scrapy框架爬取Boss直聘,数据存入mysql
自从上次用了scrapy爬取豆瓣电影后,发现scrapy除了入门相对request较难外,各方面都挺好的,速度很快,还有各个功能模块,以及django类似的各种中间件组成一个完善的系统框架,需要一点一点的学习,了解,毕竟官方文档写的太随性了~~~
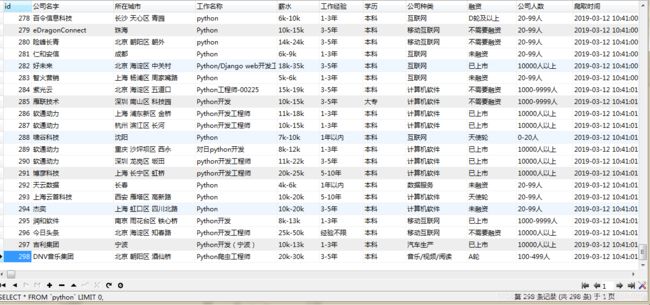
这次我爬取的是boss直聘上的各种职业,以及该职位的薪水,地点,公司等情况....
老规矩镇楼图如下:
一张表大概有300个数据,因为boss直聘搜索的条件,只会显示10页,每页大概30条的样子。
接下来进入正题:按照框架的流程走一波~

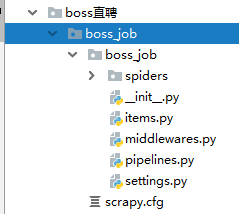
一:开始一个爬虫项目:scrapy startproject +项目名
eg:scrapy startproject boss_job
会自动生成目录如下:
二:创建spider爬虫 scrapy genspider +爬虫名 +爬取域名
1.创建项目成功需要先切换目录到bosss_iob eg:cd boss_iob
2.eg:scrapy genspider boss zhipin.com 创建完成后,spider目录下自动生成boss的spider

三:在setting里面把遵守爬虫协议改为不遵守
ROBOTSTXT_OBEY = True 改为-》ROBOTSTXT_OBEY = False
取消DEFAULT_REQUEST_HEADERS 注释,加入自己的浏览器user-agent信息伪装浏览器。

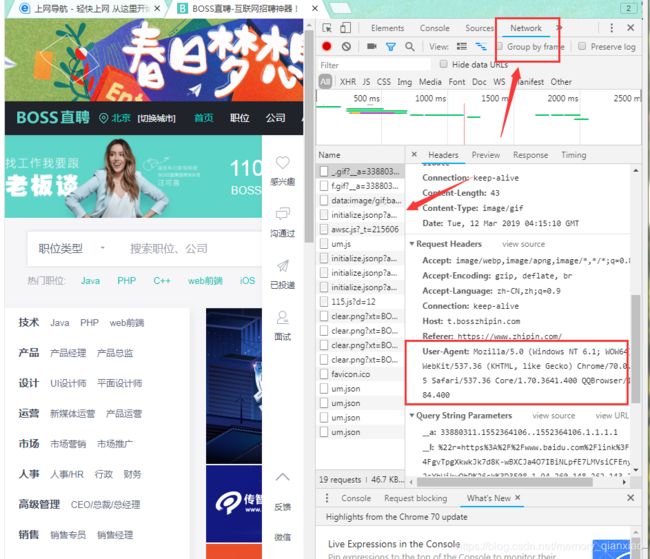
你的user-agent浏览器按F12,选择network,随便选中一个boss直聘中的一个文件,复制其中的user-agent
四:打开items.py文件,在BossJobItem定义item容器,方便数据的存储,以及数数据的表的建立(和django中的module类似)
代码如下:
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class BossJobItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
company_name=scrapy.Field()#公司名字
company_locale = scrapy.Field() # 所在城市
job_name=scrapy.Field()#工作名称
job_salary=scrapy.Field()#薪水
experience_demand=scrapy.Field()#工作经验需求
educational_demand=scrapy.Field()#学历需求
company_work=scrapy.Field()#公司种类
finance=scrapy.Field()#融资
persons_in_company=scrapy.Field()#公司人数
crawl_time=scrapy.Field()#爬取时间
五:把boss中的spider编写完成
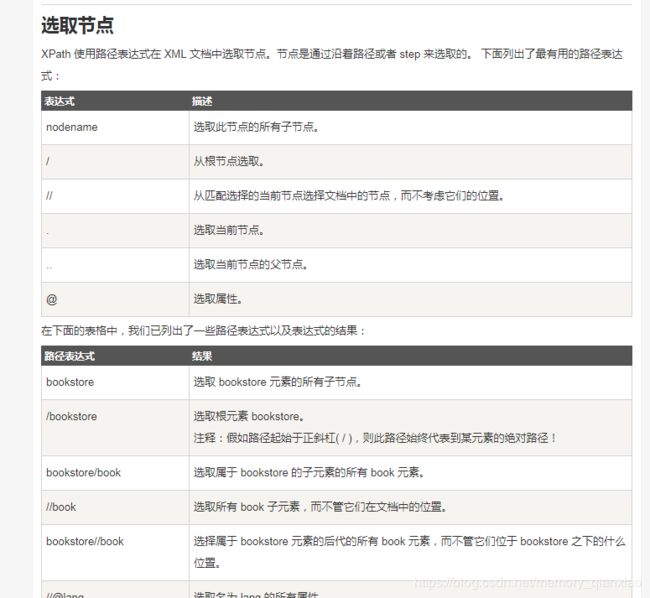
提取方法是用的是框架自带的xpath,很方便的,还有css,re,等也可以用,提取过程可以在scrapy shell测试,测试完成后就能保证提取的准确性。如果不知道xpath提取,可以看如下菜鸟教程:
菜鸟教程xpath教程:http://www.runoob.com/xpath/xpath-tutorial.html
代码如下:
# -*- coding: utf-8 -*-
import scrapy,time
from ..items import *
class BossSpider(scrapy.Spider):
name = 'boss'
allowed_domains = ['zhipin.com']
key_word=input("请输入需要查询的关键字(python,java,酒店管理,销售,或者职业部分相关关键字):")
if key_word:
url='https://www.zhipin.com/c100010000/?query='+key_word
start_urls = [url]
else:print("不能为空")
def parse(self, response):
item=BossJobItem()#导入item容器
job_list=response.xpath('//div[@class="job-list"]//ul//li')#所有工作标签列表
for job in job_list:
time.sleep(0.5)#睡眠时间X秒
item['company_name']=job.xpath('.//div[@class="info-company"]//h3/a/text()').extract_first()#公司名字
item['company_locale']=job.xpath('.//div[@class="info-primary"]//p/text()').extract_first()# 所在城市
item['job_name']=job.xpath('.//div[@class="job-title"]/text()').extract_first()#工作名称
item['job_salary']=job.xpath('.//div[@class="info-primary"]//span/text()').extract_first()#薪水
item['experience_demand']=job.xpath('.//div[@class="info-primary"]//p/text()').extract()[1]#工作经验需求
item['educational_demand']=job.xpath('.//div[@class="info-primary"]//p/text()').extract()[2]#学历需求
#因为有部分公司,没有融资说明,所以数据会空缺,程序会中断,特判处理
if len(job.xpath('.//div[@class="info-company"]//p/text()').extract())==3:
item['company_work']=job.xpath('.//div[@class="info-company"]//p/text()').extract_first()#公司种类
item['finance']=job.xpath('.//div[@class="info-company"]//p/text()').extract()[1]#融资
item['persons_in_company']=job.xpath('.//div[@class="info-company"]//p/text()').extract()[2]#公司人数
else:
item['company_work'] = job.xpath('.//div[@class="info-company"]//p/text()').extract_first() # 公司种类
item['persons_in_company'] = job.xpath('.//div[@class="info-company"]//p/text()').extract()[1] # 公司人数
item['crawl_time']=time.strftime("%Y-%m-%d %H:%M:%S",time.localtime())#爬取时间
yield item
next_url=response.xpath('//div[@class="page"]//a[@ka="page-next"]/@href').extract_first()
print("*" * 120)
print(self.url + next_url)
if next_url!="javascript:;":
yield scrapy.Request(self.url+next_url,callback=self.parse)
六:创建数据库,编写pipelines对数据进行清洗入mysql库,以及顺便输出一份json格式的文件
需要安装pymysql库,__init__函数,process_item,close_spider分别表示在爬虫运行开始之前,爬虫运行过程中,关闭爬虫后需要执行的功能,把代码写进你需要在哪个阶段执行对应的函数里面就ok了。我这里需要在运行之前连接数据库,同时判断当前输入的职位关键字,有没有,有了就删除了,重新建,没有就自动建表,同时以二进制方式打开写入json格式的数据文件,运行之中需要把数据传入item 的同时把数据存入myql,需要会插入的mysql语句,也把数据保存为json文件,别忘了,mysql游标记得commit一下保存,否则不会存入数据库。最后关掉文件和数据库连接。
对python操作mysql增删改差不太熟悉的朋友请点击传送门:https://blog.csdn.net/memory_qianxiao/article/details/82620079
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
from scrapy.exporters import JsonLinesItemExporter
from boss直聘.boss_job.boss_job.spiders.boss import BossSpider
import pymysql
#保存json个格式
class BossJobPipeline(object):
def __init__(self):
#连接数据库
dbparams={
'host':'127.0.0.1',
'port':3306,
'user':'test',
'password':'123',
'database':'boss直聘',
'charset':'utf8',
}
self.conn=pymysql.connect(**dbparams)
self.cursor=self.conn.cursor()#获取游标
self.sql=None
self.fjson=open('boss.json',"wb")#保存json格式
self.exporter=JsonLinesItemExporter(self.fjson,ensure_ascii=False)
# # 创建表之前看是否存在当前要创建的表,有就删除
self.cursor.execute("drop table if exists %s" % BossSpider.key_word)
# 创建搜索关键字表sql语句
sql = """create table %s(
id int primary key auto_increment,
公司名字 varchar (255),
所在城市 varchar (255),
工作名称 varchar (255),
薪水 varchar (255),
工作经验 varchar (255),
学历 varchar (255),
公司种类 varchar (255),
融资 varchar (255),
公司人数 varchar (255),
爬取时间 datetime)"""
# 执行创建表的语句
self.cursor.execute(sql % BossSpider.key_word)
def process_item(self, item, spider):
#插入数据的sql语句
self.sql="insert into %s"%BossSpider.key_word+"(公司名字,所在城市,工作名称,薪水,工作经验,学历,公司种类,融资,公司人数,爬取时间) values(%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)"
self.cursor.execute(self.sql,(item['company_name'],item['company_locale'],item['job_name'],
item['job_salary'],item['experience_demand'],item['educational_demand'],
item['company_work'],item['finance'],item['persons_in_company'],item['crawl_time']))
self.conn.commit()#保存数据
self.exporter.export_item(item)#传入item保存json数据
return item
def close_spider(self,spider):
self.fjson.close()#关闭json文件
self.conn.close()#关闭数据库连接
七:编写完后pipelines需要在setting 里面把ITEM_PIPELINES注释取消,才能生效

八:运行boss爬虫 scrapy crawl +爬虫名 eg:scrapy crawl boss
因为会多次爬取或者调试代码,每次运行爬虫,都要手动输入scrapy crawl +名字 这里选择新建一个start.py文件,把运行的语句scrapy crawl boss写进去,每次就不用输入这些代码了,直接鼠标右键运行就可以运行爬虫了。
代码如下:因为执行必须是一个列表的,输入的字符串需要切割(split一下)
# -*- coding: utf-8 -*-
# @Filename: start.py
# @Time : 2019/3/9 18:14
# @Author : LYT
from scrapy import cmdline
cmdline.execute('scrapy crawl boss'.split())运行如下:
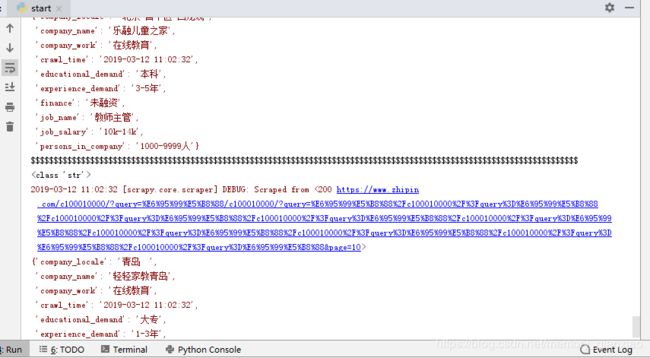
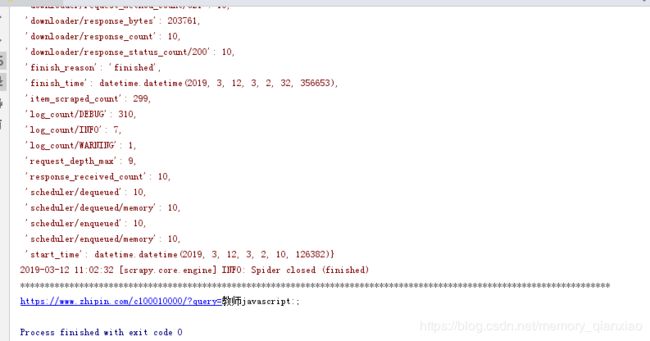
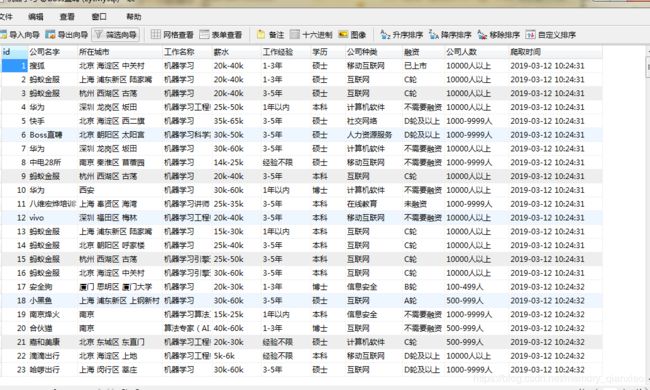
最后查看数据库如下:爬取很成功.!