本文来自网易云社区
docker监控的调研实践
docker发展到这么久,涌现了非常多的延伸工具,有的甚至自成一套系统。相信大家都对各类编排工具有所了解。而各类监控方案也都应运而生。linux内核以及cgroup技术其实已经为监控的技术可行性提供了所有的基础。这里我们列举一些监控工具:
docker原生监控
docker 提供了command方法(docker stats CID)和API: http://$dockerip:2375/containers/$containerid/stats 其本质是读文件,提供了CPU,内存,BIO,NIO的监控,想探究其实现的同学可以去查阅开源项目libcontainer,或阅读浅谈k8s+docker 资源监控了解详细的技术内容。
cAdvisor
cAdvisor是一个被k8s集成的监控agent(谷歌自家用),与docker原生监控一样采用了libcontainer的接口。cadvisor还增加了对宿主机的监控,包括CPU,内存,网卡和磁盘设备,甚至还调用了docker的api,去整合了容器的基本信息如labels,resource limits等。可以说cadvisor的监控已经比较全面了,然而容易引人吐槽的是:至今cadvisor还没有推出一个稳定的大版本,最新版本是0.24.1,可它的API版本已经出到2.1版了。这里列出几个cadvisor的关键API(只采用最新的v2.1 api):
1. http://localhost:4194/api/v2.1/stats/:containerid 查看容器的资源数据
2. http://localhost:4194/api/v2.1/machine 查看机器的信息
3. http://localhost:4194/api/v2.1/machinestats 查看机器的资源数据,包括磁盘的读写数据
4. http://localhost:4194/api/v2.1/spec/:containerid 查看容器的基础信息
5. http://localhost:4194/api/v2.1/summary:containerid 查看容器在几个时间片的各项指标状态分布值
6. http://localhost:4194/api/v2.1/storage/:containerid 查看容器中的磁盘挂载情况
需要注意的是,此处的containerid由podID和container ID,以一定规则,按照不同的QoS命名,如: /kubepods/burstable/pode0f6a540-90af-11e8-8ae8-fa163edcbbdb/2bb0179713a20d3f96c85d7fcd1354277270c413f7970b7b6c0db8363bbf892b 表示一个没有定义容器resources.requests 和resources.limits 的pod(pod的uuid:e0f6a540-90af-11e8-8ae8-fa163edcbbdb)中的容器(容器id:2bb0179713a20d3f96c85d7fcd1354277270c413f7970b7b6c0db8363bbf892b ) /kubepods/podc3b4fc59-9462-11e8-9fcd-fa163edcbbdb/282755d06a51d84c1dc0d3153b1bf4604cc37ae2ccb26c69b3855176894da50c 表示一个定义了容器resources.requests 和resources.limits 的pod中的容器。
以上几个接口其实看名字就能大概知道是什么意思,有兴趣的同学不妨在自己的机器上部署kubernetes,然后在计算节点运行这几个api试试。 cadvisor默认监听咋在4194端口,而kubelet其实也代理了cadvisor的监控,所以,我们除了上述的接口,还可以通过访问kubelet(10255端口)来获取监控数据。
这里还要再提一下heapster,cadvisor+heapster可以很好的实现kubernetes容器集群的资源监控。heapster在发布稳定版本(1.0)后,增加了对pause容器的识别,可以更直观地通过heapster的API查看到Pod级别的网络IO。数据存储用elasticsearch/influxDB/hawkular等各种存储都可以(heapster支持用户以storage driver plugin的形式将抓取的metrics sink 自由整合并推送给存储服务)数据展示使用grafana,这就打造了一套基本完整的的数据监控服务。而使用k8s可以将三个组件(heapster+influxdb+grafana)一键部署。 *k8s1.9后heapster已经被社区废弃。社区将使用metrics-server进行基础的集群性能监控,并使用prometheus来支持更细致的指标监控。
其他项目如zabbix,openfalcon,promethus,metrics-server
Zabbix更面向裸机和IaaS虚拟机,容器监控是他的软肋,而openfalcon则被许多企业或docker团队选型为容器集群监控的方案。openfalcon有完整的监控项,增加了邮件告警功能,可自定义的agnet SDK。但整套系统模块繁多,学习成本大。要想用好,还需要针对容器/kubernetes进行二次开发。
prometheus是一套非常成熟的监控,它可以监控很多细节的性能指标,比如http请求次数,磁盘读写io和延迟,cpu负载等,同时prometheus友好地支持自定义指标的采集,用户可以以此为基础设计自己服务的QPS监控、访问延迟监控、业务处理速度监控等。目前prometheus已经被很多厂商用于生产环境,也因此它已经顺利从CNCF项目中毕业。
metrics-server严格来说是heapster的替代品,它作为kubernetes的“周边”,在集群中以deployment方式部署,metrics-server会注册一套用于监控的api,监控数据则是从当前集群的所有node中拉取(也就是上文提到的kubelet代理的监控接口)。在集群中部署好metrics-server后,过一分钟我们可以通过执行kubectl top node *** 查看一个node节点的cpu和内存使用情况。 metrics-server主要应用在社区的HPA(horizontal pod autoscaler)功能中。
追根溯源
在linux中,一切都是文件,所以基于LXC技术的虚拟化方案中,对资源的监控其实也是文件,我们知道docker依赖cgroup做资源的限制,而实际上cgroup也记录了资源的使用情况。我们在容器宿主机的/sys/fs/cgroup/目录下可以看到诸如cpu,memory,blkio的子目录,他们分别存放了对机器上某些进程的资源限制和使用情况。比如: /sys/fs/cgroup/blkio/docker/1c04cedf48560c37cbac695809f8d50d632faa6b1aaeaf40d269756eb912597b/blkio.throttle.io_service_bytes 记录了某个容器的块设备IO字节数。 而容器的网络设备流量,我们可以在/sys/class/net/目录下根据对应的网卡设备名,找到统计数据文件: /sys/class/net/vethc56160e/statistics/tx_bytes 记录了某个网卡的发出字节数。 (更多知识可以学习cgroup的资源限制)
可见,监控数据的抓取并不是难事,真正困难的是将这些数据以容器维度,甚至k8s的Pod,RC维度整合。
网易云计算基础服务的容器监控设计
网易云计算基础服务在自研的云监控服务的基础上,结合开源组件cadvisor二次开发,实现了云计算基础服务的监控系统。
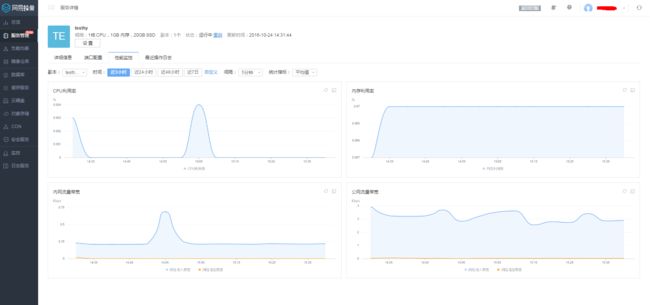
实际上,我们不创造监控,我们是监控的搬运工。网易云平台已经有成熟的自研监控系统(NMS)为我们提供了监控数据的存储,整理和展示。开源组件cadvisor也提供了cpu,内存,网络等指标的监控支持和数据缓存(保证监控数据的可读性)。 本着实用性和可用性的原则,我们还做了如下设计:
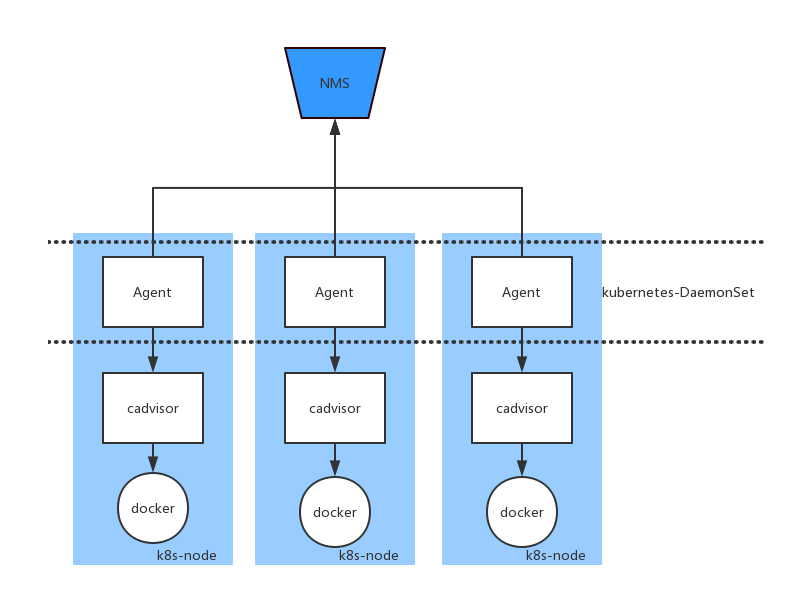
1.独立的agent模块
通过一个独立的agent模块,去收集cadvisor采集的数据,并推送给云监控。我们这么设计的初衷,最主要为了避免对cadvisor做侵入式开发,避免后续cadvisor的版本更新带来的大范围代码改动。cadvisor本身是一个pull server,不是一个push agent,强行加入push 模块会增加kubelet的复杂性和性能负担,也会提高整个系统的耦合度;二是云监控有自己一套API,对数据的维度和监控的demision都有其规范,比如,我们将每次push给云监控的CPU使用率以Namespace#Service#Pod#Container为标识,确保该监控数据能匹配到制定的容器,从而实现页面上的展示。而引入这套规范到cadvisor中也会提高整个系统的耦合度。
2.使用DaemonSet特性构建分布式监控
在agent的部署上我们直接利用了kubernetes的DaemonSet特性。
我们知道,k8s最常用的两个资源是pod和replication,daemonset是一个刚趋于稳定的特性,和deployment类似,然而十分的实用。使用daemonset会保证这个agent Pod会在每一个计算节点上启动并保持一个实例。agent调用cadvisor的接口收集数据,根据云计算基础服务产品的需求,对数据做过滤和加工,最后推送给云监控。agent既是kubernetes集群监控的组件,也是k8s-DaemonSet的应用范例。
3.增加了对容器磁盘的各项监控
云计算基础服务实现了有状态服务的部署,并支持挂载云硬盘,针对用户的反馈,我们了解到必须增加对容器的系统盘、数据盘使用率的监控(后续还会提供inode,IOPS,BPS这些指标),提出阈值预警,避免用户的误操作导致的不良影响进一步扩大。cadvisor的几个接口(下文会列出)会分别提供一部分磁盘的监控数据,但是并没有做好整合(可以看到容器stats API中Filesystem字段的内容并不是我们想要的数据).
基于cadvisor的接口和对linux底层的认识,我们是这么实现对磁盘的监控的:
1.为了不破坏cadvisor原来的代码结构,在v2.1中新增一个API,提供维度为一个/多个容器的所有挂载设备的监控信息。监控信息包括:容器名、负载名、容器挂载的云盘类型、挂载目录、云盘uuid等。这里挂载路径可以通过容器的描述文件(或直接docker inspect)得到。
2.通过原生接口/api/v2.1/stats/machinestats,我们能看到容器挂载的所有磁盘设备的IOPS和BPS(JSON中的io_serviced字段和io_service_bytes字段记录了累计值,通过计算可以求出IOPS和BPS)。结合步骤1的数据,整合出一个容器挂载的所有云盘的使用率、inode使用率、IOPS和BPS;
3.结合我们在kubernetes使用过程中的规范,区分确认系统盘(容器系统盘一般挂载在容器的/目录下)和数据盘(来自网易云存储NBS提供的卷信息),按不同维度推送给云监控。比如cloud#deployment:netease#nginx#ng1 维度,表示cloud namespace、deployment:netease、pod:nginx,容器名:ng1 。
4.云监控处理监控数据时,根据维度进行数据聚合,以此提供多视角(容器视角、pod视角、负载视角)的监控展示。
如果读者们阅读过cadvisor的代码,会发现里面对机器的描述信息、文件系统的描述信息,是全局的(感兴趣的可以在源码中阅读以下machineInfo、fsInfo两个变量),且在一个cadvisor Manager对象初始化后就不会再被修改。这导致我们在测试环境发现:动态挂载一个云盘到宿主机上,并挂载作为容器的数据盘时,cadvisor无法读取新挂的磁盘的数据,除非重启kubelet(相当于重新初始化cadvisor中的fsInfo)。我们在cadvisor的代码中增加了自检逻辑,当检查到机器上有新挂载的云盘时,对machineInfo、fsInfo做更新(需加锁,否则会引入竟态)。但这个更改没有被社区采纳。
网易云容器服务为用户提供了无服务器容器,让企业能够快速部署业务,轻松运维服务。容器服务支持弹性伸缩、垂直扩容、灰度升级、服务发现、服务编排、错误恢复及性能监测等功能,点击可免费试用。
网易云新用户大礼包:https://www.163yun.com/gift
本文来自网易实践者社区,经作者黄扬授权发布。