apache arrow_Apache Arrow和Java:闪电般的大数据传输速度
apache arrow
重要要点
- Arrow为分析应用程序提供零拷贝数据传输
- Arrow启用内存,列格式和数据处理
- Arrow是跨平台,跨语言可互操作的数据交换
- Arrow是大数据系统的骨干
从本质上讲,大数据太大,无法容纳在一台计算机上。 数据集需要在多台计算机上分区。 每个分区都分配给一台主机,并带有可选的备份分配。 因此,每台机器都拥有多个分区。 大多数大数据框架使用随机策略为计算机分配分区。 如果每个计算作业都使用一个分区,则此策略会导致整个群集上的计算负载很好地分散。 但是,如果作业需要多个分区,则很有可能需要从其他计算机上获取分区。 传输数据始终会降低性能。
Apache Arrow提出了一种跨语言,跨平台,列式内存中数据的数据格式。 由于每个平台和编程语言上的数据均由相同的字节表示,因此无需序列化。 这种通用格式支持在大数据系统中进行零拷贝数据传输,以最大程度地降低传输数据的性能影响。
本文的目的是介绍Apache Arrow ,并使您熟悉Apache Arrow Java库的基本概念。 本文随附的源代码可在此处找到。
通常, 数据传输包括:
- 以某种格式序列化数据
- 通过网络连接发送序列化数据
- 在接收端反序列化数据
例如,考虑一下Web应用程序中前端与后端之间的通信。 通常,JavaScript对象表示法(JSON)格式用于序列化数据。 对于少量数据,这是完全可以的。 序列化和反序列化的开销可以忽略不计,JSON是人类可读的,从而简化了调试。 但是,当数据量增加时,序列化成本可能成为主要的性能因素。 如果没有适当的护理,系统可以最终花费大部分时间seriali的 ž ING数据 。 显然,我们的CPU周期还有更多有用的事情要做。

在此过程中,我们在软件中控制一个因素:(反序列化)。 不用说,那里有大量的序列化框架。 考虑一下ProtoBuf,Thrift,MessagePack等。 其中许多人将最小化序列化成本作为主要目标。
尽管他们努力最小化序列化,但仍然不可避免地要进行(反序列化)步骤。 您的代码所作用的对象不是通过网络发送的字节。 通过导线接收到的字节不是另一侧处理代码的对象。 最后, 最快的序列化是没有序列化 。
是Apache Arrow吗?
从概念上讲, Apache Arrow被设计为大数据系统 (例如Ballista或Dremio )或大数据系统集成 的骨干 。 如果您的用例不在大数据系统领域,那么Apache Arrow的开销可能不值得您烦恼。 拥有广泛采用行业的序列化框架,例如ProtoBuf,FlatBuffers,Thrift,MessagePack或其他,可能会更好。
在没有Java对象的意义上,使用Apache Arrow进行编码与使用普通的旧Java对象进行编码非常不同。 代码一直对缓冲区进行操作。 现有的实用程序库,例如Apache Commons,Guava等,不再可用。 您可能必须重新实现某些算法才能使用字节缓冲区。 最后但并非最不重要的一点是,您始终必须考虑列而不是对象。
在Apache Arrow之上构建系统需要您读取,编写,呼吸和消耗Arrow缓冲区。 如果您要构建一个可以处理数据对象集合 (即某种数据库)的系统,并且想要计算对列友好的东西,并计划在集群中运行它,那么Arrow绝对值得投资。
与Parquet的集成(稍后讨论)使持久性相对容易。 跨平台,跨语言方面支持多语言微服务架构,并允许与现有的大数据环境轻松集成。 内置的称为Arrow Flight的RPC框架使以标准化,高效的方式共享/提供数据集变得容易。
零拷贝数据传输
为什么我们首先需要序列化? 在Java应用程序中,通常使用对象和原始值。 这些对象以某种方式映射到计算机RAM内存中的字节。 JDK了解如何将对象映射到计算机上的字节。 但是此映射在另一台计算机上可能有所不同。 例如,考虑字节顺序(又称字节顺序)。 而且,并非所有的编程语言都具有相同的原始类型集,甚至没有以相同的方式存储相似的类型。
序列化将对象使用的内存转换为通用格式 。 该格式有一个规范 ,并且为每种编程语言和平台提供了一个库,用于将对象转换为序列化形式并返回。 换句话说,序列化就是关于共享数据的,而不会破坏每种编程语言和平台的特有方式。 序列化可消除平台和编程语言中的所有差异,从而使每个程序员都能按自己喜欢的方式工作。 就像翻译员可以消除说不同语言的人们之间的语言障碍。
在大多数情况下,序列化是非常有用的事情。 但是,当我们传输大量数据时,它将成为一个很大的瓶颈。 因此,在这种情况下,我们可以消除序列化过程吗? 这实际上是零拷贝序列化框架 (例如Apache Arrow和FlatBuffers)的目标。 您可以将其视为处理序列化数据本身而不是处理对象,以避免序列化步骤。 零拷贝是指您的应用程序所处理的字节无需修改即可通过电线传输的事实。 同样,在接收端,应用程序可以按原样开始处理字节,而无需反序列化步骤。
这里的最大优点是, 数据可以在连接的两侧按原样从一个环境传输到另一环境,而无需任何转换,因为数据被理解为原样。
主要缺点是编程中失去特质。 所有操作都在字节缓冲区上执行 。 没有整数,有字节序列。 没有数组,有字节序列。 没有对象,有字节序列的集合。 当然,您仍然可以将通用格式的数据转换为整数,数组和对象。 但是,那时您将要进行反序列化,这将破坏零复制的目的。 一旦传输到Java对象,则只有Java才能处理数据。

在实践中这是如何工作的? 让我们快速看一下两个零复制序列化框架:Apache的Apache Arrow和FlatBuffers 。 尽管两者都是零拷贝框架,但是它们是针对不同用例的不同口味。
FlatBuffers最初是为了支持手机游戏而开发的。 重点在于以最小的开销将数据从服务器快速传输到客户端。 您可以发送单个对象或对象集合。 数据存储在(在堆中)ByteBuffer中,格式为FlatBuffers通用数据布局。 FlatBuffers编译器将根据数据规范生成代码,从而简化您与ByteBuffers的交互。 您可以像处理数组,对象或图元一样处理数据。 在后台,每个访问器方法都获取相应的字节并将字节转换为JVM和您的代码可理解的构造。 如果出于某种原因需要访问字节,仍然可以。
Arrow与FlatBuffers的区别在于它们在内存中布置列表/数组/表的方式。 FlatBuffers对表使用面向行的格式,而Arrow使用列式格式存储表格数据。 这使得对大数据集的分析(OLAP)查询产生了很大的不同。
Arrow针对的是大数据系统,在该系统中,您通常不传输单个对象,而是传输大量对象。 另一方面,FlatBuffers作为序列化框架销售(使用)。 换句话说,您的应用程序代码适用于Java对象和基元,并且仅在发送数据时将数据转换为FlatBuffers的内存布局。 如果接收方是只读的,则它们不必将数据反序列化为Java对象,则可以直接从FlatBuffers的ByteBuffers中读取数据。
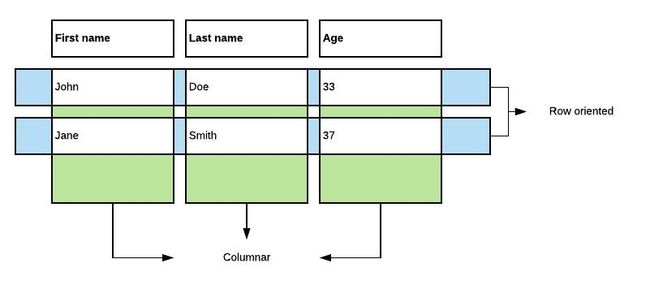
在大型数据集中,行数通常可以从数千行到数万亿行。 这样的数据集可能有几列到数千列。
对此类数据集的典型分析查询仅引用了少数列。 想象一下例如电子商务交易的数据集。 您可以想象一个销售经理想要按项目类别分组的特定区域的销售概览。 他不想看到每笔交易。 平均销售价格就足够了。 这样的查询可以通过三个步骤来回答:
- 遍历“区域”列中的所有值,并跟踪请求区域中所有销售的行/对象ID
- 根据项目类别列中的相应值对过滤后的ID进行分组
- 计算每个组的聚合
本质上,查询处理器在任何给定时间只需要在内存中有一列。 通过以列格式存储集合,我们可以分别访问单个字段/列的所有值。 在精心设计的格式中,可以通过针对CPU的SIMD指令优化布局的方式来完成此操作。 对于此类分析工作负载,Apache Flat列式布局比FlatBuffers面向行的布局更适合。
阿帕奇箭
Apache Arrow的核心是内存中的数据布局格式 。 除此格式外,Apache Arrow还提供了一组库(包括C,C ++,C#,Go,Java,JavaScript,MATLAB,Python,R,Ruby和Rust),以使用Apache Arrow格式的数据。 本文的其余部分是要熟悉Arrow的基本概念,以及如何使用Apache Arrow编写Java应用程序。
基本概念
向量架构根
假设我们正在建模连锁商店的销售记录。 通常,您会遇到一个代表销售的对象。 这样的对象将具有各种属性,例如
- 一个ID
- 有关进行销售的商店的信息,例如地区,城市,也许还有商店的类型
- 一些客户信息
- 所售商品的编号
- 所售商品的类别(可能是子类别)
- 卖了多少商品
- 等等…
在Java中,销售由Sale类建模。 该类包含单个销售的所有信息。 所有销售都由Sale对象的集合表示(在内存中)。 从数据库角度来看,Sale对象的集合等效于面向行的关系数据库。 实际上,通常在这样的应用程序中,对象的集合被映射到数据库中的关系表以实现持久性。
在面向列的数据库中,对象的集合分解为列的集合。 所有ID都存储在单个列中。 在内存中,所有ID都按顺序存储。 同样,有一列用于存储每次销售的所有商店城市。 从概念上讲,这种柱状格式可以认为是将对象集合分解为一组等长数组。 对象中每个字段一个数组。
为了重建特定对象,可通过在给定索引处选取每个列/数组的值来组合分解数组。 例如,通过获取id数组的第10个值,商店城市数组的第10个值等来重组第10次销售。
Apache Arrow的工作方式类似于面向列的关系数据库。 Java对象的集合被分解为列的集合,这些列在Arrow中称为向量。 向量是“箭头”列格式的基本单位。
所有向量的母亲是FieldVector。 存在用于原始类型的向量类型,例如Int4Vector和Float8Vector。 字符串有一个向量类型:VarCharVector。 任意二进制数据都有一个向量类型:VarBinaryVector。 存在几种类型的向量来建模时间,例如TimeStampVector,TimeStampSecVector,TimeStampTZVector和TimeMicroVector。
可以组成更复杂的结构。 StructVector用于将一组向量分组为一个字段。 例如,考虑上面的销售示例中的商店信息。 所有商店信息(地区,城市和类型)都可以组合在一个StructVector中。 ListVector允许在一个字段中存储可变长度的元素列表。 MapVector将键值映射存储在一个向量中。
继续数据库的类比,用表表示对象的集合。 为了标识表中的值,表具有一个架构:类型映射的名称。 在面向行的数据库中,每一行将名称映射到预定义类型的值。 在Java中,模式对应于类定义的成员变量集。 面向列的数据库同样具有架构。 在表中,架构中的每个名称都映射到预定义类型的列。
在Apache Arrow术语中,向量的集合由VectorSchemaRoot表示。 VectorSchemaRoot还包含一个架构,将名称(aka Fields )映射到列(aka Vectors )。
缓冲区分配器
我们添加到向量中的值存储在哪里? 箭头向量由缓冲区支持。 通常,这是一个java.nio.ByteBuffer。 缓冲区在缓冲区分配器中池化。 您可以要求缓冲区分配器创建一定大小的缓冲区,也可以让缓冲区分配器负责缓冲区的创建和自动扩展以存储新值。 缓冲区分配器跟踪所有已分配的缓冲区。
向量由一个分配器管理。 我们说分配器拥有支持向量的缓冲区。 向量所有权可以从一个分配器转移到另一个分配器。
例如,您正在实现数据流。 该流程包含一系列处理阶段。 在将数据传递到下一阶段之前,每个阶段都会对数据进行一些操作。 每个阶段都有自己的缓冲区分配器,用于管理当前正在处理的缓冲区。 处理完成后,数据将进入下一个阶段。
换句话说,支持向量的缓冲区的所有权被转移到下一级的缓冲区分配器。 现在,该缓冲区分配器负责管理内存并在不再需要内存时将其释放。
分配器创建的缓冲区是DirectByteBuffers,因此它们是堆外存储的。 这意味着使用完数据后,必须释放内存。 刚开始对Java程序员来说,这感觉很奇怪。 但这是使用Apache Arrow的重要组成部分。 向量实现AutoCloseable接口,因此,建议将向量创建包装在try-with-resources块中,该块将自动关闭向量,即释放内存。
示例:写作,阅读和处理
结束本文的介绍,我们将逐步介绍一个使用Apache Arrow的示例应用程序。 这个想法是从磁盘上的文件中读取人员的“数据库”,过滤和聚合数据,然后打印出结果。
请注意,Apache Arrow是内存格式。 在实际的应用程序中,最好使用针对持久存储进行了优化的其他(列)格式,例如Parquet 。 Parquet将压缩和中间摘要添加到写入磁盘的数据中。 因此,从磁盘读取和写入Parquet文件应该比读取和写入Apache Arrow文件更快。 在此示例中,箭头仅用于教育目的。
假设我们有一个Person类和一个Address类(仅显示相关部分):
public Person(String firstName, String lastName, int age, Address address) {
this.firstName = firstName;
this.lastName = lastName;
this.age = age;
this.address = address;
}
public Address(String street, int streetNumber, String city, int postalCode) {
this.street = street;
this.streetNumber = streetNumber;
this.city = city;
this.postalCode = postalCode;
}我们将编写两个应用程序。 第一个应用程序将生成一个随机生成的人员的集合,并将其以箭头格式写入磁盘。 接下来,我们将编写一个应用程序,该应用程序以箭头格式从磁盘读取“人员数据库”到内存。 选择所有人
- 姓氏以“ P”开头
- 年龄在18至35岁之间
- 住在以“ way”结尾的街道
对于选定的人,我们计算每个城市分组的平均年龄。 该示例应该使您对如何使用Apache Arrow实施内存中数据分析有一些看法。
此示例的代码可以在此Git存储库中找到。
写数据
在我们开始写数据之前。 请注意,“箭头”格式针对的是内存中数据。 尚未针对磁盘数据存储进行优化。 在实际的应用程序中,您应该研究诸如Parquet之类的格式,该格式支持压缩和其他技巧以加快磁盘上列数据的存储,从而持久保存数据。 在这里,我们将以箭头格式写出数据,以使讨论重点和简短。
给定一个Person对象数组,让我们开始将数据写到一个名为people.arrow的文件中。 第一步是将Person对象的数组转换为Arrow VectorSchemaRoot。 如果您真的想充分利用Arrow,可以编写整个应用程序以使用Arrow向量。 但是出于教育目的,在此处进行转换很有用。
private void vectorizePerson(int index, Person person, VectorSchemaRoot schemaRoot) {
// Using setSafe: it increases the buffer capacity if needed
((VarCharVector) schemaRoot.getVector("firstName")).setSafe(index, person.getFirstName().getBytes());
((VarCharVector) schemaRoot.getVector("lastName")).setSafe(index, person.getLastName().getBytes());
((UInt4Vector) schemaRoot.getVector("age")).setSafe(index, person.getAge());
List childrenFromFields = schemaRoot.getVector("address").getChildrenFromFields();
Address address = person.getAddress();
((VarCharVector) childrenFromFields.get(0)).setSafe(index, address.getStreet().getBytes());
((UInt4Vector) childrenFromFields.get(1)).setSafe(index, address.getStreetNumber());
((VarCharVector) childrenFromFields.get(2)).setSafe(index, address.getCity().getBytes());
((UInt4Vector) childrenFromFields.get(3)).setSafe(index, address.getPostalCode());
} 在vectorizePerson中,将Person对象映射到带有person模式的schemaRoot中的向量。 setSafe方法确保后备缓冲区足够大以容纳下一个值。 如果后备缓冲区不够大,则将扩展缓冲区。
VectorSchemaRoot是架构和向量集合的容器。 这样,类VectorSchemaRoot可以被认为是无模式数据库,只有在对象实例化时在构造函数中传递模式时,模式才是已知的。 因此,所有方法(例如getVector)都具有非常通用的返回类型,在这种情况下为FieldVector。 结果,需要基于模式或数据集的知识进行大量转换。
在此示例中,我们可以选择预分配UInt4Vectors和UInt2Vector(因为我们预先知道一批中有多少人)。 然后我们可以使用set方法来避免缓冲区大小检查和重新分配以扩展缓冲区。
可以将vectorizePerson函数传递给ChunkedWriter,ChunkedWriter是处理分块并写入Arrow格式的二进制文件的抽象。
void writeToArrowFile(Person[] people) throws IOException {
new ChunkedWriter<>(CHUNK_SIZE, this::vectorizePerson).write(new File("people.arrow"), people);
}
The ChunkedWriter has a write method that looks like this:
public void write(File file, Person[] values) throws IOException {
DictionaryProvider.MapDictionaryProvider dictProvider = new DictionaryProvider.MapDictionaryProvider();
try (RootAllocator allocator = new RootAllocator();
VectorSchemaRoot schemaRoot = VectorSchemaRoot.create(personSchema(), allocator);
FileOutputStream fd = new FileOutputStream(file);
ArrowFileWriter fileWriter = new ArrowFileWriter(schemaRoot, dictProvider, fd.getChannel())) {
fileWriter.start();
int index = 0;
while (index < values.length) {
schemaRoot.allocateNew();
int chunkIndex = 0;
while (chunkIndex < chunkSize && index + chunkIndex < values.length) {
vectorizer.vectorize(values[index + chunkIndex], chunkIndex, schemaRoot);
chunkIndex++;
}
schemaRoot.setRowCount(chunkIndex);
fileWriter.writeBatch();
index += chunkIndex;
schemaRoot.clear();
}
fileWriter.end();
}
}让我们分解一下。 首先,我们创建一个(i)分配器,(ii)schemaRoot和(iii)dictProvider。 我们需要它们(i)分配内存缓冲区,(ii)是向量的容器(由缓冲区支持),以及(iii)促进字典压缩(您现在可以忽略它)。
接下来,在(2)中创建一个ArrowFileWriter。 它基于VectorSchemaRoot处理写入磁盘。 批量写出数据集很容易。 最后但并非最不重要的一点是,不要忘记启动编写器。
该方法的其余部分是关于将Person数组按块矢量化到矢量模式根中,然后逐批写出。
分批编写有什么好处? 在某些时候,将从磁盘读取数据。 如果将数据分批写入,则必须一次读取所有数据并将其存储在主存储器中。 通过编写批处理,我们允许读取器以较小的块处理数据,从而限制了内存占用。
永远不要忘记设置向量的值计数或向量模式根的行计数(间接设置所有包含的向量的值计数)。 如果不设置计数,即使将值存储在向量中,向量也将显示为空。
最后,当所有数据都存储在向量中时,fileWriter.writeBatch()会将它们提交到磁盘。
有关内存管理的说明
请注意第(3)和(4)行上的schemaRoot.clear()和allocator.close()。 前者清除VectorSchemaRoot中包含的所有向量中的所有数据,并将行和值计数重置为零。 后者关闭分配器。 如果您忘记释放所有已分配的缓冲区,则此调用将通知您内存泄漏。
在此设置下,关闭有点多余,因为程序在分配器关闭之后不久退出。 但是,在真实的,长期运行的应用程序中,内存管理至关重要。
对于Java程序员而言,内存管理问题将变得陌生。 但是在这种情况下,这是为性能付出的代价。 要特别注意分配的缓冲区,并在其生命周期结束时释放它们。
读取数据
从Arrow格式的文件中读取数据类似于写入。 您设置了一个分配器,一个矢量模式的根(不带模式,它是文件的一部分),打开一个文件,然后让ArrowFileReader负责其余的工作。 不要忘记初始化,因为这将从文件中读取Schema。
要读取批处理,请调用fileReader.loadNextBatch()。 从磁盘读取下一批(如果仍然可用),并且schemaRoot中的向量缓冲区将填充数据,准备进行处理。
以下代码段简要描述了如何读取Arrow文件。 对于while循环的每次执行,都会将一个批处理加载到VectorSchemaRoot中。 批处理的内容由VectorSchemaRoot描述:(i)VectorSchemaRoot的架构,以及(ii)值计数,等于条目数。
try (FileInputStream fd = new FileInputStream("people.arrow");
ArrowFileReader fileReader = new ArrowFileReader(new SeekableReadChannel(fd.getChannel()), allocator)) {
// Setup file reader
fileReader.initialize();
VectorSchemaRoot schemaRoot = fileReader.getVectorSchemaRoot();
// Aggregate: Using ByteString as it is faster than creating a String from a byte[]
while (fileReader.loadNextBatch()) {
// Processing …
}
}处理数据
最后但并非最不重要的一点是,过滤,分组和聚合步骤应该使您了解如何在数据分析软件中使用Arrow向量。 我绝对不想假装这是使用Arrow向量的方式,但是它应该为探索Apache Arrow提供坚实的起点。 查看用于实际箭头代码的Gandiva处理引擎的源代码。 使用Apache Arrow进行数据处理是一个大话题。 您可以从字面上写一本书 。
请注意,示例代码是针对Person用例的。 例如,在构建带有Arrow向量的查询处理器时,事先不知道向量名称和类型,从而导致更通用,更难理解的代码。
由于Arrow是列格式,因此我们可以仅使用一列就可以独立应用过滤步骤。
private IntArrayList filterOnAge(VectorSchemaRoot schemaRoot) {
UInt4Vector age = (UInt4Vector) schemaRoot.getVector("age");
IntArrayList ageSelectedIndexes = new IntArrayList();
for (int i = 0; i < schemaRoot.getRowCount(); i++) {
int currentAge = age.get(i);
if (18 <= currentAge && currentAge <= 35) {
ageSelectedIndexes.add(i);
}
}
ageSelectedIndexes.trim();
return ageSelectedIndexes;
}此方法收集年龄向量的已加载块中所有索引,其值在18到35之间。
每个过滤器都会生成此类索引的排序列表。 在下一步中,我们将这些列表相交/合并到选定索引的单个列表中。 该列表包含满足所有条件的行的所有索引。
下一个代码片段显示了如何从向量和选定ID的集合轻松填充聚合数据结构(将城市映射为计数和总和)。
VarCharVector cityVector = (VarCharVector) ((StructVector) schemaRoot.getVector("address")).getChild("city");
UInt4Vector ageDataVector = (UInt4Vector) schemaRoot.getVector("age");
for (int selectedIndex : selectedIndexes) {
String city = new String(cityVector.get(selectedIndex));
perCityCount.put(city, perCityCount.getOrDefault(city, 0L) + 1);
perCitySum.put(city, perCitySum.getOrDefault(city, 0L) + ageDataVector.get(selectedIndex));
}填写汇总数据结构后,很容易打印出每个城市的平均年龄:
for (String city : perCityCount.keySet()) {
double average = (double) perCitySum.get(city) / perCityCount.get(city);
LOGGER.info("City = {}; Average = {}", city, average);
}结论
本文介绍了Apache Arrow,这是一种列式,内存中,跨语言的数据布局格式。 它是大数据系统的基础,着重于集群中机器之间以及不同大数据系统之间的高效数据传输。 为了开始使用Apache Arrow开发Java应用程序,我们看了两个示例应用程序,它们以Arrow格式写入和读取数据。 我们还首先使用Apache Arrow Java库来处理数据。
Apache Arrow是一种列式格式。 面向列的布局通常比面向行的布局更适合分析工作负载。 但是,总会有权衡取舍。 对于您的特定工作负载,面向行的格式可能会带来更好的结果。
VectorSchemaRoots,缓冲区和内存管理看起来像您惯用的Java代码。 如果可以从不同的框架(例如FlatBuffers)中获得所需的所有性能,那么较少惯用的工作方式可能会在您决定在应用程序中采用Apache Arrow时发挥作用。
翻译自: https://www.infoq.com/articles/apache-arrow-java/?topicPageSponsorship=c1246725-b0a7-43a6-9ef9-68102c8d48e1
apache arrow