res2net-yolov3的实现
res2net-yolov3的实现
1.res2net详解
论文:https://arxiv.org/pdf/1904.01169.pdf
1.简介:
近日,南开大学、牛津大学和加州大学默塞德分校的研究人员共同提出了一种面向目标检测任务的新模块Res2Net,新模块可以和现有其他优秀模块轻松整合,在不增加计算负载量的情况下,在ImageNet、CIFAR-100等数据集上的测试性能超过了ResNet。
Res2Net结构简单,性能优秀,可以进一步探索CNN在更细粒度级别的多“尺度”表示能力。 Res2Net揭示了一个新的维度,即“尺度”(Scale),除了深度,宽度和基数的现有维度之外,“尺度”是一个必不可少的更有效的因素。
“尺度”:在res2net模块内部,不同特征组合称为不同的尺度。原文(the number of feature groups in the Res2Net block)
2.原理:
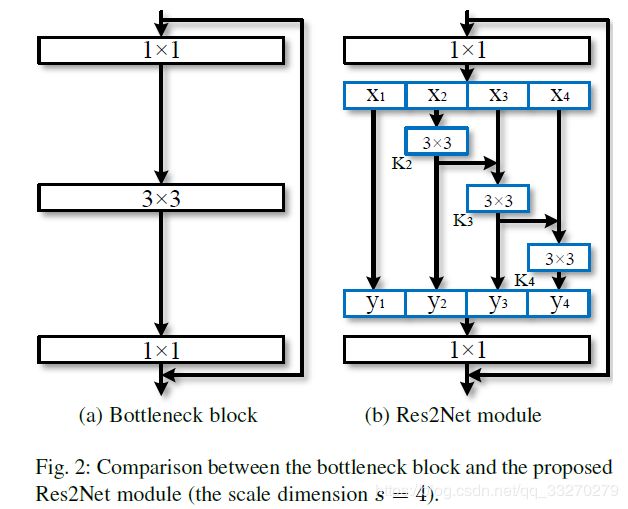
yi表示Ki()的输出(代表不同的“尺度”的特征组合)。 子特征xi和Ki-1()的输出加在一起,然后送入Ki()。 所有的特征组合拼接后在送入1*1的卷积,实现不同“尺度”特征的融合。
3.源码解析:
源码链接:https://github.com/gasvn/Res2Net(该工程基于pytorch中的res模块进行的修改)
预备知识:pytorch-res模块的实现方式(https://www.cnblogs.com/wzyuan/p/9880342.html)
class Bottle2neck(nn.Module):
expansion = 2 #通道压缩比,降低模型的计算量。
def __init__(self, inplanes, planes, stride=1, downsample=None, baseWidth=26, scale=4, stype='normal'):
""" Constructor
Args:
inplanes: input channel dimensionality #输入的特征数
planes: output channel dimensionality #1*1卷积通道压缩后的通道数,该模块最终的输出:planes*expansion
stride: conv stride. Replaces pooling layer.
downsample: None when stride = 1
baseWidth: basic width of conv3x3 #单一尺度上的3*3卷积的通道数量,控住不同尺度间,不同特征的重复利用的程度。
scale: number of scale. #分为几个尺度
type: 'normal': normal set. 'stage': first block of a new stage.# 'stage':没有不同尺度检测特征融合,相当于分组进行3*3卷积并最终进行拼接。
"""
super(Bottle2neck, self).__init__()
width = int(math.floor(planes * (baseWidth / 64.0))) #每个尺度的输入的特征通道的数量
self.conv1 = nn.Conv2d(inplanes, width * scale, kernel_size=1, bias=False)
self.bn1 = nn.BatchNorm2d(width * scale)
if scale == 1:
self.nums = 1
else:
self.nums = scale - 1
if stype == 'stage':
self.pool = nn.AvgPool2d(kernel_size=3, stride=stride, padding=1)
convs = []
bns = []
for i in range(self.nums):
convs.append(nn.Conv2d(width, width, kernel_size=3, stride=stride, padding=1, bias=False))
bns.append(nn.BatchNorm2d(width))
self.convs = nn.ModuleList(convs)
self.bns = nn.ModuleList(bns)
self.conv3 = nn.Conv2d(width * scale, planes * self.expansion, kernel_size=1, bias=False)
self.bn3 = nn.BatchNorm2d(planes * self.expansion)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
self.stype = stype
self.scale = scale
self.width = width
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
spx = torch.split(out, self.width, 1)
for i in range(self.nums):
if i == 0 or self.stype == 'stage':
sp = spx[i]
else:
sp = sp + spx[i]
sp = self.convs[i](sp)
sp = self.relu(self.bns[i](sp))
if i == 0:
out = sp
else:
out = torch.cat((out, sp), 1)
if self.scale != 1 and self.stype == 'normal': #其中有一组特征不做任何卷积操作,控制计算量不增加。因为不同特征组之间有重复利用的特征。
out = torch.cat((out, spx[self.nums]), 1)
elif self.scale != 1 and self.stype == 'stage':
out = torch.cat((out, self.pool(spx[self.nums])), 1)
out = self.conv3(out)
out = self.bn3(out)
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out2.res2net-yolov3的实现
1.网络设计
1.resnet->res2net

2.triangle->res2_triangle

3.res2net-yolov3网络结构
conv 32 3 x 3 / 1 608 x 608 x 3 -> 608 x 608 x 32
conv 64 3 x 3 / 2 608 x 608 x 32 -> 304 x 304 x 64
res*1 ------------>>>>>>>res2net*1
conv 128 3 x 3 / 2 304 x 304 x 64 -> 152 x 152 x 128
res*2 ------------>>>>>>>res2net*2
conv 256 3 x 3 / 2 152 x 152 x 128 -> 76 x 76 x 256
res*8 ------------>>>>>>>res2net*8
conv 512 3 x 3 / 2 76 x 76 x 256 -> 38 x 38 x 512
res*8 ------------>>>>>>>res2net*8
conv 1024 3 x 3 / 2 38 x 38 x 512 -> 19 x 19 x1024
res*4 ------------>>>>>>>res2net*4
triangle*2
conv 512 1 x 1 / 1 19 x 19 x1024 -> 19 x 19 x 512
conv 1024 3 x 3 / 1 19 x 19 x 512 -> 19 x 19 x1024
conv 255 1 x 1 / 1 19 x 19 x1024 -> 19 x 19 x 255
yolo
route -4
conv 256 1 x 1 / 1 19 x 19 x 512 -> 19 x 19 x 256
upsample 2x 19 x 19 x 256 -> 38 x 38 x 256
route -1 b
triangle*2
conv 256 1 x 1 / 1 38 x 38 x 512 -> 38 x 38 x 256
conv 512 3 x 3 / 1 38 x 38 x 256 -> 38 x 38 x 512
conv 255 1 x 1 / 1 38 x 38 x 512 -> 38 x 38 x 255
yolo
route -4
conv 128 1 x 1 / 1 38 x 38 x 256 -> 38 x 38 x 128
upsample 2x 38 x 38 x 128 -> 76 x 76 x 128
route -1 c
triangle*2
conv 128 1 x 1 / 1 76 x 76 x 256 -> 76 x 76 x 128
conv 256 3 x 3 / 1 76 x 76 x 128 -> 76 x 76 x 256
conv 255 1 x 1 / 1 76 x 76 x 256 -> 76 x 76 x 255
yolo
4.res2net+res2_triangle-yolov3网络结构
conv 32 3 x 3 / 1 608 x 608 x 3 -> 608 x 608 x 32
conv 64 3 x 3 / 2 608 x 608 x 32 -> 304 x 304 x 64
res*1 ------------>>>>>>>res2net*1
conv 128 3 x 3 / 2 304 x 304 x 64 -> 152 x 152 x 128
res*2 ------------>>>>>>>res2net*2
conv 256 3 x 3 / 2 152 x 152 x 128 -> 76 x 76 x 256
res*8 ------------>>>>>>>res2net*8
conv 512 3 x 3 / 2 76 x 76 x 256 -> 38 x 38 x 512
res*8 ------------>>>>>>>res2net*8
conv 1024 3 x 3 / 2 38 x 38 x 512 -> 19 x 19 x1024
res*4 ------------>>>>>>>res2net*4
triangle*2 ------------>>>>>>>res2_triangle*2
conv 512 1 x 1 / 1 19 x 19 x1024 -> 19 x 19 x 512
conv 1024 3 x 3 / 1 19 x 19 x 512 -> 19 x 19 x1024
conv 255 1 x 1 / 1 19 x 19 x1024 -> 19 x 19 x 255
yolo
route -4
conv 256 1 x 1 / 1 19 x 19 x 512 -> 19 x 19 x 256
upsample 2x 19 x 19 x 256 -> 38 x 38 x 256
route -1 b
triangle*2 ------------>>>>>>>res2_triangle*2
conv 256 1 x 1 / 1 38 x 38 x 512 -> 38 x 38 x 256
conv 512 3 x 3 / 1 38 x 38 x 256 -> 38 x 38 x 512
conv 255 1 x 1 / 1 38 x 38 x 512 -> 38 x 38 x 255
yolo
route -4
conv 128 1 x 1 / 1 38 x 38 x 256 -> 38 x 38 x 128
upsample 2x 38 x 38 x 128 -> 76 x 76 x 128
route -1 c
triangle*2 ------------>>>>>>>res2_triangle*2
conv 128 1 x 1 / 1 76 x 76 x 256 -> 76 x 76 x 128
conv 256 3 x 3 / 1 76 x 76 x 128 -> 76 x 76 x 256
conv 255 1 x 1 / 1 76 x 76 x 256 -> 76 x 76 x 255
yolo
2.代码实现
参考开源项目:https://github.com/Lam1360/YOLOv3-model-pruning
主要修改models.py,代码实现如下:
...
def create_modules(module_defs):
...
for module_i, module_def in enumerate(module_defs):
modules = nn.Sequential()
...
#新增Res2net模块yangchao
elif module_def["type"] == "res2net":
filters = int(module_def["planes"])*2
res2net = Bottle2neck(inplanes=int(module_def["inplanes"]),planes=int(module_def["planes"]),
stride=1, downsample=None, baseWidth=26, scale=4, stype='normal')
modules.add_module(f"res2net_{module_i}", res2net)
#新增triangle模块yangchao
elif module_def["type"] == "triangle":
triangle = Bottle2neck(inplanes=int(module_def["inplanes"]),planes=int(module_def["planes"]),
stride=1, downsample=None, baseWidth=16, scale=4, stype='normal')
modules.add_module(f"triangle_{module_i}", triangle)
...
# Register module list and number of output filters
module_list.append(modules)
output_filters.append(filters) # filter保存了输出的维度
return hyperparams, module_list, resnum
#新增Res2net模块yangchao
class Bottle2neck(nn.Module):
expansion = 2 #通道压缩比,降低模型的计算量。
def __init__(self, inplanes, planes, stride=1, downsample=None, baseWidth=26, scale=4, stype='normal'):
""" Constructor
Args:
inplanes: input channel dimensionality #输入的特征数
planes: output channel dimensionality #1*1卷积通道压缩后的通道数,该模块最终的输出:planes*expansion
stride: conv stride. Replaces pooling layer.
downsample: None when stride = 1
baseWidth: basic width of conv3x3 #单一尺度上的3*3卷积的通道数量,控住不同尺度间,不同特征的重复利用的程度。
scale: number of scale. #分为几个尺度
type: 'normal': normal set. 'stage': first block of a new stage.
"""
super(Bottle2neck, self).__init__()
width = int(math.floor(planes * (baseWidth / 64.0)))
self.conv1 = nn.Conv2d(inplanes, width * scale, kernel_size=1, bias=False)
self.bn1 = nn.BatchNorm2d(width * scale)
if scale == 1:
self.nums = 1
else:
self.nums = scale - 1
if stype == 'stage':
self.pool = nn.AvgPool2d(kernel_size=3, stride=stride, padding=1)
convs = []
bns = []
for i in range(self.nums):
convs.append(nn.Conv2d(width, width, kernel_size=3, stride=stride, padding=1, bias=False))
bns.append(nn.BatchNorm2d(width))
self.convs = nn.ModuleList(convs)
self.bns = nn.ModuleList(bns)
self.conv3 = nn.Conv2d(width * scale, planes * self.expansion, kernel_size=1, bias=False)
self.bn3 = nn.BatchNorm2d(planes * self.expansion)
self.leaky = nn.LeakyReLU(0.1,inplace=True)
self.linear = nn.LeakyReLU(1.0, inplace=True)#纯线性激活函数,后期会做解释。
self.downsample = downsample
self.stype = stype
self.scale = scale
self.width = width
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.leaky(out)
spx = torch.split(out, self.width, 1)
for i in range(self.nums):
if i == 0 or self.stype == 'stage':
sp = spx[i]
else:
sp = sp + spx[i]
sp = self.convs[i](sp)
sp = self.leaky(self.bns[i](sp))
if i == 0:
out = sp
else:
out = torch.cat((out, sp), 1)
if self.scale != 1 and self.stype == 'normal':
out = torch.cat((out, spx[self.nums]), 1)
elif self.scale != 1 and self.stype == 'stage':
out = torch.cat((out, self.pool(spx[self.nums])), 1)
out = self.conv3(out)
out = self.bn3(out)
# out = self.leaky(out)
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.linear(out)
return out
#新增Triangle模块yangchao
class Triangle(nn.Module):
expansion = 2 #通道压缩比,降低模型的计算量。
def __init__(self, inplanes, planes, stride=1, downsample=None, baseWidth=16, scale=4, stype='normal'):
""" Constructor
Args:
inplanes: input channel dimensionality #输入的特征数
planes: output channel dimensionality #1*1卷积通道压缩后的通道数,该模块最终的输出:planes*expansion
stride: conv stride. Replaces pooling layer.
downsample: None when stride = 1
baseWidth: basic width of conv3x3 #单一尺度上的3*3卷积的通道数量,控住不同尺度间,不同特征的重复利用的程度。
scale: number of scale. #分为几个尺度
type: 'normal': normal set. 'stage': first block of a new stage.
"""
super(Triangle, self).__init__()
width = int(math.floor(planes * (baseWidth / 64.0)))
self.conv1 = nn.Conv2d(inplanes, width * scale, kernel_size=1, bias=False)
self.bn1 = nn.BatchNorm2d(width * scale)
if scale == 1:
self.nums = 1
else:
self.nums = scale - 1
if stype == 'stage':
self.pool = nn.AvgPool2d(kernel_size=3, stride=stride, padding=1)
convs = []
bns = []
for i in range(self.nums):
convs.append(nn.Conv2d(width, width, kernel_size=3, stride=stride, padding=1, bias=False))
bns.append(nn.BatchNorm2d(width))
self.convs = nn.ModuleList(convs)
self.bns = nn.ModuleList(bns)
self.leaky = nn.LeakyReLU(0.1,inplace=True)
self.downsample = downsample
self.stype = stype
self.scale = scale
self.width = width
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.leaky(out)
spx = torch.split(out, self.width, 1)
for i in range(self.nums):
if i == 0 or self.stype == 'stage':
sp = spx[i]
else:
sp = sp + spx[i]
sp = self.convs[i](sp)
sp = self.leaky(self.bns[i](sp))
if i == 0:
out = sp
else:
out = torch.cat((out, sp), 1)
if self.scale != 1 and self.stype == 'normal':
out = torch.cat((out, spx[self.nums]), 1)
elif self.scale != 1 and self.stype == 'stage':
out = torch.cat((out, self.pool(spx[self.nums])), 1)
return out
class Darknet(nn.Module):
#...
def load_darknet_weights(self, weights_path):
...
for i, (module_def, module) in enumerate(zip(self.module_defs, self.module_list)):
...
#新增Res2net模块yangchao
elif module_def["type"] == "res2net":
module_r = module[0]
#conv1
conv1 = module_r.conv1
bn1 = module_r.bn1
# Load BN bias, weights, running mean and running variance
num_b = bn1.bias.numel() # Number of biases
# Bias
bn_b = torch.from_numpy(weights[ptr: ptr + num_b]).view_as(bn1.bias)
bn1.bias.data.copy_(bn_b)
ptr += num_b
# Weight
bn_w = torch.from_numpy(weights[ptr: ptr + num_b]).view_as(bn1.weight)
bn1.weight.data.copy_(bn_w)
ptr += num_b
# Running Mean
bn_rm = torch.from_numpy(weights[ptr: ptr + num_b]).view_as(bn1.running_mean)
bn1.running_mean.data.copy_(bn_rm)
ptr += num_b
# Running Var
bn_rv = torch.from_numpy(weights[ptr: ptr + num_b]).view_as(bn1.running_var)
bn1.running_var.data.copy_(bn_rv)
ptr += num_b
# Load conv. weights
num_w = conv1.weight.numel()
conv_w = torch.from_numpy(weights[ptr: ptr + num_w]).view_as(conv1.weight)
conv1.weight.data.copy_(conv_w)
ptr += num_w
#convs
convs = module_r.convs
bns = module_r.bns
for i in range(3):
# Load BN bias, weights, running mean and running variance
num_b = bns[i].bias.numel() # Number of biases
# Bias
bn_b = torch.from_numpy(weights[ptr: ptr + num_b]).view_as(bns[i].bias)
bns[i].bias.data.copy_(bn_b)
ptr += num_b
# Weight
bn_w = torch.from_numpy(weights[ptr: ptr + num_b]).view_as(bns[i].weight)
bns[i].weight.data.copy_(bn_w)
ptr += num_b
# Running Mean
bn_rm = torch.from_numpy(weights[ptr: ptr + num_b]).view_as(bns[i].running_mean)
bns[i].running_mean.data.copy_(bn_rm)
ptr += num_b
# Running Var
bn_rv = torch.from_numpy(weights[ptr: ptr + num_b]).view_as(bns[i].running_var)
bns[i].running_var.data.copy_(bn_rv)
ptr += num_b
# Load conv. weights
num_w = convs[i].weight.numel()
conv_w = torch.from_numpy(weights[ptr: ptr + num_w]).view_as(convs[i].weight)
convs[i].weight.data.copy_(conv_w)
ptr += num_w
#conv3
conv3 = module_r.conv3
bn3 = module_r.bn3
# Load BN bias, weights, running mean and running variance
num_b = bn3.bias.numel() # Number of biases
# Bias
bn_b = torch.from_numpy(weights[ptr: ptr + num_b]).view_as(bn3.bias)
bn3.bias.data.copy_(bn_b)
ptr += num_b
# Weight
bn_w = torch.from_numpy(weights[ptr: ptr + num_b]).view_as(bn3.weight)
bn3.weight.data.copy_(bn_w)
ptr += num_b
# Running Mean
bn_rm = torch.from_numpy(weights[ptr: ptr + num_b]).view_as(bn3.running_mean)
bn3.running_mean.data.copy_(bn_rm)
ptr += num_b
# Running Var
bn_rv = torch.from_numpy(weights[ptr: ptr + num_b]).view_as(bn3.running_var)
bn3.running_var.data.copy_(bn_rv)
ptr += num_b
# Load conv. weights
num_w = conv3.weight.numel()
conv_w = torch.from_numpy(weights[ptr: ptr + num_w]).view_as(conv3.weight)
conv3.weight.data.copy_(conv_w)
ptr += num_w
#新增Triangle模块yangchao
elif module_def["type"] == "triangle":
module_r = module[0]
#conv1
conv1 = module_r.conv1
bn1 = module_r.bn1
# Load BN bias, weights, running mean and running variance
num_b = bn1.bias.numel() # Number of biases
# Bias
bn_b = torch.from_numpy(weights[ptr: ptr + num_b]).view_as(bn1.bias)
bn1.bias.data.copy_(bn_b)
ptr += num_b
# Weight
bn_w = torch.from_numpy(weights[ptr: ptr + num_b]).view_as(bn1.weight)
bn1.weight.data.copy_(bn_w)
ptr += num_b
# Running Mean
bn_rm = torch.from_numpy(weights[ptr: ptr + num_b]).view_as(bn1.running_mean)
bn1.running_mean.data.copy_(bn_rm)
ptr += num_b
# Running Var
bn_rv = torch.from_numpy(weights[ptr: ptr + num_b]).view_as(bn1.running_var)
bn1.running_var.data.copy_(bn_rv)
ptr += num_b
# Load conv. weights
num_w = conv1.weight.numel()
conv_w = torch.from_numpy(weights[ptr: ptr + num_w]).view_as(conv1.weight)
conv1.weight.data.copy_(conv_w)
ptr += num_w
#convs
convs = module_r.convs
bns = module_r.bns
for i in range(3):
# Load BN bias, weights, running mean and running variance
num_b = bns[i].bias.numel() # Number of biases
# Bias
bn_b = torch.from_numpy(weights[ptr: ptr + num_b]).view_as(bns[i].bias)
bns[i].bias.data.copy_(bn_b)
ptr += num_b
# Weight
bn_w = torch.from_numpy(weights[ptr: ptr + num_b]).view_as(bns[i].weight)
bns[i].weight.data.copy_(bn_w)
ptr += num_b
# Running Mean
bn_rm = torch.from_numpy(weights[ptr: ptr + num_b]).view_as(bns[i].running_mean)
bns[i].running_mean.data.copy_(bn_rm)
ptr += num_b
# Running Var
bn_rv = torch.from_numpy(weights[ptr: ptr + num_b]).view_as(bns[i].running_var)
bns[i].running_var.data.copy_(bn_rv)
ptr += num_b
# Load conv. weights
num_w = convs[i].weight.numel()
conv_w = torch.from_numpy(weights[ptr: ptr + num_w]).view_as(convs[i].weight)
convs[i].weight.data.copy_(conv_w)
ptr += num_w
# 确保指针到达权重的最后一个位置
assert ptr == len(weights)
def save_darknet_weights(self, path, cutoff=-1):
...
# Iterate through layers
for i, (module_def, module) in enumerate(zip(self.module_defs[:cutoff], self.module_list[:cutoff])):
# print(module)
if module_def["type"] == "convolutional":
...
#新增Res2net模块yangchao
elif module_def["type"] == "res2net":
module_r = module[0]
conv1 = module_r.conv1
# If batch norm, load bn first
bn1 = module_r.bn1
bn1.bias.data.cpu().numpy().tofile(fp)
bn1.weight.data.cpu().numpy().tofile(fp)
bn1.running_mean.data.cpu().numpy().tofile(fp)
bn1.running_var.data.cpu().numpy().tofile(fp)
# Load conv weights
conv1.weight.data.cpu().numpy().tofile(fp)
convs = module_r.convs
bns = module_r.bns
for i in range(3):
bns[i].bias.data.cpu().numpy().tofile(fp)
bns[i].weight.data.cpu().numpy().tofile(fp)
bns[i].running_mean.data.cpu().numpy().tofile(fp)
bns[i].running_var.data.cpu().numpy().tofile(fp)
# Load conv weights
convs[i].weight.data.cpu().numpy().tofile(fp)
conv3 = module_r.conv3
# If batch norm, load bn first
bn3 = module_r.bn3
bn3.bias.data.cpu().numpy().tofile(fp)
bn3.weight.data.cpu().numpy().tofile(fp)
bn3.running_mean.data.cpu().numpy().tofile(fp)
bn3.running_var.data.cpu().numpy().tofile(fp)
# Load conv weights
conv3.weight.data.cpu().numpy().tofile(fp)
#新增Triangle模块yangchao
elif module_def["type"] == "triangle":
module_r = module[0]
conv1 = module_r.conv1
# If batch norm, load bn first
bn1 = module_r.bn1
bn1.bias.data.cpu().numpy().tofile(fp)
bn1.weight.data.cpu().numpy().tofile(fp)
bn1.running_mean.data.cpu().numpy().tofile(fp)
bn1.running_var.data.cpu().numpy().tofile(fp)
# Load conv weights
conv1.weight.data.cpu().numpy().tofile(fp)
convs = module_r.convs
bns = module_r.bns
for i in range(3):
bns[i].bias.data.cpu().numpy().tofile(fp)
bns[i].weight.data.cpu().numpy().tofile(fp)
bns[i].running_mean.data.cpu().numpy().tofile(fp)
bns[i].running_var.data.cpu().numpy().tofile(fp)
# Load conv weights
convs[i].weight.data.cpu().numpy().tofile(fp)
fp.close()