操作系统课程设计报告
操作系统课程设计报告
目录
实验一、Windows进程管理 1
实验二、Linux 进程管理 6
实验三、互斥与同步 7
实验四、银行家算法的模拟与实现 10
实验五、内存管理 14
实验六、磁盘调度 18
实验一、Windows进程管理
1、实验目的
(1)学会使用 VC 编写基本的 Win32 Consol Application(控制台应用程序)。
(2)通过创建进程、观察正在运行的进程和终止进程的程序设计和调试操作,进一步熟悉操 作系统的进程概念,理解 Windows 进程的“一生”。
(3)通过阅读和分析实验程序,学习创建进程、观察进程、终止进程以及父子进程同步的基 本程序设计方法。
2、详细设计
(1)编写基本的 Win32 Consol Application
一开始运行不成功,因为分号,双引号等字符为中文字符。

(2) 创建进程
程序从main函数开始,创建进程,每次引用该进程exe文件位置创建下一个进程(再反过来继续调用main函数,如此循环,使用c_nCloneMax作为限制)并使得nCloneID+1显示当前进程ID

打开任务管理器可以看到这些进程正在运行:

第一次修改: 结果不变(如图)

第二次修改:
我的理解是:因为改变了nclone=0赋值语句的位置,在运行时,每次都会将nclone的值变为0,所以每次在运行下面的程序时:
// 检查是否有创建子进程的需要
const int c_nCloneMax=5;
if (nClone < c_nCloneMax)
{
// 发送新进程的命令行和克隆号
StartClone(++nClone) ;
}
nClone < c_nCloneMax会永远成立,所以永远不会达到限制条件5,变成死循环,一直不断的创建ID为0的新进程,直至溢出内存。
1、nClone 的作用:
控制ID的起始值,控制创建进程的数量。
2、变量的定义和初始化方法(位置)对程序的执行结果的有没有影响?
有影响,在修改变量的定义和初始化位置时,通过程序运行结果观察到,它们的改变引起了进程的创建数目的不同(循环次数有不同),也引起了ID的起始位置的变化
(3) 父子进程的简单通信及终止进程
步骤2运行结果如图

步骤三:将下句中的字符串 child 改为别的字符串, 重新编译执行。
sprintf(szCmdLine, "\"%s\"baby" , szFilename) ;
可以观察到,在创建子进程的之后,进入的不再是child函数,而是在循环执行parent函数,所以,程序在不断的创建子进程。
步骤四:

将INFINIT换成0,意味着子进程来不及等待父进程在释放互斥体之后发送过来的自杀指令,就自己执行了下面的自杀代码。
步骤 5 : 参考 MSDN 中 的 帮 助 文 件 CreateMutex() 、 OpenMutex() 、 ReleaseMutex() 和 WaitForSingleObject()的使用方法,理解父子进程如何利用互斥体进行同步的。
CreateMutex()是创建互斥体,OpenMutex()是打开互斥体,ReleqaseMutex()是释放互斥体,WaitForSingleObject()是检测hMutexSuicide事件的信号状态,通过这些方法可以实现当前只有一个进程被创建或被使用,实现进程的同步。
3、实验结果与分析
互斥体实现了“互相排斥”(mutual exclusion)同步的简单形式(所以名为互斥体(mutex))。互斥体禁止多个线程同时进入受保护的代码“临界区”(critical section)。因此,在任意时刻,只有一个线程被允许进入这样的代码保护区。任何线程在进入临界区之前,必须获取(acquire)与此区域相关联的互斥体的所有权。如果已有另一线程拥有了临界区的互斥体,其他线程就不能再进入其中。这些线程必须等待,直到当前的属主线程释放(release)该互斥体。
WaitForSingleObject函数用来检测hMutexSuicide事件的信号状态,在某一线程中调用该函数时 ,线程暂时挂起,如果在挂起的dwMilliseconds毫秒内,线程所等待的对象变为有信号状态,则该函数立即返回;如果超时时间已经到达dwMilliseconds毫秒,但hMutexSuicide所指向的对象还没有变成有信号状态,函数照样返回。 参数dwMilliseconds有两个具有特殊意义的值:0和INFINITE。若为0,则该函数立即返回;若为INFINITE,则线程一直被挂起,直到hHandle所指向的对象变为有信号状态时为止。
5、实验总结与体会
对互斥与同步有了简单的了解,熟练了在命令行运行代码的相关操作。虽然操作系统对我来说真的有点难度,但是我还是尽力在理解和掌握,希望能通过每一个实验都收获到一些知识。
实验二、Linux 进程管理
1、 实验目的
通过进程的创建、撤销和运行加深对进程概念和进程并发执行的理解,明确进程和程序之间的区别。
2、 总体设计
任务要求1: 编写一段程序,使用系统调用 fork()创建两个子进程。当此程序运行时,在系统中有一个父进程和两个子进程活动。让每一个进程在屏幕上显示一个字符:父进程显示字符“ a”;两子进程分别显示字符“ b”和字符“ c”。
任务要求2: 编写一段程序,使用系统调用 fork()创建一个子进程。子进程通过系统调用 exec更换自己原有的执行代码, 转去执行 Linux 命令/bin/ls (显示当前目录的列表),然后调用 exit()函数结束。父进程则调用 waitpid()等待子进程结束,并在子进程结束后显示子进程的标识符,然后正常结束。
3、 详细设计
(1) 进程的创建
结果显示为bc ac

(2)子进程执行新任务
因为我新建的文档在桌面上,因此输出的结果显示了桌面上bin目录下的所有文件。当fork()函数返回值为0时,子程序可以通过调用exec()函数去执行要求的代码。

4、 实验小结与心得
fork()函数用来创建新进程,如成功调用一次则返回两个值,子进程返回0,父进程返回子进程ID,否则,出错返回-1。Linux系统还是用的不太惯,不过,通过这次使用感觉还挺不错的,很方便,什么都能在终端实现,之前在自己电脑上安装了kali Linux,可能是电脑真的垃圾,就很慢,使用体验极差。
实验三、互斥与同步
1、实验目的
(1) 回顾操作系统进程、线程的有关概念,加深对 Windows 线程的理解。
(2) 了解互斥体对象,利用互斥与同步操作编写生产者-消费者问题的并发程序,加深对 P (即 semWait)、V(即 semSignal)原语以及利用 P、V 原语进行进程间同步与互斥操作的理解。
2、总体设计
详见《操作系统课程设计参考文档》
3、详细设计
(1)生产者消费者问题
步骤 1: 创建一个“Win32 Consol Application”工程,然后拷贝清单 3-1 中的程序,编译成可执行
文件。
步骤 2:运行程序如图

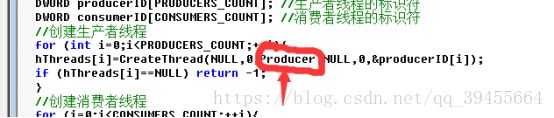
步骤 3:仔细阅读源程序,找出创建线程的 WINDOWS API 函数,回答下列问题:线程的第一个执行函数是什么(从哪里开始执行)?它位于创建线程的 API 函数的第几个参数中?
答:第一个执行的函数是producer函数,在创建线程的第三个参数里面。
步骤四:修改消费者生产者数量,使得消费者数量大于生产者数量

结论:生产速度快,生产者经常等待消费者,反之,消费者经常等待生产者。
步骤五:修改信号量 EmptySemaphore 的初始化方法

结果无法执行该程序。
步骤六:回答问题
1) CreateMutex 中有几个参数,各代表什么含义。
答:有三个参数。
LPSECURITY_ATTRIBUTES IpMutexAttributes代表安全属性的指针
BOOL bInitialOwner 代表布尔bInitialOwner
LPCTSTR IpName代表LPCTSTR类型IpName
2) CreateSemaphore 中有几个参数, 各代表什么含义,信号量的初值在第几个参数中。
答:有四个参数。
1、 表示采用不允许继承的默认描述符
2、 表示信号机的初始计数
3、 设置信号机的最大计数
4、 指定信号机对象的名称
3)程序中 P、 V 原语所对应的实际 Windows API 函数是什么,写出这几条语句。
WaitForSingleObject(EmptySemaphore,INFINITE); p操作
WaitForSingleObject(Mutex,INFINITE);
ReleaseMutex(Mutex); V操作
ReleaseSemaphore(FullSemaphore,1,NULL);
4)CreateMutex 能用 CreateSemaphore 替代吗?尝试修改程序 3-1,将信号量 Mutex 完全用CreateSemaphore 及相关函数实现。写出要修改的语句。
可以,把信号量变成二元信号量就相当于互斥体。
Mutex=CreateSemaphore(NULL,false,false,NULL);
(2) 读者写者问题(选做)
根据实验( 1)中所熟悉的 P、 V 原语对应的实际 Windows API 函数,并参考教材中读者、写者问题的算法原理,尝试利用 Windows API 函数实现第一类读者写者问题(读者优先)。
分析:
除非有写者在写文件,否则没有一个读者需要等待。
当有读者到:
1、 无读者、写者,新读者可以读。
2、 有写者等,但有其他读者正在读,则新读者也可以读。
3、 有写者写,新读者等
写者到:
1、 无读者,新写者可以写。
2、 有读者,新写者等待。
3、 有其他写者,新写者等待

4、实验分析与结论
二元信号量可以充当互斥体,可以利用互斥实现同步的操作,通过对生产者,消费者问题以及对读者和写者问题的分析,更加深了对p,v操作的了解。
5、实验心得与体会
P,V操作总是成对出现时,实现的就是互斥的功能。 Windows API里面可以用两个方法实现同步互斥,一个是CreateMutex创建互斥信号,另外一个是CreateSemaphore创建一般信号量。这两者具体的差别暂时还是一头雾水,不过做完这个实验倒是慢慢有点懂了读写问题,生产者消费者问题。
实验四、银行家算法的模拟与实现
1、
(1) 进一步了解进程的并发执行。
(2) 加强对进程死锁的理解,理解安全状态与不安全状态的概念。
(3) 掌握使用银行家算法避免死锁问题。
2、总体设计
(1) 基本概念:
死锁:多个进程在执行过程中,因为竞争资源会造成相互等待的局面。如果没有外力作用,这些进程将永远无法向前推进。此时称系统处于死锁状态或者系统产生了死锁。
安全序列:系统按某种顺序并发进程,并使它们都能达到获得最大资源而顺序完成的序列为安全序列。
安全状态:能找到安全序列的状态称为安全状态,安全状态不会导致死锁。
不安全状态:在当前状态下不存在安全序列,则系统处于不安全状态。
(2) 银行家算法
银行家算法顾名思义是来源于银行的借贷业务,一定数量的本金要满足多个客户的借贷周转,为了防止银行家资金无法周转而倒闭,对每一笔贷款,必须考察其是否能限期归还。
在操作系统中研究资源分配策略时也有类似问题,系统中有限的资源要供多个进程使用,必须保证得到的资源的进程能在有限的时间内归还资源,以供其它进程使用资源。如果资源分配不当,就会发生进程循环等待资源,则进程都无法继续执行下去的死锁现象。
当一进程提出资源申请时,银行家算法执行下列步骤以决定是否向其分配资源:
1)检查该进程所需要的资源是否已超过它所宣布的最大值。
2)检查系统当前是否有足够资源满足该进程的请求。
3)系统试探着将资源分配给该进程,得到一个新状态。
4)执行安全性算法,若该新状态是安全的,则分配完成;若新状态是不安全的,则恢复原状态,阻塞该进程
3、详细设计
(1) 银行家算法流程图:
对流程图的解释:
输入请求资源数时,先对所请求的资源数要分别与进程的需求量和剩余可用资源数进行对比REQUEST[i]<=NEED[i] REQUEST[i]<=AVAILABLE[i] 都是必须成立的,如果这些都成立了,则可以先根据REQUEST[i]更新对应的AVAILABLE[i]、ALOCATION[i]、NEED[i] ,判断是否存在安全序列,如果存在则分配请求会得到响应,如果不存在则会报错,并将刚刚更新的数组进行回滚,还原。
(2)判断是否存在安全序列算法流程图:
对安全性检测流程图的解释:
在Safe()这个函数里面,定义工作数组Work[],主要是用来进行在系统分配给某个进程资源之后,利用它进行资源释放,使得系统中拥有更多剩余可用资源数。另外布尔值数组FINISHI[] 是用来判断系统是否有足够的资源可以分配,当它的值为true时,就说明有足够资源可分配,出现false则说明没有安全序列。如果全为true,则输出安全序列。
(3)银行家算法的实现:
#include
#define MAXPROCESS 50 /*最大进程数*/
#define MAXRESOURCE 100 /*最大资源数*/
#define bool char
#define true 1
#define false 0
int AVAILABLE[MAXRESOURCE]; /*可用资源数组*/
int MAX[MAXPROCESS][MAXRESOURCE]; /*最大需求矩阵是分配之前需要的*/
int ALLOCATION[MAXPROCESS][MAXRESOURCE]; /*分配矩阵*/
int NEED[MAXPROCESS][MAXRESOURCE]; /*需求矩阵是分配之后还需要的*/
int REQUEST[MAXPROCESS][MAXRESOURCE]; /*进程需要资源数*/
bool FINISH[MAXPROCESS]; /*系统是否有足够的资源分配*/
int p[MAXPROCESS]; /*记录序列*/
int m,n; /*m个进程,n个资源*/
void Init();
bool Safe();
void Bank();
int main()
{
Init();
Safe();
Bank();
}
void Init() /*初始化算法*/
{
int i,j;
printf("\n\t************************银行家算法**************************\n");
printf("\n请输入进程数:");
scanf("%d",&m);
printf("请输入资源种类:");
scanf("%d",&n);
printf("请输入每个进程对每种资源的需求量:\n");
for(i=0;iNEED[x][i])
{
printf("您输入的请求超过资源需求量!请重新输入!\n");
continue;
}
if(REQUEST[x][i]>AVAILABLE[i])
{
printf("您输入的请求超过当前可用资源数!请重新输入!\n");
continue;
}
}
for(i=0;iWork[j])
{
break;
}
}
if(j==n)
{
FINISH[i]=true;//某进程得到资源并完成了工作
for(k=0;k");
}
}
printf("\n");
return true;
}
}
printf("系统是不安全的\n");
return false;
}
2、 实验结论与心得
银行家算法又称为死锁避免策略,在网上参考了一下代码,整体上对银行家算法的分成几个板块,有了比较全面的了解,不过,有一些地方还存在着疑问。虽然能明白意思但是可能是代码能力不行,就会觉得自己很难想到那一层去,自己敲的时候很容易丢失一些判断条件,导致对死锁避免的判断不准确。
实验五、内存管理
1、 实验目的
(1) 通过对 Windows xp/7“任务管理器”、“计算机管理”、“我的电脑”属性、“系统信息”、“系统监视器”等程序的应用,学习如何察看和调整 Windows 的内存性能,加深对操作系统内存管理、虚拟存储管理等理论知识的理解。
(2) 了解 Windows xp/7 的内存结构和虚拟内存的管理,理解进程的虚拟内存空间和物理内存的映射关系。
2、 详细设计
步骤 1:
1) 什么是“分页过程”?
将信息从主内存移动到磁盘进行临时存储的过程
2) 什么是“内存共享”?
内存共享是为了实现应用程序彼此间的通信和共享信息,减少应用程序使用的内存数量,允许访问某些内存空间而不危及它和其他应用程序的安全性和完整性。
3) 什么是“未分页合并内存”和“分页合并内存”?
未分页合并内存:包含必须驻留在内存中的占用代码和数据。
分页合并内存:存储迟早需要的可分页代码或数据的内存部分。
4) Windows xp 中,未分页合并内存的最大限制是多少?
在Windows xp中将未分页合并内存限制为256MB
5) Windows xp 分页文件默认设置的最小容量和最大容量是多少?
Windows x 使用内存数量的 1.5 倍作为分页文件的最小容量,这个最小容量的两倍作为最大容量。
步骤 2:登录进入 Windows 7。
步骤 3:查看包含多个实例的应用程序的内存需求。
1) 启动想要监视的应用程序,例如 Word。
2) 右键单击任务栏以启动“任务管理器”。
3) 在“ Windows 任务管理器”对话框中选定“进程”选项卡。
4) 向下滚动在系统上运行的进程列表,查找想要监视的应用程序。
表 5-3 实验记录
| 映像名称 |
PID |
CPU |
CPU 时间 |
内存使用 |
| WINWORD.EXE |
6096 |
00 |
0:00:24 |
45472KB
|
| TIM.EXE *32 |
4492 |
00 |
0:00:05 |
662KB |
“内存使用”列显示了该应用程序的一个实例正在使用的内存数量。
5) 启动应用程序的另一个实例并观察它的内存需求。 请描述使用第二个实例占用的内存与使用第一个实例时的内存对比情况。
WINWORD.EXE 内存需求比 TIM.EXE *32内存需求大。
步骤 4:未分页合并内存。 估算未分页合并内存大小的最简单方法是使用“任务管理器”。未分页合并内存的估计值显示
在“任务管理器”的“性能”选项卡的“核心内存”部分。
总数 (K) : 425984K 分页数: 315392K
未分页 (K) : 110592K 还可以使用“任务管理器”查看一个独立进程正在使用的未分页合并内存数量和分页合并内存
数量。操作步骤如下:
1)单击“Windows 任务管理器”的“进程”选项卡,然后从“查看”菜单中选择“选择列” 命令,显示“进程”选项卡的可查看选项。
2)在“选择列”对话框中,选定“页面缓冲池”选项和“非页面缓冲池”选项旁边的复选框, 然后单击“确定”按钮。
返回 Windows 7“任务管理器”的“进程”选项卡时,将看到其中增加显示了各个进程占用 的分页合并内存数量和未分页合并内存数量。
仍以刚才打开观察的应用程序 (例如 Word) 为例,请在表 5-4 中记录:
表 5-4 实验记录
| 映像名称 |
PID |
内存使用 |
页面缓冲池 |
非页面缓冲池 |
| WINWORD.EXE |
6096 |
45,544K |
896K |
99K |
从性能的角度来看,未分页合并内存越多,可以加载到这个空间的数据就越多。拥有的物理内 存越多,未分页合并内存就越多。但未分页合并内存被限制为 256MB,因此添加超出这个限制的内 存对未分页合并内存没有影响。
步骤 5:提高分页性能。
在 Windows 7 的安装过程中,将使用连续的磁盘空间自动创建分页文件(pagefile.sys) 。用户可以事先监视变化的内存需求并正确配置分页文件,使得当系统必须借助于分页时的性能达到最高。
虽然分页文件一般都放在系统分区的根目录下面,但这并不总是该文件的最佳位置。要想从分 页获得最佳性能,应该首先检查系统的磁盘子系统的配置,以了解它是否有多个物理硬盘驱动器。
1) 在“开始”菜单中单击“设置” – “控制面板”命令,双击“管理工具”图标,双击“计算机管理”图标。
2) 在“计算机管理”窗口的左格选择“磁盘管理”管理单元来查看系统的磁盘配置。
请在表 5-5 中记录:
表 5-5 实验记录
| 卷 |
布局 |
类型 |
文件系统 |
容量 |
状态 |
| C: |
简单 |
基本 |
NTFS |
40.58GB |
状态良好(启动,故障转储,主分区) |
| D: |
简单 |
基本 |
NTFS |
10.00GB |
状态良好(主分区) |
| E: |
简单 |
基本 |
NTFS |
10.00GB |
状态良好(主分区) |
| F: |
简单 |
基本 |
NTFS |
98.29GB |
状态良好(页面文件,主分区) |
如果系统只有一个硬盘,那么建议应该尽可能为系统配置额外的驱动器。这是因为:Windows 7 最多可以支持在多个驱动器上分布的 16 个独立的分页文件。为系统配置多个分页文件可以实现 对不同磁盘 I/O 请求的并行处理,这将大大提高 I/O 请求的分页文件性能。
步骤 6:计算分页文件的大小。 要想更改分页文件的位置或大小配置参数,可按以下步骤进行:
1) 右键单击桌面上的“我的电脑”(Win7 为计算机)图标并选定“属性”(Win7 为高级系统设置)。
2) 在“高级”选项卡上单击“性能选项”按钮。
3) 单击对话框中的“虚拟内存”区域的“更改”按钮。
请记录:
所选驱动器(C:)的页面大小:
驱动器: C: 可用空间: 22276MB
初始大小: 最大值:
所选驱动器(D:)的页面大小:
驱动器: D: 可用空间: 10196MB
初始大小: 最大值:
所选驱动器页面大小总数:
允许的最小值: 16MB 推荐: 12081 MB
当前已分配: 8192MB
4) 要想将另一个分页文件添加到现有配置,在“虚拟内存”对话框中选定一个还没有分页文件 的驱动器,然后指定分页文件的初始值和最大值 (以兆字节表示) ,单击“设置”,然后单击“确定”。
5) 要想更改现有分页文件的最大值和最小值,可选定分页文件所在的驱动器。然后指定分页文件的初始值和最大值,单击“设置”按钮,然后单击“确定”按钮。
6) 在“性能选项”对话框中单击“确定”按钮。
7) 单击“确定”按钮以关闭“系统特性”对话框。
(2)了解和检测进程的虚拟内存空间。
步骤 1:创建一个“Win32 Consol Application”工程,然后拷贝清单 5-1 中的程序,编译成 可执行文件。
步骤 2:在 VC 的工具栏单击“Execute Program”(执行程序) 按钮,或者按 Ctrl + F5 键,或者 在“命令提示符”窗口运行步骤 1 中生成的可执行文件。
步骤 3:根据运行结果,回答下列问题
虚拟内存每页容量为: 4.00KB 最小应用地址: 0x00010000
最大应用地址: 0x7ffeffff
当前可供应用程序使用的内存空间为: 1.99GB
当前计算机的实际内存大小为: 8.00GB
理论上每个 Windows 应用程序可以独占的最大存储空间是: 4.00GB
按 committed、reserved、free 等三种虚拟地址空间分别记录实验数据。其中“描述”是指对该 组数据的简单描述,例如,对下列一组数据:
00010000 – 00012000 <8.00KB> Committed, READWRITE, Private
可描述为:具有 READWRITE 权限的已调配私有内存区。
将系统当前的自由区 (free) 虚拟地址空间按表 5-6 格式记录。
表 5-6 实验记录
| 地址 |
大小 |
虚拟地址 空间类型 |
访问权限 |
描述 |
| 00031000-00040000 |
<60.0KB> |
free |
NOACCESS |
没有任何权限的自由区 |
| 00041000-00050000 |
<60.0KB> |
free |
NOACCESS |
没有任何权限的自由区 |
将系统当前的已调配区 (committed) 虚拟地址空间按表 5-7 格式记录。
表 5-7 实验记录
| 地址 |
大小 |
虚拟地址 空间类型 |
访问权限 |
描述 |
| 0019000-00194000 |
<16.0KB> |
committed |
READONLY |
具有READONLY权限的已调配私有内存区 |
| 00220000-00221000 |
<4.00KB> |
committed |
READWRITE |
具有READWRITE权限的已调配私有内存区 |
将系统当前的保留区 (reserved) 虚拟地址空间按表 5-8 格式记录。
表 5-8 实验记录
| 地址 |
大小 |
虚拟地址 空间类型 |
访问权限 |
描述 |
| 7f0e0000-7ffe0000 |
<15.0KB> |
reserved |
READONLY |
具有READONLY权限的保留区
|
| 7ffe1000-7fff0000 |
<60.0KB> |
reserved |
NOACCESS |
没有任何权限的保留区 |
3、 实验结论
简单描述Windows进程的虚拟内存管理方案:
通过对文件的操作权限,有只读,读写,不允许访问等和不同调度方式实现对虚拟内存的管理
4、实验心得:
懵懵懂懂跟着步骤做完这些操作,了解了分页合并内存、未分页合并内存的区别以及查询虚拟内存的页容量,最大最小应用地址等等。感觉还是比较神奇吧,以前确实很少接触,关于计算机操作系统的知识和操作都应该熟记于心。
实验六、磁盘调度
1、实验目的
(1)了解磁盘结构以及磁盘上数据的组织方式。
(2)掌握磁盘访问时间的计算方式。
(3)掌握常用磁盘调度算法及其相关特性。
2、总体设计
(1)磁盘数据的组织
磁盘上每一条物理记录都有唯一的地址,该地址包括三个部分:磁头号(盘面号)、柱面号(磁道号)和扇区号。给定这三个量就可以唯一地确定一个地址。
(2)磁盘访问时间的计算方式
磁盘在工作时以恒定的速率旋转。 为保证读或写,磁头必须移动到所要求的磁道上,当所要求的扇区的开始位置旋转到磁头下时,开始读或写数据。 对磁盘的访问时间包括:寻道时间、旋转延迟时间和传输时间。
(3)磁盘调度算法
磁盘调度的目的是要尽可能降低磁盘的寻道时间,以提高磁盘 I/O 系统的性能。
先进先出算法: 按访问请求到达的先后次序进行调度。
最短服务时间优先算法:优先选择使磁头臂从当前位置开始移动最少的磁盘 I/O 请求进行调度。
SCAN(电梯算法): 要求磁头臂先沿一个方向移动,并在途中满足所有未完成的请求,直到它到达这个方向上的,最后一个磁道,或者在这个方向上没有别的请求为止, 后一种改进有时候称作LOOK
C-SCAN(循环扫描) 算法: 在磁盘调度时, 把扫描限定在一个方向,当沿某个方向访问到最后一个磁道时,磁头臂返回到磁盘的另一端,并再次开始扫描。
3、详细设计
(1) SCAN 算法:
根据对SCAN算法的概念的理解,此时磁盘调度情况可以分成两种:(我的例子为:12,50,90,100,120 起始磁道号为:54)
①先增后减 则输出结果应为:54,90,100,120,50,12
②先减后增 则输出结果应为:54,50,12,90,100,120
先将输入进来的磁道号进行由小到大的排序,再依次进行比较和排序,并计算横跨的磁道数,算出平均寻道时间。
(2)C_SCAN算法 :
分析可知C_SCAN算法也可以分成两种情况
①增大 输出结果为:54,90,100,120,12,50
②减小 输出结果为:54,50,12,120,100,90
由SCAN算法稍加改动则可得到
4、实验小结和心得
我认为SCAN和C_SCAN算法代码写起来都比较简单,自己也通过在写代码时再次回忆和加深了对四种扫描算法的理解。不过要把程序写出来一定要先对SCAN算法和CSCAN算法理解清楚,才能正确的写出来,而且要多用几组数字进行测验,不然很容易出现平均寻道时间相同的状况。
完整代码如下:
#include"stdio.h"
#include"stdlib.h"
#define maxsize 1000 //定义最大数组域
//先进先出调度算法
void FIFO(int array[],int m)
{
int sum=0,j,i,now;
float avg;
printf("\n请输入当前的磁道号: ");
scanf("%d",&now);
printf("\n FIFO 调度结果: ");
printf("%d ",now);
for(i=0; iarray[j])//两磁道号之间比较
{
temp=array[i];
array[i]=array[j];
array[j]=temp;
}
}
}
for( i=0; i=0; i--) //将数组磁道号从大到小输出
printf("%d ",array[i]);
sum=now-array[0];//计算移动距离
}
else if(array[0]>=now)//判断整个数组里的数是否都大于当前磁道号
{
for(i=0; i=0)&&(r=0; j--)
{
printf("%d ",array[j]);
}
sum+=array[m-1]-array[0];//计算移动距离
}
}
avg=(float)sum/m;
printf("\n 移动的总道数: %d \n",sum);
printf(" 平均寻道长度: %f \n",avg);
}
void SCAN(int array[],int m)
{
int temp,x;
int now;
int i,j,sum=0,sum1=0;
float avg;
for(i=0; iarray[j])//两磁道号之间比较
{
temp=array[i];
array[i]=array[j];
array[j]=temp;
}
}
}
printf("\n输出排序后的磁道号数组:\n");
for( i=0; i=0; i--) //将数组磁道号从大到小输出
printf("%d ",array[i]);
sum=now-array[0];//计算移动距离
}
else if(array[m-1]>now&&array[0]=0; i--)
{
if(now>=array[i])
{
printf("%d ",array[i]);
sum1=now-array[0];
}
}
for(i=0; i=now)//判断整个数组里的数是否都大于当前磁道号
{
for(i=0; i<=m-1; i++)
printf("%d ",array[i]);
sum=array[m-1]-now;//计算移动距离
}
else if(array[m-1]>now&&array[0]=0; i--)
{
if(now>=array[i])
{
printf("%d ",array[i]);
sum=sum1+(array[m-1]-array[0]);
}
}
}
}
avg=(float)sum/m;
printf("\n 移动的总道数: %d \n",sum);
printf(" 平均寻道长度: %f \n",avg);
}
void CSCAN(int array[],int m)
{
int temp,x,k;
int now;
int i,j,sum=0,sum1=0;
float avg;
for(i=0; iarray[j])//两磁道号之间比较
{
temp=array[i];
array[i]=array[j];
array[j]=temp;
}
}
}
printf("\n输出排序后的磁道号数组:\n");
for( i=0; i=0; i--) //将数组磁道号从大到小输出
printf("%d ",array[i]);
sum=now-array[0];//计算移动距离
}
else if(array[m-1]>now&&array[0]=0; i--)
{
if(now>=array[i])
{
k=i;
break;
// printf("%d ",array[i]);
//sum1=now-array[0];
}
}
for(i=m-1; i>=0; i--)
{
if(now>=array[i])
{
printf("%d ",array[i]);
sum1=now-array[0];
}
}
for(i=m-1; i>=0; i--)
{
if(now<=array[i])
{
printf("%d ",array[i]);
sum=sum1+(array[m-1]-array[0])+(array[m-1]-array[k+1]);
}
}
}
}
else if(x==2)
{
printf("\nCSCAN 调度结果: ");
if(array[0]>=now)//判断整个数组里的数是否都大于当前磁道号
{
for(i=0; i<=m-1; i++)
printf("%d ",array[i]);
sum=array[m-1]-now;//计算移动距离
}
else if(array[m-1]>now&&array[0]=array[i])
{
printf("%d ",array[i]);
sum=sum1+(array[m-1]-array[0])+(array[k-1]-array[0]);
}
}
}
}
avg=(float)sum/m;
printf("\n 移动的总道数: %d \n",sum);
printf(" 平均寻道长度: %f \n",avg);
}
// 操作界面
int main()
{
int c;
int count;
//int m=0;
int cidao[maxsize];//定义磁道号数组
int i=0;
int b;
printf("\n --------------------------------------------------\n");
printf(" *****************磁盘调度算法模拟******************");
printf("\n --------------------------------------------------\n");
printf("请先输入磁道数量: \n");
scanf("%d",&b);
printf("请先输入磁道序列: \n");
for(i=0; i5)
break;
switch(c)//算法选择
{
case 1:
FIFO(cidao,count);//先进先出算法
printf("\n");
break;
case 2:
SSTF(cidao,count);//最短服务时间优先算法
printf("\n");
break;
case 3:
SCAN(cidao,count);//扫描算法,待补充!
printf("\n");
break;
case 4:
CSCAN(cidao,count);//循环扫描算法,待补充!
printf("\n");
break;
case 5:
exit(0);
}
}
return 0;
}