SQL语句基本操作练习(六)
文章目录
- SQL语句基操(六)
- 一、数据更新
- 1、插入数据(INSERT)
- (1) 插入元组
- [例 3.69] 将一个新学生元组插入到Student表中
- [例 3.70] 将学生张成明的信息插入到Student 表中
- [例 3.71] 插入一条选课记录(‘201215128’,‘1’)
- (2) 插入子查询结果
- [例 3.72] 对每一个系,求学生的平均年龄,并把结果存入数据库
- 2、修改数据(UPDATE)
- (1) 修改某一个元组的值
- [例 3.73] 将学生201215121的年龄改为22岁
- (2) 修改多个元组的值
- [例 3.74] 将所有学生的年龄增加1岁
- (3) 带子查询的修改语句
- [例 3.75] 将计算机科学系全体学生的成绩置零
- 3、删除数据(DELETE)
- (1) 删除某一个元组的值
- [例 3.76] 删除学号为201215128的学生记录
- (2) 删除多个元组的值
- [例 3.77] 删除所有的学生选课记录
- (3) 带子查询的删除语句
- [例 3.78] 删除计算机科学系所有学生的选课记录
- 二、空值的处理
- 1、空值的产生
- [例 3.79] 向SC表中插入一个元组,学生号是”201215126”,课程号是”1”,成绩为空
- [例 3.80] 将Student表中学生号为”201215200”的学生所属的系改为空值
- 2、空值的判断
- [例 3.81] 从Student表中找出漏填了数据的学生信息
- 3、空值的约束条件
- 4、空值的算术运算、比较运算和逻辑运算
- [例 3.82] 找出选修1号课程的不及格的学生
- [例 3.83] 选出选修1号课程的不及格的学生以及缺考的学生
- 三、视图
- 1、定义视图
- (1)建立视图
- [例 3.84] 建立信息系学生的视图
- [例 3.85]建立信息系学生的视图,并要求进行修改和插入操作时仍需保证该视图只有信息系的学生
- [例 3.86] 建立信息系选修了1号课程的学生的视图(包括学号、姓名、成绩)
- [例 3.87] 建立信息系选修了1号课程且成绩在90分以上的学生的视图
- [例 3.88] 定义一个反映学生出生年份的视图
- [例 3.89] 将学生的学号及平均成绩定义为一个视图
- [例 3.90] 将Student表中所有女生记录定义为一个视图
- (2)删除视图
- [例 3.91 ] 删除视图BT_S和IS_S1
- 2、查询视图
- [例 3.92] 在信息系学生的视图中找出年龄小于20岁的学生
- [例 3.93] 查询选修了1号课程的信息系学生
- [例 3.94] 在S_G视图中查询平均成绩在90分以上的学生学号和平均成绩
- 3、更新视图
- [例 3.95] 将信息系学生视图IS_Student中学号”201215122”的学生姓名改为”刘辰”
- [例 3.96] 向信息系学生视图IS_S中插入一个新的学生记录,其中学号为”201215129”,姓名为”赵新”,年龄为20岁
- [例 3.97] 删除信息系学生视图IS_Student中学号为”201215129”的记录
- 4、视图的作用
- 结语
SQL语句基操(六)
本篇文章记录了第九次作业
使用的数据库是SQL Server,使用的数据库管理软件是SQL Server Management Studio.
上一篇文章:SQL语句基本操作练习(五)
经历了数据查询这一大篇章的洗礼后,我们学习到了数据更新和视图这一块。在写完这篇之后,SQL语句的基本操作就学完了,下一篇会是几个综合性的题目来进行一个复习。
一、数据更新
数据更新这块是对应着数据的添加、删除和修改,也就是CRUD中的CUD,查找这块我们已经说过就不再重复了。
1、插入数据(INSERT)
插入数据我们一般使用INSERT语句,它有两种形式:一种是插入元组,我在之前的文章中记录过一点这方面的操作;另一种则是插入子查询结果,可以一次性插入多个元组。
(1) 插入元组
虽然之前记录过了,我们还是再来过一遍。
插入的INSERT语句的格式为:
INSERT INTO <表名> [(<属性列1>[,<属性列2 >…)]
VALUES (<常量1> [,<常量2>]… );
这里的属性列和常量是一一对应的,也就是说下面的常量的值插入到相应的属性列中。所以一定要看好了,不要让插入的常量和属性列不对应。另外,若表内还有INTO子句内未出现的属性列,那么该属性列则会取空值。注意不要让建表时设定不能取空值的属性列取空值,否则会报错。
[例 3.69] 将一个新学生元组插入到Student表中
该元组为(学号:201215128,姓名:陈冬,性别:男,所在系:IS,年龄:18岁)
INSERT
INTO Student(Sno,Sname,Ssex,Sdept,Sage)
VALUES('201215128','陈冬','男','IS',18); /*字符串常量使用单引号括起来*/
[例 3.70] 将学生张成明的信息插入到Student 表中
INSERT
INTO Student
VALUES ('201215126','张成民','男',18,'CS');
这里省略了属性列,因此插入的常量是按照你建表的时候的属性值顺序插入的,故要注意属性和常量的对应关系。如果数据类型不匹配的话,又得出错。
[例 3.71] 插入一条选课记录(‘201215128’,‘1’)
有两种写法:
INSERT
INTO SC(Sno,Cno)
VALUES ('201215128 ',' 1 '); /*之前说到的自动给Grade赋空值*/
//或者
INSERT
INTO SC
VALUES (' 201215128 ',' 1 ',NULL); //手动加上空值对应
(2) 插入子查询结果
在之前的查询中,子查询出现在嵌套查询里面,一般都是为了为父查询细化某种条件,先行把数据做某种处理。这里的意思差不多,就是先把数据做某种处理(查询能够做到的)之后再将其插入。这样一次性可以插入多种元组,极大地简化了操作。
插入子查询结果的INSERT语句格式为:
INSERT
INTO <表名> [(<属性列1> [,<属性列2>… )]
子查询;
子查询语句视需要而定。比如:
[例 3.72] 对每一个系,求学生的平均年龄,并把结果存入数据库
Step1:题目要求我们把结果存入数据库,我们先建一个专门用来存放这个数据的表:
CREATE TABLE Dept_age
(Sdept CHAR(15),
Avg_age SMALLINT);
Step2:这里用到子查询,先将学生按系分组求得平均年龄,然后再将其插入。其实只是两个操作的一个组合,并不难。
INSERT
INTO Dept_age(Sdept,Avg_age)
SELECT Sdept,AVG(Sage)
FROM Student
GROUP BY Sdept;
下面是Dept_age表的查询结果:
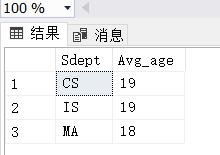
DBMS在你插入数据的时候会自动帮你检测完整性规则,也就是说这方面如果出错的话系统会自动报错。所以当插入失败的时候不妨看看是否违反了完整性规则。
2、修改数据(UPDATE)
修改操作又叫更新操作,因为它的关键句子是UPDATE.UPDATE与ALTER有所不同,前者主要用于数据修改方面,ALTER一般用于表的修改方面。
UPDATE的一般格式如下:
UPDATE <表名> /*修改表内满足WHERE条件的所有元组*/
SET <列名>=<表达式>[,<列名>=<表达式>]… /*可以一次更改多个属性*/
[WHERE <条件>]; /*更新的条件限定,省略则表示修改表内所有元组*/
(1) 修改某一个元组的值
[例 3.73] 将学生201215121的年龄改为22岁
根据上面给出的格式,我们很容易就能写出语句。把学生表内的WHERE学号是201215121的年龄SET成22就行了。
UPDATE Student
SET Sage=22
WHERE Sno = '201215121';
(2) 修改多个元组的值
[例 3.74] 将所有学生的年龄增加1岁
我们把WHERE子句去掉就可以应用到所有学生了。
UPDATE Student
SET Sage= Sage+1;
(3) 带子查询的修改语句
子查询的用法和插入里面类似,用来构造修改的条件。
[例 3.75] 将计算机科学系全体学生的成绩置零
先用子查询找出CS系学生的学号,再以此为根据,把他们在SC表中的Grade全部SET为0。
UPDATE SC
SET Grade=0
WHERE Sno IN
(SELECT Sno
FROM Student
WHERE Sdept= 'CS' );
同样,在修改的时候DBMS会检查完整性,如果对其有破坏的话也是不会通过的。
3、删除数据(DELETE)
删除数据我们一般使用DELETE来实现而不是DROP。因为DELETE只对数据进行删除而不会破坏到表的结构。比如省略WHERE子句后DELETE掉所有元组也不会对表造成损坏,而你要DROP一下可就全无了。
DELETE语句一般格式如下:
DELETE
FROM <表名>
[WHERE <条件>];
(1) 删除某一个元组的值
[例 3.76] 删除学号为201215128的学生记录
问题很简单,直接上语句
DELETE
FROM Student
WHERE Sno= '201215128';
(2) 删除多个元组的值
[例 3.77] 删除所有的学生选课记录
DELETE
FROM SC;
这就相当于把SC表清空了,表成了空表但结构还在。
(3) 带子查询的删除语句
[例 3.78] 删除计算机科学系所有学生的选课记录
和之前的操作都类似,没有什么多说的。
DELETE
FROM SC
WHERE Sno IN
(SELECT Sno
FROM Student
WHERE Sdept= 'CS');
同样,DBMS会检查完整性。
二、空值的处理
空值即(NULL),可以代表不知道、不存在或者是无意义的意思。比如在学生表中,某人因为没有上报年龄,所以可以先给他填上空值,这里就是不知道的意思。又比如在选课表中有学生缺考,那么他的成绩那一栏可以填空值,表示成绩不存在。还有可能就是该数据不方便填写女生的年龄,可以用空值代替。一些关系运算也可能会产生空值,具体含义具体判断。
这一段讲的是对空值的一些小应用。
1、空值的产生
[例 3.79] 向SC表中插入一个元组,学生号是”201215126”,课程号是”1”,成绩为空
这题在3.71中有类似的处理。两种方式,一种是在插入的时候插入空值;另一种是省略掉,让系统自动帮你插入空值。
INSERT INTO SC(Sno,Cno,Grade)
VALUES('201215126','1',NULL); /*手动插入*/
//或者
INSERT INTO SC(Sno,Cno)
VALUES('201215126','1'); /*请系统补全*/
[例 3.80] 将Student表中学生号为”201215200”的学生所属的系改为空值
这里直接SET改就完事儿了。
UPDATE Student
SET Sdept = NULL
WHERE Sno='201215200';
2、空值的判断
判断是否为空值用IN NULL或是IS NOT NULL(WHERE子句)
[例 3.81] 从Student表中找出漏填了数据的学生信息
漏填就是NULL的意思,我们可以很容易地用WHERE来判断。
SELECT *
FROM Student
WHERE Sname IS NULL OR Ssex IS NULL OR Sage IS NULL OR Sdept IS NULL;
这里就是把Student表内有任何一项为空的全都查询了出来。
3、空值的约束条件
并非所有属性都能取空值,在你建表的时候如果设定了该属性不为空(NOT NULL)的话那肯定不能取空值,否则会报错。还有加了UNIQUE限制的属性和码属性不能取空值。
4、空值的算术运算、比较运算和逻辑运算
空值和另一个值的算数运算结果为空值,空值与另一个值的比较结果运算为UNKNOWN.
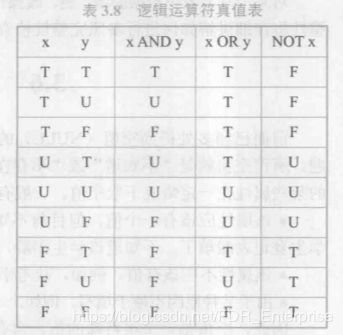
在查询语句中,只有条件子句中真值为T才会作为输出结果。
[例 3.82] 找出选修1号课程的不及格的学生
不及格是指Grade小于60分。
SELECT Sno
FROM SC
WHERE Grade < 60 AND Cno='1';
若是Grade为空的话,根据逻辑运算,U AND T是U,不会输出。
[例 3.83] 选出选修1号课程的不及格的学生以及缺考的学生
跟上一题相比增加了查询缺考学生的要求,也就是NULL。
SELECT Sno /*集合查询*/
FROM SC
WHERE Grade < 60 AND Cno='1'
UNION
SELECT Sno
FROM SC
WHERE Grade IS NULL AND Cno='1';
//或者
SELECT Sno
FROM SC
WHERE Cno='1' AND (Grade<60 OR Grade IS NULL);
两者没有什么大区别,都很好理解。
三、视图
视图时从一个或几个基本表(或视图)导出的表。视图和我们之前讲的派生表有些相似,不过那个是临时用于辅助查询的,而视图是保存到系统中的。视图是一个虚表,系统之保存它的定义,数据还是在基本表里,对基本表内数据的变化也会影响到视图,而对视图的增删改不一定影响到基本表的数据。
从这点来说,视图就像一个窗口能让你聚焦于你感兴趣的数据,但对这些数据的操作有一定的限制。而且视图的增删改其实也是应用于基本表上的。
1、定义视图
(1)建立视图
SQL用CREATE VIEW 建立视图,一般格式如下:
CREATE VIEW <视图名> [(<列名> [,<列名>]…)]
AS <子查询>
[WITH CHECK OPTION];
WITH CHECK OPTION这个语句是里面最显眼的,它的意义在于有了这个语句,那么对视图进行增删改操作时,系统会保证改动项是满足子查询语句中的条件表达式的。具体的表现形式我们在下面会看到。
组成视图的属性列名或者全部省略或者全部指定。全部省略是指该视图由子查询中SELECT子句目标列中的字段组成,即以SELECT出的属性作为视图的属性。但是以下三种情况要使用全部指定:
- 某个目标列是聚集函数或列表达式;
- 多表连接时选出了几个同名列作为视图的字段; //即有重复
- 需要在视图中为某个列启用新的更合适的名字。
我们来尝试建立一个视图:
[例 3.84] 建立信息系学生的视图
CREATE VIEW IS_Student /*全部省略,指定了Sno,Sname,Sage三个属性*/
AS
SELECT Sno,Sname,Sage
FROM Student
WHERE Sdept= 'IS';
这里的SELECT语句实际上是不执行的,只是起到提供建立视图的基本参数的作用。
[例 3.85]建立信息系学生的视图,并要求进行修改和插入操作时仍需保证该视图只有信息系的学生
跟上一题相比增加了“保证”的要求,很明显这就是之前说到的WITH CHECK OPTION,所以我们直接加上就完成了。
CREATE VIEW IS_Student
AS
SELECT Sno,Sname,Sage
FROM Student
WHERE Sdept= 'IS'
WITH CHECK OPTION;
加上这个之后,每次对该视图进行增删改操作的时候,系统会自动为其加上Sdept='IS’的条件。
像这种从一个基本表中导出,并且只是去掉了基本表的某些行、列,但仍然保持主码的视图,我们称之为行列子集视图。
当然,除了这些从一个基本表中导出的,我们还有多个基本表的视图。
[例 3.86] 建立信息系选修了1号课程的学生的视图(包括学号、姓名、成绩)
这个视图根据它涉及到的属性,我们可以判断它涉及到Student表和SC表,WHERE这块是个连接查询不多说。Show you the code.
CREATE VIEW IS_S1(Sno,Sname,Grade) /*有重复属性,必须全部指定*/
AS
SELECT Student.Sno,Sname,Grade
FROM Student,SC
WHERE Sdept= 'IS' AND
Student.Sno=SC.Sno AND
SC.Cno= '1';
视图既然是一种虚表,那么也应该可以根据视图来建立视图。
[例 3.87] 建立信息系选修了1号课程且成绩在90分以上的学生的视图
CREATE VIEW IS_S2
AS
SELECT Sno,Sname,Grade
FROM IS_S1
WHERE Grade>=90;
这就是一个在IS_S1视图上建立的视图,与根据表建立视图的操作没有什么差别。
对于一些计算出的派生数据,因为视图中的数据并不是实际存储的,所以我们可以设置一些派生属性列来存储这些计算的数据。由于这些数据并不在基本表中存在,我们称它们为虚拟列。带虚拟列的视图被称为带表达式的视图。
[例 3.88] 定义一个反映学生出生年份的视图
CREATE VIEW BT_S(Sno,Sname,Sbirth) /*Sbirth是存储下面的计算数据的虚拟列*/
AS
SELECT Sno,Sname,2020-Sage /*这里的2020-Sage,即出生年份,就是计算的数据列*/
FROM Student;
带有聚集函数和GROUP BY子句查询的视图称为分组视图。 下面就是一个分组视图。
[例 3.89] 将学生的学号及平均成绩定义为一个视图
CREATE VIEW S_G(Sno,Gavg) /*有GROUP BY,全部指定*/
AS
SELECT Sno,AVG(Grade)
FROM SC
GROUP BY Sno;
[例 3.90] 将Student表中所有女生记录定义为一个视图
CREATE VIEW F_Student(F_Sno,name,sex,age,dept)
AS
SELECT *
FROM Student
WHERE Ssex='女';
这里的视图是由SELECT *建立的,所以对原表的结构进行改动,视图将会遭到破坏,所以应该在修改后删去这个视图,重新建立视图。
(2)删除视图
删除使用的是之前使用过的DROP语句,其一般语句为:
DROP VIEW <视图名>[CASCADE];
这里的删除视图指的是将视图的定义从数据字典中删除,基本表和基本数据不会有影响。如果加了CASCADE级联就会把与它相关的所有视图一同删去。
如若删去了基本表,那么我们仍然要去手动删去视图。
[例 3.91 ] 删除视图BT_S和IS_S1
DROP VIEW BT_S;
DROP VIEW IS_S1;
/*本来说因为IS_S1关联了IS_S2不能直接删除*/
/*但我在SQL Server中的尝试成功了...*/
/*正常来说,应该把第二句改成级联删除*/
DROP VIEW IS_S1 CASCADE;
/*但SQL Server中不支持CASCADE,那还是直接删吧*/
2、查询视图
视图的查询和基本表的查询基本相同,可以说只是套了一个视图的壳子,本质上还是基本表的查询。具体上就是DBMS先进行检查看视图是否存在,如果存在则从数据字典中取出视图的定义,把定义中的子查询和用户的查询结合起来转换成等价的对基本表的查询,然后再执行修正了的查询。我们将这种转换过程称为视图消解。
[例 3.92] 在信息系学生的视图中找出年龄小于20岁的学生
SELECT Sno,Sage /*基于视图的查询语句*/
FROM IS_Student
WHERE Sage<20;
/*视图消解后的实际语句*/
SELECT Sno,Sage
FROM Student
WHERE Sdept= 'IS' AND Sage<20;
[例 3.93] 查询选修了1号课程的信息系学生
这一题是基于两个表(虚表和基本表)的查询。
SELECT IS_Student.Sno,Sname
FROM IS_Student,SC
WHERE IS_Student.Sno=SC.Sno AND SC.Cno='1';
有时候,视图消解也会出现错位。
[例 3.94] 在S_G视图中查询平均成绩在90分以上的学生学号和平均成绩
让我们直接写的话,估计就是这个样子:
SELECT *
FROM S_G
WHERE Gavg>=90;
看上去没有什么问题,但是在S_G视图中的子查询中,我们使用了AVG()这一聚集函数,我们知道,WHERE子句中是不能用积极函数作为条件表达式的,所以在某些不能自动纠正的DBMS中使用这样的查询可能会出现错误(SQL Server没出问题)。对于这样的查询我们应该直接对基本表进行。
如:
SELECT *
FROM (SELECT Sno,AVG(Grade)
FROM SC
GROUP BY Sno) AS S_G(Sno,Gavg) /*这里使用了派生表*/
WHERE Gavg>=90;
3、更新视图
对视图的更新操作也是像查询一样,是通过视图消解来转化为对基本表的操作。这方面的操作和我们在前面讲到的基本表的操作差别不大,可以依葫芦画瓢,都写出来。
[例 3.95] 将信息系学生视图IS_Student中学号”201215122”的学生姓名改为”刘辰”
UPDATE IS_Student
SET Sname= '刘辰'
WHERE Sno= '201215122';
[例 3.96] 向信息系学生视图IS_S中插入一个新的学生记录,其中学号为”201215129”,姓名为”赵新”,年龄为20岁
INSERT
INTO IS_Student
VALUES('201215129','赵新',20); /*有WITH CHECK OPTION会自动加上'IS'的信息*/
[例 3.97] 删除信息系学生视图IS_Student中学号为”201215129”的记录
DELETE
FROM IS_Student
WHERE Sno= '201215129';
在关系数据库中并不是所有的视图都是可以更新的,例如之前的S_G视图中的平均成绩并不能更新,因为它实质上是对SC表Grade的一个子查询结果,它无法转换整对基本表SC 的更新。就好像对于某些电子设备,你无法更改它的时间,因为他的时间是从授时系统中直接得来的,而授时系统的时间不会因为你想改变一台设备上的时间而改变。
一般数据库都允许对行列子集视图进行更新,而不同的数据库有不同的更新规则,我们需要按数据库出SQL。
4、视图的作用
整个视图学下来我们总结了以下几个作用:
- 视图能够简化用户操作
- 视图让用户能从多个角度看待同一数据
- 视图对重构数据库提供了一定的逻辑独立性
- 视图对机密数据可以提供安全保护
- 视图可以让查询表达更加容易、清晰
结语
SQL的基本操作到此就基本完结了。我们学习了SQL的数据定义、数据查询、数据更新。这其中篇幅最多的就是数据查询,我好像写了将近4篇文章来记录查询的学习过程。
我觉得写SQL语句的要点就是逻辑关系要清楚,这样在关系数据库里面这些个查询就好写了。如果逻辑关系搞不清楚,脑袋里就是一团浆糊,啥都写不出来的。另外这一块的实践也是很重要的,只有亲手打上一遍代码,细细品味,才能记住。疫情期间我们无法上实验课,而是用博客的方式记录下来学习过程,倒也是别具风味的“实验课”吧。
最后一篇文章:SQL语句题目练习
参考文献:
[1]萨师煊,王珊,数据库系统概论.5版.北京:高等教育出版社,2014.
[2]David老师的PPT.