上一篇已经对百科百科的结构特点进行了分析,这一篇开始介绍本体构建模块的实现。
抓取百度百科
抓取百度百科页面数据自然需要一款爬虫,可以自己实现或者使用现成的爬虫框架。目前本体构建模块选取的是开源爬虫框架 WebMagic,下面对 WebMagic 做一个基本介绍。
官方文档给出的 WebMagic 总体架构图如下:

如上所示, WebMagic 具有四大组件:
- Downloader 负责下载页面,默认使用 Apache HttpClient 作为下载工具。下载下来的页面将交付给 PageProcessor 进行解析。
- PageProcessor 用来解析页面,我们可以在这里定义抽取规则并抽取出需要的数据,抽取出的数据封装成 ResultItems 对象交付给 Pipeline 处理。
- Scheduler 管理待抓取的 URL,并负责去重工作。Downloader 需要下载页面的 URL 就来自于这里,而 PageProcessor 发现的新 URL 也将插入到这里。
- Pipeline 负责对抽取出的数据进行最后的处理,包括计算、过滤、持久化到文件或数据库等。
以上四大组件都封装到一个核心类 Spider 中,可以将 Spider 看成是 WebMagic 运转的引擎,它将作为我们进行各项操作的入口。
关于 WebMagic 更为详细的原理和使用的介绍,请参阅 WebMagic 官方文档
按照官方文档下载并在项目中集成 WebMagic 之后,我们需要实现自定义 PageProcessor 来抽取数据。同时实现自定义 Pipeline 来实现对抽取的数据的进一步处理(本体构建)和持久化(保存到本体文件),也就是说使用 Jena 接口进行本体构建的关键操作就是在 Pipeline 阶段完成的。
下面上详细代码。
public class OntologyConstructionLauncher {
public static Long pageCount = 0L;
public static void main(String args[]) {
// 创建自定义 PageProcessor,
OntologyConstructionPageProcessor constructionPageProcessor = new OntologyConstructionPageProcessor();
// 创建自定义 Pipeline
OntologyConstructionPipeline constructionPipeline = new OntologyConstructionPipeline();
// 启动爬虫并做相关设置
Spider.create(constructionPageProcessor)
.addUrl("http://baike.baidu.com/view/5081.htm")
.addPipeline(constructionPipeline)
// 开启1个线程抓取
.thread(1)
.run();
}
}
在 OntologyConstructionPageProcessor 实现 Magic 的 PageProcessor 接口,并实现接口的 public void process(Page page) 方法,其中 page 封装的便是 Download 组件下载的页面数据,在 process 方法内就需要定义所要抽取的数据的 XPath,并依据 XPath 抽取相应数据。XPath 要如何确定?需要分析页面元素的 HTML 结构。
调出浏览器控制台分析百科页面元素的标签,例如词条的标题元素的 HTML 标签如下
火影忍者
(岸本齐史创作的少年漫画)
....
则其 XPath 路径可定义为 //dd[@class='lemmaWgt-lemmaTitle-title']/h1/allText()(关于 XPath 也请参阅相关文档和 WebMagic 说明文档),调用 page.getHtml().xpath('xxx') 可依据 XPath 获得该数据,并通过 page.putField() 方法将数据存入 ResultItems 对象中。代码如下:
// 内容一:词条标题
// 抽取词条标题文本
String lemmaTitle = page.getHtml().xpath("//dd[@class='lemmaWgt-lemmaTitle-title']/h1/allText()").toString();
// 将文本存入 ResultItems,以传递给 Pipeline
page.putField("lemmaTitle", lemmaTitle);
另外不要忘记将当前页面的所有 URL 加入到待抓取队列 Scheduler 中,代码如下:
page.addTargetRequests(page.getHtml().links().regex("http://baike\\.baidu\\.com/.*").all());
再来看自定义 OntologyConstructionPipeline 类,该类实现 Pipeline 接口并实现接口的 public void process(ResultItems resultItems, Task task) 方法,其中 resultItems 封装的便是从 OntologyConstructionPageProcessor 传递过来的数据,如通过如下代码获取词条标题:
// 内容一:词条标题
String lemmaTitle = resultItems.get("lemmaTitle");
词条分类
在所有数据中,页面的基本信息一栏对本体构建很重要,如下图所示:
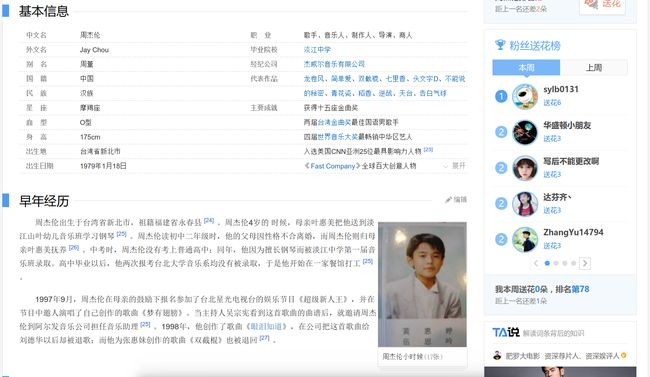
在 OntologyConstructionPipeline 中,我们首先获得这些属性名(中文名、外文名等):
// 获取这些属性名
List parameterNames = resultItems.get("parameterNames");
...
// 过滤属性名中的特殊字符,例如 160 号不间断空格等
List parameterNamesFilter = StringFilter.nonBreakingSpaceFilter(parameterNames);
...
// 根据属性特征进行分类
OntologyClassEnum ontologyClassEnum = LemmaClassify.classify(parameterNamesFilter);
其中 LemmaClassify.classify(parameterNamesFilter) 利用属性名对该词条进行分类,代码如下:
public static OntologyClassEnum classify(List parameterNamesFilter) {
// 如果该页面没有实体属性 则将该页面分类到其他类别中
if (parameterNamesFilter == null) {
return OntologyClassEnum.OTHERS;
}
for (String parameterName : parameterNamesFilter) {
if (parameterName.equals("出生地点") || parameterName.equals("出生日期") || parameterName.equals("性别") || parameterName.equals("出生地") || parameterName.equals("职业") || parameterName.equals("国籍")) {
return OntologyClassEnum.CHARACTER;
}
if (parameterName.equals("票房") || parameterName.equals("片长") || parameterName.equals("上映时间")) {
return OntologyClassEnum.MOVIE;
}
if (parameterName.equals("谱曲") || parameterName.equals("填词") || parameterName.equals("谱曲") || parameterName.equals("歌曲时长")) {
return OntologyClassEnum.MUSIC;
}
if (parameterName.equals("动画制作")) {
return OntologyClassEnum.ANIMATION;
}
if (parameterName.equals("出版期间")) {
return OntologyClassEnum.CARICATURE;
}
if (parameterName.equals("首都") || parameterName.equals("国歌") || parameterName.equals("国旗") || parameterName.equals("地区生产总值") || parameterName.equals("人均生产总值")) {
return OntologyClassEnum.AREA;
}
if (parameterName.equals("学校类型") || parameterName.equals("学校代码") || parameterName.equals("学校地址") || parameterName.equals("现任校长") || parameterName.equals("知名校友")) {
return OntologyClassEnum.ACADEMY;
}
if (parameterName.equals("公司名称") || parameterName.equals("公司性质") || parameterName.equals("公司使命") || parameterName.equals("公司口号") || parameterName.equals("公司地址")) {
return OntologyClassEnum.COMPANY;
}
}
return OntologyClassEnum.OTHERS;
}
以上是通过定义规则分类模板来进行词条分类,这是当前 0.9.0 版本 Answer 所采用的方法,这个方法很土,但作为 Demo 版本姑且先这么实现。后续可能会通过机器学习的方法如贝叶斯、支持向量机等训练分类器来对词条进行分类。
进行分类之后就可能根据不同的类型创建本体库,代码如下:
// 根据分类结果获取对应类型的本体构建对象
ConstructionServiceI constructionService = LemmaClassify.classify(ontologyClassEnum);
try {
// 开始构建本体
constructionService.construction(baikePage);
} catch(Exception e) {
e.printStackTrace();
}
其中 LemmaClassify.classify(ontologyClassEnum) 方法代码如下:
public static ConstructionServiceI classify(OntologyClassEnum ontologyClassEnum) {
switch (ontologyClassEnum) {
case CHARACTER :
return new CharacterConstructionServiceImpl();
case MOVIE :
return new MovieConstructionServiceImpl();
case MUSIC :
return new MusicConstructionServiceImpl();
case ANIMATION :
return new AnimationConstructionServiceImpl();
case CARICATURE :
return new CaricatureConstructionServiceImpl();
case AREA :
return new AreaConstructionServiceImpl();
case ACADEMY :
return new AcademyConstructionServiceImpl();
case COMPANY :
return new CompanyConstructionServiceImpl();
default :
return new OthersConstructionServiceImpl();
}
}
实体词典
如果本体库涉及多个领域,那么之前文章所提到的同名实体问题就会变得更为明显。为了解决这个问题,Answer 系统中设计了具有多个用途的实体词典。实体词典在 Answer 系统中具有很重要的作用,在本体构建阶段可用来避免重复抓取,在语义解析阶段可用来进行命名实体识别和实体别名识别等。
实体词典最终的字段设计为 UUID、实体名、歧义说明、URL、是否本名、类型共六个字段,如下图所示:
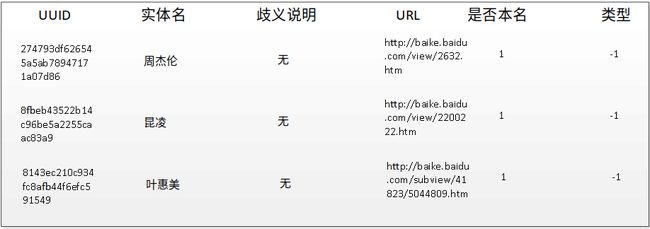
我们以抓取周星驰页面为例,抓取的过程中,在向本体库插入“周星驰”这个实体以及他的相关对象属性和数据属性、二级类等信息之前,程序将先查询该词典。如果该词典中已经存在“周星驰”这个实体名,同时URL和当前抓取的URL相同(因为可能存在另一个叫周星驰的人存在),则认为当前抓取的“周星驰”页面代表的实体已经存在,则直接取出UUID字段更新这个实体的相关数据。如果没有,则生成一个UUID,插入记录到该词典中,并在本体库中生成一个新实体。
另外还存在一种情况,在 "周星驰" 的页面中,有明星关系这一对象属性,例如在明星关系这一栏中我们有 "周星驰"-"搭档"-"吴孟达" 这一个对象属性。
我们在创建对象属性时,将在本体库中创建一个 "吴孟达" 的实体,这样才能建立该对象属性,因为对象属性实际上是实体和实体之间联系,但是在当前的 "周星驰" 页面中,我们并没有 "吴孟达" 的相关信息,这意味着我们建立 "吴孟达" 这个实体时是无法完善其相关属性等信息的,只有等到爬虫爬取到 "吴孟达" 那个百科页面时我们才能完善其信息。
因此这时候我们需要标识实体是否是完善状态,在 Answer 系统中,我们仍然通过实体词典来解决这个问题,我们在歧义理解这个字段上写入 "待更新" ,表示该实体还未完善属性,那么在抓取到 "吴孟达" 那个页面时并可判断本体库中的 "吴孟达" 实体是否是待更新,如果是,则使用 "吴孟达" 页面的相关信息来更新本体库中的实体。
实体词典中的 "是否本名" 这个字段来表示该实体是本名实体,还是别名实体,依然以 "周星驰" 页面为例,抓取到实体 "周星驰",这个并可标识为本名(用 1 表示),而对于周星驰页面中的别名属性,其中有 "星爷、星仔、阿星" 等,则在构建"星爷"、"星仔"、"阿星" 等实体时,将其标识为别名(用 0 表示)。
最后实体词典中的类型表示该实体所属于的类,一共分为拟人、电影、音乐、动画、漫画、地区、院校、公司、其它九大类(分别用 -1 到 -9 表示)。
本体构建
Answer 系统本体构建模块的构建原理实际上是针对百科页面实现了八大类的模板(在这八大类之外的分到第九大类其它类中),因此在这里不同类的构建代码都不相同,但同时不同之处也仅仅在于个别对象属性不同,整体的构建思路是相似的,所以下面以 "拟人" 类实体的构建为例,给出 "拟人" 类实体构建的算法实现过程如下图所示:
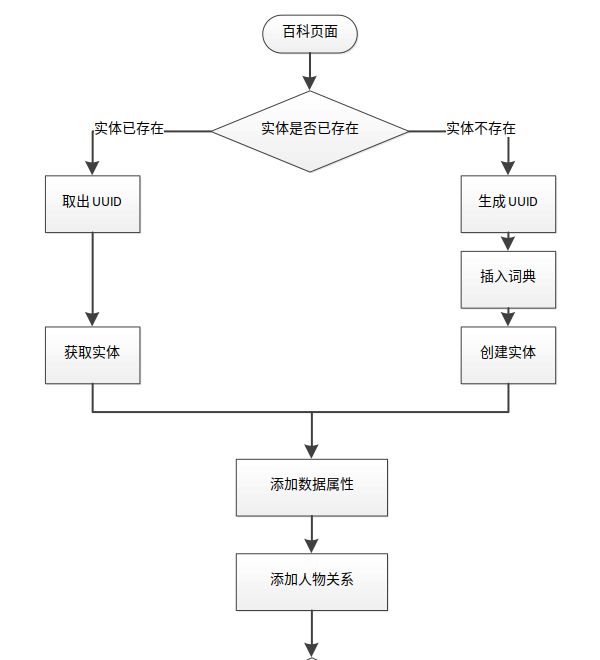
在添加人物关系时,添加的是对象属性即添加新的实体,固在此需要判断实体是否存在,如下图所示:
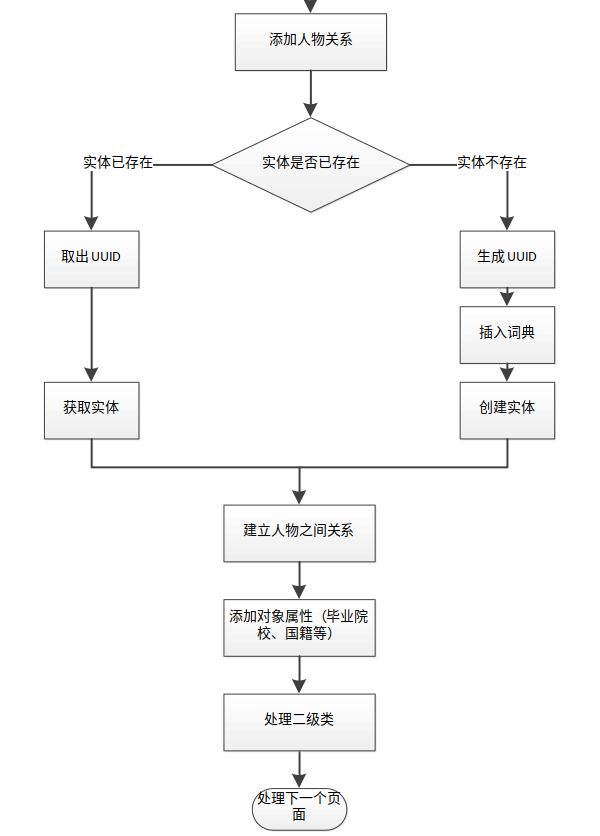
主要构建代码如下:
@Override
public boolean construction(BaikePage baikePage) throws Exception {
// 词条标题(实体名)
String individualName = baikePage.getLemmaTitle();
String polysemantExplain = baikePage.getPolysemantExplain();
String url = baikePage.getUrl();
Individual characterIndividual = null;
// 查询词典中是否有该实体 有则查询返回 没有则创建返回 true表示这是本名
characterIndividual = this.queryIndividual(individualName, polysemantExplain, url, true, OntologyClassEnum.CHARACTER);
constructionDAO.addObjectProperty(characterIndividual, "是", characterIndividual);
// 添加数据属性(描述和歧义说明)
String lemmaSummary = baikePage.getLemmaSummary();
String picSrc = baikePage.getPicSrc();
if (picSrc != null) {
// 取得当前时间
long times = System.currentTimeMillis();
// 生成0-1000的随机数
int random = (int)(Math.random() * 1000);
// 扩展名称
String newPicName = times + "" + random + ".jpg";
PictureDownloader.picDownload(picSrc, newPicName, Config.picSavePath + File.separator + OntologyClassEnum.CHARACTER.getName() );
constructionDAO.addDataProperty(characterIndividual, "picSrc", newPicName);
}
constructionDAO.addDataProperty(characterIndividual, "URL信息来源", url);
constructionDAO.addDataProperty(characterIndividual, "描述", lemmaSummary);
constructionDAO.addDataProperty(characterIndividual, "歧义说明", polysemantExplain);
// 添加人物关系
/*List relationNames = baikePage.getRelationNames();
List relationValues = baikePage.getParameterValues();
List relationUrls = baikePage.getRelationUrls();*/
if (baikePage.getRelationNames().size() != 0 && baikePage.getRelationValues().size() !=0) {
this.dealCharacterRelations(characterIndividual, baikePage);
}
// 添加基本信息
List parameterNamesFilter = baikePage.getParameterNames();
List parameterValuesFilter = baikePage.getParameterValues();
constructionDAO.addDataProperties(characterIndividual, parameterNamesFilter, parameterValuesFilter);
// 处理别名
this.dealAliases(characterIndividual, baikePage);
// 处理职业
this.dealProfession(characterIndividual, baikePage);
// 处理人物-地区对象(国籍对象属性) TODO 超链接情况
this.dealNationality(characterIndividual, baikePage);
// 处理人物-院校对象(毕业院校对象属性)
this.dealGraduateSchools(characterIndividual, baikePage);
// 处理人物-公司对象(毕业院校公司属性)
this.dealCompanys(characterIndividual, baikePage);
return false;
}
其中 constructionDAO.addDataProperties 等方法内部便是调用 Jena API 实现对实体添加数据属性。在目前的实现中, Jena 会在内存建立一个本体数据模型 OntModel,对本体库的操作就是对该内存数据模型的操作,之后会将该模型写入到磁盘文件中。这里代码实现的时候是每次操作都会写入磁盘文件,这无疑是增加了磁盘 IO,效率极低,看来当时本科写这些代码时还没有优化的意识,后面找个时间改改。
因为现在是将磁盘中的 OWL 文件载入内存建立 OntModel 模型,然后对模型操作,所以单机情况下查询速度还可接受。但是如果数据量大了之后,尤其是具备了海量数据量之后,如果进行本体的分布式存储?如何按需载入构建数据模型?这些问题是 Demo 版没有考虑的,也是之后我想要解决的问题,这部分还需要抽时间继续查阅论文和相关资料找寻解决方案。
另外从代码中也可知目前实体之间的关系也是通过分析百科然后人工定义,如人物与地区的关系、人物与院校的关系......
这种方式的局限性还是很明显的,因为关系是没办法穷举定义的。但是就像之前说的那样,百度百科依然不属于完全语义标注的数据源(就像上一篇所说,我们是利用 HTML 标签来做标注),所以想要自动挖掘和定义新的对象关系还是有一定难度的。
如果有哪位专门搞知识图谱或做过类似工作的大牛看到这篇文章,对如何从百度百科中挖掘词条与词条之间的关联以及对如何实现本体库的分布式存储有一定的思路,欢迎交流和赐教!
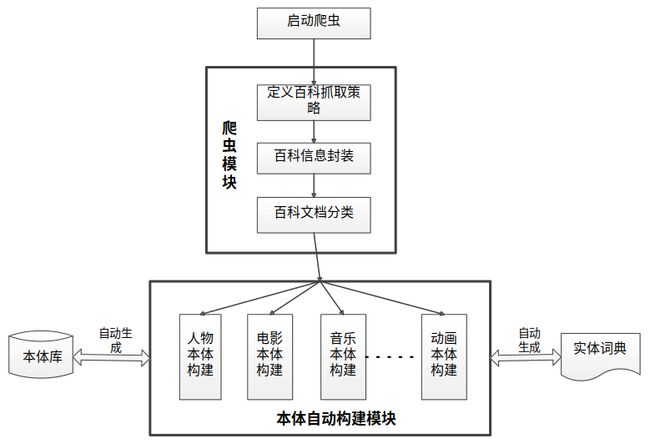
本体构建模块框架图
最后再补充上本体构建模块的框架图,如下:
下一篇
这一篇加上前面两篇,基本介绍完了基于规则的本体构建模块。本体构建模块还有很多需要解决的问题,例如实体的分类算法,实体之间的关联关系挖掘、本体库的分布式存储等,后续也许会有重构,也希望路过的大牛提供一些思路。
下一篇应该会开始介绍本体查询模块。
汪
汪.