初学者复现CornerNet:详细指导零基础在Ubuntu系统运行该代码并完全理解论文思路的教程
本篇博客将从CornerNet的内容介绍开始,详细介绍其代码复现、指出一些常见问题、如何理解代码中的诸多文件夹以及一些常见的改进,CornerNet的学习入门仅此一篇即可——阿波,更新于2020.4.5
快速检索
- 写在前面
- CornerNet简单介绍
- Advantage
- Corner Pooling
- 具体介绍
- 思路来源
- Two-stage目标检测器
- One-stage目标检测器
- 公式分析
- Overview
- Detecting Corners
- Grouping Corners
- Corner Pooling
- 详细介绍代码复现
- 环境和代码
- 数据集的准备
- 程序运行
- 1. 入门
- 2. 编译角池化层
- 3. 编译NMS
- 4.安装MS COCO API
- 5. 下载数据集
- 6. 训练和测试
- 代码内容浅析
- 文件夹介绍
- 代码解析
- Train.py 文件
- config
- Models
- 结束语
写在前面
首先,此篇博客对于研一基础一般的同学最为合适,可以直接开始在自己的系统上运行CornerNet,通过代码的运行了解何为CornerNet。
其次,对于很想深入认真学习的同学,可以先从U-net的复现开始,其复现也很简单,我已将代码调好,注释完善,环境要求都做了备注,可以从该代码的复现深入了解深度学习中的池化和采样过程。U-net代码实现CPU版本
最后,在此博客结尾也会分析一下CornerNet相关的其他算法,作为近期的学习总结。
CornerNet简单介绍
论文链接原文:https://arxiv.org/abs/1808.01244
我先简要介绍一下相关的概念和优缺点,后期结合代码的分析将在后面写出,感兴趣的同学可以看我的更新
CornerNet是一种比较新颖的目标检测方法,使用沙漏网络作为其骨干网络,将之前的anchor boxes(最早出现在Faster R-CNN中)改为检测目标的一对关键点(边界框的左上角和右下角)。
锚框:Anchor box综述 - Jackpop的文章 - 知乎
Advantage
优点:很显然,规避了anchor boxes的一些缺点,比如超参数过多和设计选择问题(尤其是当与多尺度架构相结合时)。同时,CornerNet这种新型的one stage目标检测算法主要使用了热图和角点嵌入向量的概念,通过训练网络以预测他们的类似嵌入。
缺点:非要说的话,该算法作者(普林斯顿大学)自己将自己的记录打破了——提出了CornerNet算法。结合了CornerNet-Saccade和CornerNet-Squeeze,准确度和速度都有非常大的提升。主要改动为:变成了two stage检测器(精度提升)、引进了新的紧凑框架。
CornerNet-Lite算法笔记
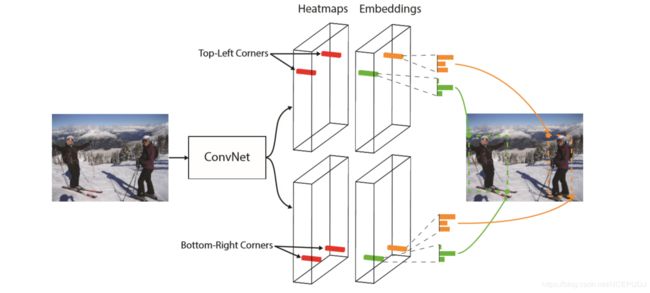 如图像所示,CornerNet将一个目标检测为一对组合在一起的边界框角点。卷积网络输出一个左上角热图和一个右下角热图,并输出每个检测到的角点的嵌入矢量。
如图像所示,CornerNet将一个目标检测为一对组合在一起的边界框角点。卷积网络输出一个左上角热图和一个右下角热图,并输出每个检测到的角点的嵌入矢量。
Corner Pooling
同时,为了配合该算法的独特性,作者提出corner pooling这一新型池化层,可以帮助卷积网络更好的定位边界框的角点。
 为了解决角点不在图像上这一问题,同时也为了更好的激活池化层,我们引入了Corner pooling这一组件:在每个像素位置,它大池化从第一个特征映射到右侧的所有特征向 量,大池化从第二个特征映射下面的所有特征向量,然后将两个池化结果一起添加。
为了解决角点不在图像上这一问题,同时也为了更好的激活池化层,我们引入了Corner pooling这一组件:在每个像素位置,它大池化从第一个特征映射到右侧的所有特征向 量,大池化从第二个特征映射下面的所有特征向量,然后将两个池化结果一起添加。
好处如下:
- 中心点需要四个边和中点,很难把握这个度,而角点只需要取决于两边即可
- 角点本质上说和边界框是没什么区别的,表示起来更加高效
- Corner pooling是该算法的量身定制,非常合适
具体介绍
思路来源
本文是第一个将目标检测任务定义为同时检测和分组角点的任务。我们的另一个 新颖之处在于corner pooling layer,它有助于更好定位角点。我们还对沙漏结构进行了显著地修改,并添加了新的focal loss的变体,以帮助更好地训练网络。
Two-stage目标检测器
- R-NN首次推出two-stage目标检测器,并通过网络对每个区域进行分类。使用了低层次的视觉算法生成ROIs,由CovNet独立处理,造成了大量计算冗余。
- SPP-Net和Fast R-CNN,设计了一个特殊的池化层(金字塔池化),将每个区域从feature map中池化。然而,两者仍然依赖于单独的proposals算法,不能进行端到端训练。
- Faster-RCNN 通过引入区域生成网络(RPN)来去除低层次的proposals算法,RPN从一组预先确定的候选框(通常称为anchor boxes)中生成proposals。
- DeNet是一种two-stage检测器,不使用anchor boxes就能生成RoIs。它首先确定每个位置属于边界框的左上角、右上角、左下角或右下角的可能性。
One-stage目标检测器
- YOLO直接从图像中预测边界框坐标,后来在 YOLO9000中,通过使用anchor boxes进行了改进。
- DSSD和RON采用了类似沙漏的网络[28],使它们能够通过跳跃连接将低级和高级特性结合起来, 从而更准确地预测边界框。
- 在RetinaNet出现之前,这些one-stage检测器的检测精度仍然落后于two-stage检测器。在RetinaNet中,提出了一种新的loss,Focal Loss, 来动态调整每个anchor boxes的权重,并说明了他们的one-stage检测器检测性能优于two-stage检测器。
公式分析
这三个我准备结合代码来进一步分析,这里就先不赘述了,网上相关博客也很多,我罗列出来一方面是提醒自己后面深入学习时候记得补充完善,另一方面也是给读者一个提示,这一块的数学推到也很重要。
Overview
在CornerNet中,我们将物体边界框检测为一对关键点(即边界框的左上角和右下角)。卷积网络通过预测两组热图来表示不同物体类别的角的位置,一组用于左上角,另一组用于右下角。 网络还预测每个检测到的角的嵌入向量[27],使得来自同一目标的两个角的嵌入之间的距离很小。 为了产生更紧密的边界框,网络还预 测偏移以稍微调整角的位置。 通过预测的热图,嵌入和偏移,我们应用一个简单的后处理算法来获得终的边界框。
我们使用沙漏网络作为CornerNet的骨干网络。 沙漏网络之后是两个预测模块。 一个模块用于左上角,而另一个模块用于右下 角。 每个模块都有自己的corner pooling模块,在预测热图、嵌入和偏移之前,池化来自沙漏网络的特征。 与许多其他物体探测器不同,我们不使用不同尺度的特 征来检测不同大小的物体。 我们只将两个模块应用于沙漏网络的输出。

骨干网络之后是两个预测模块,一个用于左上角,另一个用于右下角。 使用两个模块的预测,我们定位并分组边界框的角。
Detecting Corners
我们预测两组热图,一组用于左上角,另一组用于右下角。 每组热图具有C个通道,其中C是分类的数量,并且大小为H×W。 没有背景通道。 每个通道都是一个二进制掩码,用于表示该类的角点位置。
对于每个角点,有一个ground-truth正位置,其他所有的位置都是负值。 在训练期间,我们没有同等地惩罚负位置,而是减少对正位置半径内的负位置给予的惩罚。 给定半径,惩罚的减少量由非标准化的2D高斯给出,其中心位于正位置,其 σ 是半径的1/3。

用于训练的“Ground-truth”热图:在正位置半径范围内(橙色圆圈)的方框(绿色虚线矩形)仍然与地ground-truth(红色实心矩形)有很大的重叠。
设pcij为预测热图中c类在位置(i,j)处的得分,并设ycij为用非正规高斯函数增强的“实际真实数据”热图。我们设计了一种局部损失(focus loss)的变体:
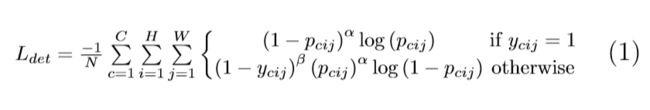
许多网络涉及下采样层以收集全局信息和减少内存使用。 当它们完全卷积应用于图像时,输出的尺寸通常小于图像。当我们将热图中的位置重新映射到输入图像时,可能会丢失一些精度,这会极大地影响小边界框与ground-truth之间的IoU。 为了解决这个问题,我们预测位置偏移,以稍微调整角位置,然后再将它们重新映射到输入分辨率。

其中Ok是偏移量(offset),xk和yk是角k的x和y坐标。特别是,我们预测一组offset由所有类别的左上角共享,另一组由右下角共享。对于训练,我们在地面真相角位置应用平滑L1损失(Girshick,2015):
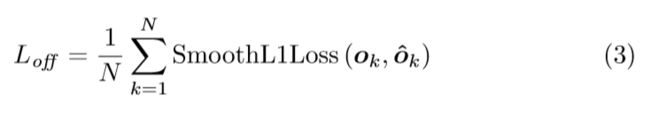
Grouping Corners
图像中可能出现多个目标,因此可能检测到多个左上角和右下角。我们需要确定左上角和右下角的一对角点是否来自同一个目标边界框。我们的方法受到Newell等人提出的用于多人姿态估计任务的关联嵌入方法的启发。Newell等人检测所有人类关节,并为每个检测到的关节生成嵌入。他们根据嵌入之间的距离将节点进行分组。
关联嵌入的思想也适用于我们的任务。 网络预测每个检测到的角点的嵌入向量,使得如果左上角和右下角属于同一个边界框,则它们的嵌入之间的距离应该小。 然后,我们可以根据左上角和右下角嵌入之间的距离对角点进行分组。 嵌入的实际值并不重要。 仅使用嵌入之间的距离来对角点进行分组。
设 etk 为对象k左上角的嵌入,ebk 为右下角的嵌入。与Newell和Deng(2017年)一样,我们使用“拉”损失来训练网络来分组角点,使用“推”损失来分离角点:
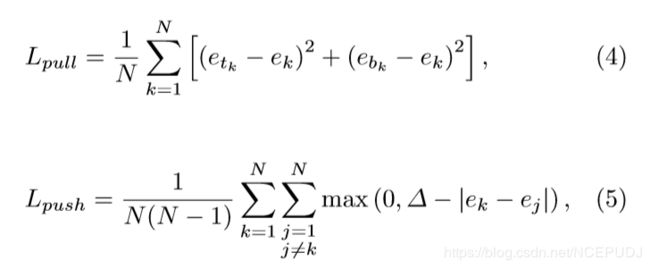
式中,ek 是 etk 和 ebk 的平均值,在所有实验中,我们将Δ设为1。类似于效应损失,我们只在地面真实角位置应用损失。
Corner Pooling
如图2所示,通常没有局部视觉证据表明存在角点。要确定像素是否为左上角,我们需要水平地向右看目标的最上面边界,垂直地向底部看物体的最左边边界。因此,我们提出corner Pooling通过编码显式先验知识来更好地定位角点。
假设我们想确定位置(i,j)处的像素是否是左上角。设ft和fl为左上角池层输入的特征映射,ft i j和flij分别为ft和fl中位置(i,j)处的向量。对于H×W特征映射,角池层first max将ft中(i,j)和(i,H)之间的所有特征向量合并为特征向量tij,max将fl中(i,j)和(W,j)之间的所有特征向量合并为特征向量lij。最后,它把 tij 和 lij 加在一起。这种计算可以用下列方程式表示:
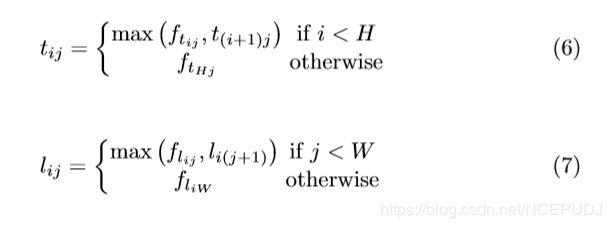
在这里我们应用元素最大运算,动态规划可以有效地计算tij和lij。
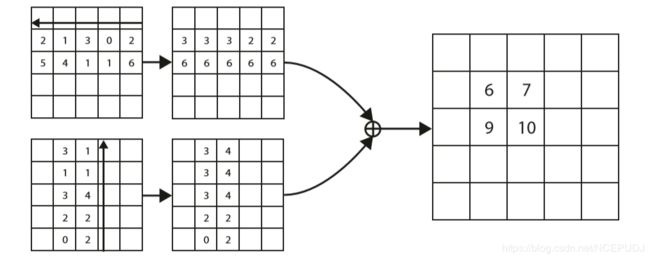 左上角的池层可以非常高效地实现。我们从右到左扫描水平最大池,从下到上扫描垂直最大池。然后我们添加两个最大池特征映射。
左上角的池层可以非常高效地实现。我们从右到左扫描水平最大池,从下到上扫描垂直最大池。然后我们添加两个最大池特征映射。
我们以类似的方式定义了右下角的池层。在添加合并结果之前,它最大化了(0,j)和(i,j)之间的所有特征向量,以及(i,0)和(i,j)之间的所有特征向量。在预测模块中,角池层用于预测热图、嵌入和效果集。
预测模块的架构如图7所示。模块的第一部分是剩余块的修改版本(He等人,2016)。在这个修改后的剩余块中,我们将第一个3×3卷积模块替换为角池模块,角池模块首先用两个3×3卷积模块1(128个通道)处理来自骨干网络的特征,然后应用角池层。在设计剩余块的基础上,将合并后的特征输入到一个3×3conv-BN层中,该层有256个通道,并将投影快捷方式相加。修改后的残差块后面是一个3×3卷积模块,具有256个通道和3个Conv ReLU Conv层,用于生成热图、嵌入和效果集。

预测模块从修改后的残差块开始,在残差块中,我们用角池模块替换第一个卷积模块。修改后的残差块之后是卷积模块。我们有多个分支用于预测热图、嵌入和效果集。
详细介绍代码复现
首先肯定需要配有GPU的Linux系统,这个我就不做太多说明了
环境和代码
- 我介绍下我的机器配置:
内存:16G + 处理器:i7-6700K + 显卡:GTX970 + 操作系统:64位Ubuntu16.04 LTS - 下载作者源码:ConerNet源码
- 安装Pycharm和Anaconda软件:Ubuntu16.04+Pycharm+Anaconda配置
数据集的准备
深度学习里面数据集的准备尤为重要,特别是对于没有自己制作过数据集的同学使用开源代码能有限避免走坑。
从此处下载图像(2014 Train,2014 Val,2017 Test)即可。COCO数据集下载
当然,也可以了解更多相关的介绍,以便后期制作自己的数据集
Dataset之COCO数据集:COCO数据集的简介、下载、使用方法之详细攻略
当然,这些数据集都比较大,而且还是在外网,所以有条件的同学可以从师兄师姐那里寻求一些已经下载好的,或者他们测试用轻量级的数据集。
程序运行
这里本不应该细说,GitHub上面有步骤说明,但是为了方便其他同学和我一样没有尝试过复现代码,我做一个详细的介绍。

下面的操作都在这个Readme里面有文字说明,可以直接用来复制粘贴的
1. 入门
通过Anaconda创建一个可以用来运行我们代码的单独环境,注意这个地方可能出问题,如果有某个包装不上,需要注释掉那个txt文件里面的相应行,自己安装单独的包

这一步中,我的 pytorch-0.4.0 和 torchvision-0.2.1 库文件一直安装不上,加载进度为零
解决方法为:
a. 在晚上人少的时候安装,比如12点运行上述代码,让其自行安装
b. 找出安装不了的库文件名称,注释掉或者删除掉(比如我上面的有三个),再次运行上述代码
然后将未安装的文件,通过搜索其他下载链接下载安装包或者直接迅雷下载上述文件,再进行安装
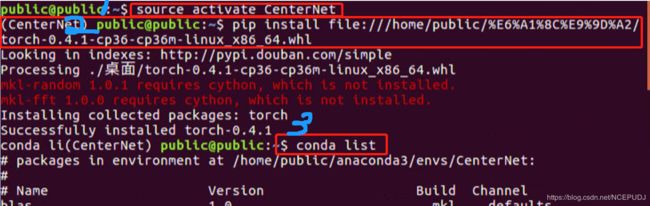
如图,直接下载torch-0.4.1的 whl 文件, 1. 先打开我们的环境 2. 安装下载的库 3. 查看是否安装成功
2. 编译角池化层
编译好环境后,将我们下载的压缩包解压,获得代码文件。再通过一下步骤安装池化层,也就是我们的GPU老大需要这个才能干活

注意哦,我们是在第一步的CornerNet环境中执行上述步骤,但是会出现这个问题:

我们输入 python -m pip install cython 可以解决,如果安装不上,记得sudo pip-apt upgrade和update,这个的意思自行百度,是用来更新Linux系统的库函数下载源的

然后再继续我们的第二步指令即可,结果如下
3. 编译NMS
这一步基本没问题的,直接按照这个操作就行了

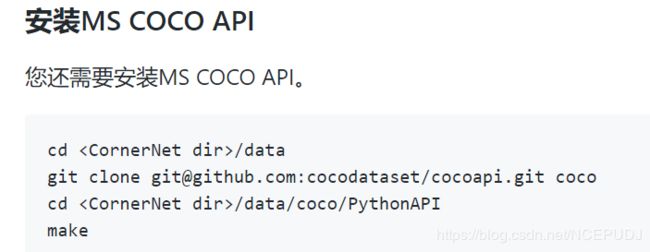
4.安装MS COCO API
这一步,同样很简单,再次提醒,这些文档都在我们下载代码的readme里面,或者GitHub上面就能看到
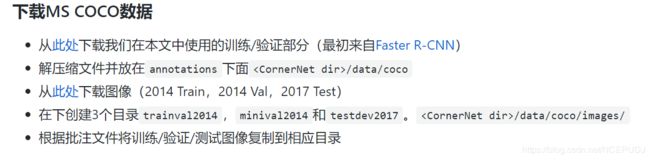
5. 下载数据集
我们的准备部分已经准备了数据集,没有注意可以返回上面的准备步骤,现在要做的是如何放置
而annotation这个最好用迅雷等下载器下载,会快很多annotation下载
需要注意的是,这些都是国外的资源,没点办法还真下不了
但是,我们还有一步需要做,就是改动代码里面的文件路径,特别是我们使用的数据集或者文件路径位置不对,需要改动代码主目录里面的的config文件夹下面的CornerNet.json文件

当然,是在Linux里面改动过,图片仅为示意图,改动的内容为

将这里的路径改为自己所使用的数据集位置,至于改成什么

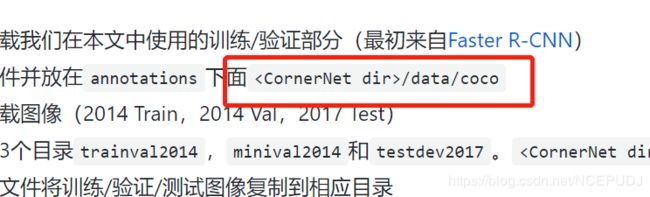
可以看到,变动的内容对应coco这个文件夹即可
6. 训练和测试
运行train为例的话,如下所示:

通过运行该代码即可执行train操作

代码内容浅析
我们先来简单介绍下这些文件夹到底是什么,以及他们到底在我们的程序执行中发挥了什么作用
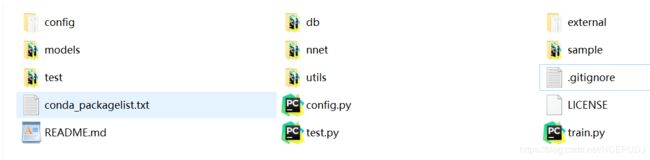
文件夹介绍
如上图所示,我们依次介绍各个文件夹是干嘛的,参考了这篇博客代码运行:CornerNet源码
config:配置文件,Cornernet训练的配置文件由config/CornerNet.json 和 config.py组成,测试加上db/detections.py
db:数据类别、基础参数、读取加载等,运行自己数据集需要修改db/coco.py下的self._cat_ids
external:存放用c写的NMS和soft_NMS算法
models和nnet:网络结构代码,models里面是具体操作,而nnet是网络结构
test:test.py调用coco.py里面的kp_detection方法
utils:工具类
test.py和train.py:测试和训练
代码解析
Train.py 文件
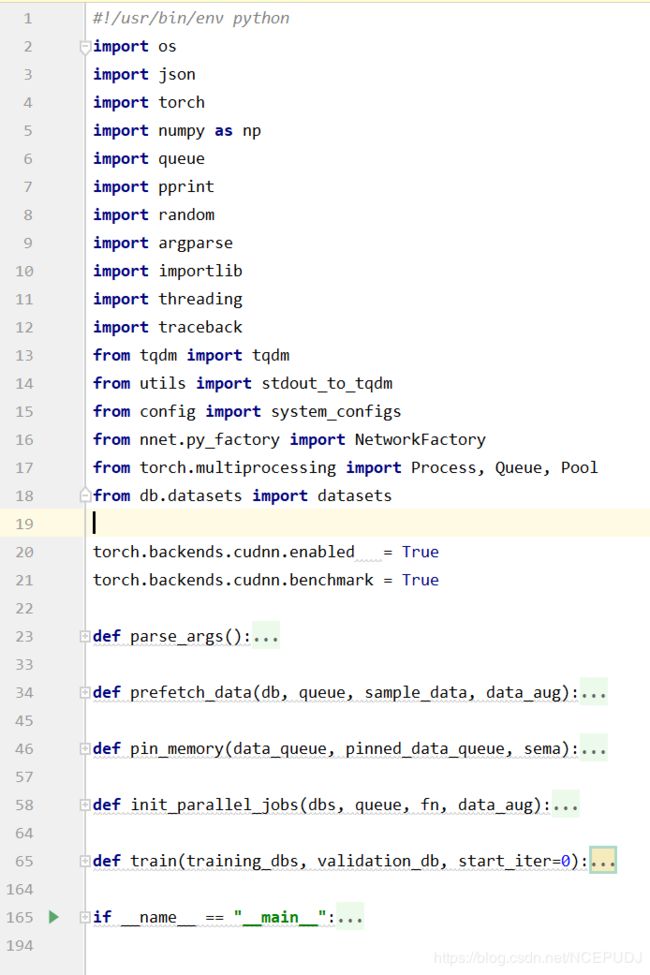 如图所示,我们可以看到,train文件主要分为1. 加载库 2. 定义内部子函数 3. 主函数,简单来说就是,最后一个才是主函数
如图所示,我们可以看到,train文件主要分为1. 加载库 2. 定义内部子函数 3. 主函数,简单来说就是,最后一个才是主函数
Python中if name == ‘main’,__init__和self 的解析
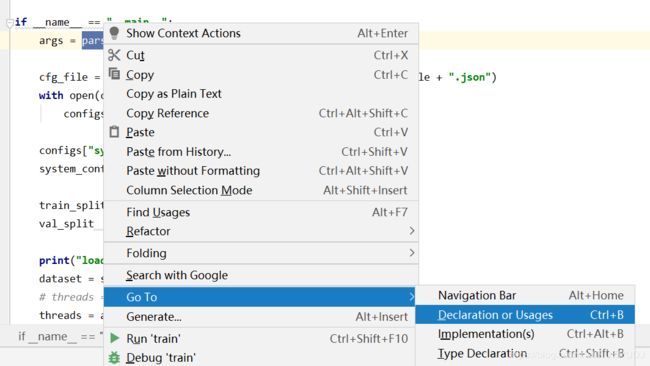
对于某个句子的意思我们可以通过图片上面的go to查看,很显然后,这段代码文件便可以通过这种方式成为一段可以阅读的文本了
config
如果看了train.py 文件可以发现,它引用了很多config文件的参数,对于这些我们提前设定好的固定值参数,我们称之为超参数。

上面可以看到这些参数包括:学习率、步长、引用文件路径等,具体含义我建议自己使用时候再去深究,或者像我一样写个博客,不然很容易遗忘的。
Models

打开这个文件,我们可以通过代码揭开论文里面讲述的一些深奥的池化骚操作到底是什么样子
 对于代码我们可能不完全理解含义,但是,通过观察这些数字,我们也能大概理解一些东西。
对于代码我们可能不完全理解含义,但是,通过观察这些数字,我们也能大概理解一些东西。
比如(3.3)表示论文里面提到的3*3卷积核大小,那个 forward函数 表示前向网络的卷积层操作方式,其中的pool1+pool2也很容易想到论文里面提到的corner pooling池化方式

结束语
个人认为,CornerNet其实算一个偏复杂的代码结构了,对于初学者来说,它有着很多独特的创新思路,只看论文或者只看代码都很难深入理解透彻。不过没有关系,我觉得你能看到这里表示我们都有着共同的兴趣和爱好,一起加油吧。
我已经详细介绍了大部分的入门基础知识,至于其他的代码内容,便不在此赘述了,祝大家学习进步~