适用于 Java 开发人员的微服务:监视和警报
1.简介
在本教程的最后部分中,我们将讨论将所有可观察性Struts融合在一起的主题:监视和警报。 对于许多人来说,该主题严格地属于操作,并且您知道它以某种方式起作用的唯一方法是在待命中并被吸引时。
目录
1.简介
2.监测和预警哲学
3.基础架构监控
4.应用监控
4.1。 普罗米修斯和警报经理
4.2。 滴答堆栈:Chronograf
4.3。 Netfix图集
4.4。 鹰形
4.5。 舞台监控器
4.6。 格拉法纳
4.7。 自适应警报
5.编排
6.云
7.无服务器
8.警报不仅涉及指标
9.结论
10.最后
我们讨论的目的是至少使监视的某些方面神秘化,了解警报,并了解如何使用指标 , 分布式跟踪甚至有时甚至日志来持续观察系统状态并通知即将发生的问题,异常,潜在的中断或行为异常。
2.监测和预警哲学
在运行或多或少切合实际的软件系统时,可以(并且应该)收集大量不同的度量标准 ,其特殊性是根据微服务架构原理设计的。 在这种情况下,用于收集和存储这种状态数据的过程通常称为监视。
那么,您到底应该监视什么? 公平地说,要预先了解系统的所有可能方面,并且决定要收集哪些指标 (和其他信号)而不必收集哪些指标 ,这并不容易,但是“多多有多”的黄金法则在这里肯定适用。 最终目标是,当出现问题时,监视子系统应立即通知您。 这就是警报的全部内容。
警报消息(或警报通知)是重要的或时间敏感的人机通信。
https://zh.wikipedia.org/wiki/Alert_messaging
显然,您可以发出任何警报,但是在定义自己的警报时,建议您遵循某些规则。 这些出色的文章总结了有关警报哲学的最佳摘要,这是Netflix的 警报哲学和Rob Ewaschuk的《 关于警报的我的哲学》 。 请尝试寻找时间来浏览这些资源,其中提供的见解是无价的。
总结一些最佳实践,当警报触发时,应该很容易理解原因,因此,使警报规则尽可能简单是一个好主意。 警报触发后,应通知某人并进行调查。 因此,警报应指示出真正的原因,是可行的和有意义的,应不惜一切代价避免产生嘈杂的警报(无论如何,它们都将被忽略)。
最后但并非最不重要的一点是,无论您收集了多少个指标,配置了多少个仪表板和警报,总会有一些遗漏。 请认为此过程是一项持续改进,请定期重新评估您的监视,日志记录,分布式跟踪,指标收集和警报决策。
3.基础架构监控
对基础结构组件和层的监视在某种程度上已解决。 从开源的角度来看,像Nagios , Zabbix , Riemann , OpenNMS和Icinga之类的知名公司正在那里统治,您的运营团队很可能已经押注其中之一。
4.应用监控
基础架构当然属于“必须监视”类别,但是可以说监视的应用程序方面更加有趣,并且更接近主题。 因此,让我们直接进行对话。
4.1 Prometheus和Alertmanager
我们已经讨论过Prometheus ,主要是作为指标存储,但事实是它还包含称为AlertManager的警报组件,可以使它回来。
该 AlertManager 把手警报发送客户端应用程序,如普罗米修斯服务器。 它负责将重复数据删除,分组和路由到正确的接收者集成,例如电子邮件,PagerDuty或OpsGenie。 它还负责沉默和禁止警报。 – https://prometheus.io/docs/alerting/alertmanager/
实际上, AlertManager是一个独立的二进制进程,用于处理Prometheus服务器实例发送的警报。 由于JCG租车平台选择了 Prometheus作为指标和监视平台,因此也成为管理警报的合理选择。
基本上,有几个步骤可以遵循。 该过程包括配置和运行AlertManager实例,配置Prometheus与该AlertManager实例进行对话以及最终在Prometheus中定义警报规则。 一次迈出一步,让我们首先开始使用AlertManager配置。
global:
resolve_timeout: 5m
smtp_smarthost: 'localhost:25'
smtp_from: '[email protected]'
route:
receiver: 'jcg-ops'
group_wait: 30s
group_interval: 5m
repeat_interval: 1h
group_by: [cluster, alertname]
routes:
- receiver: 'jcg-db-ops'
group_wait: 10s
match_re:
service: postgresql|cassandra|mongodb
receivers:
- name: 'jcg-ops'
email_configs:
- to: '[email protected]'
- name: 'jcg-db-ops'
email_configs:
- to: '[email protected]'如果我们将此配置代码段提供给AlertManager进程(通常通过将其存储在alertmanager.yml ),则它应该成功启动,并将其Web前端暴露在端口9093 。
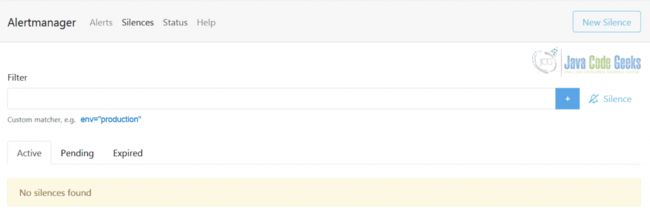
AlertManager Web前端
太好了 ,现在我们必须告诉Prometheus在哪里寻找AlertManager实例。 通常,这是通过配置文件完成的。
rule_files:
- alert.rules.yml
alerting:
alertmanagers:
- static_configs:
- targets:
- 'alertmanager:9093'上面的代码段还包括最有趣的部分,即警报规则,这就是我们接下来要讨论的内容。 那么,在JCG租车平台下,有意义警报的一个好,简单和有用的例子是什么? 由于大多数JCG租车服务都在JVM上运行,因此首先想到的是堆使用情况:太接近限制了就很好地表明了故障和可能的内存泄漏。
groups:
- name: jvm
rules:
- alert: JvmHeapIsFillingUp
expr: jvm_memory_used_bytes{area="heap"} / jvm_memory_max_bytes{area="heap"} > 0.8
for: 5m
labels:
severity: warning
annotations:
description: 'JVM heap usage for {{ $labels.instance }} of job {{ $labels.job }} is close to 80% for last 5 minutes.'
summary: 'JVM heap for {{ $labels.instance }} is filling up'在Prometheus中,使用“ 警报”视图可以看到相同的警报规则,确认已正确选择配置。
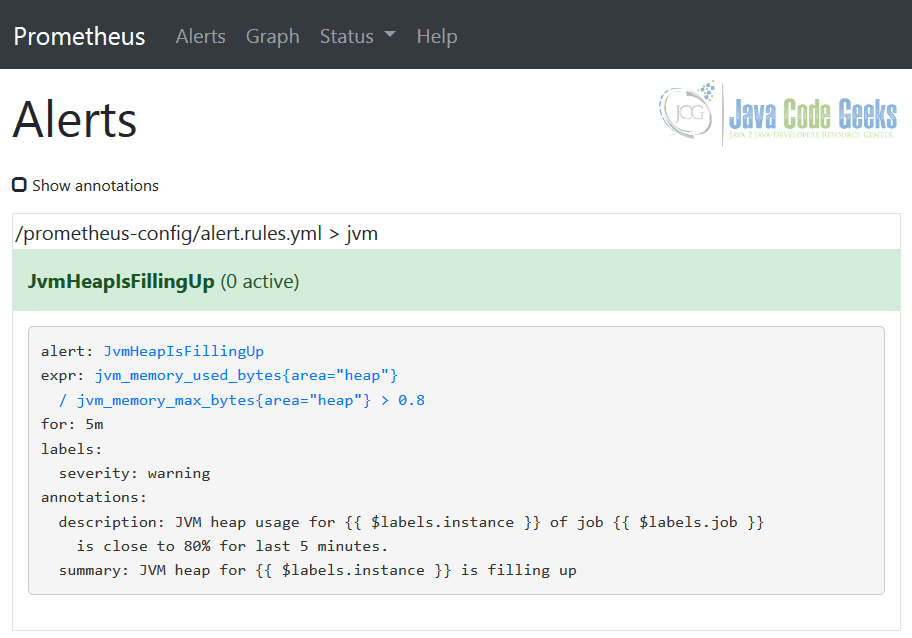
普罗米修斯的警报视图
警报触发后,它将立即显示在AlertManager中 ,同时通知所有受影响的接收者(接收者)。 在下面的图片上,您可以看到触发的JvmHeapIsFillingUp警报的示例。
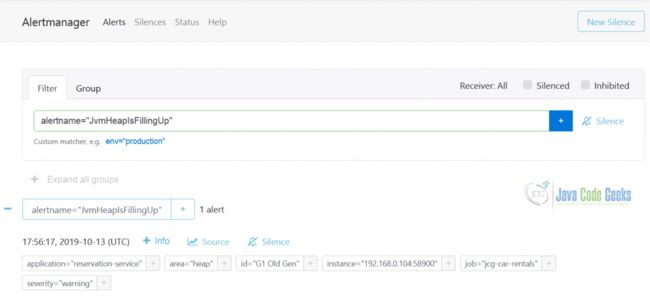
AlertManager中的触发警报
您可能会同意, Prometheus确实是一个完善的监视平台,不仅从度量收集角度涵盖了您,而且还提供了警报。
4.2 Tick Stack:Chronograf
如果您对TICK堆栈感到熟悉,那是因为在本教程的上半部分它弹出了我们的雷达。 Tron堆栈的组成部分之一(对应于缩写C )是Chronograf 。
Chronograf 为 Kapacitor 提供了一个用户界面, Kapacitor 是一个本地数据处理引擎,可以处理来自 InfluxDB的 流数据和批处理数据 。 您可以使用简单的分步UI创建警报,并在 Chronograf中 查看警报历史记录 。
https://www.influxdata.com/time-series-platform/chronograf/
InfluxDB 2.0 (仍处于alpha版本),通常是InfluxDB和TICK堆栈的未来,会将Chronograf纳入其时间序列平台。
4.3 Netfix图集
Netflix Atlas是我们之前谈论过的老用户中的最后一个,它也支持内置在平台中的警报 。
4.4鹰派
从红帽社区项目之一的Hawkular开始,我们将关闭专用于多合一的专用开源监视解决方案的设备。
Hawkular 是一组开放源代码(Apache许可证v2)项目,旨在作为常见监视问题的通用解决方案。 该 Hawkular 项目提供可用于各种监控需要REST服务。
https://www.hawkular.org/overview/
Hawkular组件列表包括对警报,度量标准收集和分布式跟踪的支持(基于Jaeger )。
4.5舞台监控器
Stagemonitor是专用于基于Java的服务器应用程序的监视解决方案的示例。
Stagemonitor 是一个Java监视代理,它与时间序列数据库(例如 Elasticsearch , Graphite 和 InfluxDB) 紧密集成 以分析图形化指标,而 Kibana则 可以分析请求和调用栈。 它包括 可以自定义的 预配置 Grafana 和 Kibana 仪表板。
https://github.com/stagemonitor/stagemonitor
与Hawkular相似 ,它具有开箱即用的分布式跟踪,指标和警报支持。 另外,由于它仅针对Java应用程序,因此许多特定于Java的见解也都被支持到平台中。
4.6格拉法纳
听起来似乎没什么好料的,但是Grafana不仅是一个很棒的可视化工具,而且从4.0版开始,它带有自己的警报引擎和警报规则。 Grafana中的警报可在每个仪表板级别使用(目前仅图形),并且保存后,警报规则将被提取到单独的存储中并计划进行评估。 老实说,有一些限制使Grafana警惕使用受限。
4.7自适应警报
到目前为止,我们已经讨论了基于度量,规则,标准或/和表达式的或多或少的传统警报方法。 但是,诸如异常检测之类的更先进的技术正逐渐进入监视系统。 该领域的先驱之一是Expedia的 Adaptive Alerting 。
自适应警报 的主要目标 是帮助降低平均检测时间(MTTD)。 它通过侦听流指标数据,识别候选异常,对其进行验证以避免误报并最终将其传递到下游的浓缩和响应系统来实现。 – https://github.com/ExpediaDotCom/adaptive-alerting/wiki/Architectural-Overview
自适应警报位于Haystack异常检测子系统的后面,该子系统是我们在本教程的上一部分中谈到的一种灵活,可伸缩的跟踪和分析系统。
5.编排
服务网格所统治的容器协调器可能是当今最广泛的微服务部署模型。 实际上,服务网格扮演着负责并了解一切的“影子红衣主教”的角色。 通过从服务网格中获取所有这些知识,将展现出微服务架构的完整图景。 决定追求这个简单而强大的想法的第一个项目是Kiali 。
Kiali 是可观测控制台 Istio 与服务网格配置功能。 它可以通过推断拓扑来帮助您了解服务网格的结构,还可以提供网格的运行状况。 Kiali提供了详细的指标,并且基本的 Grafana 集成可用于高级查询。 通过集成 Jaeger 提供分布式跟踪 。
Kiali将大多数可观察性Struts整合在一处,并将其与微服务机群的实时拓扑视图结合在一起。 如果您不使用Istio , 那么Kiali可能对您没有太大帮助,但是其他服务网格正在赶上,例如Linkerd还具有遥测和监视功能。
那么警报呢? 警报功能似乎暂时缺席了,您可能需要亲自加入Prometheus或/和Grafana才能配置警报规则。
6.云
警报的云故事是我们在讨论指标时已经开始的讨论的逻辑延续。 管理警报的是那些负责收集操作数据的产品。
在使用AWS的情况下, Amazon CloudWatch可以基于预定义的阈值或基于机器学习算法(例如异常检测)来设置警报( AWS警报概念)和自动操作。
Azure Monitor支持Microsoft Azure中的指标和日志收集,它可以基于日志,指标或活动配置不同类型的警报。
同样, Google Cloud将警报捆绑到Stackdriver Monitoring中 ,它提供了一种定义警报策略的方式:要警告的情况以及如何通知。
7.无服务器
在无服务器世界中,警报与其他地方一样重要。 但是,正如我们已经意识到的那样,例如与主机相关的警报肯定不在您的视线范围内。 那么在无服务器领域中有关警报的情况如何?
实际上,这不是一个容易回答的问题。 显然,如果您使用的是云提供商的无服务器产品,那么他们的工具应该足以覆盖(或限制?)。 另一方面,我们有独立的框架可以自己选择。
例如, OpenFaas使用Prometheus和AlertManager,因此您几乎可以自由定义所需的任何警报。 同样, Apache OpenWhisk公开了许多指标,这些指标可以发布到Prometheus ,并由警报规则进一步修饰。 无服务器框架附带了一组预配置的警报,但是它们的免费层有相关限制。
8.警报不仅涉及指标
在大多数情况下, 指标是输入到警报规则的唯一输入。 总的来说,这是有道理的,但是您可能还需要利用其他信号。 让我们以日志为例。 如果日志中出现某种特定类型的异常,您想获得警报怎么办?
不幸的是, Prometheus或Grafana , Netfix Atlas , Chronograf或Stagemonitor都不会在这里为您提供帮助。 令人欣慰的是,我们拥有Hawkular ,它能够检查存储在Elasticsearch中的日志并使用模式匹配来触发警报。 另外, Grafana Loki在支持基于日志的警报方面也取得了不错的进展 。 作为最后的手段,您可能需要推出自己的解决方案。
9.微服务:监视和警报–结论
在本教程的最后部分中,我们讨论了警报,即可观察性讨论的高潮。 如我们所见,创建警报非常容易,但是要提出好的和可行的警报却非常困难。 如果您在晚上被传呼,那应该是一个真正的原因。 您不应花费数小时来尝试了解此警报的含义,触发该警报的原因以及如何处理。
10.最后
诚然,这是一段漫长的旅程! 在整个过程中,我们讨论了许多不同的主题,您可能会害怕微服务体系结构 。 不用担心,它带来了巨大的好处,但是它还需要您以不同的方式考虑正在构建的系统。 希望本教程的结尾只是您进入微服务体系结构令人兴奋的世界的开始。
但是,请保持警惕。 是的, 微服务架构不是万灵丹 。 请不要购买它作为销售宣传或陷入炒作陷阱。 它解决了真正的问题,但是在选择微服务作为解决方案之前,您应该真正解决它们。 请不要反转这个简单的公式。
祝您好运,并祝您维修愉快!
翻译自: https://www.javacodegeeks.com/microservices-for-java-developers-monitoring-and-alerting.html