners from. Defaults toGraphKeys.QUEUE_RUNNERS.
返回的是进程列表;
Returns: A list of threads.
代码的结果就是在read文件夹下生成5个epoch的图像(可以理解为队列中有5次重复的A.jpg,B.jpg,C.jpg读入)
