以Python撰写 AI模型框架
by 高焕堂
-
前言:
在AI(人工智慧)方面,由于当今的机器学习本质是一种<大数据相关性支撑的>归纳性推理。软体框架的复用(Reuse)性愈高,对于应用开发的帮助愈大。因此,在AI领域里,软体框架魅力将会大放异彩。在本文里,是基于最简单的Perceptron模型来阐述如何分析、设计及实作一个框架和API。在本节里,将优化这个AI模型,让它从线性分类,提升到非线性分类,可以展现更高的智慧,也适用于更广的范围。而且将把最典型的Sigmoid激励函数,添加到上一节所撰写的Percentron基类里。由于这Sigmoid激励函数适合于二元分类(Binary classification)的情境,包括线性和非线性二元分类问题。所以将这框架取名为:BCModelFarmework。期待充分发挥框架威力、支援您的商业模式,迈向辉煌腾达之道。
-
Python框架设计:从需求到实作
大家都知道,人们的需求都是善变的,所以API的内涵也是随时会改变的。在上一篇文章里,其API里只定义了一个getLR()函数。在本节里,就来替API增添多函数。
2.1 亲自演练:需求分析
一旦客人的需求有所改变了,可能会不断扩充API。例如,当客人来了之后,才会告知下述5项资料:学习率(Learning Rate)、要训练几回合(Epoch)、训练资料集X[] ,以及期望值T[]等。就能依据框架的需求时间轴概念,来绘出下图:
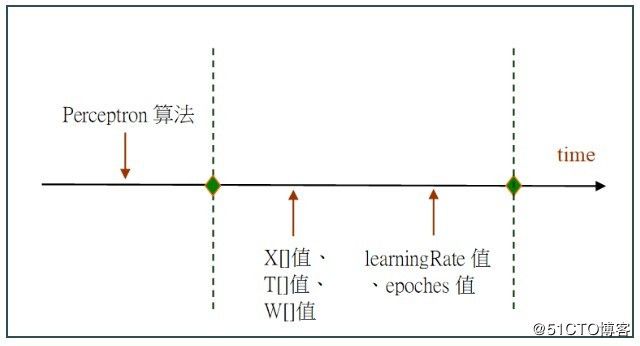
图1、框架需求分析
从这图可以看出来,这5项资料都是写在子类里,而框架必须透过API来向子类索取这5项资料值。一旦框架取得了这些资料,就能展开AI模型的训练工作了。现在,就依据上图的思维而绘制出类别图,如下所示:
图2、此范例的类别图
在这PerFramewor02框架里,含有一个Perceptron基类,让myNN子类来继承之。也就是由子类来实作Perceptron里的抽象函数。
2.2 亲自演练:实現框架
现在,就以Python来实現这个框架,如下:
PerFramework02.py
import numpy as np
from abc import ABC, abstractmethod
class Perceptron(ABC):
def init(self):
self.learningRate = self.getLR()
self.epoches = self.getEpoch()
self.B = 0;
self.W = 0;
self.correctRate = np.zeros([30])
def train(self):
X = self.getX()
T = self.getT()
len = X.size
for i in range(self.epoches):
errorCount = 0;
for j in range(len):
error = T[j] - self.predict(X[j])
update = self.learningRate * error
# 修正W和B
self.W += update * X[j]
self.B += update
# 累积错误次数
if (error != 0):
errorCount = errorCount + 1
# 算出正确率
self.correctRate[i] = 1 - errorCount * 1.0 / len
def predict(self, x):
y = x * self.W + self.B
z = self.getZ(y)
return z
def printCR(self, idx):
print("#:", idx, " ", self.correctRate[idx])@abstractmethod
def getLR(): pass
@abstractmethod
def getEpoch(): pass
@abstractmethod
def getZ(y): pass
@abstractmethod
def getX(): pass
@abstractmethod
def getT(): pass
这个时候,API已经扩大了,总共包含了5个抽象函数:getLR()、getEpoch()、getZ()、getX()和getT()。在程式执行时,基类就会透过抽象函数的机制,来呼叫子类的函数,来取得上述的5项资料。接着,就来撰写App如下:
Ex1-01.py
import numpy as np
from abc import ABC, abstractmethod
from PerFramework02 import Perceptron
class myNN(Perceptron):
def init(self):
super().init()
def getLR(self):
return 0.1
def getEpoch(self):
return 30
def getZ(self, y):
if (y >= 0):
return 1
else:
return 0
def getX(self):
dx = np.array([0.0, 1.0, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0, 8.0, 9.0])
return dx
def getT(self):
dt = np.array([0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 1.0, 1.0, 1.0, 1.0])
return dt----主程式部分---------------------------------------
p = myNN()
p.train()
p.printCR(0)
p.printCR(1)
p.printCR(2)
p.printCR(21)
p.printCR(22)
p.printCR(23)
p.printCR(24)
p.printCR(25)
p.printCR(26)
这是一支能在Python环境里执行的App,内含两个类别,其中的myNN继承框架里的Perceptron基类。其中的主程式(部分)里有个指令:
p = myNN()诞生一个myNN的物件,并且呼叫到Perceptron基类的建构式(Constructor):
class Perceptron(ABC):
def __init__(self):
self.learningRate = self.getLR()
self.epoches = self.getEpoch()# …………..
# ………….然后,开始执行这建构式里的指令,首先呼叫到getLR()函数,转而呼叫子类myNN里的getLR()函数,要求它传回来<学习率>的值。接着,就呼叫到getEpoch()函数,转而呼叫子类myNN里的getEpoch()函数,要求它传回来训练的回合数。然后返回主程式部分,执行下一个指令:
p.train()
于是,这指令就呼叫Perceptron基类的train()函数,并开始执行train()函数里的指令:
def train(self):
X = self.getX()
T = self.getT()就呼叫到getX()函数了,并转而呼叫myNN里的getX()函数,要求它传回来训练资料X[]的内容。接着呼叫getT()函数了,然而这getT()是抽象函数,其指令是实作于myNN子类里,于是就转而呼叫myNN里的getT()函数,要求它传回来期望资料T[]的内容。然后展开训练的动作,并输出结果如下:

一开始,在第#0~#22回合,其预测的正确率比较低。然而愈多回合的训练,其正确率就逐渐上升了。到了第#23回合之后,其预测的正确率就接近于1.0(即达到100%)了。以上展现了框架API的不断成长过程,而框架与App之间的互动也更频繁了。-
优化模型:使用Sigmoid激励函数
3.1 写出一支App:使用Sigmoid函数
在上一节里,是基于最简单的Perceptron模型来阐述如何分析、设计及实作一个框架和API。在本节里,将优化这个AI模型,让它从线性分类,提升到非线性分类,可以展现更高的智慧,也适用于更广的范围。本节的范例里,将把最典型的Sigmoid激励函数,添加到上一节所撰写的Percentron基类里。由于这Sigmoid激励函数适合于二元分类(Binary classification)的情境,包括线性和非线性二元分类问题。所以将这框架取名为:BCModelFarmework。如下述Python程式码:
#BCModelFramework.py
from abc import ABC, abstractmethod
import numpy as np
class Perceptron(ABC):
def __init__(self):
self.learningRate = self.onLearningRate()
self.epoches = self.onEpoch()
dw = self.onW()
self.W = dw[0]
self.B = dw[1]
self.correctRate = np.zeros(self.epoches)
def train(self):
X = self.onX()
T = self.onT()
epoches = self.correctRate.size
len = np.size(X, 0)
for i in range(epoches):
errorCount = 0
for j in range(len):
z = self.predict(X[j])
loss = T[j] - z
delta = 2 * self.deriv(z) * loss
update = self.learningRate * delta
# 修正W和B
self.W += update * X[j]
self.B += update
# 累计错误次数
if (z >= 0.5):
v = 1
else:
v = 0
if ((T[j] - v) != 0):
errorCount = errorCount + 1
# 算出正确率
self.correctRate[i] = 1 - errorCount * 1.0 / len
def predict(self, X):
y = np.dot(X, self.W) + self.B
z = self.sigmoid(y)
return z
def sigmoid(self, y):
z = float(1 / (1 + np.exp(-y)))
return z
def deriv(self, z):
d = z * (1 - z)
return d
@abstractmethod
def onLearningRate(): pass@abstractmethod
def onEpoch(): pass
@abstractmethod
def onX(): pass
@abstractmethod
def onT(): pass
@abstractmethod
def onW(): pass
def getW(self):
return self.W
def getCR(self):
return self.correctRate
这个BCModelFramework框架里,含由一个Perceptron基类,它提供的API总共包含5个抽象函数:onLearningRate()、onEpoch()、onX()、onT()和onW()。接着,就可基于这个框架来快速开发App了,如下述的程式码:
Ex12-07.py
import numpy as np
from abc import ABC, abstractmethod
from BCModelFramework import Perceptron
class myNN(Perceptron):
def init(self):
super().init()
def onLearningRate(self):
return 0.1
def onEpoch(self):
return 80
def onX(self):
dx = np.array([0.0, 1.0, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0, 8.0, 9.0])
return dx
def onT(self):
dt = np.array([0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 1.0, 1.0, 1.0, 1.0])
return dt
def onW(self):
self.dw = np.array([[0.0], 0.0])
return self.dw
def printWeight(self):
print(self.getW())
def printCR(self, idx):
cr = self.correctRate
print(" 第", idx, "回合: ", str(int(cr[idx] * 100)), "%")
-----------------主程式部分-------------------------------------------
p = myNN()
p.train()
print(" 正确率:")
p.printCR(0)
p.printCR(1)
p.printCR(10)
p.printCR(20)
p.printCR(30)
p.printCR(40)
p.printCR(50)
p.printCR(60)
p.printCR(70)
这是一支能在Python环境里执行的App,内含两个类别。其中的myNN继承框架里的Perceptron基类,如下:

图3、框架支援App的快速开发这个简单范例里,输出层神经元的主要计算公式是:y= X*W+B。表现于指令:
def predict(self, X):
y = np.dot(X, self.W) + self.B
z = self.sigmoid(y)
return z计算出y值之后,再经由Sigmoid()激励函数,转换出z值,才成为这神经元的输出值(即z值)。有了z值之后,就能进行「反向传播(Backpropagation)」来更新权重(Weight)值。表现于指令:
loss = T[j] - z
delta = 2 * self.deriv(z) * loss
update = self.learningRate * delta其中的loss值,还要乘以Sigmoid的导数(Derivation)值,来决定修正的幅度。这样子,让模型的适用范围更广了。除了可以应用于线性分类(Linear classification)问题上,也适用于非线性分类(Nonlinear classification)的情境。
至于主程式(部分)里有个指令:
p = myNN() 诞生一个myNN的物件,并且呼叫到基类Perceptron的建构式:
class Perceptron(ABC):
def __init__(self):
self.learningRate = self.onLearningRate()
self.epoches = self.onEpoch()
dw = self.onW()
# …………
# …………然后,开始执行建构式里的指令,呼叫到了onLearningRate()函数,转而呼叫子类myNN里的onLearningRate()函数,要求它传回来<学习率>的值。接着,就呼叫到onEpoch()函数,转而呼叫子类myNN里的onEpoch()函数,要求它传回来训练的回合数。接着,就呼叫到onW()函数,转而呼叫子类myNN里的onW()函数,要求它传回来权重的初期值。然后返回主程式部分,执行下一个指令:
p.train()
于是,这指令就呼叫基类Perceptron里的train()函数,执行到train()函数里的指令:
def train(self):
X = self.onX()
T = self.onT() 就呼叫到onX()函数了。然而这onX()是抽象函数,其指令是实作于myNN子类里。于是就转而呼叫myNN里的onX()函数,要求它传回来训练资料X[]的内容。接着呼叫onT()函数了,就转而呼叫myNN里的onT()函数,要求它传回来期望资料T[]的内容。然后展开训练的动作,并输出结果如下:
其结果与上一个范例是一致的,一开始的预测正确率比较低。然而愈多回合的训练,其正确率就逐渐上升了。到了第#50回合之后,其预测的正确率就接近于1.0(即达到100%)了。◆