认真的虎ORBSLAM2源码解读(四):图解ORB特征提取ORBextractor
目录
- 1.参考博客
- 1.1.理论基础参考
- 1.2.参考博客
- 2.头文件ORBextractor.h
- 3.源文件ORBextractor.cc
- 3.1.类ORBextractor构造函数
- 3.1.1.umax的计算
- 3.2.重载ORBextractor::operator()
- 3.3.类方法ORBextractor::ComputePyramid(cv::Mat image)
- 3.4.类方法ORBextractor::ComputeKeyPointsOctTree()
- 3.5.类方法ORBextractor::DistributeOctTree()
- 3.5.1.根节点数量
- 3.5.2.分配关键点
- 3.5.3.不断分裂双向链表lNodes中的节点
- 3.6.类方法ExtractorNode::DivideNode()
- 3.7.函数IC_Angle()
- 3.8.函数computeDescriptor()
1.参考博客
1.1.理论基础参考
Oriented FAST and Rotated BRIEF
Features From Accelerated Segment Test
Binary Robust Independent Elementary Features
Sift中尺度空间、高斯金字塔、差分金字塔(DOG金字塔)、图像金字塔
1.2.参考博客
ORB-SLAM2的源码阅读(二):ORB特征提取
一起学ORBSLAM(2)ORB特征点提取
ORBSLAM2源码学习(1)ORBextractor
2.头文件ORBextractor.h
// 分配四叉树时用到的结点类型
class ExtractorNode {
public:
ExtractorNode() : bNoMore(false) {}
void DivideNode(ExtractorNode &n1, ExtractorNode &n2, ExtractorNode &n3, ExtractorNode &n4);
std::vector<cv::KeyPoint> vKeys;
cv::Point2i UL, UR, BL, BR;
std::list<ExtractorNode>::iterator lit;
bool bNoMore;
};
class ORBextractor
{
public:
enum {HARRIS_SCORE=0, FAST_SCORE=1 };
//nfeatures,ORB特征点数量 scaleFactor,相邻层的放大倍数 nlevels,层数 iniThFAST,提取FAST角点时初始阈值 minThFAST提取FAST角点时,更小的阈值
//设置两个阈值的原因是在FAST提取角点进行分块后有可能在某个块中在原始阈值情况下提取不到角点,使用更小的阈值进一步提取
//ORBextractor构造函数
///功能:提取特征前的准备工作
ORBextractor(int nfeatures, float scaleFactor, int nlevels,
int iniThFAST, int minThFAST);
~ORBextractor(){}
// Compute the ORB features and descriptors on an image.
// ORB are dispersed on the image using an octree.
// Mask is ignored in the current implementation.
//重载()运算符
void operator()( cv::InputArray image, cv::InputArray mask,
std::vector<cv::KeyPoint>& keypoints,
cv::OutputArray descriptors);
int inline GetLevels(){
return nlevels;}
float inline GetScaleFactor(){
return scaleFactor;}
std::vector<float> inline GetScaleFactors(){
return mvScaleFactor;
}
std::vector<float> inline GetInverseScaleFactors(){
return mvInvScaleFactor;
}
std::vector<float> inline GetScaleSigmaSquares(){
return mvLevelSigma2;
}
std::vector<float> inline GetInverseScaleSigmaSquares(){
return mvInvLevelSigma2;
}
//图像金字塔 存放各层的图片
std::vector<cv::Mat> mvImagePyramid;
protected:
//建立图像金字塔
//将原始图像一级级缩小并依次存在mvImagePyramid里
void ComputePyramid(cv::Mat image);
//利用四叉树提取高斯金字塔中每层图像的orb关键点
void ComputeKeyPointsOctTree(std::vector<std::vector<cv::KeyPoint> >& allKeypoints);
//将关键点分配到四叉树,筛选关键点
std::vector<cv::KeyPoint> DistributeOctTree(const std::vector<cv::KeyPoint>& vToDistributeKeys, const int &minX,const int &maxX, const int &minY, const int &maxY, const int &nFeatures, const int &level);
//作者遗留下的旧的orb关键点方法
void ComputeKeyPointsOld(std::vector<std::vector<cv::KeyPoint> >& allKeypoints);
//存储关键点附近patch的点对相对位置
std::vector<cv::Point> pattern;
//提取特征点的最大数量
int nfeatures;
//每层之间的缩放比例
double scaleFactor;
//高斯金字塔的层数
int nlevels;
//iniThFAST提取FAST角点时初始阈值
int iniThFAST;
//minThFAST提取FAST角点时更小的阈值
int minThFAST;
//每层的特征数量
std::vector<int> mnFeaturesPerLevel;
//Patch圆的u轴方向最大坐标
std::vector<int> umax;
//每层的相对于原始图像的缩放比例
std::vector<float> mvScaleFactor;
//mvScaleFactor的倒数
std::vector<float> mvInvScaleFactor;
//mvScaleFactor的平方
std::vector<float> mvLevelSigma2;
//mvScaleFactor的平方的倒数
std::vector<float> mvInvLevelSigma2;
};
3.源文件ORBextractor.cc
3.1.类ORBextractor构造函数
功能:提取特征前的准备工作
///功能:提取特征前的准备工作
ORBextractor::ORBextractor(int _nfeatures, float _scaleFactor, int _nlevels,
int _iniThFAST, int _minThFAST):
nfeatures(_nfeatures), scaleFactor(_scaleFactor), nlevels(_nlevels),
iniThFAST(_iniThFAST), minThFAST(_minThFAST)
{
mvScaleFactor.resize(nlevels);
mvLevelSigma2.resize(nlevels);
//初始化mvScaleFactor,mvLevelSigma2
mvScaleFactor[0]=1.0f;
mvLevelSigma2[0]=1.0f;
//根据scaleFactor计算每层的mvScaleFactor,其值单调递增
for(int i=1; i<nlevels; i++)
{
mvScaleFactor[i]=mvScaleFactor[i-1]*scaleFactor;
mvLevelSigma2[i]=mvScaleFactor[i]*mvScaleFactor[i];
}
mvInvScaleFactor.resize(nlevels);
mvInvLevelSigma2.resize(nlevels);
//计算 mvInvScaleFactor,mvInvLevelSigma2
for(int i=0; i<nlevels; i++)
{
mvInvScaleFactor[i]=1.0f/mvScaleFactor[i];
mvInvLevelSigma2[i]=1.0f/mvLevelSigma2[i];
}
mvImagePyramid.resize(nlevels);
//对于缩放的每层高斯金字塔图像,计算其对应每层待提取特征的数量放入mnFeaturesPerLevel中,使得每层特征点的数列成等比数列数列递减
mnFeaturesPerLevel.resize(nlevels);
float factor = 1.0f / scaleFactor;
float nDesiredFeaturesPerScale = nfeatures*(1 - factor)/(1 - (float)pow((double)factor, (double)nlevels));
int sumFeatures = 0;
for( int level = 0; level < nlevels-1; level++ )
{
mnFeaturesPerLevel[level] = cvRound(nDesiredFeaturesPerScale);
sumFeatures += mnFeaturesPerLevel[level];
nDesiredFeaturesPerScale *= factor;
}
mnFeaturesPerLevel[nlevels-1] = std::max(nfeatures - sumFeatures, 0);
//准备计算关键点keypoint的brief描述子时所需要的pattern
//这个pattern一共有512个点对;
const int npoints = 512;
//bit_pattern_31_是一个1024维的数组,其信息是512对点对的相对中心点的像素坐标
//这里将bit_pattern_31_里的信息以Point的形式存储在了std::vector pattern里;
//最后pattern储存了512个Point
const Point* pattern0 = (const Point*)bit_pattern_31_;
std::copy(pattern0, pattern0 + npoints, std::back_inserter(pattern));
//This is for orientation
// pre-compute the end of a row in a circular patch
//这里是为了计算关键点方向的准备工作
//我们是要在以关键点keypoint像素坐标点为中心的直径为PATCH_SIZE,半径为HALF_PATCH_SIZE的patch圆内计算关键点keypoint的方向。
//那如何描述这个patch圆的范围呢?这里选择的是储存不同v所对应的的umax来描述这个patch圆的范围。
umax.resize(HALF_PATCH_SIZE + 1);
int v, v0, vmax = cvFloor(HALF_PATCH_SIZE * sqrt(2.f) / 2 + 1);
int vmin = cvCeil(HALF_PATCH_SIZE * sqrt(2.f) / 2);
const double hp2 = HALF_PATCH_SIZE*HALF_PATCH_SIZE;
for (v = 0; v <= vmax; ++v)
umax[v] = cvRound(sqrt(hp2 - v * v));
// Make sure we are symmetric
//其实是算当v=vmax至HALF_PATCH_SIZE时的umax[v]
for (v = HALF_PATCH_SIZE, v0 = 0; v >= vmin; --v)
{
while (umax[v0] == umax[v0 + 1])
++v0;
umax[v] = v0;
++v0;
}
}
3.1.1.umax的计算
为什么要计算umax?
我们知道,ORB特征点是由FAST关键点和BRIEF描述子组成的。
ORB特征点的关键点告诉我们ORB特征点的位置信息。在后面我们还需要计算ORB特征点的方向。
而ORB特征点是根据像素坐标点为中心的直径为PATCH_SIZE,半径为HALF_PATCH_SIZE的patch圆内计算出来的(具体计算方法在)。
在源文件ORBextractor.cc,我们可以看到这个patch圆的相关信息
const int PATCH_SIZE = 31;
const int HALF_PATCH_SIZE = 15;
const int EDGE_THRESHOLD = 19;
于是我们需要先解决如何这个描述这个patch圆。

看上图。
当0
3.2.重载ORBextractor::operator()
该方法具体流程:
1.对于输入的图片,计算其图像金字塔;
2.提取图像金字塔中各层图像的关键点;
3.计算提取出的关键点对应的描述子;
//通过调用()来提取图像的orb的关键点和描述子
//输入的变量
// _image:获取的灰度图像
// _mask:掩码
// _keypoints:关键点位置
// _descriptors:描述子
//括号运算符输入图像,并且传入引用参数_keypoints,_descriptors用于计算得到的特征点及其描述子
void ORBextractor::operator()( InputArray _image, InputArray _mask, vector<KeyPoint>& _keypoints,
OutputArray _descriptors)
{
if(_image.empty())
return;
Mat image = _image.getMat();
//判断通道是否为灰度图
assert(image.type() == CV_8UC1 );
// Pre-compute the scale pyramid
//计算图像金字塔
ComputePyramid(image);
//提取图像金字塔中各层图像的关键点并储存在allKeypoints里
vector < vector<KeyPoint> > allKeypoints;
ComputeKeyPointsOctTree(allKeypoints);
//ComputeKeyPointsOld(allKeypoints);
Mat descriptors;
//算出实际提取出来的关键点数量nkeypoints
//新建descriptors对象,特征点的描述子将存在这里
//descriptors就好似nkeypoints*32维的矩阵,矩阵里存着一个uchar,其单位为8bit
//这样对于每个关键点,就对应有32*8=256bit的二进制向量作为描述子
int nkeypoints = 0;
for (int level = 0; level < nlevels; ++level)
nkeypoints += (int)allKeypoints[level].size();
if( nkeypoints == 0 )
_descriptors.release();
else
{
_descriptors.create(nkeypoints, 32, CV_8U);
descriptors = _descriptors.getMat();
}
_keypoints.clear();
_keypoints.reserve(nkeypoints);
int offset = 0;
//遍历高斯金字塔每层,计算其提取出的关键点的描述子储存在descriptors里
for (int level = 0; level < nlevels; ++level)
{
vector<KeyPoint>& keypoints = allKeypoints[level];
int nkeypointsLevel = (int)keypoints.size();
if(nkeypointsLevel==0)
continue;
// preprocess the resized image
Mat workingMat = mvImagePyramid[level].clone();
//使用高斯模糊
GaussianBlur(workingMat, workingMat, Size(7, 7), 2, 2, BORDER_REFLECT_101);
// Compute the descriptors
//计算描述子,其计算所需的点对分布采用的是高斯分布,储存在pattern里
Mat desc = descriptors.rowRange(offset, offset + nkeypointsLevel);
computeDescriptors(workingMat, keypoints, desc, pattern);
offset += nkeypointsLevel;
// Scale keypoint coordinates
// 对关键点的位置坐做尺度恢复,恢复到原图的位置
if (level != 0)
{
float scale = mvScaleFactor[level]; //getScale(level, firstLevel, scaleFactor);
for (vector<KeyPoint>::iterator keypoint = keypoints.begin(),
keypointEnd = keypoints.end(); keypoint != keypointEnd; ++keypoint)
keypoint->pt *= scale;
}
// And add the keypoints to the output
_keypoints.insert(_keypoints.end(), keypoints.begin(), keypoints.end());
}
}
3.3.类方法ORBextractor::ComputePyramid(cv::Mat image)
将原始图像一级级缩小并依次存在mvImagePyramid里
//建立图像金字塔
//将原始图像一级级缩小并依次存在mvImagePyramid里
void ORBextractor::ComputePyramid(cv::Mat image)
{
// 计算n个level尺度的图片
for (int level = 0; level < nlevels; ++level)
{
//获取缩放尺度
float scale = mvInvScaleFactor[level];
//当前层图片尺寸
Size sz(cvRound((float)image.cols*scale), cvRound((float)image.rows*scale));
//截图前的图片尺寸
Size wholeSize(sz.width + EDGE_THRESHOLD*2, sz.height + EDGE_THRESHOLD*2);
//新建一个temp,大小为wholeSize
Mat temp(wholeSize, image.type()), masktemp;
//从temp裁剪(起点为EDGE_THRESHOLD, EDGE_THRESHOLD,大小为sz.width,
//sz.height)存入mvImagePyramid[level]
mvImagePyramid[level] = temp(Rect(EDGE_THRESHOLD, EDGE_THRESHOLD, sz.width, sz.height));
// Compute the resized image
if( level != 0 )
{
//从上一级图像mvImagePyramid[level-1]中缩小图像至sz大小,
//并存入mvImagePyramid[level]
resize(mvImagePyramid[level-1], mvImagePyramid[level], sz, 0, 0, INTER_LINEAR);
//扩充上下左右边界EDGE_THRESHOLD个像素,放入temp中,对mvImagePyramid无影响
copyMakeBorder(mvImagePyramid[level], temp, EDGE_THRESHOLD, EDGE_THRESHOLD, EDGE_THRESHOLD, EDGE_THRESHOLD,
BORDER_REFLECT_101+BORDER_ISOLATED);
}
else
{
//需要扩充上下左右边界EDGE_THRESHOLD个像素,放入temp中,对mvImagePyramid无影响
copyMakeBorder(image, temp, EDGE_THRESHOLD, EDGE_THRESHOLD, EDGE_THRESHOLD, EDGE_THRESHOLD,
BORDER_REFLECT_101);
}
}
}
这个函数主要是生成了nlevels张不同缩放尺度的图片放入mvImagePyramid中
当nlevels=8时,其生成的图片为:

其中image为原始图片,image0~7对应为mvImagePyramid中图片。
生成mvImagePyramid[i]的图片的方法是:
- 先用
resize()将图片缩放至sz大小,放入mvImagePyramid[i]; - 接着用
copyMakeBorder()扩展边界至wholeSize大小放入temp; - 注意
temp和mvImagePyramid[i]公用相同数据区,改变temp会改变mvImagePyramid[i]。
参考:
resize()用法
OpenCV(3)-图像resize
copyMakeBorder()用法
OpenCV图像剪切的扩展和高级用法:任意裁剪,边界扩充
3.4.类方法ORBextractor::ComputeKeyPointsOctTree()
最开始我以为提取出来的关键点是以四叉树的形式储存的,结果不是。四叉树只是被利用使得提取的关键点均匀分布,并且用到了非极大值抑制(Non-maximum suppression, NMS)算法。
该算法的具体步骤为:
1.先是计算提取关键点的边界,太边缘的地方放弃提取关键点;
2.将图像分割为W*W的小图片,遍历这些分割出来的小图片并提取其关键点;
3.将提取的关键点交给DistributeOctTree()利用四叉树以及非极大值抑制算法进行筛选;
4.计算关键点的相关信息:像素位置,patch尺度,方向,所在高斯金字塔层数;
ps注意在分割图片的时候,小窗之间室友重叠的。
//利用四叉树提取高斯金字塔中每层图像的orb关键点
void ORBextractor::ComputeKeyPointsOctTree(vector<vector<KeyPoint> >& allKeypoints)
{
allKeypoints.resize(nlevels);
//暂定的分割窗口的大小
const float W = 30;
//对高斯金字塔mvImagePyramid中每层图像提取orb特征点
for (int level = 0; level < nlevels; ++level)
{
//计算边界,在这个边界内计算FAST关键点
const int minBorderX = EDGE_THRESHOLD-3;
const int minBorderY = minBorderX;
const int maxBorderX = mvImagePyramid[level].cols-EDGE_THRESHOLD+3;
const int maxBorderY = mvImagePyramid[level].rows-EDGE_THRESHOLD+3;
//用这个存储待筛选的orb
vector<cv::KeyPoint> vToDistributeKeys;
vToDistributeKeys.reserve(nfeatures*10);
//计算边界宽度和高度
const float width = (maxBorderX-minBorderX);
const float height = (maxBorderY-minBorderY);
//将原始图片分割的行数和列数
const int nCols = width/W;
const int nRows = height/W;
//实际分割窗口的大小
const int wCell = ceil(width/nCols);
const int hCell = ceil(height/nRows);
//使用两个for循环遍历每个窗口,首先先计算窗口的四个坐标
//遍历每行
for(int i=0; i<nRows; i++)
{
//iniY,maxY为窗口的行上坐标和下坐标
//计算(iniY,maxY)坐标
const float iniY =minBorderY+i*hCell;
//这里注意窗口之间有6行的重叠
float maxY = iniY+hCell+6;
//窗口的行上坐标超出边界,则放弃此行
if(iniY>=maxBorderY-3)
continue;
//窗口的行下坐标超出边界,则将窗口的行下坐标设置为边界
if(maxY>maxBorderY)
maxY = maxBorderY;
//遍历每列
for(int j=0; j<nCols; j++)
{
//iniX,maxX为窗口的列左坐标和右坐标
//计算(iniX,maxX)坐标
const float iniX =minBorderX+j*wCell;
//这里注意窗口之间有6列的重叠
float maxX = iniX+wCell+6;
//窗口的列左坐标超出边界,则放弃此列
if(iniX>=maxBorderX-6)
continue;
//窗口的列右坐标超出边界,则将窗口的列右坐标设置为边界
if(maxX>maxBorderX)
maxX = maxBorderX;
//每个小窗里的关键点KeyPoint将存在这里
vector<cv::KeyPoint> vKeysCell;
//提取FAST角点
//输入参数
//mvImagePyramid[level].rowRange(iniY,maxY).colRange(iniX,maxX) level层的图片中行
//范围(iniY,maxY),列范围(iniX,maxX)的截图
//
//vKeysCell,储存提取的fast关键点
//iniThFAST提取角点的阈值
//true 是否开启非极大值抑制算法
FAST(mvImagePyramid[level].rowRange(iniY,maxY).colRange(iniX,maxX),
vKeysCell,iniThFAST,true);
// 如果没有找到FAST关键点,就降低阈值重新计算FAST
if(vKeysCell.empty())
{
FAST(mvImagePyramid[level].rowRange(iniY,maxY).colRange(iniX,maxX),
vKeysCell,minThFAST,true);
}
//如果找到的点不为空,就加入到vToDistributeKeys
if(!vKeysCell.empty())
{
for(vector<cv::KeyPoint>::iterator vit=vKeysCell.begin(); vit!=vKeysCell.end();vit++)
{
//根据前面的行列计算实际的位置
(*vit).pt.x+=j*wCell;
(*vit).pt.y+=i*hCell;
vToDistributeKeys.push_back(*vit);
}
}
}
}
//经DistributeOctTree筛选后的关键点存储在这里
vector<KeyPoint> & keypoints = allKeypoints[level];
keypoints.reserve(nfeatures);
//筛选vToDistributeKeys中的关键点
keypoints = DistributeOctTree(vToDistributeKeys, minBorderX, maxBorderX,
minBorderY, maxBorderY,mnFeaturesPerLevel[level], level);
//计算在本层提取出的关键点对应的Patch大小,称为scaledPatchSize
//你想想,本层的图像是缩小的,而你在本层提取的orb特征点,计算orb的方向,描述子的时候根据
//的PATCH大小依旧是PATCH_SIZE。
//而你在本层提取的orb是要恢复到原始图像上去的,所以其特征点的size(代表特征点的尺度信息)需要放大。
const int scaledPatchSize = PATCH_SIZE*mvScaleFactor[level];
// Add border to coordinates and scale information
const int nkps = keypoints.size();
for(int i=0; i<nkps ; i++)
{
keypoints[i].pt.x+=minBorderX;
keypoints[i].pt.y+=minBorderY;
keypoints[i].octave=level;
keypoints[i].size = scaledPatchSize;
}
}
// compute orientations
//计算方向
for (int level = 0; level < nlevels; ++level)
computeOrientation(mvImagePyramid[level], allKeypoints[level], umax);
}
3.5.类方法ORBextractor::DistributeOctTree()
利用四叉树来筛选提取的特征点,使得筛选后的特征点数量在预计的范围,并且分布均匀
3.5.1.根节点数量

根节点的数量nIni是根据边界的宽高比值确定的。
确定根节点的数量nIni后,再计算根节点的领域范围
3.5.2.分配关键点
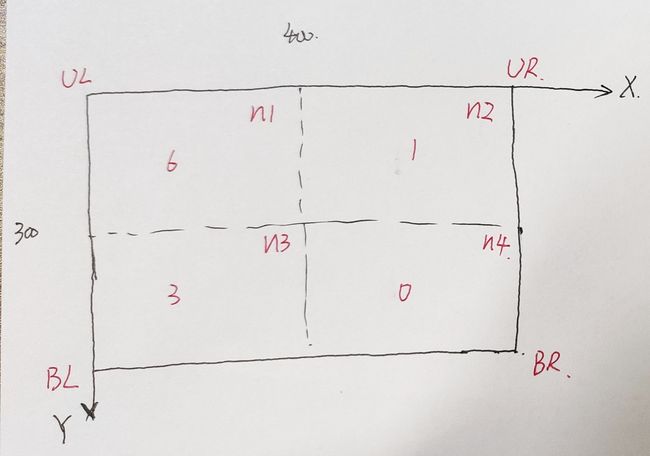
根节点算好再根据关键点位置分配关键点
图中关键点分成了4份,分别为6,1,3,0
3.5.3.不断分裂双向链表lNodes中的节点
不断分裂lNodes中的节点,直至lNodes节点数量大于等于需要的特征点数(N),或者lNodes中节点所有节点的关键点数量都为1.
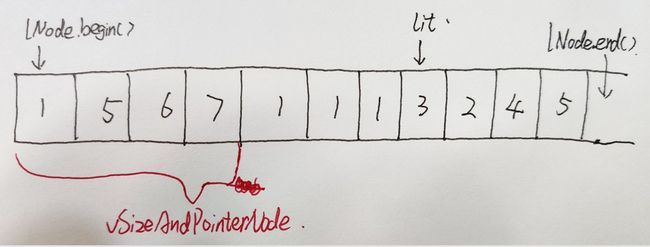
上图为遍历lNodes,分裂lNodes中节点时的示意图
vector<cv::KeyPoint> ORBextractor::DistributeOctTree(const vector<cv::KeyPoint>& vToDistributeKeys, const int &minX,const int &maxX, const int &minY, const int &maxY, const int &N, const int &level)
{
// Compute how many initial nodes
//计算根节点的数量
const int nIni = round(static_cast<float>(maxX-minX)/(maxY-minY));
//计算根节点的X范围,其Y轴范围就是(maxY-minY)
const float hX = static_cast<float>(maxX-minX)/nIni;
//新建一个双向链表,其实后面大部分操作是改变这个
list<ExtractorNode> lNodes;
//vpIniNodes在将vToDistributeKeys分配到父节点中时起索引作用
vector<ExtractorNode*> vpIniNodes;
vpIniNodes.resize(nIni);
//遍历每个根节点,计算根节点领域的四个点UL,UR,BL,BR并其存入lNodes和vpIniNodes
for(int i=0; i<nIni; i++)
{
ExtractorNode ni;
ni.UL = cv::Point2i(hX*static_cast<float>(i),0);
ni.UR = cv::Point2i(hX*static_cast<float>(i+1),0);
ni.BL = cv::Point2i(ni.UL.x,maxY-minY);
ni.BR = cv::Point2i(ni.UR.x,maxY-minY);
ni.vKeys.reserve(vToDistributeKeys.size());
lNodes.push_back(ni);
vpIniNodes[i] = &lNodes.back();
}
//Associate points to childs
//将vToDistributeKeys按照位置分配在根节点中
for(size_t i=0;i<vToDistributeKeys.size();i++)
{
const cv::KeyPoint &kp = vToDistributeKeys[i];
vpIniNodes[kp.pt.x/hX]->vKeys.push_back(kp);
}
list<ExtractorNode>::iterator lit = lNodes.begin();
//现在lNodes中只放有根节点,变量根节点,如果根节点中关键点个数为1
//那么将这个节点的bNoMore,表示这个节点不能再分裂了。
//如果为空,那么就删除这个节点
while(lit!=lNodes.end())
{
if(lit->vKeys.size()==1)
{
lit->bNoMore=true;
lit++;
}
else if(lit->vKeys.empty())
lit = lNodes.erase(lit);
else
lit++;
}
//后面大循环结束标志位
bool bFinish = false;
int iteration = 0;
vector<pair<int,ExtractorNode*> > vSizeAndPointerToNode;
vSizeAndPointerToNode.reserve(lNodes.size()*4);
//现在lNodes里只有根节点,且每个节点的关键点数量都不为0
while(!bFinish)
{
iteration++;
int prevSize = lNodes.size();
lit = lNodes.begin();
//待分裂的节点数nToExpand
int nToExpand = 0;
vSizeAndPointerToNode.clear();
//遍历双向链表lNodes中的节点
while(lit!=lNodes.end())
{
if(lit->bNoMore)
{
// If node only contains one point do not subdivide and continue
//如果此节点包含的关键点数量为一,那么就不分裂
lit++;
continue;
}
else
{
// If more than one point, subdivide
//如果此节点关键点数量大于1,那么就分裂此节点,将此节点中的关键点通过DivideNode
//分配到n1,n2,n3,n4
//并且将此被分裂的节点删除
ExtractorNode n1,n2,n3,n4;
lit->DivideNode(n1,n2,n3,n4);
// Add childs if they contain points
//如果节点n1的关键点数量大于0,将其插入lNodes的**前面**
//如果节点n1的关键点数量大于1,将其插入vSizeAndPointerToNode中表示待分裂
//后面n2,n3,n4以此类推
if(n1.vKeys.size()>0)
{
lNodes.push_front(n1);
if(n1.vKeys.size()>1)
{
nToExpand++;
vSizeAndPointerToNode.push_back(make_pair(n1.vKeys.size(),&lNodes.front()));
lNodes.front().lit = lNodes.begin();
}
}
if(n2.vKeys.size()>0)
{
lNodes.push_front(n2);
if(n2.vKeys.size()>1)
{
nToExpand++;
vSizeAndPointerToNode.push_back(make_pair(n2.vKeys.size(),&lNodes.front()));
lNodes.front().lit = lNodes.begin();
}
}
if(n3.vKeys.size()>0)
{
lNodes.push_front(n3);
if(n3.vKeys.size()>1)
{
nToExpand++;
vSizeAndPointerToNode.push_back(make_pair(n3.vKeys.size(),&lNodes.front()));
lNodes.front().lit = lNodes.begin();
}
}
if(n4.vKeys.size()>0)
{
lNodes.push_front(n4);
if(n4.vKeys.size()>1)
{
nToExpand++;
vSizeAndPointerToNode.push_back(make_pair(n4.vKeys.size(),&lNodes.front()));
lNodes.front().lit = lNodes.begin();
}
}
lit=lNodes.erase(lit);
continue;
}
}
// Finish if there are more nodes than required features
// or all nodes contain just one point
//lNodes节点数量大于等于需要的特征点数(N),或者lNodes中节点所有节点的关键点数量都为1,
//标志 bFinish,结束循环
if((int)lNodes.size()>=N || (int)lNodes.size()==prevSize)
{
bFinish = true;
}
//待分裂的节点数vSizeAndPointerToNode分裂后,一般会增加nToExpand*3,
//如果增加nToExpand*3后大于N,则进入此分支
else if(((int)lNodes.size()+nToExpand*3)>N)
{
while(!bFinish)
{
prevSize = lNodes.size();
vector<pair<int,ExtractorNode*> > vPrevSizeAndPointerToNode = vSizeAndPointerToNode;
vSizeAndPointerToNode.clear();
//根据vPrevSizeAndPointerToNode.first大小来排序,
//也就是根据待分裂节点的关键点数量大小来有小到大排序。
sort(vPrevSizeAndPointerToNode.begin(),vPrevSizeAndPointerToNode.end());
//倒叙遍历vPrevSizeAndPointerToNode,也先分裂待分裂节点的关键点数量大的
for(int j=vPrevSizeAndPointerToNode.size()-1;j>=0;j--)
{
ExtractorNode n1,n2,n3,n4;
vPrevSizeAndPointerToNode[j].second->DivideNode(n1,n2,n3,n4);
// Add childs if they contain points
if(n1.vKeys.size()>0)
{
lNodes.push_front(n1);
if(n1.vKeys.size()>1)
{
vSizeAndPointerToNode.push_back(make_pair(n1.vKeys.size(),&lNodes.front()));
lNodes.front().lit = lNodes.begin();
}
}
if(n2.vKeys.size()>0)
{
lNodes.push_front(n2);
if(n2.vKeys.size()>1)
{
vSizeAndPointerToNode.push_back(make_pair(n2.vKeys.size(),&lNodes.front()));
lNodes.front().lit = lNodes.begin();
}
}
if(n3.vKeys.size()>0)
{
lNodes.push_front(n3);
if(n3.vKeys.size()>1)
{
vSizeAndPointerToNode.push_back(make_pair(n3.vKeys.size(),&lNodes.front()));
lNodes.front().lit = lNodes.begin();
}
}
if(n4.vKeys.size()>0)
{
lNodes.push_front(n4);
if(n4.vKeys.size()>1)
{
vSizeAndPointerToNode.push_back(make_pair(n4.vKeys.size(),&lNodes.front()));
lNodes.front().lit = lNodes.begin();
}
}
//删除被分裂的节点
lNodes.erase(vPrevSizeAndPointerToNode[j].second->lit);
if((int)lNodes.size()>=N)
break;
}
if((int)lNodes.size()>=N || (int)lNodes.size()==prevSize)
bFinish = true;
}
}
}
// Retain the best point in each node
//取出每个节点中响应最大的特征点
vector<cv::KeyPoint> vResultKeys;
vResultKeys.reserve(nfeatures);
for(list<ExtractorNode>::iterator lit=lNodes.begin(); lit!=lNodes.end(); lit++)
{
vector<cv::KeyPoint> &vNodeKeys = lit->vKeys;
cv::KeyPoint* pKP = &vNodeKeys[0];
float maxResponse = pKP->response;
for(size_t k=1;k<vNodeKeys.size();k++)
{
if(vNodeKeys[k].response>maxResponse)
{
pKP = &vNodeKeys[k];
maxResponse = vNodeKeys[k].response;
}
}
vResultKeys.push_back(*pKP);
}
return vResultKeys;
}
ORB-SLAM2中四叉树管理特征点
3.6.类方法ExtractorNode::DivideNode()
将ExtractorNode内的关键点按照其位置分配给n1~n4
void ExtractorNode::DivideNode(ExtractorNode &n1, ExtractorNode &n2, ExtractorNode &n3, ExtractorNode &n4)
{
const int halfX = ceil(static_cast<float>(UR.x-UL.x)/2);
const int halfY = ceil(static_cast<float>(BR.y-UL.y)/2);
//Define boundaries of childs
n1.UL = UL;
n1.UR = cv::Point2i(UL.x+halfX,UL.y);
n1.BL = cv::Point2i(UL.x,UL.y+halfY);
n1.BR = cv::Point2i(UL.x+halfX,UL.y+halfY);
n1.vKeys.reserve(vKeys.size());
n2.UL = n1.UR;
n2.UR = UR;
n2.BL = n1.BR;
n2.BR = cv::Point2i(UR.x,UL.y+halfY);
n2.vKeys.reserve(vKeys.size());
n3.UL = n1.BL;
n3.UR = n1.BR;
n3.BL = BL;
n3.BR = cv::Point2i(n1.BR.x,BL.y);
n3.vKeys.reserve(vKeys.size());
n4.UL = n3.UR;
n4.UR = n2.BR;
n4.BL = n3.BR;
n4.BR = BR;
n4.vKeys.reserve(vKeys.size());
//Associate points to childs
for(size_t i=0;i<vKeys.size();i++)
{
const cv::KeyPoint &kp = vKeys[i];
if(kp.pt.x<n1.UR.x)
{
if(kp.pt.y<n1.BR.y)
n1.vKeys.push_back(kp);
else
n3.vKeys.push_back(kp);
}
else if(kp.pt.y<n1.BR.y)
n2.vKeys.push_back(kp);
else
n4.vKeys.push_back(kp);
}
if(n1.vKeys.size()==1)
n1.bNoMore = true;
if(n2.vKeys.size()==1)
n2.bNoMore = true;
if(n3.vKeys.size()==1)
n3.bNoMore = true;
if(n4.vKeys.size()==1)
n4.bNoMore = true;
}
3.7.函数IC_Angle()
static float IC_Angle(const Mat& image, Point2f pt, const vector<int> & u_max)
{
//根据公式初始化图像块的矩
int m_01 = 0, m_10 = 0;
const uchar* center = &image.at<uchar> (cvRound(pt.y), cvRound(pt.x));
// Treat the center line differently, v=0
for (int u = -HALF_PATCH_SIZE; u <= HALF_PATCH_SIZE; ++u)
m_10 += u * center[u];
// Go line by line in the circuI853lar patch
int step = (int)image.step1();
for (int v = 1; v <= HALF_PATCH_SIZE; ++v)
{
// Proceed over the two lines
int v_sum = 0;
int d = u_max[v];
for (int u = -d; u <= d; ++u)
{
int val_plus = center[u + v*step], val_minus = center[u - v*step];
v_sum += (val_plus - val_minus);
m_10 += u * (val_plus + val_minus);
}
m_01 += v * v_sum;
}
return fastAtan2((float)m_01, (float)m_10);
}
3.8.函数computeDescriptor()
//弧度制和角度制之间的转换
const float factorPI = (float)(CV_PI/180.f);
//计算ORB描述子
static void computeOrbDescriptor(const KeyPoint& kpt,
const Mat& img, const Point* pattern,
uchar* desc)
{
float angle = (float)kpt.angle*factorPI;
//考虑关键点的方向
float a = (float)cos(angle), b = (float)sin(angle);
const uchar* center = &img.at<uchar>(cvRound(kpt.pt.y), cvRound(kpt.pt.x));
const int step = (int)img.step;
//注意这里在pattern里找点的时候,是利用关键点的方向信息进行了旋转矫正的
#define GET_VALUE(idx) \
center[cvRound(pattern[idx].x*b + pattern[idx].y*a)*step + \
cvRound(pattern[idx].x*a - pattern[idx].y*b)]
for (int i = 0; i < 32; ++i, pattern += 16)
{
int t0, t1, val;
t0 = GET_VALUE(0); t1 = GET_VALUE(1);
val = t0 < t1;
t0 = GET_VALUE(2); t1 = GET_VALUE(3);
val |= (t0 < t1) << 1;
t0 = GET_VALUE(4); t1 = GET_VALUE(5);
val |= (t0 < t1) << 2;
t0 = GET_VALUE(6); t1 = GET_VALUE(7);
val |= (t0 < t1) << 3;
t0 = GET_VALUE(8); t1 = GET_VALUE(9);
val |= (t0 < t1) << 4;
t0 = GET_VALUE(10); t1 = GET_VALUE(11);
val |= (t0 < t1) << 5;
t0 = GET_VALUE(12); t1 = GET_VALUE(13);
val |= (t0 < t1) << 6;
t0 = GET_VALUE(14); t1 = GET_VALUE(15);
val |= (t0 < t1) << 7;
desc[i] = (uchar)val;
}
#undef GET_VALUE
}