List (单链表17个函数讲解)
链表时一种常用的数据结构,是通过“链”来建立起数据元素之间的逻辑关系,这种用链接方式储存的线性表简称链表(Link List)。
一,链表与顺序表的对比
在接触链表之前大家想必已经了解过了顺序表的储存结构方式,顺序表与链表的不同之处如下:
1.顺序表是物理位置上相邻来表示数据元素之间的逻辑关系;但链表不是,物理地址不相连,通过指针来链接。
2.顺序表储存密度高,且能够随机的存取数据(通过下标);但链表不能随机访问,只能通过头指针遍历到指定节点遍历,这点没有顺序表方便。
3.顺序表插入删除操作,一般需要大量数据的移动,效率低下;链表无需移动数据,只改变指针的指向即可。
4.顺序表需要预先分配储存的空间,若表长过大,则存储规模难以预先确定,估计会过大的造成储存空间的浪费;链表由于是链式结构,无需过大的连续空间,链表结构可以充分利用计算机内存空间,实现灵活的内存动态管理。
二,单链表的定义
链表是通过一组任意的存储单元来存储线性表中的数据元素,各元素之间可以是不连续,为了建立起数据元素之间的线性关系,对于每个数据元素ai来说,除了存放数据元素自身的信息外,还必须有包含指示该元素后继元素的位置的信息—指针,数据域和指针两部分和起来我们称作—“结点”。以单链表为例,节点结构如下:
typedef struct List_Node{
struct List_Node *next;
int data;
}List_Node;构造完节点,多个节点相连就是我们的链式储存结构了,如图所示:
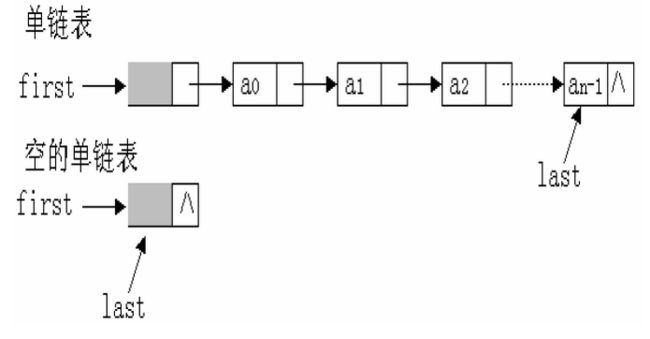
n个元素的线性表通过结点的指针域连接成一条“链子”,我们形象的称之为链表。因为每个结点中只有指向其后继的指针,所以称之为单链表。
为了操作方便,我们在链表之外构造一个“结点”,储存链表的头结点(链表的第一个结点),尾结点(链表的最后一个结点)和链表的结点个数。
typedef struct List{
struct List_Node *head;
struct List_Node *tail;
int count;
}List;这样就能清楚的反映链表信息,便于操作。
三,建立单链表
搭建一个链表,并实现以下基本函数:
enum Bool{
FALSE,
TRUE
};
typedef unsigned char Boolean;
typedef struct List{
struct List_Node *head;
struct List_Node *tail;
int count;
}List;
typedef struct List_Node{
struct List_Node *next;
int data;
}List_Node;
List *init_list(void); //初始化
void destroy_list(List **list); //销毁
Boolean push_back(List *list, int value); //尾插
Boolean pusn_front(List *list, int value); //头插
Boolean pop_back(List *list); //尾删
Boolean pop_front(List *list); //头删
void print_list(List *list); //显示搭建一个链表从链表初始化开始,链表的结点定义需要先申请空间,我们简单的封装下malloc,如下:
static void *Malloc(size_t size)
{
void *result = malloc(size);
if(result == NULL){
fprintf(stderr,"memory is full!\n");
exit(1);
}
return result;
}- 初始化链表时,我们有必要对Malloc的空间进行清除操作,bzero函数是将所指空间大小内的数据全部清零。
List *init_list(void) //初始化
{
List *list = NULL;
list = (List *)Malloc(sizeof(List));
bzero(list, sizeof(List));
return list;
}
static List_Node *create_node(void)
{
List_Node *node= (List_Node*)Malloc(sizeof(List_Node));
bzero(node, sizeof(List_Node));
return node;
}有初始化必然有销毁操作
void destroy_list(List **list) //销毁
{
if(list == NULL || *list){
return ;
}
while((*list)->count){
pop_back(*list);
}
free(*list);
*list = NULL;
}- 要构造链表,插入删除操作是必不可少的,而插入删除又分别分为头插,尾插,头删,尾删四种操作。
头插: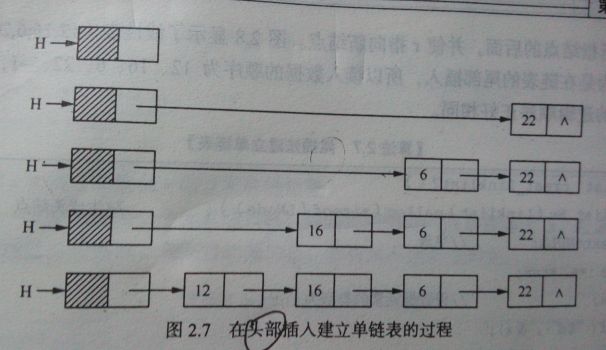
如图所示:情况1 当List中没有结点时,那么设置新结点既是头结点又是尾结点,count++;情况2 当List中有节点时,头插法首先要将新节点的next设为头结点(node->next = list->head),然后将新结点变为头结点(list->head = node),count++,完成。
Boolean push_front(List *list, int value) //头插
{
List_Node *node = NULL;
if(list == NULL){
return FALSE;
}
node = create_node();
node->data = value;
if(list->count){
node->next = list->head;
list->head = node;
}else{
list->head = list->tail = node;
}
list->count++;
return TRUE;
}尾插: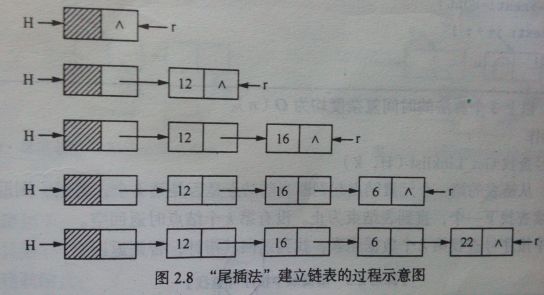
尾插法也分为两种情况 1.当没有结点时,新节点既是头结点,也是尾结点,count++。 2.有结点时,首先将尾结点的next域指向新节点(list->tail->next = node),然后再把新节点设置为尾结点(list->tail = node)。
需要注意的是,头插和尾插的两步操作不可颠倒,若先将新节点设置为头结点或者尾结点都将丢失原来的头结点尾结点!导致操作失败。
Boolean push_back(List* list, int value) //尾插
{
List_Node *node = NULL;
if(list == NULL){
return FALSE;
}
node = create_node();
node->data = value;
if(list->count){
list->tail->next = node;
list->tail = node;
}else{
list->head = list->tail = node;
}
list->count++;
return TRUE;
}头删
头删和头插相反,先将头指针设置为下一个结点(list->head = list->head->next),再把之前的头结点删除,count–。
Boolean pop_front(List* list) //头删
{
List_Node *p_node = NULL;
if(list == NULL || list->count <= 0){
return FALSE;
}
p_node = list->head;
if(list->count == 1){
list->head = list->tail = NULL;
}else{
list->head = list->head->next;
}
free(p_node);
list->count--;
return TRUE;
}尾删
尾删法有所不同,由于是单链表没有指向前一个结点的指针,我们需要把倒数第二个结点遍历查找出来当做新的尾结点,然后再删除之前的尾结点,count–。
Boolean pop_back(List* list) //尾删
{
List_Node *p_node = NULL;
if(list == NULL || list->count == 0){
return FALSE;
}
p_node = list->head;
if(list->count == 1){
list->head = list->tail = NULL;
free(p_node);
}else{
while(p_node->next != list->tail){
p_node = p_node->next;
}
free(list->tail);
list->tail = p_node;
p_node->next = NULL;
}
list->count--;
return TRUE;
}显示链表信息的函数如下:
void print_list(List *list) //显示
{
List_Node *p_node = NULL;
if(list != NULL && list->count > 0){
for(p_node = list->head; p_node; p_node = p_node->next){
printf("%d ", p_node->data);
}
printf("\n");
}
}四,复杂一点的链表操作
有了第三部分的操作代码,链表已经完成了基本的搭建,但是这样的链表只能储存数据,实际应用价值不大。我们还需要对链表进行一些复杂的操作:
void sort_list_ascend(List *list); //升序
List *merge_two_lists(List *list1, List *list2);//合并两个链表
List_Node *find_node(List *list, int num); //找到链表中倒数第几个节点
List *reverse_list(List *list); //逆序
List *copy_list(List *list); //链表的拷贝
Boolean is_list_intersect(List *list1, List *list2);//两个链表是否有交点
List_Node *find_first_common_node(List *list1, List *list2);//找出第一个交点
void delete_one_node(List *list, List_Node *node);//删除链表的一个交点
Boolean has_circle(List *list); //判断链表是否有环
List_Node *find_circle_begin(List *list); //找到环入口链表的排序
以升序为例,链表的排序是对所储存的data值进行排序,其排序原理和平常的排序一样,但操作上有所区别。循环判断条件可以是结点个数count,也可以是结点不等于NULL(尾结点的下一个结点为NULL)。这里链表在排序时为了效率,不交换结点,只交换结点的data域。
void sort_list_ascend(List *list) //升序
{
List_Node *p_node = NULL;
List_Node *q_node = NULL;
if(list == NULL || list->count < 2){
return ;
}
for(p_node = list->head; p_node->next; p_node = p_node->next){
for(q_node = p_node->next; q_node; q_node = q_node->next){
if(q_node->data < p_node->data){
swap(&q_node->data, &p_node->data, sizeof(int));
}
}
}
}
void swap(void *a, void *b, int length)
{
void *temp = malloc(length);
memcpy(temp, a, length);
memcpy(a, b, length);
memcpy(b, temp, length);
free(temp);
}合并两个链表也是常用的函数
首先两个链表得是有序的链表,利用归并排序的思想,在常数的时间复杂度就可以完成两个有序链表的合并。
List *merge_two_lists(List *list1, List *list2)//合并两个链表
{
List_Node *p_node = NULL;
List_Node *q_node = NULL;
List *result = NULL;
if(list1 == NULL){
return copy_list(list2);
}else if(list2 == NULL){
return copy_list(list1);
}
sort_list_ascend(list1);
sort_list_ascend(list2);
result = init_list();
p_node = list1->head;
q_node = list2->head;
while(p_node && q_node){
if(p_node->data < q_node->data){
push_back(result, p_node->data);
p_node = p_node->next;
}else{
push_back(result, q_node->data);
q_node = q_node->next;
}
}
while(p_node){
push_back(result, p_node->data);
p_node = p_node->next;
}
while(q_node){
push_back(result, q_node->data);
q_node = q_node->next;
}
return result;
}找到链表的倒数第几个结点在其他函数中也是必须的操作。
由于单链表没有回溯指针,我们只能又得从头结点开始遍历,通过move定位指定节点。
List_Node *find_node(List *list, int num) //找到链表中倒数第几个节点
{
List_Node *p_node = NULL;
int move = 0;
if(list == NULL || num <= 0 || num > list->count){
return NULL;
}
p_node = list->head;
move = list->count - num;
while(move--){
p_node = p_node->next;
}
return p_node;
}删除链表的一个结点
这和头删尾删是不同的,在中间删除结点时,需要将所删结点的前一个结点的next指向所删结点的下一个结点。问题在于单链表没有指向之前结点的指针,如何找到前一个结点?如果又用遍历的话,效率太低了,我们有更巧妙的方法。
我们改变思路,将下一个结点的data值给原本要删的结点,将原本要删的结点的next指向下的结点的下个结点,将下一个结点删除。由于所要删除的结点的值被下个结点的覆盖,且下个结点值被保存,所以虽然删除的不是所指的结点,但实际上等同于删除了所指结点。
void delete_one_node(List *list, List_Node *node)//删除链表的一个结点
{
if(list == NULL || node == NULL){
return ;
}
List_Node *p_node = NULL;
if(node != list->tail){
p_node = node->next;
node->data = p_node->data;
node->next = p_node->next; //巧妙的思想
free(p_node);
list->count--;
}else{
pop_back(list);
}
}链表的逆序
非常实用的操作,思想是从头遍历,将data头插入新的链表,新的链表是头插法构建,与原链表是逆序的,返回新链表。
List *reverse_list(List *list) //逆序
{
if(list == NULL || list->count < 2){
return NULL;
}
List_Node *p_node = NULL;
List *result = NULL;
result = init_list();
p_node = list->head;
while(p_node->next){
push_front(result, p_node->data);
p_node = p_node->next;
}
push_front(result, p_node->data);
return result;
}链表的拷贝
List *copy_list(List *list) //链表的拷贝
{
if(list == NULL){
return NULL;
}
List_Node *p_node = NULL;
List *result = NULL;
result = init_list();
p_node = list->head;
while(p_node){
push_back(result, p_node->data);
p_node = p_node->next;
}判断两个链表有没有交点
链表是否交点问题和是否有环问题是面试时常问的问题。
怎样判断两个链表有交点?链表如果有交点,那么交点之后的链表一定合二为一,成为了一条链表。也就是说,它们的尾结点一定是相同的!
Boolean is_list_intersect(List *list1, List *list2)//两个链表是否有交点
{
if(list1 == NULL || list2 == NULL){
return FALSE;
}
return list1->tail == list2->tail;
}求出第一个交点
上面的如果你想出来了,那么面试官一般还会让你求出两条链表交点的位置。
这么思考,若有交点,交点之后的结点必定一模一样,若两条链表count数不同,我们就让长的链表先遍历,当两个一样长时,同时遍历,并判断是否是相同结点,若有交点,在尾结点之前一定可以找到。
List_Node *find_first_common_node(List *list1, List *list2)//找出第一个交点
{
int l1_len = 0;
int l2_len = 0;
List_Node *p_node = NULL;
List_Node *q_node = NULL;
int move = 0;
if(!is_list_intersect(list1, list2)){
return NULL;
}
l1_len = list1->count;
l2_len = list2->count;
p_node = list1->head;
q_node = list2->head;
if(l1_len > l2_len){
move = l1_len - l2_len;
while(move--){
p_node = p_node->next;
}
}else{
move = l2_len - l1_len;
while(move--){
q_node = q_node->next;
}
}
while(p_node != q_node){
q_node = q_node->next;
p_node = p_node->next;
}
return q_node;
}判断一个链表是否有环
这又是一个面试热题,既考了链表又考了你的思维。
一个链表有环,必然是循环结构。1. 对链表的head到倒数第二个节点进行遍历,如果其中任意一个节点地址和list->tail相等,则说明有环。2. 利用快慢指针 ,fast每次移动两个,slow每次移动一个,判断fast和slow是否相等,如果相等,有环
(在环里跑,快的总能追上慢的)。
Boolean has_circle(List *list) //判断链表是否有环
{
List_Node *p_node = NULL;
if(list == NULL || list->count < 2 || list->tail->next == NULL){
return FALSE;
}
//对链表的head到倒数第二个节点进行遍历,如果其中任意一个节点地址和list->tail相等,则说明有环
p_node = list->head;
while(p_node != NULL){
if(list->tail->next == p_node){
return TRUE;
}
p_node = p_node->next;
}
return FALSE;
}
Boolean has_circle2(List *list, List_Node **intersect)
{
List_Node *fast = NULL;
List_Node *slow = NULL;
if(list == NULL || list->count < 2){
return FALSE;
}
fast = slow = list->head;
//fast每次移动两个,slow每次移动一个,判断fast和slow是否相等,如果相等,有环。
while(fast && fast->next){
fast = fast->next->next;
slow = slow->next;
if(fast == slow){
if(intersect != NULL){
*intersect = fast;
}
return TRUE;
}
}
return FALSE;
} 找到环入口
上一个问题回答出来,这个问题也就比较容易解决了。我们换个思路将这个链表“拆”为两个链表,问题就转化为,求两个链表交点的问题。
List_Node *find_circle_begin1(List *list) //找到环入口
{
if(!has_circle(list)){
return NULL;
}
return list->tail->next;
}
List_Node *find_circle_begin(List *list) //找到环入口
{
List_Node *intersect = NULL;
if(!has_circle2(list, &intersect)){
return NULL;
}
}