机器学习笔记(二十六):支撑向量机(SVM)

凌云时刻 · 技术


导读:这一篇笔记主要讲机器学习算法中一个重要的分类算法,支撑向量机(Support Vector Machine)。它背后有严格的数学理论和统计学理论支撑的,这里我们只对它的原理和应用做以介绍,更深层次的数学理论有兴趣可以查阅其他资料。
作者 | 计缘
来源 | 凌云时刻(微信号:linuxpk)
Soft Margin SVM

在上一节介绍了Hard Margin SVM和Soft Margin SVM,并且在诠释SVM背后最优化问题的数学原理时也是基于Hard Margin SVM前提的。这一节我们来看看Soft Margin SVM。
 Soft Margin SVM概念
Soft Margin SVM概念
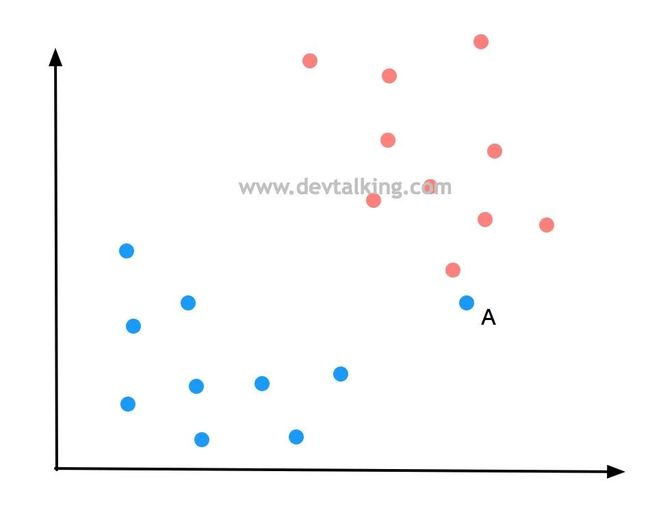
如上图所示,点A是一个蓝色分类的点,但是它离红色分类的点非常近,那么如果按Hard Margin SVM的思路,上图情况的决策边界很有可能是下图所示这样:
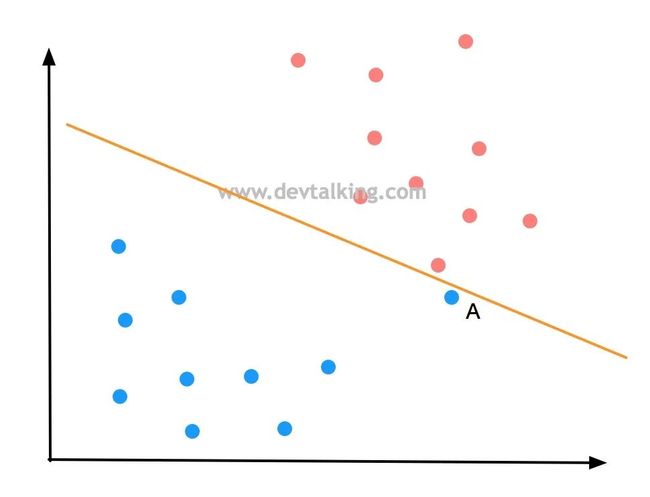
这条决策边界直线看似很好的将蓝色和红色点完全区分开了,但是它的泛化能力是值得怀疑的,因为这条决策边界极大的受到了点A的影响,而点A可能是蓝色点中极为特殊的一个点,也有可能它根本就是一个错误的点。所以根据SVM的思想,比较合理的决策边界应该下图绿色的直线所示:
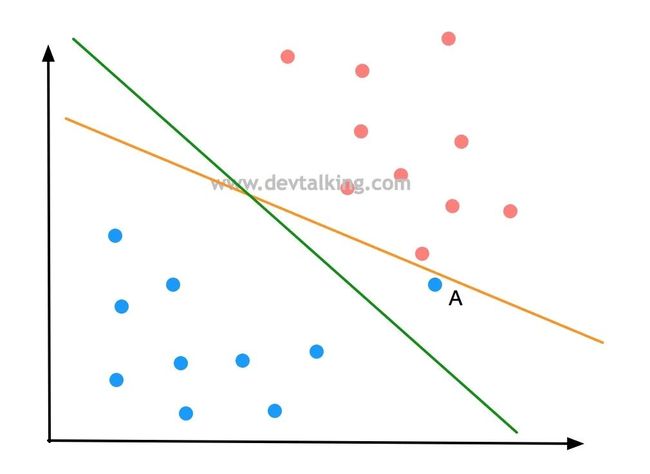
虽然绿色直线的决策边界没有完全将红蓝点分开,但是如果将它放在生产数据中,可能预测准确度更高,也就是泛化能力更强。
再如上图中的情况,已经根本不可能有一条线性决策边界能将红蓝点分开了,所以我们希望决策边界具有一定的包容性或容错性,已降低分类准确度的代价换来更高的泛化能力。那么这种SVM就称为Soft Margin SVM。
Soft Margin SVM原理
在Hard Margin SVM最优化问题的两个函数中,限定条件 表示在Margin区域内不会有任何点出现,但是在Soft Margin SVM中为了容错性,是允许在Margin区域内出现点的,也就是将Hard Margin SVM的限定条件加以宽松量,并且这个宽松量必须是正数:
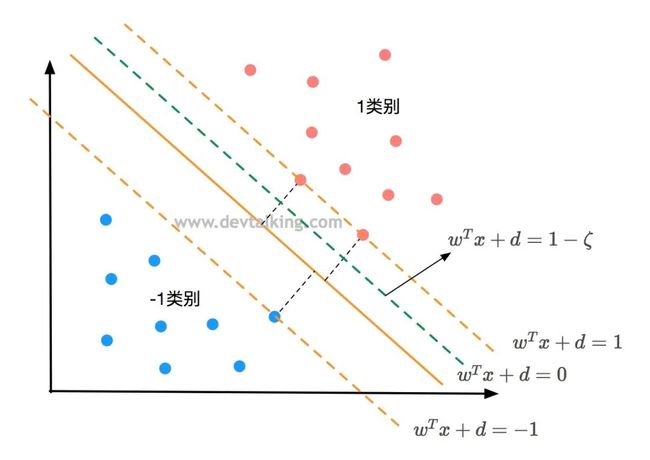
上图中有四条直线,其中橘黄色的三条是在讲Hard Margin SVM中得出的,如果我们将Hard Margin SVM中的限定条件加以宽松量的话,其实Margin的区域就会变小,也就是图中绿色虚线和决策边界构成的区域。而绿色虚线的方程为:
那么Soft Margin SVM的限定条件我们就知道了。
但是现在问题来了,如果当 无穷大时会发生什么情况呢?那就意味着容错性无穷大,也就是可以将所有点都认为是同一类了,故而分不出类别。解决这个问题的思路我们之前已经了解过了,那就是模型正则化。
我们知道Hard Margin SVM的优化目标函数为 ,Soft Margin SVM也是基于Hard Margin SVM的思想演变的,所以我们将这个目标函数加一个正则模型,而这个正则模型又恰是Soft Margin SVM的宽松量,这样就达到了在Hard Margin SVM的思路下,增加宽松量从而实现Soft Margin SVM,所以 Soft Margin SVM的目标函数为:
公式里的 是模型正则化中的一个超参数,取值范围在0到1之间。用来权衡Hard Margin SVM目标函数和Soft Margin SVM宽松量两者之间的比例。如此一来也就限制了 无穷大的问题,因为Soft Margin SVM的目标函数最优化要同时估计两部分,相互制约。
我们在之前的笔记中学习过了 范数及 正则模型。这里的 就是 正则模型,而 正则模型是 。
C∑i=1mζi。
模型正则化的内容请参见 机器学习笔记(十七)、(十八)交叉验证、模型正则化 。
Scikit Learn中的SVM
前面两小节介绍了SVM背后的数学原理,这一节来看看如何使用Scikit Learn中封装的SVM方法。我们还是使用之前使用过很多次的鸢尾花数据:
|
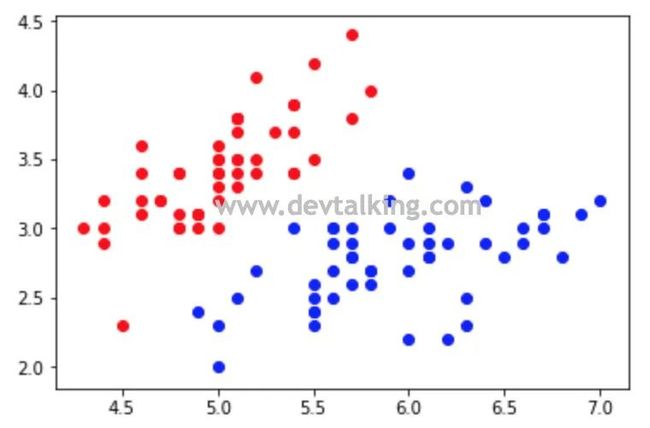
接下来我们使用Scikit Learn封装的SVM方法对样本数据进行分类:
|
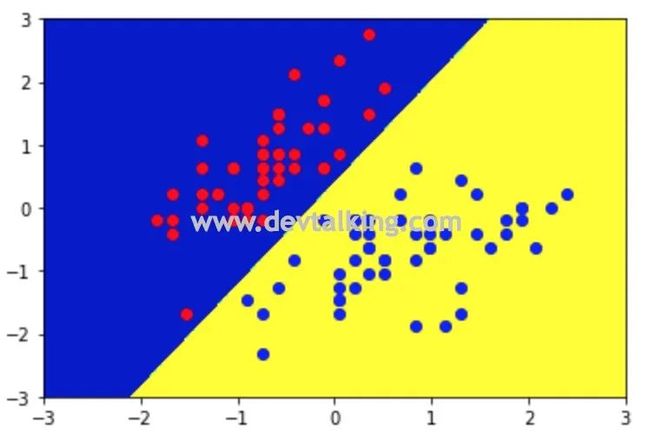
在上面的示例代码中,我将超参数 取了一个非常大的数,那么为了平衡 整个函数, 就得等于0才能让最大限度的平衡正则模型和整个目标函数。所以宽松量为零,就成了Hard Margin SVM。并且从上图可以看出,离决策边界最近的点,无论是红色点还是蓝色点,也就是红蓝支撑向量到决策边界的距离都差不多。
如果我们将超参数C的值取的小一些,那么整个问题就变成了Soft Margin SVM,来对比看看决策边界会有什么不同:
|
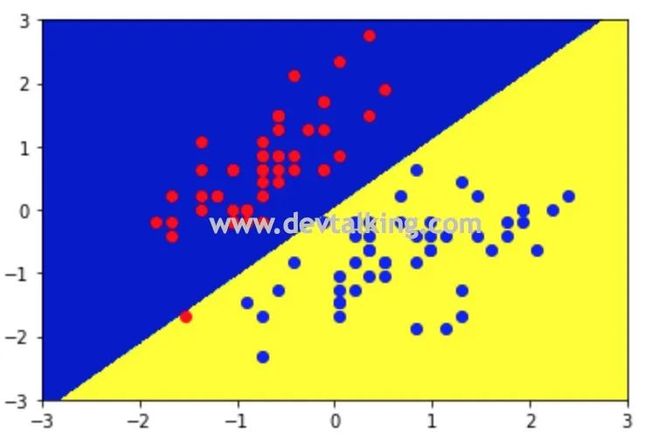
此时从上图可以看到,红蓝支撑向量到决策边界的距离已经不一样了,并且还有一个红色的点被划到蓝色点的范围内,那么我们知道这都是因为Soft Margin SVM中加了宽松量的缘故。
绘制支撑向量直线
在上一小节,我们知道决策边界以及上下支撑向量构成的直线的公式分别是:
决策边界:
上支撑向量直线:
下支撑向量直线:
那么在鸢尾花的示例中,如何来求这三条直线呢?以决策边界直线为例,ww和dd其实我们已经知道了,就是特征系数和截距:
|
因为我们只用了鸢尾花的两个类型和两个特征,所以决策边界直线的公式可以展开为:
将上面的公式转换为 的形式:
同理我们也可以将支撑向量直线的公式作以转换:
此时我们在给定的坐标系内,构建一组,那么就可以求出一组x1x1,然后将这些点连起来,就绘制出了决策边界的直线:
|
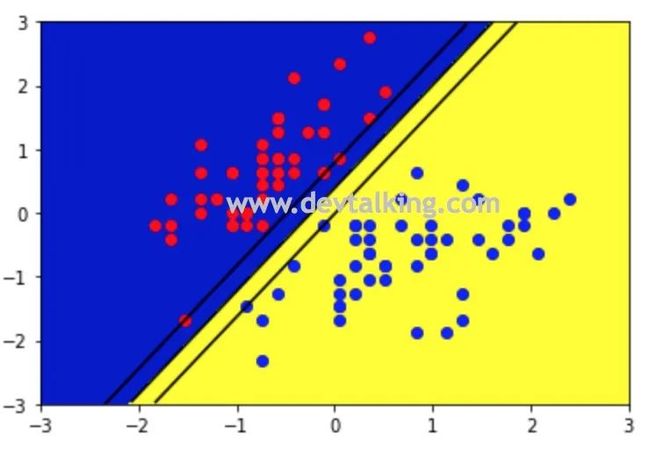
从上图可以看到,是一个标准的Hard Margin SVM,Margin区域没有任何一个点,支撑向量一共有五个,红色点三个,蓝色点两个。
我们再来看看Soft Margin SVM的情况:
|
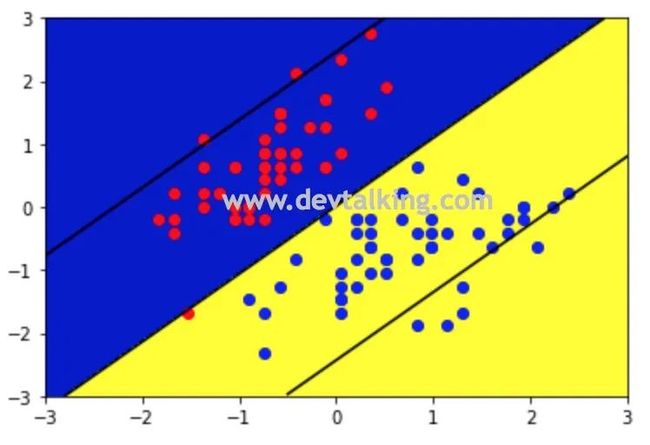
从上图中可以看出,Margin区域内有很多点,说明相比Hard Margin SVM,Soft Margin SVM增加了不少宽松量。
END

往期精彩文章回顾

机器学习笔记(二十五):支撑向量机(SVM)
机器学习笔记(二十四):召回率、混淆矩阵
机器学习笔记(二十三):算法精准率、召回率
机器学习笔记(二十二):逻辑回归中使用模型正则化
机器学习笔记(二十一):决策边界
机器学习笔记(二十):逻辑回归(2)
机器学习笔记(十九):逻辑回归
机器学习笔记(十八):模型正则化
机器学习笔记(十七):交叉验证
机器学习笔记(十六):多项式回归、拟合程度、模型泛化

长按扫描二维码关注凌云时刻
每日收获前沿技术与科技洞见