gdb对dwarf调试信息的解析和使用
Dwarf调试信息Consumer——gdb
1 引言
前面介绍过dwarf调试信息格式,内容包括有哪些类型的调试信息,调试信息的存放格式、某些调试信息的编码方法等。本文的内容主要调试信息是怎样被解析使用的调试信息作为编译器为了实现源码级别调试生成的内容,其主要的consumer自然是gdb。下面介绍gdb中如何使用dwarf调试信息。
本文是一个基于源码debug过程的分析文档,内容比较细,偏笔记性质的。总结抽象工作做得不多。所以其中的内容以及一些流程图都会比较细节。下面提供一个总结概括性的ppt文档点击打开链接。
2 调试信息回顾
在介绍gdb如何读取dwarf调试信息之前,我们先回顾一下有哪些调试信息,调试信息在elf文件中的位置。
在使用gcc编译程序的时候,加上-g参数,那么最后生成的目标文件中会有调试信息,调试信息格式使用dwarf2格式。使用readelf工具加上-S参数,可以查看目标文件中有哪些调试信息section,示例如图2-1所示。

图 2‑1 调试信息类别
可以看到.debug_*都是调试信息的section,每个section代表不同类型的调试信息,表2-1介绍不同类型调试信息。
表格2‑1调试信息类型说明
| Section |
说明 |
| .debug_info |
调试信息主要内容,各个DIE |
| .debug_abbrev |
调试信息缩写表,每个编译单元对应一个缩写表,每个缩写表包含一系列的缩写声明,每个缩写对应一个DIE |
| .debug_line |
行号信息 |
| .debug_macinfo |
宏信息,编译器-g3参数才会产生宏信息 |
| .debug_aranges |
范围表,每个编译单元对应一个范围范围表,记录了该编译单元的某些ENTRY的text或者data的起始地址和长度,用于跨编译单元的快速查询 |
| .debug_pubnames |
全局符号查询表,以编译单元为单位,记录了每个编译单元的全局符号的名称 |
| .debug_frame |
函数的堆栈信息 |
| .debug_str |
.debug_info中使用到的字符串表 |
| .debug_loc |
Location list |
3 Gdb使用调试信息
Gdb中实现源码级别调试,主要实现名称、位置的映射。而这些信息在gdb内部通过symbol来记录的。Symbols按照一定的关系组合在一起,形成symbol table。在gdb中有三类符号表。
表格3‑1 gdb中的符号表
| 符号表 |
说明 |
| Minimal_symbol table |
该符号表通过分析elf文件中的.symtab section得来,该section中记录的是在elf文件的链接过程中所必须的一些全局的符号。该符号表在没有-g参数的时候也会有。 |
| Partial symboltable |
顾名思义,部分符号表,里面记录的是部分的符号的部分的信息,在gdb读入symbol file的时候会初步分析调试信息,建立这么一张partial symbol table,它有两个作用:1,满足一部分的调试需求;2,gdb可以根据partial symtab读入full symtab。 |
| Full symbol table |
完整符号表,里面记录的是完整的符号信息,源码级别调试实现的基础。由于其信息很多,占的内存空间很大,所以gdb在一开始读入symbol file的时候并不会产生这么一个full symtab,而是在后续的调试过程中,如果有需要完整符号表的地方,才会把该cu的full symtab读入,这样效率较高。 |
Gdb调试主要依靠这三个符号表实现,minimal symtab比较简单,也不属于调试信息分析的范畴,本文不会对minimal symtab多加叙述。Partial symtab和full symtab的建立是根据调试信息完成的。下面gdb对调试信息的使用过程也是这么两张符号表的建立的过程。
3.1 Debug_info——PartialSymtab
3.1.1 Partial symtab简介
在展开partial symbol相关的讨论之前,我们先看看partialsymbol是什么。
在gdb中使用structpartial_symbol,来描述一个partial symbol,其中包含的信息如下表所示。
表格3‑2 struct partial_symbol
| 数据项 |
说明 |
| Domain |
该symbol的类型:变量、函数、type、label等。 |
| Address_class |
说明该符号的地址类型,即在什么地方可以找到该符号:寄存器、arglist、local变量、typedef类型等。 |
| Struct general_symbol_info |
所有类型符号的基础信息:name、value(是个union,取决于符号的类型)、在哪个section等。 |
Partial symbol以一定的规则组合在一起,形成partial symtab,gdb中以source file为单位,每个source file对应一个struct partial_symtab,一个objfile中的所有的partial_symtab组成一个链表。Partial symtab中只记录该file中static类型的和global类型的一些符号。Struct partial_symtab的包含的信息如下表所示。
表格3‑3 struct partial_symtab
| 数据项 |
说明 |
| Struct partial_symtab *next |
Objfile的所有partial_symtab形成一个链表 |
| Filename、fullname、dirname |
文件名、路径等信息 |
| Struct objfile *objfile |
对应是哪个objfile |
| Struct section_offsets |
Objfile的各个section的offset |
| Textlow、 texthigh |
该file的地址范围 |
| Struct partial_symtab **dependencies |
该file依赖的文件。依赖的意思是在读入本file的symbol之前,要先将dependency的symbol先读入。比如hello.c中include hello.h,那么hello.h的dependency是hello.c,一个文件可能有很多dependency。 |
| Int global_offset, int n_gloabl_syms |
该文件对应的全局符号在objfile->global_psymbols中的偏移和个数 |
| Int static_offst, int n_static_syms |
同上,不过是objfile->static_psymbols |
| Struct symtab *symtab |
该file对应的full symtab |
| Void(*read_symtab)(struct partial_symtab *) |
该函数指针用来根据该pst读取full symtab |
| Void *read_symtab_private |
上述函数建立full symtab需要用到的一些数据 |
| Unsigned char readin |
标识该pst对应的symtab有没有被读入 |
3.1.2 Partial_symtab建立流程
本节介绍读取调试信息,建立partialsymtab的流程。
gdb就可以根据此使用一些file_static和global的符号,进行一些基本的源码级别的调试了。
该过程在gdb将symbol file添加进来的时候进行。不同的objfile格式,实现的函数不一样。针对Elf文件,具体调用函数elf_symfile_read()函数完成。该函数主要做了两件事情:1,读取objfile中.symtab、.dynsym(如果有的话)的符号,建立起minimal symtab;2,读取分析调试信息,建立partial symtab。下面具体分析此流程,流程如下图所示。
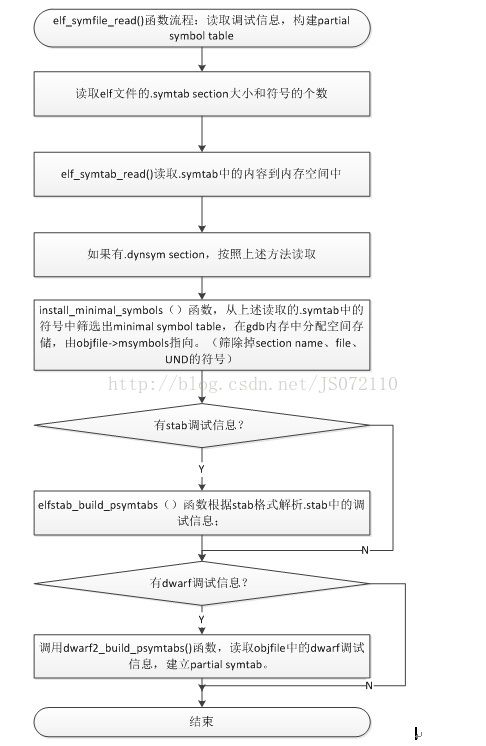
图 3‑1 elf_symfile_read流程
从上述流程图中我们看到会有stab调试信息的部分,这里做一个说明。调试信息分为很多中有dwarf格式、stab格式等。调试信息在gcc将源文件编译成汇编文件时会加入调试信息,而汇编器在将汇编文件汇编成目标文件。汇编器输入的汇编文件分为两类:一类是gcc编译生成的,里面会含有调试信息;另一类是用户hand-write汇编文件,其中不带调试信息。而汇编器也有调试相关参数:-gstatbs和-gdwarf-2,分别用来为汇编文件生成stabs格式和dwarf格式的调试信息。
本文的重点是介绍dwarf调试信息的读取和解析,该过程在dwarf2_build_psymtabs()函数中完成,该函数的基本流程如图2-3,
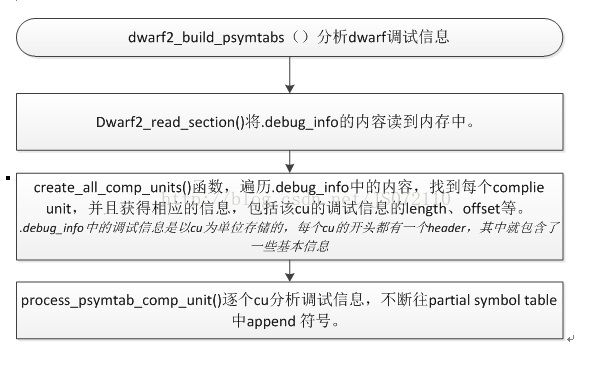
图 3‑2 dwarf2_build_psymtabs函数流程
3.1.3 以cu为单位解析调试信息
Gdb中以cu为单位对调试信息进行分析,建立partial symtab,下面展开具体分析。
通过上述分析可知,首先会把.debug_info中的内容读入到内存中,然后获取每个cu的调试信息的header信息,最后逐个cu来分析.debug_info中的内容,以append的方式建立起partial symbol table。对于dwarf调试信息分析的细节在函数process_psymtab_comp_unit()中,下面到这个函数中跟踪分析
图 3‑3 process_psymtab_comp_unit流程
通过对process_psymtab_comp_unit()的跟踪分析,发现并不会把所有的DIE对应的符号都添加到partialsymbol table中。而是选取了一些file static和global的符号。流程分析中可以看出来,怎么去读取DIE中的信息构建partial symbol的、选取哪些DIE、怎么把symbol添加到list中,这个核心的过程都在load_partial_dies()函数中。接下来跟踪分析这一过程,如图所示。

图 3‑4 load_partial_dies()流程
至此,将该cu的main file的.debug_info中的所有DIE都分析完,选取了合适的加入到partial symbol table中。
但是我们知道,main file中可能include很多file,有header file,也可能是c file。Partial_symtab是一个sourcefile一个的。这里,我们不是为所有的included file都创建一个partial_symtab,而是选取如果该cu行号信息中,有用到该included file(该file中有函数定义),那么就需要为该included file建立一个struct partial_symtab。。那该cu有哪些included files?这些included files有没有在行号信息中用到?这些通过怎样分析得到呢?接下来就要分析.debug_line section的行号信息了。process_psymtab_comp_unit()函数的最后一步调用dwarf2_build_include_psymtabs()完成这个工作。
在分析此函数之前,先简单回顾一下.debug_line中行号信息的格式。行号信息是实现source-level debug的重要部分,完成目标地址和源代码之间的映射关系。.debug_line中的行号信息也是以cu为单位组织存放的,行号信息理论上应该是一张很大的表,每个地址一个表项,记录当前的行号、文件名、路径名等信息。但是为了存储空间的问题,我们将行号信息进行编码,.debug_line中存储的实际上是一系列的编码过的opcode,每个cu的行号信息叫做一个opcode program。每个cu的opcode program之前都会有一个header,这个header记录了一些重要的信息。比如,该cu的行号信息的长度,header的长度,dwarf的版本,以及一些opcode相关的初始信息。此处,我们需要关注的是header中还包含两张表“The Directory Table”和“The File Name Table”。分别记录了该编译单元的include的路径表和included file names表。
下面,跟踪分析dwarf2_build_include_psymtabs()的具体流程,如所示。
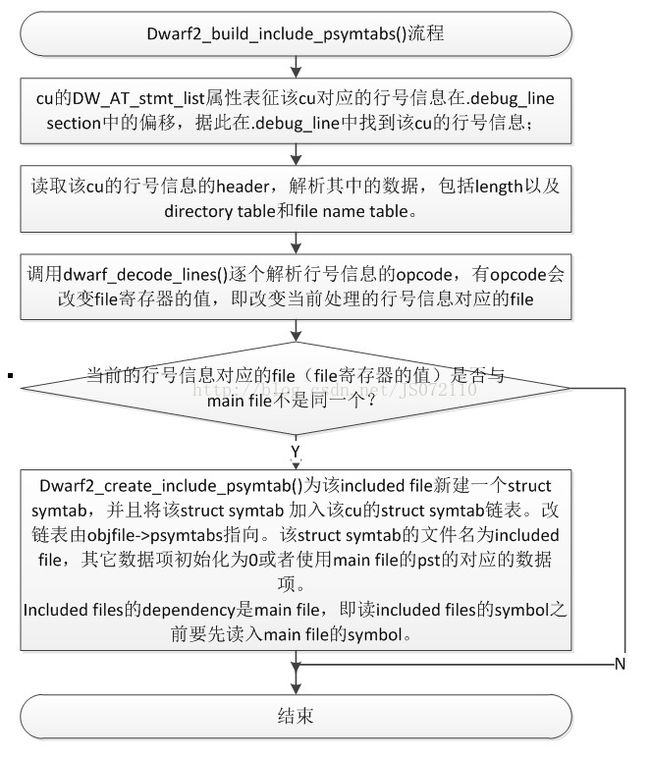
图 3‑5 build include psymtab流程
每个source file一个structpartial_symtab,objfile中维护这么一个链,included file依赖于其main file(dependency可以不止一个)。
至此,根据dwarf调试信息读入partialsymbol table的工作已经完成,在接来下的调试过程中如果需要更多的调试信息,可以根据当前的partial symbol table读入full symbol table。可以根据对应struct partial_symtab的read_symtab()函数指针指向的函数完成full symtab的读入,dwarf2_psymtab_to_symtab()函数。Read_symtab_private指针指向当读入fullsymtab中需要的数据,struct dwarf2_per_cu_data。具体过程在3.2中介绍。
3.2 partial_symtab+dies——full_symtab
Gdb的source-leveldebugging的原理就是符号名、位置、值的处理,这些信息都由symbol提供,gdb的调试过程实质上是对符号的处理,而gdb中维护的symbol信息是从调试信息中解析出来的。在3.1Section中介绍的partial symbol是提取部分调试信息获得的,而调试过程中需要更多的更完整的符号信息时,我们就需要获取full symbol table。Full symtab是partial symtab的扩展,符号的信息更全,添加的符号也更多。同样的,full symtab也是以source file为单位的。下面举例介绍。
3.2.1 When is full_symtab needed?
Gdb调试过程中最常见的操作是设置断点,比如 “break main”,那么我们需要知道字符串main对应的symbol,进而知道该symbol的location,那么我们就可以在这个位置placebreakpoint了。那么我们现在已知的条件是:1,main字符串、2,当前的pc、3,一堆待解析的调试信息,下面开始整个使用调试信息建立symbol的流程。

在本例中,分析的是dwarf和stabs调试信息格式混用的情况,汇编器对于用户输入的汇编文件,使用stabs调试信息(至少有行号信息)。第一个编译单元是stabs的格式,而要查找的main并不在该编译单元中,所以需要global symbol查找,然后根据psymtab_to_symtab(pst)读入main符号所在cu的full symtab。
3.2.2 Full_symtab 建立流程
Psymtab_to_symtab(pst)是一个函数接口,根据不同格式的调试信息会调用不同的函数实现。Here,dwarf2_psymtab_to_symtab()函数来实现该过程。下面具体分析这个fullsymtab的读入过程。
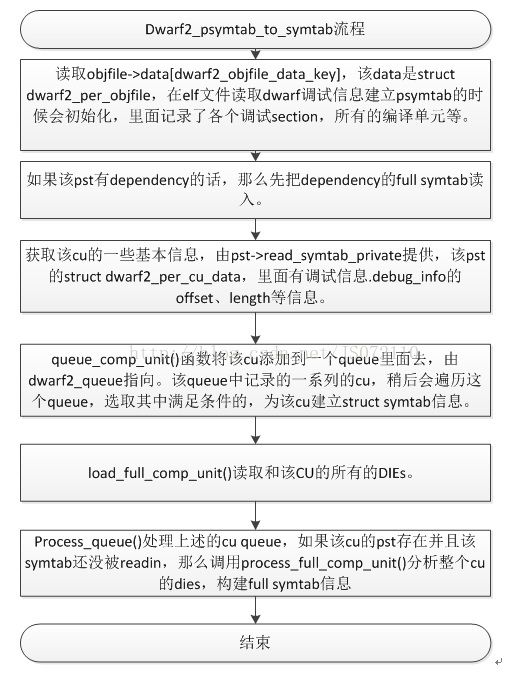
图 3‑6 psymtab_to_symtab流程
简要描述该流程就是:根据pst找到cu,读取cu的所有的dies,根据读入的dies构建该cu的full symtab。现在我们关注后两步,怎么读取所有的dies,以及怎样根据读入的cu的dies构建好full symtab。
3.2.2.1 Full dies的读入
首先,考察一下如何读入这个cu的所有的dies,如图所示
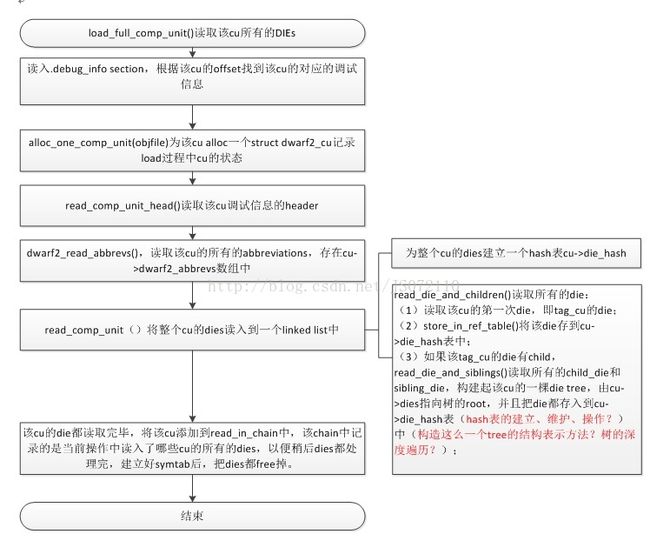
图 3‑7 full调试信息dies的读入
该部分的逻辑很简答,就是根据die存储的逻辑结构,把该cu的所有的die从.debug_info中读出来,然后构建出这个一个die tree,存储在内存中。
3.2.2.2 分析dies,构建full symtab
现在我们获取了整个cu的所有的dies,那么接下来分析这些调试信息,为该cu构建好full symtab。该部分工作由函数process_full_comp_unit()完成,该函数的流程如图所示。

图 3‑8分析dies流程
该流程包括三个步骤,一个是建立symtab之前的初始化工作,一个是对调试信息die的处理建立symtab,最后是一些善后工作。在初始化过程中看到的几个全局变量做一一说明,如下表所示。
表格3‑4 full_symtab构建相关全局变量说明
| 变量名 |
说明 |
| File_symbols |
是struct pending结构,用来记录symbols Gdb中有三个list,分别是File_symbols、global_symbols、local_symbols,分别用来记录file static、global和local的符号。在建立symtab的过程中cu->list_in_scope list指示当前符号要加入到哪个list中。 |
| Global_symbols |
|
| Local_symbols |
|
| Pending_blocks |
该全局变量指向一个链表,链表将整个cu的所有的scope block,通常一个函数对应一个block的链表。 |
| Pending_macros |
全局变量,struct marco_table记录该cu的宏信息,包括用来存储宏信息的空间、该cu的main_file,macro definition的table,以splay tree的方式存储。该tree的节点的key是宏的name,该tree的节点的value是该宏的参数列表(如果是宏函数的话)和该宏的replacement。 |
该流程的核心是process_die(),该函数是一个switch函数体,针对不同TAG的die,采取不同的处理方式。先总体介绍一下对不同的die的处理函数。如下表所示。
表格3‑5 不同类型die的处理
| Die类型 |
处理函数 |
说明 |
| DW_TAG_compile_unit |
read_file_scope() |
该函数比较复杂,下面会具体介绍 |
| DW_TAG_base_type,DW_TAG_subrange_type,DW_TAG_typedef |
new_symbol() |
是否要为该die生成一个symbol,并将该symbol添加到cu->list_in_scope list中。 |
| DW_TAG_enumeration_type |
process_enumeration_scope() |
为enumerator的die创建symbol,并添加到相应的list中。 |
| DW_TAG_subprogram DW_TAG_inlined_subroutine |
read_func_scope() |
●将该函数加入到cu的func list中,创建symbol,并且添加到相应的list中。 ●如果有DW_AT_frame_base,那么解析该属性,那么调用dwarf2_symbol_mark_computed()函数,计算value,并且将该属性的data、size等信息放入struct symbol->aux_value中,并且初始化struct symbol->ops_computed=dwarf2_locexpr_funcs。 ●将cu->list_in_scope设置为local_symbols,将该函数的child_die()都调用process_die()进行处理,创建symbol,添加到cu->list_in_scope中去(对于inline 函数的abstract instance tree和concrete instance tree?)。 ●调用finish_block()函数,为该函数的创建一个block,并且将block添加到全局变量pending_blocks指向的链表中。流程见图 ●如果处理完了top-level function后,将cu->list_in_scope设置回file_symbols. |
| DW_TAG_class_type,DW_TAG_interface_type,DW_TAG_structure_type,DW_TAG_union_type |
process_structure_scope() |
structure的member die不会被加入到symbol list中,为什么? |
| subroutine_type, set_type, array_type, pointer_type, ptr_to_member_type, reference_type, string_type |
无 |
process不进行任何操作,这些类型的DIE仅仅描述的是类型信息,并不代表实际的object,所以不需要为他们创建一个symbol,并且添加到symbol list中。同样的,也不需要处理它们的children。当process这些类型的variable的时候,可以根据需要在读取variable的DW_AT_type的时候,调用read_type_die()函数读取。 |
| Default |
new_symbol() |
判断是否要为该die生成一个symbol,并将该symbol添加到cu->list_in_scope list中。 |
下面是对DW_TAG_subprogramdie处理时,为function建立block的流程,该cu中的所有block会组成一个链表,由pending_blocks全局变量指
图 3‑9 为function建立block
Process_die()函数用来处理参数指定的die及其child,首先处理的是tag_cu的die,然而该cu的所有的die都是tag_cu的die的children。所以在过程中会递归调用process_die()函数把该cu的其它的dies也处理掉。那么我们查看下对tag_cudie的处理函数read_file_scope()函数的流程。

图 3‑10 read_file_scope()流程
可以看到process_die()函数流程走完,该cu的所有的die都会被处理,这时候相应的symbol都已经建立并且记录下来了,行号信息也解析读取了,宏信息也相应的解析了。至此调试信息的分析工作大部分已经完成。
上述流程图中把symbols的建立以及行号信息的分析详细介绍了,下面单独介绍一下宏信息的解析。宏信息放在.debug_macinfo section中,也是以cu为单位存放的,但是只有一系列的entry,没有为每个cu建立一个宏信息的header,在DW_TAG_complile_unit中会有DW_AT_macro_info属性表征该cu的宏信息在.debug_macinfo中的字节偏移。宏信息的格式很简单。
在开始分析宏信息的解析流程之前,我们先了解下gdb中几个在宏信息解析中重要的数据结构,如下表所示。
表格3‑6 宏信息相关数据结构
| 数据结构 |
说明 |
| struct macro_table |
该数据结构对应一个cu,用来描述该cu的macro_table,里面包含cu的文件名,宏的存储树等。 |
| struct macro_definition |
一个宏对应一个该数据结构,包括该宏的name以及参数和replacement。 |
| struct macro_source_file |
在宏信息描述中用来表征一个文件,包括main_file和included_file。包括文件名、对应的macro_table等信息。特别说明下,该数据结构会表征当前文件的parent_file,以及在parent_file中被include的行号位置,以及该parent_file的下一个子file,即sibling。Plus,还会记录该file的子files。 因为宏信息中,file的include的关系也是一个树形关系。这样使用该数据结构能够很好的描述这样一个关系。 |
数据结构背景介绍完成之后,下面开始宏信息的分析流程,如下图所示,
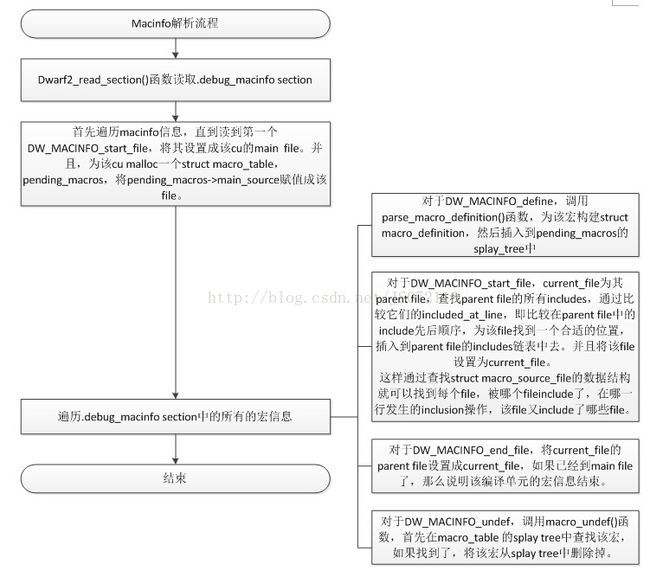
图 3‑11 宏信息解析流程图
宏信息的entry中无非就是四类操作,文件的开始,文件的结束,宏的define,宏的undefine。该cu的宏信息解析完成后,我们最后得到的是一个macro_table,里面包含了宏的splay tree,file的inclusion tree。该macro_table由全局变量pending_macros指向。
Prcess_die()的流程至此结束,symtab建立的流程只剩下最后一步,symtab_end()来完成最后的一些信息收集和扫尾工作。如下图所示,

图 3‑12 end_symtab()流程图
至此该cu的full symtab就已经完全建立,为对该cu的调试提供了完整的信息。